使用Kaldi CVTE v2模型进行语音识别测试 2/2
目录
- 词格输出
- 查看lat.1的二进制内容
- 详解 lat.1.gz 文件
- 使用发音词典打印出文字
- 查看 OpenFST 的图
- 评测模型
- 多种超参数打分
- 输出最佳 WER
词格输出
上一篇文章中,我们提到 nnet3-latgen-faster 的输出结果是 lat.1.gz,这个压缩文件是使用ark binary格式存储的Lattice,即识别结果是词格压缩文件。
可以认为,词格(Lattice 或 CompactLattice) 就是Kaldi的语音识别结果,这种形式的输出对于开发者基于其他方法,提取最优结果更友好。
回顾一下 nnet3-latgen-faster 的使用:
nnet3-latgen-faster \
--frame-subsampling-factor=3 \
--frames-per-chunk=50 \
--extra-left-context=0 \
--extra-right-context=0 \
--extra-left-context-initial=-1 \
--extra-right-context-final=-1 \
--minimize=false \
--max-active=7000 \
--min-active=200 \
--beam=15.0 \
--lattice-beam=8.0 \
--acoustic-scale=1.0 \
--allow-partial=true \
--word-symbol-table=exp/chain/tdnn/graph/words.txt \
exp/chain/tdnn/final.mdl \
exp/chain/tdnn/graph/HCLG.fst \
"ark,s,cs:apply-cmvn --norm-means=true --norm-vars=false --utt2spk=ark:data/chat001/test/split1/1/utt2spk scp:data/chat001/test/split1/1/cmvn.scp scp:data/chat001/test/split1/1/feats.scp ark:- |" \
"ark:|lattice-scale --acoustic-scale=10.0 ark:- ark:- | gzip -c >exp/chain/tdnn/decode_chat001_test/lat.1.gz"
在词格输出时,lattice-scale 进一步处理了词格中的声学分,--acoustic-scale=10.0,将原声学分提高10倍,与之对应的是HCLG.fst中对一个词的图固有分数,并且其中主要的成分是语言模型的分数,可以通过 lattice-scale --lm-scale 处理。
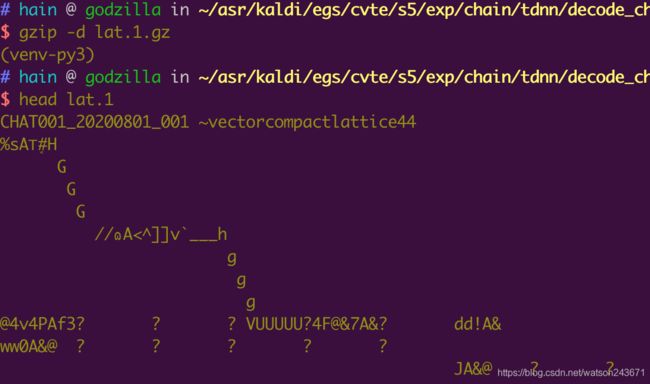
查看lat.1的二进制内容
前面一行的内容,可以看到 lat.1 为每个语音文件建立了 lattice 数组,44维
详解 lat.1.gz 文件
以文本形式打印数组内容
cd egs/cvte/s5
source path.sh
cd exp/chain/tdnn/decode_chat001_test
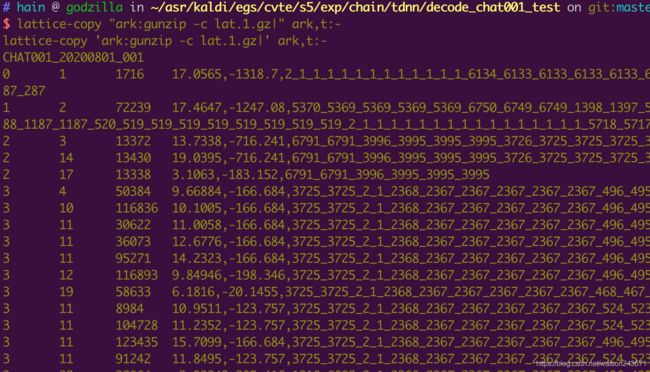
lattice-copy "ark:gunzip -c lat.1.gz|" ark,t:-
使用发音词典打印出文字
depending on the lang/ directory, parse phone to words
cd cvte/s5
source path.sh
cd exp/chain/tdnn/decode_chat001_test
lattice-copy "ark:gunzip -c lat.1.gz|" ark,t:- | ../../../../utils/int2sym.pl -f 3 `pwd`/../../../../exp/chain/tdnn/graph/words.txt
这个命令输出内容很多,截取部分:
CHAT001_20200801_001
0 1 上海 17.0565,-1318.7,2_1_1_1_1_1_1_1_1_1_1_1_1_6134_6133_6133_6133_6133_6133_6133_538_537_537_537_537_2888_2887_2887_2887_288_287_287_287_287_287
1 2 浦东机场 17.4647,-1247.08,5370_5369_5369_5369_5369_6750_6749_6749_1398_1397_5128_5127_5127_5127_5127_3936_3935_3935_3935_2920_2919_2919_2919_1188_1187_1187_520_519_519_519_519_519_519_519_519_2_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_1_5718_5717_5717_5717_5717_5717_6792_6791
2 3 入境 13.7338,-716.241,6791_6791_3996_3995_3995_3995_3726_3725_3725_3725_3725_3725_3725
2 14 入镜 19.0395,-716.241,6791_6791_3996_3995_3995_3995_3726_3725_3725_3725_3725_3725_3725_3725_3725_2_1_2368_2367_2367
2 17 入 3.1063,-183.152,6791_6791_3996_3995_3995_3995
3 4 房 9.66884,-166.684,3725_3725_2_1_2368_2367_2367_2367_2367_2367_496_495_495
3 10 防 10.1005,-166.684,3725_3725_2_1_2368_2367_2367_2367_2367_2367_496_495_495
3 11 坊 11.0058,-166.684,3725_3725_2_1_2368_2367_2367_2367_2367_2367_496_495_495_6290_6289_6289_6289_6674
3 11 妨 12.6776,-166.684,3725_3725_2_1_2368_2367_2367_2367_2367_2367_496_495_495_6290_6289_6289_6289_6674
3 11 肪 14.2323,-166.684,3725_3725_2_1_2368_2367_2367_2367_2367_2367_496_495_495_6290_6289_6289_6289_6674
3 12 防暑 9.84946,-198.346,3725_3725_2_1_2368_2367_2367_2367_2367_2367_496_495_495_6290_6289_6289_6289_6758_6757_6757_6757
这实际上就是根据输入的语音文件,计算出的相关的 HCLG.fst 中的子图,也是使用OpenFST 形式描述的加权状态转移图。
查看 OpenFST 的图
在上一步,输出的文件可以认为是fst格式,那么对其中一项修改并保存为 fst 文件,我们就可以使用OpenFST查看这个图了。
先生成 draw 文件。
fstdraw --portrait=true --osymbols=words.txt utterance.fst > ~/tmp/utterance.fst.dot
其中,osymbols 可以讲符号转为文字,更友好,除 fstdraw 外,还有fstprint 完成打印到控制台。
生成文件
cat ~/tmp/utterance.fst.dot | dot -Tsvg > utterance.fst.svg # 生成SVG
fst通常很大,不方便查看,主要是帮助理解算法。
得到 svg 文件,使用浏览器打开。

评测模型
如何判断一个模型的质量怎么样呢?在测试集上验证。
多种超参数打分
以解码器的输出为输入,通过 lattice-scale, lattice-add-penalty, lattice-best-path 生成 scoring_kaldi/penalty_0.0/16.txt 文件。
文件 scoring_kaldi/penalty_0.0/log/best_path.16.log 内容
# lattice-scale --inv-acoustic-scale=16 "ark:gunzip -c exp/chain/tdnn/decode_chat001_test/lat.*.gz|" ark:- | lattice-add-penalty --word-ins-penalty=0.0 ark:- ark:- | lattice-best-path --word-symbol-table=exp/chain/tdnn/graph/words.txt ark:- ark,t:- | utils/int2sym.pl -f 2- exp/chain/tdnn/graph/words.txt | cat > exp/chain/tdnn/decode_chat001_test/scoring_kaldi/penalty_0.0/16.txt
# Started at Sat Aug 1 16:22:07 CST 2020
#
lattice-add-penalty --word-ins-penalty=0.0 ark:- ark:-
lattice-scale --inv-acoustic-scale=16 'ark:gunzip -c exp/chain/tdnn/decode_chat001_test/lat.*.gz|' ark:-
LOG (lattice-scale[5.5.765-f88d5]:main():lattice-scale.cc:107) Done 2 lattices.
LOG (lattice-add-penalty[5.5.765-f88d5]:main():lattice-add-penalty.cc:62) Done adding word insertion penalty to 2 lattices.
lattice-best-path --word-symbol-table=exp/chain/tdnn/graph/words.txt ark:- ark,t:-
LOG (lattice-best-path[5.5.765-f88d5]:main():lattice-best-path.cc:99) For utterance CHAT001_20200801_001, best cost 94.4663 + -344.934 = -250.468 over 208 frames.
CHAT001_20200801_001 上海 浦东机场 入境 房 输入 全 闭 环 管理
LOG (lattice-best-path[5.5.765-f88d5]:main():lattice-best-path.cc:99) For utterance CHAT001_20200801_002, best cost 105.511 + -522.802 = -417.291 over 333 frames.
CHAT001_20200801_002 北京 地铁 宣武门 站 综合 改造 新增 换乘 通道
LOG (lattice-best-path[5.5.765-f88d5]:main():lattice-best-path.cc:124) Overall cost per frame is -1.23431 = 0.369643 [graph] + -1.60395 [acoustic] over 541 frames.
LOG (lattice-best-path[5.5.765-f88d5]:main():lattice-best-path.cc:128) Done 2 lattices, failed for 0
# Accounting: time=0 threads=1
# Ended (code 0) at Sat Aug 1 16:22:07 CST 2020, elapsed time 0 seconds
参数,inv-acoustic-scale=16, word-ins-penalty=0.0;
以上命令执行后,取得下面两个文件。
文件 scoring_kaldi/penalty_0.0/16.chars.txt 内容
CHAT001_20200801_001 上 海 浦 东 机 场 入 境 房 输 入 全 闭 环 管 理
CHAT001_20200801_002 北 京 地 铁 宣 武 门 站 综 合 改 造 新 增 换 乘 通 道
文件 scoring_kaldi/penalty_0.0/16.txt 内容
CHAT001_20200801_001 上海 浦东机场 入境 房 输入 全 闭 环 管理
CHAT001_20200801_002 北京 地铁 宣武门 站 综合 改造 新增 换乘 通道
此外还有多种组合:

因为作为测试集,有对应的正确答案,通过 scoring 程序,识别出最佳的参数,作为上线应用的参数。
输出最佳 WER
前述步骤已经生成 scoring_kaldi, scoring_kaldi 是基于 lat.1.gz 的。
penaltyN中又包括很多路径。
下面脚本,是评分过程,将各种输出结果的WER计算出来,得到最佳的参数。
# The output of this script is the files "lat.*.gz"-- we'll rescore this at
# different acoustic scales to get the final output.
if [ $stage -le 3 ]; then
if ! $skip_scoring ; then
[ ! -x local/score.sh ] && \
echo "Not scoring because local/score.sh does not exist or not executable." && exit 1;
echo "score best paths"
[ "$iter" != "final" ] && iter_opt="--iter $iter"
local/score.sh $scoring_opts --cmd "$cmd" $data $graphdir $dir
echo "score confidence and timing with sclite"
fi
fi

WER最好的值。
$ cat scoring_kaldi/best_cer
%WER 2.94 [ 1 / 34, 0 ins, 0 del, 1 sub ] exp/chain/tdnn/decode_chat001_test/cer_7_0.0
$ cat cer_7_0.0
compute-wer --text --mode=present ark:exp/chain/tdnn/decode_chat001_test/scoring_kaldi/test_filt.chars.txt ark,p:-
%WER 2.94 [ 1 / 34, 0 ins, 0 del, 1 sub ]
%SER 50.00 [ 1 / 2 ]
Scored 2 sentences, 0 not present in hyp.
这样,就得到了模型的评测结果和最佳的超参数。