python学习-第11课
一、内置模块2
1.1.logging(日志)
1.1.1.日志级别
日志级别大小关系为:CRITICAL > ERROR > WARNING > INFO > DEBUG
● DEBUG:详细的信息,通常只出现在诊断问题上。
● INFO:确认一切按预期运行
● WARNING:一个警告,可能会有一些意想不到的事情发生了,或表明一些问题在不久的将来(例如。磁盘空间低”)。这个软件还能按预期工作,这个是默认级别
● ERROR:个更严重的问题,软件没能执行一些功能
● CRITICAL:一个严重的错误,这表明程序本身可能无法继续运行
1.1.2.日志级别的常用函数
logging模块定义的模块级别的常用函数包括如下:| 函数 | 说明 |
|---|---|
| logging.debug(msg, *args, **kwargs) | 创建一条严重级别为DEBUG的日志记录 |
| logging.info(msg, *args, **kwargs) | 创建一条严重级别为INFO的日志记录 |
| logging.warning(msg, *args, **kwargs) | 创建一条严重级别为WARNING的日志记录 |
| logging.error(msg, *args, **kwargs) | 创建一条严重级别为ERROR的日志记录 |
| logging.critical(msg, *args, **kwargs) | 创建一条严重级别为CRITICAL的日志记录 |
| logging.log(level, *args, **kwargs) | 创建一条严重级别为level的日志记录 |
示例
import logging
logger=logging.debug("this is debug level")
logger=logging.info("this is info level")
logger=logging.warning("this is warning level") #默认
logger=logging.error("this is error level")
logger=logging.critical("this is critical level")
结果
WARNING:root:this is warning level
ERROR:root:this is error level
CRITICAL:root:this is critical level
debug和info模式没有打印
**kwargs参数说明:
**kwargs参数支持3个关键字参数: exc_info, stack_info, extra
exc_info: 其值为布尔值,如果该参数的值设置为True,则会将异常异常信息添加到日志消息中。如果没有异常信息则添加None到日志信息中。
stack_info: 其值也为布尔值,默认值为False。如果该参数的值设置为True,栈信息将会被添加到日志信息中。
extra: 这是一个字典(dict)参数,它可以用来自定义消息格式中所包含的字段,但是它的key不能与logging模块定义的字段冲突。
示例
import logging
logging.basicConfig(format="%(asctime)s %(levelname)s %(user)s[%(ip)s] %(message)s",datefmt="%Y-%m-%d %H:%M:%S %p")
logging.warning("this is warning level log info",exc_info=True,stack_info=True,extra={"user":"pyname","ip":"192.168.200.121"})
结果

1.1.3.logging.basicConfig()
logging.basicConfig(**kwargs)用于指定“要记录的日志级别”、“日志格式”、“日志输出位置”、“日志文件的打开模式”等信息。
示例
import logging
logging.basicConfig(level=logging.DEBUG,format="%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s",datefmt="%Y/%m/%d %H:%M:%S",filename="myapp.log",filemode="w")
logging.debug("this is debug message")
logging.info("this is info message")
logging.warning("this is debug message")
logging.error("this is error message")
logging.critical("this is critical message")
运行生成myapp.log文件,生成文件内容如下:
2018/04/25 14:18:43 test1102.py [line:11] DEBUG this is debug message
2018/04/25 14:18:43 test1102.py [line:12] INFO this is info message
2018/04/25 14:18:43 test1102.py [line:13] WARNING this is debug message
2018/04/25 14:18:43 test1102.py [line:14] ERROR this is error message
2018/04/25 14:18:43 test1102.py [line:15] CRITICAL this is critical message
参数说明:
level: 设置日志级别,默认为logging.WARNING
filename: 指定日志文件名。
filemode: 和file函数意义相同,指定日志文件的打开模式,'w'或'a'
format: 指定输出的格式和内容,format可以输出很多有用信息,如上例所示:
%(levelname)s: 打印日志级别名称
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(process)d: 打印进程ID
%(message)s: 打印日志信息
datefmt: 指定时间格式,同time.strftime()
stream: 指定将日志的输出流,可以指定输出到sys.stderr,sys.stdout或者文件,默认输出到sys.stderr,当stream和filename同时指定时,stream被忽略
1.1.4.logging.getLogger()
用于定义一个模块对象
示例
import logging
logger=logging.getLogger(__name__) #__name__指提是本模块名字
def hello():
print("hello world")
def main():logger.info("开始执数") #调用logger
codecs.open("demo1101.py","w")
try:
a = 2/0
except Exception as e:
logger.error("除数不能为0")
finally:
logger.warning("没有关闭文件")
if __name__=="__main__":
main()
1.1.5.logging日志模块四大组件及类
logging模块的四大组件如下:| 组件名称 | 对应类名 | 功能描述 |
|---|---|---|
| 日志器 | Logger | 提供了应用程序可一直使用的接口 |
| 处理器 | Handler | 将logger创建的日志记录发送到合适的目的输出 |
| 过滤器 | Filter | 提供了更细粒度的控制工具来决定输出哪条日志记录,丢弃哪条日志记录 |
| 格式器 | Formatter | 决定日志记录的最终输出格式 |
这些组件之间的关系描述:
- 日志器(logger)需要通过处理器(handler)将日志信息输出到目标位置,如:文件、sys.stdout、网络等;
- 不同的处理器(handler)可以将日志输出到不同的位置;
- 日志器(logger)可以设置多个处理器(handler)将同一条日志记录输出到不同的位置;
- 每个处理器(handler)都可以设置自己的过滤器(filter)实现日志过滤,从而只保留感兴趣的日志;
- 每个处理器(handler)都可以设置自己的格式器(formatter)实现同一条日志以不同的格式输出到不同的地方。
1.1.5.1.Logger类
Logger对象有3个任务要做:1)向应用程序代码暴露几个方法,使应用程序可以在运行时记录日志消息;
2)基于日志严重等级(默认的过滤设施)或filter对象来决定要对哪些日志进行后续处理;
3)将日志消息传送给所有感兴趣的日志handlers。
Logger对象最常用的方法分为两类:配置方法 和 消息发送方法
最常用的配置方法如下:
| 方法 | 描述 |
|---|---|
| Logger.setLevel() | 设置日志器将会处理的日志消息的最低严重级别 |
| Logger.addHandler() 和 Logger.removeHandler() | 为该logger对象添加 和 移除一个handler对象 |
| Logger.addFilter() 和 Logger.removeFilter() | 为该logger对象添加 和 移除一个filter对象 |
内建等级中,级别最低的是DEBUG,级别最高的是CRITICAL。例如setLevel(logging.INFO),此时函数参数为INFO,那么该logger将只会处理INFO、WARNING、ERROR和CRITICAL级别的日志,而DEBUG级别的消息将会被忽略/丢弃。
logger对象配置完成后,可以使用下面的方法来创建日志记录:
| 方法 | 描述 |
|---|---|
| Logger.debug(), Logger.info(), Logger.warning(), Logger.error(), Logger.critical() | 创建一个与它们的方法名对应等级的日志记录 |
| Logger.exception() | 创建一个类似于Logger.error()的日志消息 |
| Logger.log() | 需要获取一个明确的日志level参数来创建一个日志记录 |
Logger.exception()与Logger.error()的区别在于:Logger.exception()将会输出堆栈追踪信息,另外通常只是在一个exception handler中调用该方法。
Logger.log()与Logger.debug()、Logger.info()等方法相比,虽然需要多传一个level参数,显得不是那么方便,但是当需要记录自定义level的日志时还是需要该方法来完成。
1.1.5.2.Handler类
Handler对象的作用是(基于日志消息的level)将消息分发到handler指定的位置(文件、网络、邮件等)。Logger对象可以通过addHandler()方法为自己添加0个或者更多个handler对象。比如,一个应用程序可能想要实现以下几个日志需求:
1)把所有日志都发送到一个日志文件中;
2)把所有严重级别大于等于error的日志发送到stdout(标准输出);
3)把所有严重级别为critical的日志发送到一个email邮件地址。
这种场景就需要3个不同的handlers,每个handler复杂发送一个特定严重级别的日志到一个特定的位置。
一个handler中只有非常少数的方法是需要应用开发人员去关心的。对于使用内建handler对象的应用开发人员来说,似乎唯一相关的handler方法就是下面这几个配置方法:
| 方法 | 描述 |
|---|---|
| Handler.setLevel() | 设置handler将会处理的日志消息的最低严重级别 |
| Handler.setFormatter() | 为handler设置一个格式器对象 |
| Handler.addFilter() 和 Handler.removeFilter() | 为handler添加 和 删除一个过滤器对象 |
需要说明的是,应用程序代码不应该直接实例化和使用Handler实例。因为Handler是一个基类,它只定义了素有handlers都应该有的接口,同时提供了一些子类可以直接使用或覆盖的默认行为。下面是一些常用的Handler:
| Handler | 描述 |
|---|---|
| logging.StreamHandler | 将日志消息发送到输出到Stream,如std.out, std.err或任何file-like对象。 |
| logging.FileHandler | 将日志消息发送到磁盘文件,默认情况下文件大小会无限增长 |
| logging.handlers.RotatingFileHandler | 将日志消息发送到磁盘文件,并支持日志文件按大小切割 |
| logging.hanlders.TimedRotatingFileHandler | 将日志消息发送到磁盘文件,并支持日志文件按时间切割 |
| logging.handlers.HTTPHandler | 将日志消息以GET或POST的方式发送给一个HTTP服务器 |
| logging.handlers.SMTPHandler | 将日志消息发送给一个指定的email地址 |
| logging.NullHandler | 该Handler实例会忽略error messages,通常被想使用logging的library开发者使用来避免'No handlers could be found for logger XXX'信息的出现。 |
1.1.5.3.Formater类
Formater对象用于配置日志信息的最终顺序、结构和内容。与logging.Handler基类不同的是,应用代码可以直接实例化Formatter类。另外,如果你的应用程序需要一些特殊的处理行为,也可以实现一个Formatter的子类来完成。Formatter类的构造方法定义如下:
logging.Formatter.__init__(fmt=None, datefmt=None, style='%')
可见,该构造方法接收3个可选参数:
- fmt:指定消息格式化字符串,如果不指定该参数则默认使用message的原始值
- datefmt:指定日期格式字符串,如果不指定该参数则默认使用"%Y-%m-%d %H:%M:%S"
- style:Python 3.2新增的参数,可取值为 '%', '{'和 '$',如果不指定该参数则默认使用'%'
1.1.5.3.Filter类
Filter可以被Handler和Logger用来做比level更细粒度的、更复杂的过滤功能。Filter是一个过滤器基类,它只允许某个logger层级下的日志事件通过过滤。该类定义如下:class logging.Filter(name='')
filter(record)
比如,一个filter实例化时传递的name参数值为'A.B',那么该filter实例将只允许名称为类似如下规则的loggers产生的日志记录通过过滤:'A.B','A.B,C','A.B.C.D','A.B.D',而名称为'A.BB', 'B.A.B'的loggers产生的日志则会被过滤掉。如果name的值为空字符串,则允许所有的日志事件通过过滤。
filter方法用于具体控制传递的record记录是否能通过过滤,如果该方法返回值为0表示不能通过过滤,返回值为非0表示可以通过过滤。
1.2.OS
1.2.1. os.name
指明操作系统类型:如果结果为nt,则为windows系统;如果结果为posix,则为unix系统示例
import os
if os.name=="nt":
cmd="ipconfig"
elif os.name=="posix":
cmd="ifconfig"
os.system(cmd)
1.2.2. os.listdir()
os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。这个列表以字母顺序。 它不包括 '.' 和'..' 即使它在文件夹中。只支持在 Unix, Windows 下使用。
语法
os.listdir(path)
参数
- path -- 需要列出的目录路径
path="D:\TDDownload"
dirs=os.listdir(path)
for file in dirs:
print(file)
结果

1.2.3. os.access()
os.access() 方法使用当前的uid/gid尝试访问路径。大部分操作使用有效的 uid/gid, 因此运行环境可以在 suid/sgid 环境尝试。语法
os.access(path, mode)
参数
- path -- 要用来检测是否有访问权限的路径。
- mode -- mode为F_OK,测试存在的路径,或者它可以是包含R_OK, W_OK和X_OK或者R_OK, W_OK和X_OK其中之一或者更多。
os.F_OK: 作为access()的mode参数,测试path是否存在。
os.R_OK: 包含在access()的mode参数中 , 测试path是否可读。
os.W_OK 包含在access()的mode参数中 , 测试path是否可写。
os.X_OK 包含在access()的mode参数中 ,测试path是否可执行。
如果允许访问返回 True , 否则返回False。
示例
import os
ret = os.access("/tmp/foo.txt", os.F_OK)
print ("F_OK - 返回值 %s"% ret)
ret = os.access("/tmp/foo.txt", os.R_OK)
print ("R_OK - 返回值 %s"% ret)
ret = os.access("/tmp/foo.txt", os.W_OK)
print ("W_OK - 返回值 %s"% ret)
ret = os.access("/tmp/foo.txt", os.X_OK)
print ("X_OK - 返回值 %s"% ret)
结果

1.2.4. os.chdir()
os.chdir() 方法用于改变当前工作目录到指定的路径语法
os.chdir(path)
参数
path -- 要切换到的新路径。
返回值
如果允许访问返回 True , 否则返回False。
import os
#查看当前目录
currpath=os.getcwd()
print("当前工作目录为:{0}".format(currpath))
#切换工作目录
newpath="D:\\"
os.chdir(newpath)
#查看切换后的目录
newP=os.getcwd()
print("更改后的工作目录为:{0}".format(newP))
结果
当前工作目录为:D:\pythoncode\LivePython02\14第十一课
更改后的工作目录为:D:\
1.2.5. os.getcwd()
os.getcwd() 方法用于返回当前工作目录。语法
os.getcwd()
参数
无
返回值
返回当前进程的工作目录。
示例
见os.chdir示
1.2.6. os.mkdir()
os.mkdir() 方法用于以数字权限模式创建目录。默认的模式为 0777 (八进制)。语法
os.mkdir(path[, mode])
参数
- path -- 要创建的目录
- mode -- 要为目录设置的权限数字模式
该方法没有返回值。
示例
import os
#创建目录
path="D:\\pythoncode\\tmps"
os.mkdir(path,0o755)
print("目录已创建")
创建目录如下
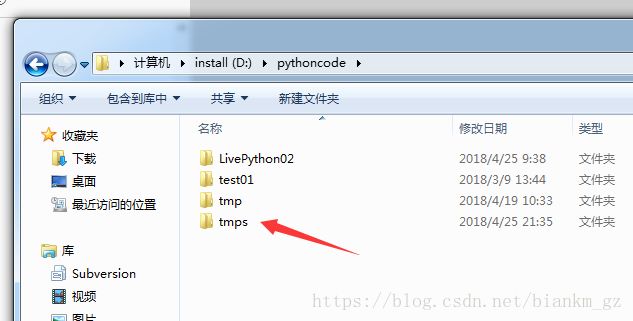
1.2.7. os.remove()
os.remove() 方法用于删除指定路径的文件。如果指定的路径是一个目录,将抛出OSError。在Unix, Windows中有效
语法
os.remove(path)
参数
path -- 要移除的文件路径
返回值
该方法没有返回值
示例
import os
# 列出目录
print ("目录为: {0}".format(os.listdir(os.getcwd())))
# 移除
os.remove("foo.txt")
# 移除后列出目录
print ("移除后 : {0}".format(os.listdir(os.getcwd())))
1.2.8. os.rmdir()
os.rmdir() 方法用于删除指定路径的目录。仅当这文件夹是空的才可以, 否则, 抛出OSError。语法
os.rmdir(path)
参数
- path -- 要删除的目录路径
该方法没有返回值
示例
import os
# 列出目录
print ("目录为: {0}".format(os.listdir(os.getcwd())))
# 删除路径
os.rmdir("mydir")
# 列出重命名后的目录
print ("目录为: {0}".format(os.listdir(os.getcwd())))
1.2.9. os.rename()
os.rename() 方法用于命名文件或目录,从 src 到 dst,如果dst是一个存在的目录, 将抛出OSError。语法
os.rename(src, dst)
参数
- src -- 要修改的文件名或目录名
- dst -- 修改后的文件名或目录名
该方法没有返回值
示例
import os
# 列出目录
print ("目录为: {0}".format(os.listdir(os.getcwd())))
# 重命名
os.rename("test","test2")
print ("重命名成功。")
# 列出重命名后的目录
print ("目录为: {0}".format(os.listdir(os.getcwd())))
1.2.10. os.linesep()
os.linesep字符串给出当前平台使用的行终止符。window换行符\n\r linux换行符\n mac换行符是\r
print(os.linesep)
1.3.sys模块
1.3.1.sys.argv
传递到Python脚本的命令行参数列表,第一个元素是程序本身路径
1.3.2.sys.stdout
标准输出
1.3.3.sys.stdin
标准输入1.3.4.sys.stderr
错误输出1.3.5.sys.modules.keys()
返回所有已经导入的模块列表1.3.6.sys.exit(n)
退出程序,正常退出时exit(0)1.4.random模块
1.4.1.random.random()
用于生成一个0到1区间的随机浮点数示例
import random
print(random.random())
结果
0.02401764095437875
1.4.2.random.uniform()
用于生成一个指定范围内的随机浮点数n,如果 a <= b,则a <= n <= b,如果b < a,则b <= n <= a示例
import random
print(random.uniform(2.5,10))
结果
3.4556583212094947
1.4.3.random.randrange()
语法range(start, stop, step)
在整数范围,每个step获取一个随机数
示例
从1到100随机每隔2随机取一个整数
import random
print(random.randrange(1,101,2))
1.4.4.random.randint(a,b)
用于生成一个指定范围内的整数n,a <= n <= b,等价于random.randrange(a, b+1)。示例
import random
print(random.randint(1,20))
1.4.5.random.choice(seq)
从序列中随机选取一个元素,如果序列为空,则抛出IndexError异常。import random
print(random.choice("ABCD"))
print(random.choice(["A","P","L","E"]))
print(random.choice(("T","E","S","W")))
1.4.6.random.shuffle(x[,random])
原地打乱一个序列(可变序列类型如列表),如果要打乱的是一个不可变序列类型如字符串、元组等,则要用random.sample(x, k=len(x))创建一个新的打乱后的列表。import random
l=["a","b","c","d"]
print(random.shuffle(l))
1.4.7.random.sample(population, k)
从序列或集合中返回指定长度的列表,不会改变原序列或原集合。示例
从中随机获取6位随机码
import random
print(random.sample([1,2,3,4,5,6,7,8,9],6))
1.5.string模块
1.5.1.string.ascii_letters
生成所有字母,从a-z和A-Z示例
import string
print(string.ascii_letters)
结果
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
1.5.2.string.digits
生成0-9数字
示例
import string
print(string.digits)
结果
0123456789
练习题
比如生成激活码,激活码一般都是字母和数字组成的,首先要有一个所有字母和数字的字符串,然后随机取出几个字母或数字
def rand_str(num,length=7):
with codecs.open("activation_code.txt","w") as f:
chars=string.ascii_letters+string.digits
s = [random.choice(chars) for i in range(length)]
f.write("{0}\n".format("".join(s)))
if __name__=="__main__":
rand_str(200)
打开activation_code.txt文件,内容如下:
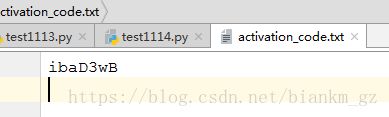
1.5.3.string.ascii_lowercase
生成小写字母a-zimport string
print(string.ascii_lowercase)
结果如下:
abcdefghijklmnopqrstuvwxyz
1.5.4.string.ascii_uppercase
生成大写字母A-Zimport string
print(string.ascii_uppercase)
结果
ABCDEFGHIJKLMNOPQRSTUVWXYZ
1.5.5.string.printable
打印所有可打印的字符,包含字符、数字及特殊字条import string
print(string.printable)
结果
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
1.5.6.string.punctuation
打印特殊字符
import string
print(string.printable)
结果
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
1.5.7.string.hexdigits
打印十六进制
import string
print(string.hexdigits)
结果
0123456789abcdefABCDEF