MySQL实现排名/分组排名/合计(8.0窗口函数rank/dense_rank、5.6/5.7自行模拟)
读完本文,您将掌握:
- MySQL查询时直接显示排名/分组排名/分组合计的方法,支持5.6/5.7/8.0版本
- MySQL 8.0中
rank()和dense_rank()的用法与区别 - MySQL 8.0的
window窗口函数用法 - MySQL 变量的一些用法
更多MySQL函数介绍,可查看《MySQL函数和运算符》
目录
- 目标效果
- 实现方案
- MySQL 8.0
- 全局排名
- 分组排名
- 合计
- 小结
- MySQL 5.6/5.7
- 全局排名
- 分组排名
- 合计
- 总结
目标效果
模拟数据如下:
DROP TABLE IF EXISTS `test_sum`;
CREATE TABLE `test_sum` (
`year` SMALLINT NOT NULL,
`province` VARCHAR(32) NOT NULL,
`num` INT UNSIGNED NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
INSERT INTO `test_sum` (`year`,`province`,`num`) VALUES
(2018,'北京',1),
(2018,'上海',3),
(2018,'浙江',7),
(2019,'北京',5),
(2019,'上海',5),
(2019,'浙江',11);
目标实现三个场景:
- 结果集会显示全局排名

排名分有间隔和无间隔两种情况:主要区别为出现并列排名后,下一个排名是按行号,还是在上一个排名后+1
- 结果集分几个组后独立排名

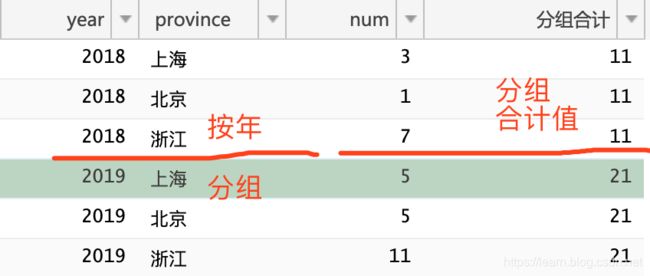
- 结果集分几个组后显示每行数据、和合计值
实现方案
因为不同MySQL版本,实现方案有所不同,下面分开介绍方案。
小提示:判断MySQL函数在哪个版本支持,可以在MySQL官方的《函数和运算符参考文档》中查找、对比不同版本。
MySQL 8.0
MySQL 8.0提供了窗口函数1。其实现的核心,通过window获取结果集、在window中可以指定排序和分组,然后主查询通过over连接window结果集,进行相应运算。窗口函数包括排名等函数。
全局排名
只要使用内置的rank()、dense_rank()函数2即可。
SELECT *,
ROW_NUMBER() OVER w AS '行号',
RANK() OVER w AS '排名-有间隔',
DENSE_RANK() OVER w AS '排名-无间隔'
FROM `test_sum`
WINDOW w AS (ORDER BY `num`);
WINDOW和OVER是窗口函数的主要特征。
分组排名
分组排名的实现,与上面全局排名的区别,仅仅是WINDOW中增加了PARTITION:
SELECT *,
ROW_NUMBER() OVER w AS '行号',
RANK() OVER w AS '排名-有间隔',
DENSE_RANK() OVER w AS '排名-无间隔'
FROM `test_sum`
WINDOW w AS (partition by `year` ORDER BY `num`)
合计
SELECT *, SUM(`num`) over w AS '分组合计'
FROM `test_sum`
WINDOW w AS (partition by `year`)
ORDER BY `year`, `province`
窗口函数下的分组合计,和之前理解的
group分组有所不同,区别在于合计函数并不会导致分组的行合并成一行。
小结
思考窗口函数的实现思路,看起来像是window查询出后,按照排序、分组在内存中组织临时表(有序、指定分区),然后按分区开始运算主查询函数,运算后的结果按分区键关联到临时表中,然后整合数据输出。
window中指定排序、主查询不指定排序,最终的结果是按window的排序来输出,而不是主查询默认的顺序;而多个window都指定了排序时,会使用最后一个的排序(可以尝试同个列用升序和降序),因而有此猜测。
后面会考虑追踪sql执行过程、验证猜想,有结果再补充更新本文。
MySQL item_rank源代码文档:https://dev.mysql.com/doc/dev/mysql-server/latest/classItem__rank.html
MySQL 5.6/5.7
上面说的三个效果,MySQL 8.0以下都需要自行模拟。
全局排名
全局排名实现思路:
- 查询结果集,指定排序
- 声明变量,结果集每行都通过变量计算、排名需否增加
最终SQL如下:
select a.*,
@rowNo := @rowNo + 1 as '行号',
if(`num` = @preFactor, @curRank, @curRank := @rowNo) as '排名-有间隔',
if(`num` = @preFactor, @curDenseRank, @curDenseRank := @curDenseRank + 1) as '排名-无间隔',
@preFactor := `num` as "临时列"
from `test_sum` a ,
(select @rowNo :=0, @curDenseRank := 0, @curRank := 0, @preFactor := NULL) q
order by `num`;
要点说明:
(select @rowNo :=0, @curDenseRank := 0, @curRank := 0, @preFactor := NULL) q这个子查询,只是快速声明变量的一个方式,等价于在select前执行set @rowNo =0, @curDenseRank = 0, @curRank = 0, @preFactor = NULL;- 每获取一行数据,
select后的表达式都会计算一次,这就像在对所有数据进行循环遍历时计算一样。
分组排名
思路:
- 按分组排序,确定分组开始位置的行;
- 该分组所有行,在其全局排名上,减去改组开始位置行的全局排名、然后+1即可
select a.*,
@rowNo := @rowNo + 1 as '行号',
if( @prePartition = `year`, @rankOffset := @rankOffset, @rankOffset := @rowNo - 1) as 'offset_rank',
if( @prePartition = `year`, @denseRankOffset := @denseRankOffset, @denseRankOffset := @curDenseRank) as 'offset_dense',
if(`num` = @preFactor, @curRank, @curRank := @rowNo) as '排名-有间隔',
@curRank - @rankOffset as '分组排名-有间隔',
if(`num` = @preFactor, @curDenseRank, @curDenseRank := @curDenseRank + 1) as '排名-无间隔',
@curDenseRank - @denseRankOffset as '分组排名-无间隔',
@preFactor := `num` as temp, @prePartition := `year`
from `test_sum` a ,
(select @rowNo :=0, @curDenseRank := 0, @curRank := 0, @preFactor := NULL,
@prePartition := NULL, @rankOffset := 0, @denseRankOffset := 0) q
order by `year`, `num`;
效果如下:

合计
先看SQL,思路稍微有点绕,结合下面的截图来讲:
SQl如下:
select `year`, `province`, `num`, if(@year = `y1`, @num := @num, @num:=`sum`) AS '分组合计', @year:=`y1`
from
(
select *,
if(@year = `year` , @num:=@num + `num` , @num:=`num`) `sum`,
@year:=`year` 'y1'
from `test_sum` a, (select @year:=NULL, @num:=0) temp
order by `year`, `province` desc
) temp
order by 1, 2
执行效果截图:
- 子查询:指定分组+任意列,但需确保组合列是唯一的,排序与实际查询需要的顺序相反(倒序)
- 结果集中用变量进行合计,并作为临时列
- 合计时发现是新分组,合计时从0开始合计
- 每一组的最后一行,实际上会得到本组的合计值

- 主查询:处理子查询的结果,按实际需要排序(正序)
- 子查询时每组最后一行,在主查询中变成每组第一行
- 使用变量缓存第一行的合计值;
- 发现是新分组时,更新变量为当前行的合计值
- 不是第一行,使用缓存的合计值;

方案不足:用子查询排序后再分组,但实际上都在内存中,消耗太大;即使加limit限制,对大数据量时不可靠
总结
虽然8.0支持了内置函数,但5.7的解决方案也提供了更多MySQL开发的可能。
MySQL8.0新增加的窗口函数,还有其他一些具体函数也非常有用,可以自行去进一步了解2。
以上。感谢您的阅读。
MySQL官方文档 - 窗口函数语法:https://dev.mysql.com/doc/refman/8.0/en/window-functions-usage.html ↩︎
MySQL官方文档 - 窗口函数概述: https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html ↩︎ ↩︎