Android Protect-0.Apk文件结构简介
文章目录
- 1. APK 文件结构
- 2. APK 文件的生成流程
- 3. classes.dex
- 3.1 DEX 文件结构
- 3.1.1 LEB128
- 3.1.2 DexHeader
- 3.1.3 DexMapList
- 3.1.4 DexStringld
- 3.1.5 DexTypeld
- 3.1.6 DexProtoId
- 3.1.7 DexFieldld (标识了类成员)
- 3.1.8 DexMethodld
- 3.1.9 DexClassDef
- 3.2 DEX 文件的验证与优化过程
- 3.3 DEX 文件的修改
- 4. AndroidManifest.xml(AXML 文件格式)
- 4.1 Header
- 4.2 String Chunk
- 4.3 ResourceId Chunk
- 4.4 XmlContent Chunk
- 4.5 AXML 文件的修改
- 5.resources.arsc
- 5.1 ARSC 文件格式
- 5.1 Header、 String Chunk
- 5.2 ResTable_package
- 5.3 TypeStrings、KeyStrings
- 5.4 ResTable_typeSpec、ResTable_type
- 6. META-INF 目录
- 6.1 CERT.RSA
- 6.2 MANIFEST.MF
- 6.3 CERT.SF
window中可以配合Cygwin查看。
1. APK 文件结构
APK 文件与其他系统中的软件包一样,都有自己的格式与组织结构。 从 Android 诞生那天起,APK 文件的格式就没有发生过变化,始终使用 zip 作为其格式。在目录结构上, APK 文件也没有发生过变化。解包查看它的目录结构, 具体如下。
$ unzip app-release.apk
Archive: app-release.apk
inflating: AndroidManifest.xml
inflating: META-INF/CERT.RSA
inflating: META-INF/CERT.SF
inflating: META-INF/MANIFEST.MF
inflating: classes.dex
inflating: res/anim/abc_fade_in.xml
inflating: res/anim/abc_fade_out.xml
...
$ tree
.
├── AndroidManifest.xml
├── META-INF
│ ├── CERT.RSA
│ ├── CERT.SF
│ └── MANIFEST.MF
├── app-release.apk
├── classes.dex
├── desc
├── res
│ ├── anim
│ │ ├── abc_fade_in.xml
...
│ ├── color
│ │ ├── abc_btn_colored_borderless_text_material.xml
│ │ ├── abc_btn_colored_text_material.xml
...
│ │ └── switch_thumb_material_light.xml
...
│ ├── drawable
...
│ │ └── abc_text_select_handle_right_mtrl_light.png
│ ├── layout
...
│ │ ├── activity_main.xml
│ │ ├── notification_action.xml
...
│ │ ├── notification_template_part_time.xml
│ │ ├── select_dialog_item_material.xml
...
│ ├── mipmap-hdpi-v4
│ │ ├── ic_launcher.png
│ │ └── ic_launcher_round.png
...
├── resources.arsc
└── setup.ini
30 directories, 426 files
一个完整的APK文件包含如下内容。
AndroidManifest.xml: 编译好的AXML二进制格式的文件。META-INF目录: 用于保存 APK 的签名信息。classes.dex: 程序的可执行代码。如果开启了MutliDex, 则会有多个DEX文件。res目录: 程序中使用的资源信息。针对不同分辨率的设备,可以使用不同的资源文件。resources.arsc: 编译好的二进制格式的资源信息。assets目录: 如果程序使用Asset系统来存放Raw资源, 所有的资源都将存放在这个目录下。
2. APK 文件的生成流程
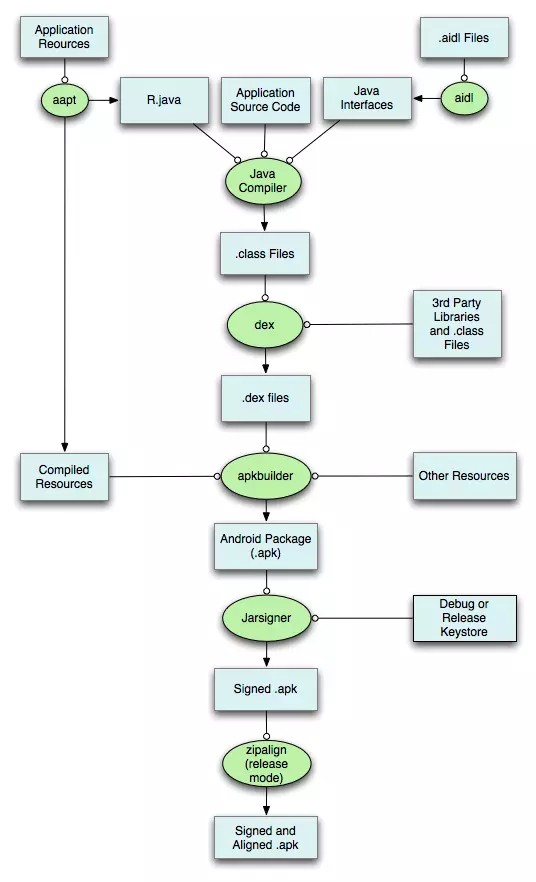
在 ADT 时代, Android 官方发布 了一幅完整的 APK 编译流程图, 如下所示:
首先, 使用 aapt 打包程序资源, 处理项目中的 AndroidManifest.xml 文件和 XML 布局文件,并生成 R.java 文件。
然后, 使用 aidl 解析 AIDL 接口, 定义并生成相应的 Java 文件。
接下来, 调用 Java 编译器生成 class 文件,使用 dx 将所有的 class 文件与 jar 包打包生成 DEX 文件,调用 apkbuilder 将上述资源与 class 文件合并成 APK 文件。
最后 , 对 APK 进行对齐处理和签名 。
到了 Android Studio 时代, 编译流程的细节发生了一些 变化, Android 官方使用 gradle 作为 APK 的构建工具, 但没有给
出 详细的 “新 版” APK 打包流程,只是放出了一幅新的打包流程图,如下所示:

3. classes.dex
classes.dex 中包含 APK 的 可执行代码, 它是分析 Android 软件时最常见的目标。
3.1 DEX 文件结构
在 Android 源码文件 dalvik/libdex/DexFile.h 中, 有 DEX 文件可能用到的所有数据结构与常量定义。
在了解 DEX 文件格式之前,我们来了解一下 DEX 文件使用的数据类型, 如下所示:
| 自定 义类型 | 原类型 | 含 义 |
|---|---|---|
| s1 | int8_t | 8 位有符号整型 |
| u1 | uint8_t | 8 位无符号整型 |
| s2 | int16_t | 16 位有符号整型,小端字节序 |
| u2 | uint16_t | 16 位无符号整型,小端字节序 |
| s4 | int32_t | 32 位有符号整型,小端字节序 |
| u4 | uint32_t | 32 位无符号整型, 小端字节序 |
| s8 | int64_t | 64 位有符号整型, 小端字节序 |
| u8 | uint64_t | 64 位无符号整型, 小端字节序 |
| sleb128 | 无 | 有符号 LEB128, 可变长度 |
| uleb128 | 无 | 无符号 LEB128, 可变长度 |
| uleb128p1 | 无 | 无符号 LEB128加1, 可变长度 |
ul ~ u8 很容易理解, 表示 1到8 字节的无符号数;
si ~ s8 表示 1到8 字节的有符号数;
sleb128、uleb128、uleb128pl 则是 DEX 文件中特有的 LEB128 数据类型。
3.1.1 LEB128
每个 LEB128 由 1~5 字节组成, 所有的字节组合在一起表示一个 32 位的数据,如下图所示,每个字节只有 7 位为有效位,如果第 1 个字节的最高位为 1, 表示 LEB128 需要使用第 2 个字节,如果第 2 个字节的最高位为 1, 表示会使用第 3 个字节, 依此类推,直到最后一个字节的最高位为 0 为止。当然, LEB128 最多使用 5 字节,如果读取 5 字节后下一个字节的最高位仍为 1, 则表示该 DEX 文件无效,Dalvik 虚拟机在验证 DEX 文件时会失败并返回。

在 Android 系统源码文件 dalvik/libdex/Leb128.h 中可以找到 LEB128 的实现。 读取无符号LEB128 (uleb128) 数据 的代码如下:
DEX_INLINE int readUnsignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result > 0x7f) { // 大于 0x7f, 表示第 1 个字节最高位为 1
int cur = *(ptr++); // 第 2 个字节
result = (result & 0x7f) | ((cur & 0x7f) << 7); // 前 2 个字节的组合
if (cur > 0x7f) { // 大于 0x7f, 表示第 2 个字节最高位为 1
cur = *(ptr++); // 第 3 个字节
result |= (cur & 0x7f) << 14; // 前 3 个字节的组合
if (cur > 0x7f) { // 大于 0x7f, 表示第 3 个字节最高位为 1
cur = *(ptr++); // 第 4 个字节
result |= (cur & 0x7f) << 21; // 前 4 个字节的组合
if (cur > 0x7f) { // 大于 0x7f, 表示第 4 个字节最高位为 1
/*
* Note: We don't check to see if cur is out of
* range here, meaning we tolerate garbage in the
* high four-order bits.
*/
cur = *(ptr++); // 不检查第 5 位了,直接得到结果
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}
有符号的 LEB128 ( sleb128 ) 与无符号的 LEB128 的计算方法大致相同,区别是无符号的LEB128 的最后一个字节的最高有效位进行了符号扩展。 读取有符号 LEB128 数据 的代码 如下:
DEX_INLINE int readSignedLeb128(const u1** pStream) {
const u1* ptr = *pStream;
int result = *(ptr++);
if (result <= 0x7f) { // 小于 0x7f, 表示第 1个字节的最高 位不为 1
result = (result << 25) >> 25; // 对第 1个字节的最高 有效位进行符号扩展
} else {
int cur = *(ptr++); // 第 2 个字节
result = (result & 0x7f) | ((cur & 0x7f) << 7); // 前 2 个字节的组合
if (cur <= 0x7f) {
result = (result << 18) >> 18; // 对结果进行符号位扩展
} else { // 大于 0x7f, 表示第 2 个字节最高位为 1
cur = *(ptr++); // 第 3 个字节
result |= (cur & 0x7f) << 14; // 前 3 个字节的组合
if (cur <= 0x7f) {
result = (result << 11) >> 11; // 对结果进行符号位扩展
} else { // 大于 0x7f, 表示第 3 个字节最高位为 1
cur = *(ptr++); // 第 4 个字节
result |= (cur & 0x7f) << 21; // 前 4 个字节的组合
if (cur <= 0x7f) {
result = (result << 4) >> 4; // 对结果进行符号位扩展
} else { // 大于 0x7f, 表示第 4 个字节最高位为 1
/*
* Note: We don't check to see if cur is out of
* range here, meaning we tolerate garbage in the
* high four-order bits.
*/
cur = *(ptr++);
result |= cur << 28;
}
}
}
}
*pStream = ptr;
return result;
}
uleb128pl = uleb128 + 1。
下面以字符序列 “c0 83 92 25” 为例, 计算它的 uleb128 值:
- 第 1 个字节
0xc0大于0x7f表示需要使用第 2 个字节,即result1 = 0xc0 & 0x7f。 - 第 2 个字节
0x83大于0x7f表示需要使用第 3 个字节,即result2 = result1 + (0x83 & 0x7f) << 7。 - 第 3 个字节
0x92大于0x7f表示 需要使用第 4 个字节, 即result3 = result2 + (0x92 & 0x7f) << 14。 - 第 4 个字节
0x25小于0x7f表示到了结尾, 即result4 = result3 + (0x25 & 0x7f) << 21。
计算结果为 0x40 + 0x180 + 0x48000 + 0x4a00000 = 0x4a481c0。
再以字符序列 “d1 c2 b3 40” 为例, 计算它的 sleb128 值。
- 第 1 个字节
0xd1大于0x7f, 表示需要使用第 2 个字节,即result1 =0xdl & 0x7f。 - 第 2 个字节
0xc2大于0x7f, 表示需要使用第 3 个字节,即result2 = result 1 + (0xc2 & 0x7f) << 7。 - 第 3 个字节
0xb3大于0x7f表示需要使用第 4 个字节,即result3 = result2 + (0xb3 & 0x7f) << 14。 - 第 4 个字节
0x40小于0x7f,表示到了结尾,即result4 = ((result3 + (0x40&0x7f) << 21) << 4) >> 4。
计算结果为 ((0x51 +0x2100 + 0xcc000 + 0x8000000) << 4 ) >> 4 = 0xf80ce151。
另外要注意LEB128最后是不需要00额外结尾的。
DEX 文件是由多个结构体组合而成的。如下图所示,一个 DEX 文件由 7 个部分组成:
dex header 为 DEX 文件头,它指定了 DEX 文件的一些属性并记录了其他数据结构在 DEX 文件中的物理偏移;
string_ids 到 class_def 部分可以理解为 “ 索引结构区” ;真实的数据存放在 data 数据区中; link_data 为静态链接数据区。

DEX 文件由 DexFile 结构体表示, 其定义如下。
struct DexFile {
/* directly-mapped "opt" header */
const DexOptHeader* pOptHeader;
/* pointers to directly-mapped structs and arrays in base DEX */
const DexHeader* pHeader;
const DexStringId* pStringIds;
const DexTypeId* pTypeIds;
const DexFieldId* pFieldIds;
const DexMethodId* pMethodIds;
const DexProtoId* pProtoIds;
const DexClassDef* pClassDefs;
const DexLink* pLinkData;
/*
* These are mapped out of the "auxillary" section, and may not be
* included in the file.
*/
const DexClassLookup* pClassLookup;
const void* pRegisterMapPool; // RegisterMapClassPool
/* points to start of DEX file data */
const u1* baseAddr;
/* track memory overhead for auxillary structures */
int overhead;
/* additional app-specific data structures associated with the DEX */
//void* auxData;
};
3.1.2 DexHeader
DexOptHeader 是 ODEX 的头(后续讲解)。 DexHeader 是 DEX 文件的头部信息, 定义如下。
struct DexHeader {
u1 magic[8]; // DEX 版本标识
u4 checksum; // adler32 检验
u1 signature[kSHA1DigestLen]; // SHA-1 散列值
u4 fileSize; // 整个文件的大小
u4 headerSize; // DexHeader 结构的大小
u4 endianTag; // 字节序标记
u4 linkSize; // 链接段的大小
u4 linkOff; // 链接段的偏移量
u4 mapOff; // DexMapList 的文件偏移
u4 stringIdsSize; // DexStringld 的个数
u4 stringIdsOff; // DexStringld 的文件偏移
u4 typeIdsSize; // DexTypeld 的个数
u4 typeIdsOff; // DexTypeld 的文件偏移
u4 protoIdsSize; // DexProtoId 的个数
u4 protoIdsOff; // DexProtoId 的文件偏移
u4 fieldIdsSize; // DexFieldld 的个数
u4 fieldIdsOff; // DexFieldld 的文件偏移
u4 methodIdsSize; // DexMethodld 的个数
u4 methodIdsOff; // DexMethodld 的文件偏移
u4 classDefsSize; // DexClassDef 的个数
u4 classDefsOff; // DexClassDef 的文件偏移
u4 dataSize; // 数据段的大小
u4 dataOff; // 数据段的文件偏移
};
magic字段表示这是一个有效的 DEX 文件, 目前 它的值固定为 “64 65 78 Oa 30 33 35 00” , 转换为字符串格式为 “dex.035.” 。checksum字段为 DEX 文件的校验和, 我们可以通过它来判断 DEX 文件是否已经损坏或被篡改。signature字段用于识别未经dexopt优化的 DEX 文件。fileSize字段记录了包括DexHeader在内的整个 DEX 文件的大小。headerSize字段记录了DexHeader结构本身占用的字节数,目前它的值为 0x70。endianTag字段指定了 DEX 运行环境的 CPU 字节序, 预设值ENDIAN_CONSTANT等于0x12345678, 表示默认采用小端字节序。linkSize与linkOff字段分别指定了链接段的大小与文件偏移,在大多数情况下它们的值为 0。mapOff字段指定了DexMapList结构的文件偏移。- 接下来的字段则分别表示
DexStringld、DexTypeld、DexProtoId、DexFieldld、DexMethodld、DexClassDef及数据段的大小与文件偏移。
DexHeader 结构下面的数据是索引结构区和数据区。索引结构区中各数据结构的偏移地址都是由 DexHeader 结构的 stringldsOff ~ classDefsOff 字段的值指定的。它们并非真正的类数据,而是指向 DEX 文件的 data 数据区 ( DexData 字段,实际上是 ubyte 字节数组,其中包含程序使用的所有数据 )的偏移量或数据结构索引。
为了能更加容易地理解 DEX 文件中的各个结构,我们使用 Hello.dex 文件作为演示对象。
下载链接:https://pan.baidu.com/s/1EKvT2KK-hU9pHfQlfht5yA
提取码:4jec
Hello.java 代码如下:
public class Hello {
public int foo(int a, int b) {
return (a + b) * (a - b);
}
public static void main(String[] argc) {
Hello hello = new Hello();
System.out.println(hello.foo(5, 3));
}
}
3.1.3 DexMapList
Dalvik 虚拟机解析 DEX 文件的内容, 最 终将其映射成 DexMapList 数据结构。DexHeader 结构的 mapOff 字段指明了 DexMapList 结构在 DEX 文件中的偏 移量,它的声明如下:
struct DexMapList {
u4 size; // DexMapItem 结构的个数
DexMapItem list[1]; // DexMapItem 结构
};
struct DexMapItem {
u2 type; // kDexType 幵头的类型
u2 unused; // 未使用, 用于字节对齐
u4 size; // 指定类型的个数
u4 offset; // 指定类型数据的文件偏移
};
type 字段是一个枚举常量, 如下所示, 通过类型名称很容易就能判断它的具体类型。
enum {// 通用方式:把k, Type, Item去掉,就是对应的结构体,
kDexTypeHeaderItem = 0x0000,// 对应DexHeader
kDexTypeStringIdItem = 0x0001,// DexStringld
kDexTypeTypeIdItem = 0x0002,
kDexTypeProtoIdItem = 0x0003,
kDexTypeFieldIdItem = 0x0004,
kDexTypeMethodIdItem = 0x0005,
kDexTypeClassDefItem = 0x0006,// DexClassDef
kDexTypeMapList = 0x1000,
kDexTypeTypeList = 0x1001,
kDexTypeAnnotationSetRefList = 0x1002,
kDexTypeAnnotationSetItem = 0x1003,
kDexTypeClassDataItem = 0x2000,
kDexTypeCodeItem = 0x2001,
kDexTypeStringDataItem = 0x2002,
kDexTypeDebugInfoItem = 0x2003,
kDexTypeAnnotationItem = 0x2004,
kDexTypeEncodedArrayItem = 0x2005,
kDexTypeAnnotationsDirectoryItem = 0x2006,
};
DexMapItem 中的 size 字段指定了特定 类型的个数,它们以特定的类型在 DEX 文件中连续存放, offset 为该类型的起始文件偏移地址。
以 HelloWorld.dex 为例, 使用 010 Editor 打开它, 可 以看到DexHeader 结构的 mapOff 字段的值 656( 十六进制值为 0x90), 如下图所示:
读取 0x290 处的一个双字,值为0x0D, 表示接下来会有 13 个 DexMapItem 结构, 如下图所示:
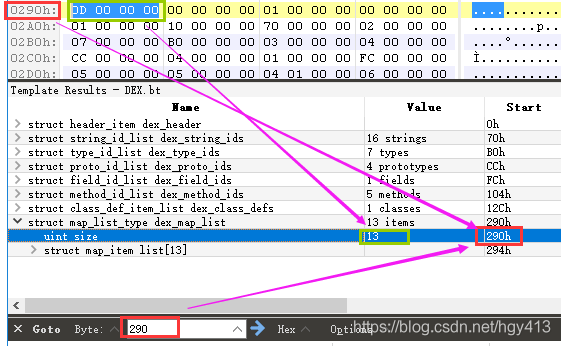
根据上面的结构描述整理出来的 13 个 DexMapItem 结构,如下表所示:
| 类型 | 个数 | 偏移量 |
|---|---|---|
| kDexTypeHeaderltem | 0x1 | 0x0 |
| kDexTypeStringldltem | 0x10 | 0x70 |
| kDexTypeTypeldltem | 0x7 | 0xb0 |
| kDexTypeProtoIdltem | 0x4 | 0xcc |
| kDexTypeFieldldltem | 0x1 | 0xfc |
| kDexTypeMethodldltem | 0x5 | 0x104 |
| kDexTypeClassDefltem | 0x1 | 0x12c |
| kDexTypeCodeltem | 0x3 | 0x14c |
| kDexTypeTypeList | 0x3 | 0x1b4 |
| kDexTypeStringDataltem | 0x10 | 0x1ca |
| kDexTypeDehuglnfoItem | 0x3 | 0x267 |
| kDexTypeClassDataltem | 0x1 | 0x27b |
| kDexTypeMapList | 0x1 | 0x290 |
对比文件头 DexHeader 部分,如下图所示,kDexTypeHeaderltem 描述 了整个 DexHeader 结构,占用了文件的前 0x70 字节的空间,而接下来的 kDexTypeStringldltem~kDexTypeClassDefItem 与DexHeader 中对应的类型及类型个数字段的值是相同的。

3.1.4 DexStringld
例如,kDexTypeStringldltem 对应于 DexHeader 的 stringldsSize 与 stringldsOff 字段, 表示在 0x70 偏移处有连续 0x10 个 DexStringld 对象。DexStringld 结构的声明如下:
struct DexStringId {
u4 stringDataOff; /* 字符串数据偏移 file offset to string_data_item */
};
从 0x70 处开始, 16 个字符串:
| DexStringld 序 号(索引) | 偏移量 | 字符串 |
|---|---|---|
| 0x0 | 0x1ca | < init> |
| 0x1 | 0x1d2 | Hello,java |
| 0x2 | 0x1de | I |
| 0x3 | 0x1e1 | III |
| 0x4 | 0x1e6 | LHello; |
| 0x5 | 0x1ef | Ljava/io/PrintStream; |
| 0x6 | 0x206 | Ljava/lang/Object; |
| 0x7 | 0x21a | Ljava/lang/System; |
| 0x8 | 0x22e | V |
| 0x9 | 0x231 | VI |
| 0xa | 0x235 | VL |
| 0xb | 0x392 | [Ljava/lang/String; |
| 0xc | 0x24e | foo |
| 0xd | 0x253 | main |
| 0xe | 0x259 | out |
| 0xf | 0x25e | println |
stringDataOff 字段指向的字符串并非普通的 ASCII 字符串,而是由 MUTF-8 编码表示 的字符串。 “MUTF-8" 是 "Modified UTF-8” 的缩写,意为 “经过修改的UTF-8 编码” 。 MUTF-8 与传统的 UTF-8 相似, 但有以下几点区别。
- MUTF-8 使用 1 ~ 3 字节编码长度。
- 对大于 16 位的 Unicode 编码 U+0x10000 ~U+0x10ffff 使用 3 字节来编码。
- 对 U+0x0000, 采用 2 字节来编码。
- 采用类似于 C 语言中的 空字符 null 作为字符串的结尾。
MUTF-8 实现代码如下:
/* return the const char* string data referred to by the given string_id */
DEX_INLINE const char* dexGetStringData(const DexFile* pDexFile,
const DexStringId* pStringId) {
// 指向 MUTF-8 字符串的指针
const u1* ptr = pDexFile->baseAddr + pStringId->stringDataOff;
// Skip the uleb128 length.
while (*(ptr++) > 0x7f) /* empty */ ;
return (const char*) ptr;
}
在 MUTF-8 字符 串的头部存放的是由 ulebl28 编码的字符的个数 ( 一定要注意,这里存放的是个数, ulebl28意味着它是1~5个不定字节 )。
例如, 字符序列 “02 e4 bd a0 e5 a5 bd 00” 头部的 “02” 表示字符串中有两个字符,“e4 bd a0” 是 UTF-8 编码字符 “你” ,“e5 a5 bd” 是 UTF-8 编码字符 “好” , 而最后的空字符“00” 是字符串的结尾 ( 不过, 计算字符个数时不包含它)。
DexStringld 列出了所有的字符串,后面的都是基于它的引用。
3.1.5 DexTypeld
接下来是 kDexTypeTypeldltem, 它对应于 DexHeader 中的 typeldsSize 与 typeldsOff 字段,指向的结构体为 DexTypeld, 声明如下。
struct DexTypeId {
u4 descriptorIdx; /* 指向 DexStringld 列表的索引 */
};
descriptorldx 为指向 DexStringld 列表的索引, 它所对应的字符串代表了具体类的类型。
注意,它指向的是前面 DexStringld 那16个字符列表的索引,参看上表和下图标出的索引:
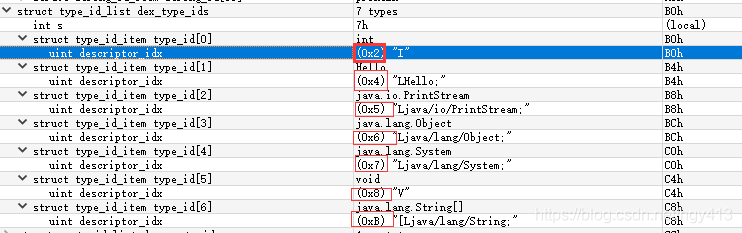
| DexTypeld 类型索引 | DexStringld 字符串索引 | 字符串 |
|---|---|---|
| 0 | 0x2 | I |
| 1 | 0x4 | LHello; |
| 2 | 0x5 | Ljava/io/PrintStream; |
| 3 | 0x6 | Ljava/lang/Object; |
| 4 | 0x7 | Ljava/lang/System; |
| 5 | 0x8 | V |
| 6 | 0xb | [Ljava/lang/String; |
3.1.6 DexProtoId
然后是 kDexTypeProtoIdltem, 它对应于 DexHeader 中的 protoIdsSize 与 protoIdsOff 字段, 指向的结构体为 DexProtoId, 声明如下。
struct DexProtoId {
u4 shortyIdx; /* 指向 DexStringld 列表的索引 */
u4 returnTypeIdx; /* 指向 DexTypeld 列表的索引 */
u4 parametersOff; /* 指向 DexTypeList 的 偏移量 */
};
DexProtoId 是一个方法声明结构体,shortyldx 为方法声明字符串,returnTypeldx 为方法返回类型字符串,parametersOff 指向一个 DexTypeList 结构体, 其中存放了方法的参数列表。
struct DexTypeList {
u4 size; /* 接下来 DexTypeltem 结构的个数 */
DexTypeItem list[1]; /* DexTypeltem 结构 */
};
DexTypeltem 结构的声明如下:
struct DexTypeItem {
u2 typeIdx; /* 指向 DexTypeld列表的索引 */
};
从 0xcc 开始,以第0个为例,如下图数据:
![]()
shortyldx = 03 00 00 00,对应前面DexStringld字符串列表中的III:
| DexStringld序 号(索引) | 偏移量 | 字符串 |
|---|---|---|
| 0x3 | 0x1e1 | III |
returnTypeldx=00 00 00 00,对应前面DexTypeld 列表中的I:
| DexTypeld类型索引 | 字符 串索引 | 字符串 |
|---|---|---|
| 0 | 0x2 | I |
parametersOff = B4 01 00 00,对应DexTypeList 的偏移, 如下图数据:
![]()
DexTypeList.size = 02 00 00 00 表示接下来有2个DexTypeItem的数据,每个DexTypeItem占用2个字节,也就是两个都是“00 00”,它们的值是DexTypeId列表的索引,我们去找一下,发现0对应的是I,两个对应字符串II。
因此这个方法的声明我们也就确定了。也就是int(int,int)(III)。
一共有 4 个 DexProtoId 结构, 如下表所示。
| DexProtoId索 引 | 方法声明 | 返 回类型 | 参数列表 |
|---|---|---|---|
| 0 | III | I | 2 个参数 I、 I |
| 1 | V | V | 无参数 |
| 2 | VI | V | 1 个参数I |
| 3 | VL | V | 1 个参数 [Ljava/lang/String; |
同时我们可以发现,方法声明由返回类型与参数列表组成, 且 返回类型 在 参数列表 的前面。
3.1.7 DexFieldld (标识了类成员)
接下来是 kDexTypeFieldldltem, 它对应于 DexHeader 中的 fieldldsSize 与 fieldldsOff 字段,指向的结构体为 DexFieldld 声明如下。
struct DexFieldId {
u2 classIdx; /* 类的类型,指向 DexTypeld 列表的索引 */
u2 typeIdx; /* 字段类型,指向 DexTypeld 列表的索引 */
u4 nameIdx; /* 字段名 ,指向 DexStringld 列表的索引 */
};
DexFieldld 结构中的数据全都是索引值, 指明了字段所在的类、 字段的类型及字段名。从0xfc 开始, 共有 1 个 DexFieldld 结构,如下图数据:
![]()
classldx = 04 00, typeIdx = 02 00, nameIdx = 0E 00 00 00, 如下表所示:
| DexTypeld 类型索引 | 字符 串索引 | 字符串 |
|---|---|---|
| 2 | 0x5 | Ljava/io/PrintStream; |
| 4 | 0x7 | Ljava/lang/System; |
| DexStringld 序 号(索引) | 偏移量 | 字符串 |
|---|---|---|
| 0xe | 0x259 | out |
==>smali表示法:Ljava/io/PrintStream;->out:Ljava/io/PrintStream;。
3.1.8 DexMethodld
接下来是 kDexTypeMethodldltem, 它对应于 DexHeader 中的 methodldsSize 与 methodldsOff 字段, 指向的结构体 DexMethodld, 声明如下。
struct DexMethodId {
u2 classIdx; /* 类的类型,指向 DexTypeld 列表的索引 */
u2 protoIdx; /* 声明类型,指向 DexProtoId 列表的索引 */
u4 nameIdx; /* 方法名 ,指向 DexStringld 列表的索引 */
};
DexMethodld 结构中的数据也都是索引值, 指明了方法所在的类、 方法的声 明及方 法名。从0x104 处开始, 共有 5 个 DexMethodld 结构, 如下表所示。
| DexMethodld 索引 | 类的类型 | 方法声明 | 方法名 | 方法全称 |
|---|---|---|---|---|
| 0 | LHello; | V | < init> | void.Hello.< init>() |
| 1 | LHello; | III | foo | int Hello.foo(int,int) |
| 2 | LHello; | VL | main | void Hello.main(java.lang.String[]) |
| 3 | Ljava/io/PrintStream; | VI | println | void java.io.PrintStream.println(int) |
| 4 | Ljava/lang/Ohject; | V | < init> | void java.lang.Object.< init>() |
3.1.9 DexClassDef
接下来是 kDexTypeClassDefltem, 它对应于 DexHeader 中的 classDefsSize 与 classDefsOff 字段, 指向的结构体DexClassDef, 声明如下。
struct DexClassDef{
u4 classIdx; /*类的类型,指向DexTypeId列表的索引*/
u4 accessFlags; /*访问标志*/
u4 superclassIdx; /*父类类型,指向DexTypeId列表的索引*/
u4 interfacesOff; /*接口,指向DexTypeList的偏移*/
u4 sourceFileIdx; /*源文件名,指向DexStringId列表的索引*/
u4 annotationsOff; /*注解,指向DexAnnotationsDirectoryItem结构*/
u4 classDataOff; /*指向DexClassData结构的偏移*/
u4 staticValuesOff; /*指向DexEncodedArray结构的偏移*/
}
DexClassDef 比前面介绍的结构要复杂一些。
classldx 字段是一个索引值,表示类的类型。
accessFlags 字段是类的访问标志,是一个以 ACC_开头的枚举值。
superclassldx 字段是父类类型索引值, 如果类中含有接口声明或实现,interfacesOff 字段会指向一个 DexTypeList 结构, 否则这里的值为 0。
sourceFileldx 字段是字符串索引值, 表示类所在源文件的名称。
annotationsOff 字段指向注解目录结构,根据类型的不同,会有注解类、注解方法、注解字段及注解参数, 如果类中没有注解,则这里的值为 0。
classDataOff 字段指向 DexClassData 结构, 它是类的数据部分。
staticValuesOff 字段指向 DexEncodedArray 结构, 其中记录了类中的静态数据。
DexClassData 结构的声明如下。
struct DexClassData{
DexClassDataHeader header; /*指定字段与方法的个数*/
DexField* staticFields; /*静态字段,DexField结构*/
DexField* instanceFields; /*实例字段,DexField结构*/
DexMethod* directMethods; /*直接方法,DexMethod结构*/
DexMethod* virtualMethods; /*虚方法,DexMethod结构*/
}
DexClassDataHeader 结构记录了当前类中字段和方法的数目, 它的声明如下。
struct DexClassDataHeader{
u4 staticFieldsSize; /*静态字段个数*/
u4 instanceFieldsSize; /*实例字段个数*/
u4 directMethodsSize; /*直接方法个数*/
u4 virtualMethodsSize; /*虚方法个数*/
}
DexClassDataHeader 的 结构与 DexClassData —样,都是在 DexClass.h 文件中声明的,为什么不在 DexFile.h 文件中声 明呢?它们可都是 DexFile 文件结构 的一部分啊!这是因为 DexClass.h中的u4 = uleb128, 而DexFile.h中的u4 = uint32_t。
DexField 结构描述了字段的类型与访问标志,它的结构声明如下。
struct DexField {
u4 fieldIdx; /* 指向 DexFieldld 的索引 */
u4 accessFlags; /* 访问标志 */
};
fieldldx 字段为指向 DexFieldld 的 索引。accessFlags 字段与 DexClassDef 中相应字段的类型相同。
DexMethod 结构描述了方法的原型、 名称、 访问标志及代码数据块, 它的结构声明如下。
struct DexMethod {
u4 methodIdx; /* 指向 DexMethodld 的索引 */
u4 accessFlags; /* 访问标志 */
u4 codeOff; /* 指向 DexCode 结构的偏移量 */
};
methodldx 字段为指向 DexMethodld 的 索引。accessFlags 字段为访问标志。codeOff 字段指向一个 DexCode 结构体,该结构体描述了方法的详细信息及方法中指令的 内容。 DexCode 结构体的声明如下, DexCode 定义位于DexFile.h中。
struct DexCode {
u2 registersSize; // 使用的寄存器的个数
u2 insSize; // 参数的个数
u2 outsSize; // 调用其他方法时使用的寄存器的个数
u2 triesSize; // try/catch 语句的个数
u4 debugInfoOff; /* 指向调试信息的偏移量 */
u4 insnsSize; /* 指令集的个数,以2 字节为单位 */
u2 insns[1]; // 指令集
/* 2字节空间用于结构对齐 */
/* followed by try_item[triesSize], DexTry 结构*/
/* followed by uleb128 handlersSize */
/* followed by catch_handler_item[handlersSize] */
};
通过层层分析, 我们终于看到存放指令集的结构体了。
registersSize 字段指定了方法中使用的寄存器的个数,对应smali语法中的 .registers 指令。
insSize 字段指定了方法的参数的个数,对应于 smali语法中的 .paramter 指令。
outsSize 字段指定了方法在调用外部方法时使用的寄存器的个数。
我们可以这样理解 :现在有一个方法, 使用了 5 个寄存器,其中有 2 个为参数,而该方法调用了另一个方法,后者使用了 20 个寄存器,那么, Dalvik 虚拟机在分配时, 会在分配自身方法寄存器空间时加上那 20 个寄存器空间。 triesSize 字段指定了方法中 try/catch 语句的个数, 如果 DEX 文件中保留了调试 信息,debuglnfoOff 字段会指向它。 调试信息的解码函数为 dexDecodeDebugInfo() 。insnsSize 字段指定了接下来的指令的个数。insns 字段为真正的代码部分。
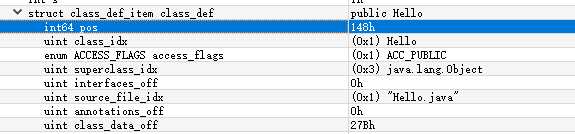
从 0x12c 处开始,共有 1 个 DexClassDef 结构, 下面我们来分析它, 如下图:

classIdx = 01 00 00 00, 指定的字符串为 “LHello;”(类名), 如下:
| DexTypeld 类型索引 | 字符 串索引 | 字符串 |
|---|---|---|
| 1 | 0x4 | LHello; |
accessFlags = 01 00 00 00, 访问标志为ACC_PUBLIC。
superclassIdx = 03 00 00 00, 指向的字符串为 “Ljava/lang/Object;” (这是 Hello 的父类名), 如下:
| DexTypeld 类型索引 | 字符 串索引 | 字符串 |
|---|---|---|
| 3 | 0x6 | Ljava/lang/Object; |
interfacesOff = 00 00 00 00, 表示没有接口。
sourceFileIdx = 01 00 00 00, 指向的字符串为 “Hello.java” (这是类的源文件名 ), 如下:
| DexStringld 序 号(索引) | 偏移量 | 字符串 |
|---|---|---|
| 0x1 | 0x1d2 | Hello,java |
annotationsOff = 00 00 00 00,表示没有注解。
classDataOff = 7B 02 00 00 = 0x27b, 指向 DexClassData 结构。
staticValuesOff = 00 00 00 00, 表示没有静态值。
从 0x27b 处开始,u首先读取DexClassData 结构中的 DexClassDataHeader 结构, 发现其为 4 个 ulebl28 值, 结果分别为 0、 0、2、1, 这表示该类不含字段, 有两个直接方法和一个虚方法。
由于类中不含字段,DexClassData 结构中的两个 DexField 结构也就没用了。从 0x27f 处开始直接解析 DexMethod 。
methodIdx = 0,指向的 DexMethodld 为第 0 条, 也就是< init> 方法, 如下:
| DexMethodld 索引 | 类的类型 | 方法声明 | 方法名 | 方法全称 |
|---|---|---|---|---|
| 0 | LHello; | V | < init> | void.Hello.< init>() |
accessFlags = “81 80 04” = 0x10001, 访问标志为 ACC_PUBLIC | ACC_CONSTRUCTOR。
codeOff = “cc 02” = 0x14c, 指向 DexCode 结构。
从 0x14c 处开始解析 DexCode结构。

registersSize = 01 00, 1个寄存器。
insSize = 01 00, 1个参数。
outsSize = 01 00,调用其他方法时使用的寄存器的个数为1。
triesSize = 00 00,没有 try/catch 语句。
debugInfoOff = 67 02 00 00,指向调试信息的偏移量。
insnsSize = 04 00 00 00, 方法中有 4 条指令。
insns = “7010 0400 0000 0e00” 为4条指令的具体。
3.2 DEX 文件的验证与优化过程
只有了解 DEX 文件的验证与优化过程, 才能知道 DEX 文件头结构 DexHeader 中 checksum 与 signature 字段的计算过程,也才能在修改 DEX 文件后对这两个字段进行修正。
为了使 Android 程序在 Dalvik 虚拟机中快速、 顺畅地运行,有必要对 DEX 文件进行验证与优化, Android 提供了一个专门验证与优化 DEX 文件的工具 dexopt, 它的源码位于 Android 系统源码的dalvik/dexopt 目录下, Dalvik 虚拟机在加载一个 DEX 文件时, 通过指定的验证与优化选项来调用 dexopt 进行相应的验证与优化操作。
dexopt 的主程序代码为 OptMain.cpp, 其中,处理 apk/jar/zip 中的 classes.dex 文件的函数为extractAndProcessZip()。
extractAndProcessZip() 函数先通过 dexZipFindEntry() 函数检查目标文件中是否有 classes.dex, 如果没有, 程序失败并返回。
如果有, 就调用 dexZipGetEntryInfo() 函数来读取 classes.dex 的时间戳与 CRC 校验值。
接着调用 dexZipExtractEntryToFile() 函数释放 classes.dex 为缓存文件, 然后解析传递过来的验证与优化选项。
验证选项用“v=” 指出, 优化选项用“o=”指出。
做完所有的准备工作后, 调用 dvmPrepForDexOpt 函数, 启动一个虚拟机进程。在这个 函数中 , 优化选项 dexOptMode 与验证选项 verifyMode 被传递到全局 DvmGlobals 结构 gDvm 的 dexOptMode 与classVerifyMode 字段中。
这时,所有的初始化工作完成,dexopt 调用 dvmContinueOptimization() 函数, 开始进行真正的验证与优化工作, 代码如下:
static int extractAndProcessZip(int zipFd, int cacheFd,
const char* debugFileName, bool isBootstrap, const char* bootClassPath,
const char* dexoptFlagStr)
{
....
// 1.检查目标文件中是否有 classes.dex
zipEntry = dexZipFindEntry(&zippy, kClassesDex);
if (zipEntry == NULL) {
ALOGW("DexOptZ: zip archive '%s' does not include %s", debugFileName, kClassesDex);
goto bail;
}
// 2.读取 classes.dex 的时间戳与 CRC 校验值
if (dexZipGetEntryInfo(&zippy, zipEntry, NULL, &uncompLen, NULL, NULL,
&modWhen, &crc32) != 0)
{
ALOGW("DexOptZ: zip archive GetEntryInfo failed on %s", debugFileName);
goto bail;
}
uncompLen = uncompLen;
modWhen = modWhen;
crc32 = crc32;
// 3.释放 `classes.dex` 为缓存文件,
if (dexZipExtractEntryToFile(&zippy, zipEntry, cacheFd) != 0) {
ALOGW("DexOptZ: extraction of %s from %s failed", kClassesDex, debugFileName);
goto bail;
}
// 4.然后解析传递过来的验证与优化选项,验证选项用`“v=”` 指出, 优化选项用`“o=”`指出
if (dexoptFlagStr[0] != '\0') {
...
}
// 5. 启动一个虚拟机进程
if (dvmPrepForDexOpt(bootClassPath, dexOptMode, verifyMode,
dexoptFlags) != 0)
{
ALOGE("DexOptZ: VM init failed");
goto bail;
}
// 6.开始进行真正的验证与优化工作
if (!dvmContinueOptimization(cacheFd, dexOffset, uncompLen, debugFileName,
modWhen, crc32, isBootstrap))
{
ALOGE("Optimization failed");
goto bail;
}
/* we don't shut the VM down -- process is about to exit */
result = 0;
bail:
dexZipCloseArchive(&zippy);
return result;
}
dalvik/vm/analysis/DexPrepare.cpp中实现了dvmContinueOptimization()函数。该函数首先对 DEX 文件进行简单的检查,确保传递进来的目标文件属于 DEX 或 ODEX。接着调用 mmap() 函数将整个文件映射到内存中,然后根据 gDvm 的 dexOptMode 与 classVerifyMode 字段来设置 doVerify 与 doOpt 两个布尔值,
调用 rewriteDex() 函数来重写 DEX 文件 ( 重写内容包 括字节序调整、结构重新对齐、类验证信息及辅助数据)。
rewriteDex() 函数调用 dexSwapAndVerify() 调整字节序,调用 dvmDexFileOpenPartial() 创建 DexFile 结构。
dvmDexFileOpenPartial() 函数的实现在Android 系统源码文件 dalvik/vm/DvmDex.cpp 中, 该函数调用 dexFileParse() 函数解析 DEX文件。
dexFileParse() 函数的实现在Android 系统源码文件dalvik/libdex/DexFile.cpp。该函数读取 DEX 文件头,并根据需要, 调用 dexComputeChecksum() 函数来验证 DEX 文件头的 checksum 字段,或者调用 dexComputeOptChecksum() 函数来验证 ODEX 文件头的checksum 字段。 代码片段如下:
if (flags & kDexParseVerifyChecksum) {
u4 adler = dexComputeChecksum(pHeader);
if (adler != pHeader->checksum) {
ALOGE("ERROR: bad checksum (%08x vs %08x)",
adler, pHeader->checksum);
if (!(flags & kDexParseContinueOnError))
goto bail;
} else {
ALOGV("+++ adler32 checksum (%08x) verified", adler);
}
const DexOptHeader* pOptHeader = pDexFile->pOptHeader;
if (pOptHeader != NULL) {
adler = dexComputeOptChecksum(pOptHeader);
if (adler != pOptHeader->checksum) {
ALOGE("ERROR: bad opt checksum (%08x vs %08x)",
adler, pOptHeader->checksum);
if (!(flags & kDexParseContinueOnError))
goto bail;
} else {
ALOGV("+++ adler32 opt checksum (%08x) verified", adler);
}
}
}
dexComputeChecksum( ) 函数的代码如下:
u4 dexComputeChecksum(const DexHeader* pHeader)
{
const u1* start = (const u1*) pHeader;
uLong adler = adler32(0L, Z_NULL, 0);
const int nonSum = sizeof(pHeader->magic) + sizeof(pHeader->checksum);
return (u4) adler32(adler, start + nonSum, pHeader->fileSize - nonSum);
}
可以发现, checksum 实际上是调用 adler32() 来完成计算的,整个计算步骤也很清楚:跳过 DexHeader 的 magic 与 checksum 字段, 将第 3 个字段到文件的结尾作为计算的总数据长度,调用 Adler32 标准算法计算数据的 adler 值。
因为checksum没有跳过signature,所以我们要先计算下面的signature,再算checksum
dexComputeOptChecksum( ) 函数的代码如下:
u4 dexComputeOptChecksum(const DexOptHeader* pOptHeader)
{
const u1* start = (const u1*) pOptHeader + pOptHeader->depsOffset;
const u1* end = (const u1*) pOptHeader +
pOptHeader->optOffset + pOptHeader->optLength;
uLong adler = adler32(0L, Z_NULL, 0);
return (u4) adler32(adler, start, end - start);
}
ODEX 的 checksum 计算方法与 DEX 的 checksum 计算方法一样,只是其取值范围是从 ODEX
文件头到最后的依赖库与辅助数据两个数据块。
下一步是验证 signature, 代码如下:
if (kVerifySignature) {
unsigned char sha1Digest[kSHA1DigestLen];
const int nonSum = sizeof(pHeader->magic) + sizeof(pHeader->checksum) +
kSHA1DigestLen;
dexComputeSHA1Digest(data + nonSum, length - nonSum, sha1Digest);
if (memcmp(sha1Digest, pHeader->signature, kSHA1DigestLen) != 0) {
char tmpBuf1[kSHA1DigestOutputLen];
char tmpBuf2[kSHA1DigestOutputLen];
ALOGE("ERROR: bad SHA1 digest (%s vs %s)",
dexSHA1DigestToStr(sha1Digest, tmpBuf1),
dexSHA1DigestToStr(pHeader->signature, tmpBuf2));
if (!(flags & kDexParseContinueOnError))
goto bail;
} else {
ALOGV("+++ sha1 digest verified");
}
}
验证算法是: 跳过 magic、 checksum 与 signature 字段,调用 dexComputeSHAlDigest()方法对
DEX 头部后面的数据进行 SHA-1 计算,然后将计算结果与 signature 字段中保存的值进行比较,
如果相等就通过,如果不相等则验证失败。
dexComputeSHAlDigest () 方法 的代码如下:
static void dexComputeSHA1Digest(const unsigned char* data, size_t length,
unsigned char digest[])
{
SHA1_CTX context;
SHA1Init(&context);
SHA1Update(&context, data, length);
SHA1Final(digest, &context);
}
这是 OpenSSL 库标准中计算 SHA-1 散列值的接口。
回到分析流程。 验证成功后, dvmDexFileOpenPartial() 调用 allocateAuxStructures() , 设置与 DexFile 结构辅助数据相关的字段,执行后返回 rewriteDex() 函数。 接着,rewriteDex() 调用loadAllClasses(), 加载 DEX 文件中所有的类 ( 如果这一步失败了,程序等不到后面的优化与验证就退出了 ; 如果执行这一步时没有发生错误,程序会调用 verifyAndOptimizeClasses() 函数来完成真正的验证工作)。 loadAllClasses() 函数会调用 verifyAndOptimizeClass( ) 函数来优化与验证具体的类, 而 verifyAndOptimizeClass() 函数会细分这些工作, 先调用 dvmVerifyClass( ) 函 数进行验证, 再调用 dvmOptimizeClass() 函数进行优化。
dvmVerifyClass() 函数的实现代码位于 Android 系统源码文件 dalvik/vm/analysis/DexVerify.cpp中。 这个函数调用 verifyMethod() 函数对类的所有直接方法和虚方法进行验证。
bool dvmVerifyClass(ClassObject* clazz)
{
int i;
if (dvmIsClassVerified(clazz)) {
ALOGD("Ignoring duplicate verify attempt on %s", clazz->descriptor);
return true;
}
for (i = 0; i < clazz->directMethodCount; i++) {
if (!verifyMethod(&clazz->directMethods[i])) {
LOG_VFY("Verifier rejected class %s", clazz->descriptor);
return false;
}
}
for (i = 0; i < clazz->virtualMethodCount; i++) {
if (!verifyMethod(&clazz->virtualMethods[i])) {
LOG_VFY("Verifier rejected class %s", clazz->descriptor);
return false;
}
}
return true;
}
verifyMethod() 函数的具体工作是:先调用 verifylnstructions() 函数来验证方法中的指令及其数目的正确性,再调用 dvmVerifyCodeFlow() 函数来验证代码流的正确性。
dvmOptimizeClass() 函数的实现代码位于 Android 系统源码文件 dalvik/vm/analysis/Optimize.cpp 中。 这个函数调用 optimizeMethod() 函数对类的所有直接方法和虚方法进行优化,优化的主要工作是进行指令替换, 替换的优先级为: volatile 替换最高, 正确性替换其次,高性能替换最低。例如, iget-wide 指令会根据优先级被替换为 volatile 形式的 iget-wide-volatile , 而不是高性能的iget-wide-quick。
rewriteDex() 函数返回后, 会再次调用 dvmDexFileOpenPartial() 函数来验证 ODEX 文件, 并接着调用 dvmGenerateRegisterMaps() 函数来填充辅助数据区的结构。 完成对结构的填充后,会调用 updateChecksum() 函数重写 DEX 文件的 checksum 值。
static void updateChecksum(u1* addr, int len, DexHeader* pHeader)
{
/*
* Rewrite the checksum. We leave the SHA-1 signature alone.
*/
uLong adler = adler32(0L, Z_NULL, 0);
const int nonSum = sizeof(pHeader->magic) + sizeof(pHeader->checksum);
adler = adler32(adler, addr + nonSum, len - nonSum);
pHeader->checksum = adler;
}
3.3 DEX 文件的修改
利用IDA Pro给DEX文件打补丁,参考 IDA修改二进制文件、显示修改点, 记得使用Apply patches to input file保存改动。
修改后的 DEX, 其 DexHeader 头部的 checksum 与 signature 字段是错误的,需 要进行修正。
-
使用
010 Editor编辑器,配合 DexFixer.lsc 脚本功能,即可完成对 DEX 的 修改。 -
使用
dex2jar提供的工具d2j-dex-recompute-checksum, 在cmd下执行如下命令:
d2j-dex-recompute-checksum.bat -f classes.dex
会自动生成classes-rechecksum.dex文件。
将修正后的 "classes.dex"重新打包进 APK 文件中并进行签名,就可以完成修改。
4. AndroidManifest.xml(AXML 文件格式)
点击下载测试使用的Androidmanifest.xml
Android Studio 在编译 APK 文件时,会将 AndroidManifest.xml 处理后打包进去,打包进去的AndroidManifest.xml 被编译成了二进制格式的文件, 这种格式称为 “AXML 文件格式”。
APK 使用 AXML 而非纯文本格式 XML 来存放数据, 其主要目的应该是解决 APK 加载时的性能问题。
Android 官方并没有明确给出 AXML 的二进制布局规范, 但我们可以通过阅读 APK 打包流程与系统加载 APK 的代码来掌握它的文件格式。
在 Android 系统源码文件 frameworks/base/include/androidfw/ResourceTypes.h 中列举了 AXML 使用的大部分数据结构与常量定义。
在学习 AXML 文件格式的过程中, 在了解数据结构的同时, 可以使用 010 Editor 编辑器的 AXML 文件格式解析模板 AXMLTemplate.bt 进行辅助分析。
AXML 文件格式简图,如下所示,数据块用 chunk (块)表示。 从整体结构上看, 一个 AXML 文件由文件头 ResFileheader、 字符串池 ResStringPool 、资源 ID 块 ResIDs、 XML 数据内容块 ResXMLTree 四部分线性地组成。

4.1 Header
ResFileheader 表示文件的头部, 在这里用 ResChunk_header 表示。ResChunk_header 除了在文件开头表示文件头, 还用于表示其他 chunk 的头部信息。ResChunk_header的定义如下。
struct ResChunk_header
{
uint16_t type;
uint16_t headerSize;
uint32_t size;
};
type 字段描述了 chunk 所属结构体的类型,它的取值如下:
enum {
RES_NULL_TYPE = 0x0000,
RES_STRING_POOL_TYPE = 0x0001,
RES_TABLE_TYPE = 0x0002,
RES_XML_TYPE = 0x0003,
// Chunk types in RES_XML_TYPE
RES_XML_FIRST_CHUNK_TYPE = 0x0100,
RES_XML_START_NAMESPACE_TYPE= 0x0100,
RES_XML_END_NAMESPACE_TYPE = 0x0101,
RES_XML_START_ELEMENT_TYPE = 0x0102,
RES_XML_END_ELEMENT_TYPE = 0x0103,
RES_XML_CDATA_TYPE = 0x0104,
RES_XML_LAST_CHUNK_TYPE = 0x017f,
// This contains a uint32_t array mapping strings in the string
// pool back to resource identifiers. It is optional.
RES_XML_RESOURCE_MAP_TYPE = 0x0180,
// Chunk types in RES_TABLE_TYPE
RES_TABLE_PACKAGE_TYPE = 0x0200,
RES_TABLE_TYPE_TYPE = 0x0201,
RES_TABLE_TYPE_SPEC_TYPE = 0x0202,
RES_TABLE_LIBRARY_TYPE = 0x0203
};
对文件头来说,type 字段的值固定为 RES_XML_TYPE(0x3) , 表示这是一个 AXML 文件。
header_size 字段表示当前 ResChunk_header 结构的大小,它的值固定是 0x8。在一些 AXML 文件格式的描述文档中, 使用一个 4 字节的字段 magic 来表示 type 与 header_size 字段 ( 其效果是一样的)。
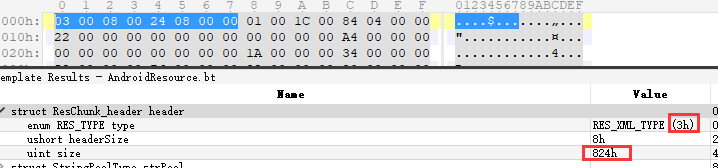
file_size 字段表示该 chunk 结构体数据的长度,它包含当前 ResChunk_header 结构体的 8 字节,因此在实际计算数据大小时需要减去 8 字节 (对第 1 个 ResChunk_header 结构来说, file_size 表示文件的总长度 )。对于第一个chunk,0x824表示AndroidManifest.xml文件的总长度, 如下图:
4.2 String Chunk
紧接在文件头之后是字符串池 ResStringPool, 它包含了 AXML 中使用的所有字符串。 字符串池由字符串池头 ResStringPool_header、字符串偏移列表、 字符串列表、 样式列表(基本为空)四部分组成。
struct ResStringPool_header
{
struct ResChunk_header header;
// Number of strings in this pool (number of uint32_t indices that follow
// in the data).
uint32_t stringCount;
uint32_t styleCount;
enum {
SORTED_FLAG = 1<<0,
UTF8_FLAG = 1<<8
};
uint32_t flags; // 这里固定为0
uint32_t stringsStart;
uint32_t stylesStart;
};
header 字段的结构与文件中的第 1 个 ResChunk_header —样,只是这里的 type 不同。 其取值固定为 RES_STRING_POOL_TYPE(0x1), 表示这个 chunk 是一个字符串池。
stringCount 与 styleCount 字段分别表示这个池中字符串的数目与样式的数目,styleCount一般为0。
flags 字段用于标识字符串的类型是 UTF-8 还是 16 位编码, 默认为0,表示使用 16 位编码字符串。
特别注意:下面所有涉及到偏移值的,都是以当前
chunk的偏移做为起始,所以在计算时都需要加上前面的字节数
比如ResStringPool_header内的所有偏移都需要加8个字节(ResStringPool_header起始偏移是0x8)
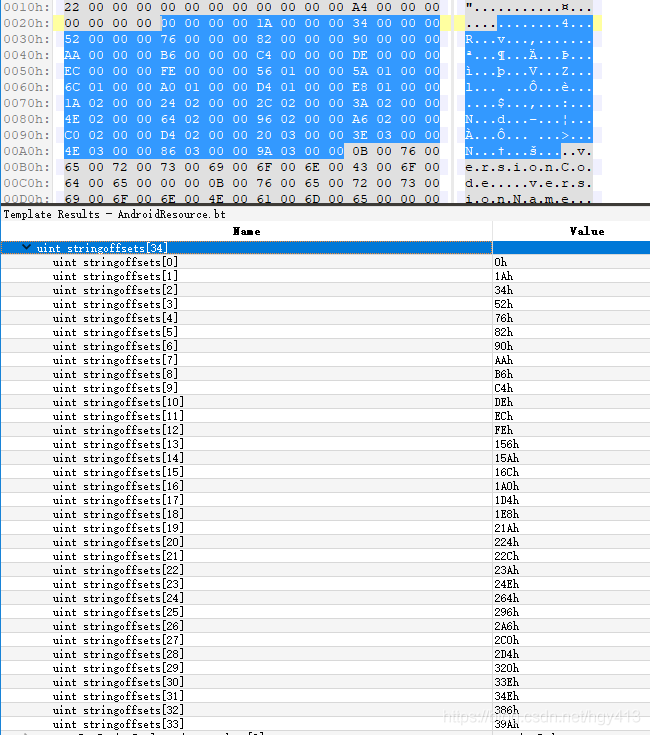
styleCount和stylesStart总是为0,所以可以无视。stringsStart 表示字符串列表在文件中的偏移量, 如下图所示:stringsStart=0xA4, stringCount=0x22, flags = 0。

紧挨着的是字符串偏移的索引列表,每条索引都使用ResStringPool_string 结构体来表示, 定义如下。
struct ResStringPool_string
{
uint32_t index;
};
index 字段指向字符串在文件中的具体偏移量,注意是相对于 ResStringPool_header 的开始处, 其指向的内容可能是一个 UTF-8 字符串,也可能是一个 16 位编码字符串 (这依赖于前面的 flags 字段)。
因为 stringCount=0x22, 所以在ResStringPool_header之后紧跟着0x22个ResStringPool_string。如下所示:
目前, AXML 文件没有使用样式,所有关于样式的实际数据部分都为 0 或空值, 而AndroidManifest.xml中字符串数据默认都使用的是 16 位编码字符串(flags = 0), 所以字符串中的每个字符使用双字节来表示, 在字符串开头使用 16 位来表示字符串的长度。
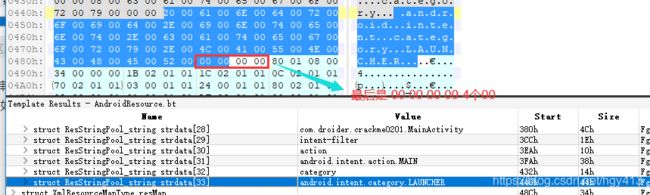
stringsStart=0xA4, 所以起始字符串偏移是0xA4+0x8=0xAC(ResStringPool_header起始偏移是0x8)。具体的字符串列表如下图:


字符串的最后结束处是0x484+0x8 = 0x48C(前面提到过必须加8字节)。可以看出最后一个字符是以00 00 00 00 结尾的, 如下图:
4.3 ResourceId Chunk
紧接着是资源 ID 块 ResIDs。 这部分主要用于存放 AndroidManifest.xml 使用的系统属性值所对应的资源 ID, 结构定义如下。
typedef struct {
ResChunk_header header;
//int count;
uint ids[count];
} ResIDs;
header 字段的 type 在这里是 RES_XML_RESOURCE_MAP_TYPE(0x180) ,表示这是资源表。
count 字段表示资源 ID 的个数。
ids 字段中存放的是一个个资源 ID。 每个资源 ID 都是一个 32 位的整型值, 它由三部分组成, 使用十六进制表示为 “0xpptteeee” 。“pp” “tt” “eeee” 分别表示资源 ID 的 Package ID index ( 包 ID 索引 )、 Type ID index ( 类型 ID 索引 )、Entry ID index( 条目ID 索引) 。
- Package ID 相当于一个命名空间, 用于限定资源的来源。 Android 系统目前定义了两个资源命名空间: 一个是系统资源命名空间, 它的 Package ID 等于
0x01, 例如 Application 标签的android :allowBackup属性的 Package ID 就是0x01; 另一个是应用程序资源命令空间, 它的 Package ID 等于0x7f, 例如程序中 R.java 中的资源 ID。 - Type ID 表示资源的类型 ID。 资源的类型包括 attr、 id、 style、 anim、 color、 drawable、layout、menu、 raw、 string、xml 等, 每种类型都会被赋予一个 ID。 ID 的 取值从 1 开始, 0 表示无效, 例如 0x1 表示 attr、 0x2 表示 id、 0x9 表示 layout。
- Entry ID 指明了每一个资源在其所属的资源类型中的索引位置。
所有系统资源命名空间的资源 ID 都可以在 Android 源码文件 frameworks/base/core/res/res/values/public.xml 中找到。例如, 0x01010280 在 public.xml 中的定义如下:
<public type="attr" name="allowBackup" id="0x01010280" />
以上定义表示它是一个名为 “allowBackup” 的属性值。
如下图:

注意上图中并没有count,count是这样计算的:ResChunk_header.size = 0x34h = 54, 再减去ResChunk_header自身的8字节,再除以4得到count = (54 - 8)/4 = 11。
4.4 XmlContent Chunk
接下来是 ResXMLTree, 它用于表示 XML 文件的具体内容。 它是一个线性的 XML 节点数据集合,由多个 XML 节点数据组成, 每个 XML 节点数据由基本结构体 ResXMLTree_node 和扩展结构体组成。
ResXMLTree_node 的定义如下:
struct ResXMLTree_node
{
struct ResChunk_header header;
// Line number in original source file at which this element appeared.
uint32_t lineNumber;
// Optional XML comment that was associated with this element; -1 if none.
struct ResStringPool_ref comment;
};
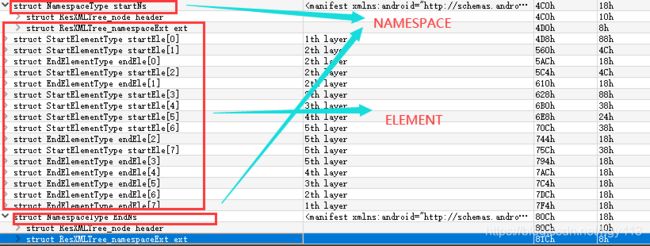
对第 1 个节点来说,header 的 type 字段必须是 RES_XML_START_NAMESPACE_TYPE(0x0100),表示这是一个 namespace 开始节点。
与此对应的是 ResXMLTree 部分的最后一个 ResXMLTree_node, 它的 header 的 type 字段必须是 RES_XML_END_NAMESPACE_TYPE(0x0101), 表示 namespace 节点的结束。
如下所示:

lineNumber 字段表示节点数据在 AndroidManifest 文件中的行号,占用 4 字节。
comment 字段表示节点数据关联的注释内容, 它的结构是 ResStringPool_ref, 定义如下:
struct ResStringPool_ref
{
// Index into the string pool table (uint32_t-offset from the indices
// immediately after ResStringPool_header) at which to find the location
// of the string data in the pool.
uint32_t index;
};
index 字段是字符串在字符串池中的偏移索引。如果节点数据没有对应的注释, comment 字段取值-1(FFFFFFFFh),如上图所示。
对类型为 RES_XML_START_NAMESPACE_TYPE 与 RES_XML_END_NAMESPACE_TYPE的节点数据来说, 它的扩展结构体用 ResXMLTree_namespaceExt 表示,定义如下:
/**
* Extended XML tree node for namespace start/end nodes.
* Appears header.headerSize bytes after a ResXMLTree_node.
*/
struct ResXMLTree_namespaceExt
{
// The prefix of the namespace.
struct ResStringPool_ref prefix;
// The URI of the namespace.
struct ResStringPool_ref uri;
};
prefix 字段表示 namespace 的 前缀, 对 AXML 来说,它的值通常是 “android” 。 uri 字段表示 namespace 的 URI, 对 AXML 来说, 它的值通常是 “http://schemas.android.com/apk/res/android” , 如下图:

具体的对应字符串列表如下图(0xBh = 11, 0xCh = 12):
![]()
在 RES_XML_START_NAMESPACE_TYPE(0x0100) 与 RES_XML_END_NAMESPACE_TYPE(0x0101)类型的节点数据中间是一系列以 RES_XML_START_ELEMENT_TYPE(0x0102) 开头且以 RES_XML_END_ELEMENT_TYPE(0x0103) 结束的成对的 ResXMLTree_node节点数据。 这些节点数据虽然可以嵌套, 但必须成对出现, 与 XML的解析语法格式一样。
RES_XML_START_ELEMENT_TYPE(0x0102) 类型的节点数据表示一个节点 TAG 的开始。它除了可以包含多个子 TAG, 还可以包含多个属性值。它的扩展结构部分用 ResXMLTree_attrExt 表示, 定义如下:
struct ResXMLTree_attrExt
{
// String of the full namespace of this element.
struct ResStringPool_ref ns;
// String name of this node if it is an ELEMENT; the raw
// character data if this is a CDATA node.
struct ResStringPool_ref name;
// Byte offset from the start of this structure where the attributes start.
uint16_t attributeStart;
// Size of the ResXMLTree_attribute structures that follow.
uint16_t attributeSize;
// Number of attributes associated with an ELEMENT. These are
// available as an array of ResXMLTree_attribute structures
// immediately following this node.
uint16_t attributeCount;
// Index (1-based) of the "id" attribute. 0 if none.
uint16_t idIndex;
// Index (1-based) of the "class" attribute. 0 if none.
uint16_t classIndex;
// Index (1-based) of the "style" attribute. 0 if none.
uint16_t styleIndex;
};
ns 与 name 字段分别表示节点数据所在的 namespace 与节点的名称。
attributeStart 字段表示属性的初始地址,它的位置是相对于本结构体ResXMLTree_attrExt的文件偏移。
attributeSize 字段表示单个属性的大小。 attributeCount 字段表示属性的总个数。
idlndex、 classlndex、 stylelndex 字段分别表示 id属性、 class 属性、 style 属性的索引 (注意 : 以 1 为下标, 为 0 表示空值)。

如果 attributeStart 字段指向的偏移量不为 -1 , 且 attributeCount 字段指定的个数大于 0,接下来就是具体的属性数据了。属性数据由 ResXMLTree_attribute 表示, 定义如下:
struct ResXMLTree_attribute
{
// Namespace of this attribute.
struct ResStringPool_ref ns;
// Name of this attribute.
struct ResStringPool_ref name;
// The original raw string value of this attribute.
struct ResStringPool_ref rawValue;
// Processesd typed value of this attribute.
struct Res_value typedValue;
};
ns 与 name 字段分别表示属性所在的 namespace 与属性的名称。
rawValue字段表示该属性的原始字符串值。
typedValue 字段的类型是 Res_value。 Res_value 是一个复杂的类型,可以存放各种类型的属性值。Res_value 的定义如下, data_type 字段表示可以存储的数据类型。
struct Res_value
{
// Number of bytes in this structure.
uint16_t size;
// Always set to 0.
uint8_t res0;
uint8_t dataType;
// The data for this item, as interpreted according to dataType.
typedef uint32_t data_type;
data_type data;
void copyFrom_dtoh(const Res_value& src);
};
size 字段描述了属性占用的总字节数。res0 字段的值目前必须是 0。 dataType 字段表示数据的类型,它的取值可以是如下形式:
// Type of the data value.
enum {
// The 'data' is either 0 or 1, specifying this resource is either
// undefined or empty, respectively.
TYPE_NULL = 0x00,
// The 'data' holds a ResTable_ref, a reference to another resource
// table entry.
TYPE_REFERENCE = 0x01,
// The 'data' holds an attribute resource identifier.
TYPE_ATTRIBUTE = 0x02,
// The 'data' holds an index into the containing resource table's
// global value string pool.
TYPE_STRING = 0x03,
// The 'data' holds a single-precision floating point number.
TYPE_FLOAT = 0x04,
// The 'data' holds a complex number encoding a dimension value,
// such as "100in".
TYPE_DIMENSION = 0x05,
// The 'data' holds a complex number encoding a fraction of a
// container.
TYPE_FRACTION = 0x06,
// The 'data' holds a dynamic ResTable_ref, which needs to be
// resolved before it can be used like a TYPE_REFERENCE.
TYPE_DYNAMIC_REFERENCE = 0x07,
// Beginning of integer flavors...
TYPE_FIRST_INT = 0x10,
// The 'data' is a raw integer value of the form n..n.
TYPE_INT_DEC = 0x10,
// The 'data' is a raw integer value of the form 0xn..n.
TYPE_INT_HEX = 0x11,
// The 'data' is either 0 or 1, for input "false" or "true" respectively.
TYPE_INT_BOOLEAN = 0x12,
// Beginning of color integer flavors...
TYPE_FIRST_COLOR_INT = 0x1c,
// The 'data' is a raw integer value of the form #aarrggbb.
TYPE_INT_COLOR_ARGB8 = 0x1c,
// The 'data' is a raw integer value of the form #rrggbb.
TYPE_INT_COLOR_RGB8 = 0x1d,
// The 'data' is a raw integer value of the form #argb.
TYPE_INT_COLOR_ARGB4 = 0x1e,
// The 'data' is a raw integer value of the form #rgb.
TYPE_INT_COLOR_RGB4 = 0x1f,
// ...end of integer flavors.
TYPE_LAST_COLOR_INT = 0x1f,
// ...end of integer flavors.
TYPE_LAST_INT = 0x1f
};
data 字段中存放了具体的数据, 根据 dataType 指定的不同的数据 类型,它的值的类型也不同。
例如,当 dataType 为 TYPE_STRING 时, data 字段中存放的是字符串的索引, 前面的 rawValue 字段
指向的也是字符串的索引值, 如下图:
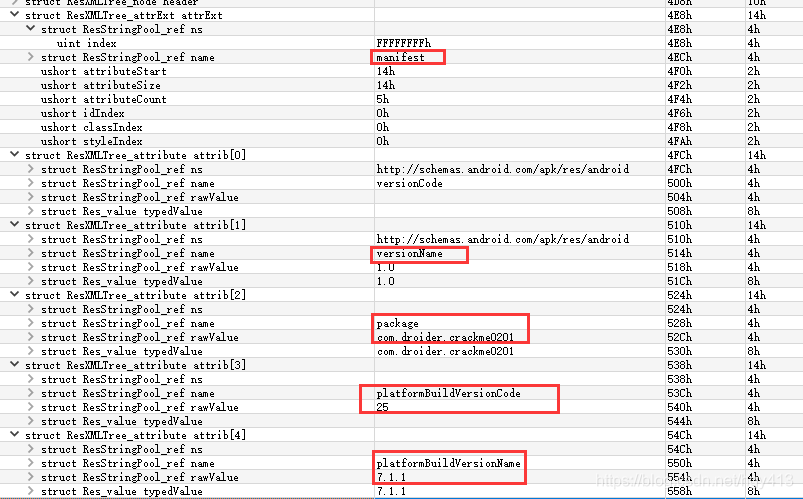
对应:
<manifest android:versionCode="1" android:versionName="1.0" package="com.droider.crackme0201" platformBuildVersionCode="25" platformBuildVersionName="7.1.1" xmlns:android="http://schemas.android.com/apk/res/android">
对 RES_XML_END_ELEMENT_TYPE(0x0103) 类型 的节点 来说,它表示一个节点 TAG 的结束 , 它的扩展结构用 ResXMLTree_endElementExt 表示,定义如下:
struct ResXMLTree_endElementExt
{
// String of the full namespace of this element.
struct ResStringPool_ref ns;
// String name of this node if it is an ELEMENT; the raw
// character data if this is a CDATA node.
struct ResStringPool_ref name;
};
这里的 ns 与 name 字段与前面的 ResXMLTree_attrExt 结构体所对应的字段一样, 分别表示属性所在的namespace 与属性的名称。
可以使用JEB反编译AndroidManifest.xml然后和010 Editor对比,apktools可能会把某些属性直接忽略掉。
4.5 AXML 文件的修改
目前, 部分 APK 保护工具及一些厂商的加固方案利用了 Android 系统解析 AXML 的漏洞,在编译 APK 时构造畸形的 AXML, 使系统能正常安装 APK, 但无法运行 ApkTool 这类反编译工具。 在 这种情况下, 需要对 AXML 进行修改,最直接的修改方式是: 配合使用 010 Editor 及AXML 模板査看文件格式,找到异常部分后进行修改。对一些已经出现的 AXML 加固方案,可以使用现成的工具来修改, 具体如下。
AmBinaryEditor下载地址为 https://github.com/ele7enxxh/AmBinaryEditorAndroidManifestFix, 下载地址为 https://github.com/zylc369/AndroidManifestFix
5.resources.arsc
点击下载测试使用的resources.arsc
android 工程下的 java/res 目录中存放了软件使用的各种类型的资源文件, 这些 资源文件在被编译成APK 时,会被统一打包存放在 APK 的 res 目 录下。其中,jpg、png 图片文件按照原样存放,layout、drawable、 color 目录下的 xml 配置文件都会以前面介绍的 AXML 格式存放。所有的文件在打包时会以原来的文件名保存。
开发人员都知道, 连接程序代码与资源的桥梁是 R.java, 该文件 由编译器自动生成,里面保存的是不同类型的资源的 ID 值。 这些 ID 值通过 res/values/public.xml 方式来定位自己属于哪个资源。
一个资源包含资源的名称、 类型、 值及所在的 Package。 简单地讲, resources.arsc 包含不同语言环境中 res 目录下所有资源的类型、 名称与 ID 所对应的信息。
5.1 ARSC 文件格式
resources.arsc 文件的格式称为 “ARSC 文件格式“。目前在 APK 中, 只有 resources.arsc 文件使用这种格式。
ARSC 使用的数据结构同样位于 ResourceTypes.h 文件中。与 AXML —样,它表示数据块使用chunk。 ARSC 中也引用了 不同的 AXML 中的数据结构。 一个 ARSC 从整体结构上看,由文件头ResTableHeader、 资源项值字符串池 ResStringPool 、Package 数据内容块 ResTablePackage 三部分线性地组成。在分析 ARSC 文件格式时,同样可以使用 010 Editor。
先来看一幅 ARSC 文件格式简图,如下图所示:

ARSC 的内部 细节比 AXML 要复杂得多, 主要体现在 Package 数据内容块部分, 所以我们还是从头看起。
5.1 Header、 String Chunk
首先是文件头 ResTableHeader, 它使用 ResTable_header 结构体表示, 定义如下:
struct ResTable_header
{
struct ResChunk_header header;
// The number of ResTable_package structures.
uint32_t packageCount;
};
header 字段的类型是 ResChunk_header , 这一点在讲解 AXML 时提到过。header 的 type 字段指向的类型为 RES_TABLE_TYPE(0x02), 表示这是一个 ARSC 文件。
packageCount 字段指明该 ARSC 中包含多少个 Package 的资源 信息,它对应于 ARSC 文件中 Package 数据内容块 ResTablePackage 的个数,目前它的取值通常是1。
![]()
接下来是资源值字符串池 ResStringPool, 其中存放了 APK 中所有资源项值的字符串内容。它的数据格式在前面介绍过, 如下所示,它的flags=0x100,也就是使用了 utf-8 编码(前面AndroidManifest.xml是utf-16),ResStringPool的起始偏移是0xC, stringsStart = 0x1AF0, 所以具体字符串起始是0x1AF0+0xC=0x1AFC, ResChunk_header.size = 0xE9A8, 所以ResStringPool结束点是0xE9A8+0xC=0xE9B4。

最后一个字符串在0xE9A2结束,之后跟着 00 00(前面AndroidManifest.xml是4个00),也就是结束位是0xE9B4。
![]()
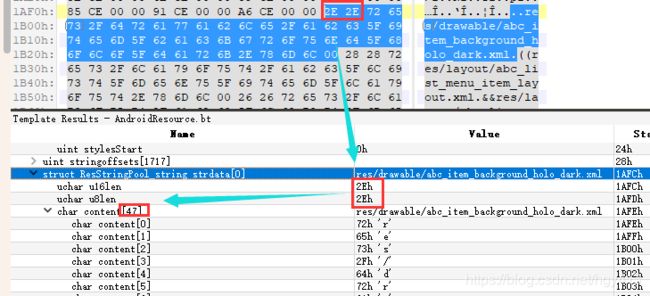
每个字符串的前2个字节都是长度(AndroidManifest.xml是前1个字节),如下,0x2E = 46表示字符串的实际长度,最后还有一个 00 结束符。

5.2 ResTable_package
紧接着 Package 数据内容块 ResTablePackage。 它由数据内容块头 ResTable_package 、资源类型字符串池 TypeStrings、 资源项名称字符串池 KeyStrings、 资源表规范 ResTable_typeSpec 、资源表类型配置 ResTable_type 五部分组成。
ResTable_package 的定义如下:
struct ResTable_package
{
struct ResChunk_header header;
// If this is a base package, its ID. Package IDs start
// at 1 (corresponding to the value of the package bits in a
// resource identifier). 0 means this is not a base package.
uint32_t id;
// Actual name of this package, \0-terminated.
uint16_t name[128];
// Offset to a ResStringPool_header defining the resource
// type symbol table. If zero, this package is inheriting from
// another base package (overriding specific values in it).
uint32_t typeStrings;
// Last index into typeStrings that is for public use by others.
uint32_t lastPublicType;
// Offset to a ResStringPool_header defining the resource
// key symbol table. If zero, this package is inheriting from
// another base package (overriding specific values in it).
uint32_t keyStrings;
// Last index into keyStrings that is for public use by others.
uint32_t lastPublicKey;
uint32_t typeIdOffset;
};
在这里,header 的 type 字段的类型是 RES_TABLE_PACKAGE_TYPE(0x0200)。
id 字段指定了 Package 的 ID, 对用户编译的 APK 来说, 它的取值是 0x7F。
name 字段指定了 Package 的 名称, 该名称通常就是 APK 的 包名。
typeStrings 字段是一个偏移量,指的是资源类型字符串池 typeStrings 在文件中相对 ResTable_package 结构体的偏移量。
lastPublicType 字段指的是导出的 Public 类型的字符串在资源类型字符串池中的索引, 目前它的值被设置为资源类型字符串池中的元素的个数。
keyStrings字段是一个偏移量,指的是资源项名称字符串池 KeyStrings 在文件中相对 ResTable_package 结构体的偏移量。
lastPublicKey 字段指的是导出的 Public 资源项名称字符串在资源项名称字符串池中的索引,目前这个值被设置为资源项名称字符串池中的元素的个数。
typeldOffset 字段指的是类型 ID 的偏移量,只在新版本的 ARSC 中 才有,在旧版本中它的值为 0。
如下所示: 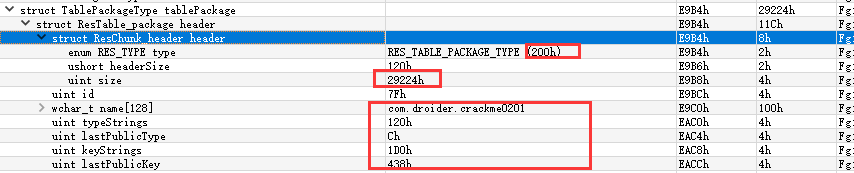
5.3 TypeStrings、KeyStrings
ResTable_package 中指定了 TypeStrings 与 KeyStrings 的偏移量和数目。在 ResTable_package 之后就是 TypeStrings 和 KeyStrings 的具体数据了,它们都使用与资源值字符串池 ResStringPool 相同的数据类型。
根据上图所示,typeStrings=0x120 + 起始偏移0xE9B4 = 0xEAD4为TypeStrings具体数据的起始位, lastPublicType =0xC = 12表示 TypeStrings 的数目,如下图所示:
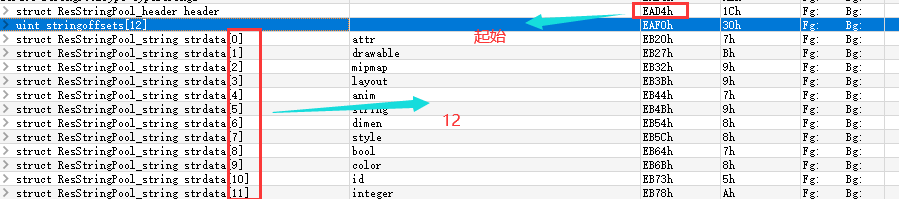
同样可以得到KeyStrings 具体数据的起始位为keyStrings=0x1D0+ 起始偏移0xE9B4 = 0xEB84, 数目为lastPublicKey=0x438=1080。
使用apktool d app-release.apk反编译解析得到public.xml如下:
<?xml version="1.0" encoding="utf-8"?>
<resources>
<public type="attr" name="drawerArrowStyle" id="0x7f010000" />
...
<public type="drawable" name="abc_btn_borderless_material" id="0x7f020002" />
...
<public type="mipmap" name="ic_launcher" id="0x7f030000" />
<public type="mipmap" name="ic_launcher_round" id="0x7f030001" />
<public type="layout" name="abc_action_bar_title_item" id="0x7f040000" />
...
<public type="anim" name="abc_fade_in" id="0x7f050000" />
...
<public type="string" name="abc_action_bar_home_description" id="0x7f060000" />
...
<public type="dimen" name="abc_alert_dialog_button_bar_height" id="0x7f070000" />
...
<public type="style" name="Base.Widget.AppCompat.DrawerArrowToggle" id="0x7f080000" />
...
<public type="bool" name="abc_action_bar_embed_tabs" id="0x7f090000" />
...
<public type="color" name="notification_action_color_filter" id="0x7f0a0000" />
...
<public type="id" name="action_bar_activity_content" id="0x7f0b0000" />
...
<public type="integer" name="abc_config_activityDefaultDur" id="0x7f0c0000" />
...
</resources>
在输出的 type="attr" 中, attr 就属于 TypeStrings。
目前, TypeStrings 中指定的资源类型不到 20 种,除了 attr, 还有 color、strings、 styles、 id、 drawable 等。
name="drawerArrowStyle" 中的 drawerArrowStyle 属于 KeyStrings。 因此, KeyStrings 的数量比 TypeStrings 多得多。
5.4 ResTable_typeSpec、ResTable_type
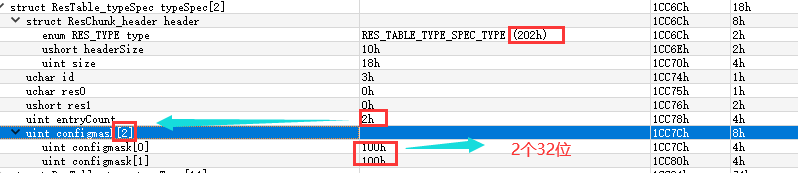
在 KeyStrings 下面就是 ResTable_typeSpec 与 ResTable_type, 它们在文件中可能交叉出现。ResTable_typeSpec 的定义如下:
struct ResTable_typeSpec
{
struct ResChunk_header header;
// The type identifier this chunk is holding. Type IDs start
// at 1 (corresponding to the value of the type bits in a
// resource identifier). 0 is invalid.
uint8_t id;
// Must be 0.
uint8_t res0;
// Must be 0.
uint16_t res1;
// Number of uint32_t entry configuration masks that follow.
uint32_t entryCount;
enum {
// Additional flag indicating an entry is public.
SPEC_PUBLIC = 0x40000000
};
};
header 的 type 字段在这里是 RES_TABLE_TYPE_SPEC_TYPE(0x0202)。
id 字段指明了类型规范资源的 Type ID。Type ID 的细节在前面讲过(4.3 ResourceId Chunk), 它指明了资源的类型到底是 anim,还是 drawable 或 layout 抑或其他。
ResTablejtypeSpec 的具体用途是 : 在 APK 调用 OnConfigChange() 时, 针对不同类型的资源设置一系列的 FLAG 标志供系统使用。因为它针对不同的 Type ID, 所以它的个数的最大值就是 Type ID 的个数。
res0 与 res1 字段的值目前必须是 0。 entryCount 字段指明了接 下来的 flags 的个数 (每个 flag 都是 32 位整型的)。
如下图:
接下来就是 ResTable_type 了, 它是一个非常重要的结构, 描述了资源项的具体信息。通过它我们可以知道每一个资源项的名称、类型、值和配置等信息。ResTable_type的定义如下:
struct ResTable_type
{
struct ResChunk_header header;
enum {
NO_ENTRY = 0xFFFFFFFF
};
// The type identifier this chunk is holding. Type IDs start
// at 1 (corresponding to the value of the type bits in a
// resource identifier). 0 is invalid.
uint8_t id;
// Must be 0.
uint8_t res0;
// Must be 0.
uint16_t res1;
// Number of uint32_t entry indices that follow.
uint32_t entryCount;
// Offset from header where ResTable_entry data starts.
uint32_t entriesStart;
// Configuration this collection of entries is designed for.
ResTable_config config;
};
header 的 type 字段在这里是 RES_TABLE_TYPE_TYPE(0x0201)。
id 字段用于指定资源的类型。
res0 与 res1 字段在这里没有使用, 值必须为 0。
entryCount 与 entriesStart 字段指定了资源条目的个数与资源条目起始地址相对本header头部的文件偏移。
config 字段指明了资源的配置信息 , 包括资源的 SDK 版本、地区、语言、 分辨率等。ResTable_config 的结构定义:
struct ResTable_config
{
// Number of bytes in this structure.
uint32_t size;
union {
struct {
// Mobile country code (from SIM). 0 means "any".
uint16_t mcc;
// Mobile network code (from SIM). 0 means "any".
uint16_t mnc;
};
uint32_t imsi;
};
...
ResTable_config 结构体可能随着系统的升级而扩展, 其第 1 个 size 字段规定了本配置信息结构的总字节数。

紧接着后面是一个大小为 entryCount 的 32 位整型数组 entries, 每个数组元素都用来描述一个资源项数据块的偏移位置,这由前面的entryCount 与 entriesStart 字段指定,如下图:

在这个数组之后是一个 ResTable_entry 结构数组resentries, 它的大小依赖于数组 entries, 如果 entries 里面的条目的偏移量是 -1 则跳过,所有偏移量不为 -1 的条目的个数就是数组 resentries 的 个数。ResTable_entry结构的定义如下:
struct ResTable_entry
{
// Number of bytes in this structure.
uint16_t size;
uint16_t flags;
// Reference into ResTable_package::keyStrings identifying this entry.
struct ResStringPool_ref key;
};
size 字段表示本结构占用的字节大小, flags 是一个标志,key 是 KeyStrings 中引用的字符串数组的下标(0开始)。
flags 的取值如下:
enum {
// If set, this is a complex entry, holding a set of name/value
// mappings. It is followed by an array of ResTable_map structures.
FLAG_COMPLEX = 0x0001,
// If set, this resource has been declared public, so libraries
// are allowed to reference it.
FLAG_PUBLIC = 0x0002,
// If set, this is a weak resource and may be overriden by strong
// resources of the same name/type. This is only useful during
// linking with other resource tables.
FLAG_WEAK = 0x0004
};
如果取值包含 FLAG_COMPLEX,表明本结构体数据是一个 ResTable_map_entry 结构体; 如果取值不包含 FLAG_COMPLEX, 说明下面跟随的是一个 Res_value 结构体, 用于存放上面的 key 字段所对应的值。
ResTable_map_entry 是一个基于键值对的复杂 结构, 继承自前面的 ResTable_entry 结构体, 定义如下:
struct ResTable_map_entry : public ResTable_entry
{
// Resource identifier of the parent mapping, or 0 if there is none.
// This is always treated as a TYPE_DYNAMIC_REFERENCE.
ResTable_ref parent;
// Number of name/value pairs that follow for FLAG_COMPLEX.
uint32_t count;
};
ResTable_ref 类型中只有一个 32 位整型的 ID 字段。parent 字段指明了当前资源项的父资源项的资源 ID。 count 字段指明了接 下来有多少个 ResTable_map 类型的结 构体。ResTable_map 描述了具体的键值对信息,它的结构体定义如下:
struct ResTable_map
{
// The resource identifier defining this mapping's name. For attribute
// resources, 'name' can be one of the following special resource types
// to supply meta-data about the attribute; for all other resource types
// it must be an attribute resource.
ResTable_ref name;
// This mapping's value.
Res_value value;
};
name 与 value 字段分别表示资源的名称与具体的值, Res_value 字段在前面 AXML 时介绍过,它可以是各种类型的数据。
通过解析 ResTable_map_entry 和 ResTable_map, 就可以解析 public.xml 及其他类型的 XML 文件了。
6. META-INF 目录
APK 包 中有一 个名为 “META-INF” 的目录。 该目录中存储了一些与 APK 签名有关的信息,示例如下。
$ ls META-INF/
CERT.RSA
CERT.SF
MANIFEST.MF
.MF的名字是确定的,就是MANIFEST.MF,其他的两个文件默认的文件名是CERT,但是这个名字可以随意修改,只要.SF和.RSA的文件名字相同就可以了,比如Android.SF和Android.RSA。
6.1 CERT.RSA
CERT.RSA 文件中存放了 APK 的开发者证书与签名信息。 通过该文件可以识别开发者的身份,以及判断 APK 是否被篡改。CERT.RSA 文件是由 DER 编码的证书。由于在 DER 内部使用了 ASN1 进行编码, 使用任何 ASN1 解码库都能对其进行解码, 例如 GNU 的 libtasnl 库。 在这里 ,使用 OpenSSL 提供的解码功能来查看 CERT.RSA 的证书内容。
OpenSSL 是一款跨平台的加解密库管理套件。Cygwin安装命令为 apt-cyg install openssl。
安装后,执行如下命令即可查看 CERT.RSA 中开发者证书的内容。
$ openssl pkcs7 -inform DER -in CERT.RSA -noout -print_certs -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 1395067791 (0x53270b8f)
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=CN, ST=HuBei, L=WuHan, O=FC, OU=FC, CN=Fei Cong
Validity
Not Before: Mar 1 04:25:43 2017 GMT
Not After : Feb 23 04:25:43 2042 GMT
Subject: C=CN, ST=HuBei, L=WuHan, O=FC, OU=FC, CN=Fei Cong
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:80:49:98:a0:96:eb:5b:49:32:56:c1:e3:bd:f2:
d0:cb:5f:75:9e:34:9c:1d:1c:c9:ae:96:de:da:f3:
bd:90:e1:6c:9d:08:88:58:88:73:6d:32:80:45:9a:
09:eb:d0:36:08:eb:4d:3d:cd:e3:67:ba:d2:21:ce:
c8:45:e8:c3:9b:44:f1:b9:95:94:89:8d:c1:3b:f1:
60:14:6c:9e:b0:50:56:1c:91:7e:cb:15:78:eb:b4:
ca:df:2e:50:38:99:5b:b3:72:87:b3:35:e1:0b:74:
59:96:e6:62:3a:95:cf:3b:d4:cf:5a:4c:5a:aa:27:
1c:7a:78:54:50:ce:6c:9a:05:10:c2:f7:0c:ca:56:
46:ef:cd:ae:40:a8:9d:57:2b:0b:17:4e:51:79:d6:
c6:ef:df:55:75:6b:d0:30:a4:d7:90:b4:3d:be:58:
f4:d8:45:4e:57:64:24:7b:aa:0d:ba:4c:41:cd:dd:
72:a9:30:17:d9:99:7b:d0:9c:0a:f8:89:a6:6e:cf:
24:86:07:ef:b2:b9:fe:ea:94:5f:74:a0:e6:2f:7d:
1f:16:00:f0:e6:57:65:1a:a8:39:19:79:1e:53:8c:
3a:72:5c:7b:dd:02:74:11:2e:19:a0:99:5c:1a:88:
22:bf:39:bc:1a:54:1a:fe:f0:51:4e:e4:cc:c0:a2:
2f:6d
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Subject Key Identifier:
C6:10:54:72:EF:EA:91:F6:D4:C3:15:F6:AB:09:59:8B:01:A5:37:FD
Signature Algorithm: sha256WithRSAEncryption
04:ac:55:70:91:4e:88:1e:a8:12:23:fd:cd:07:4c:75:48:ce:
76:1b:0c:56:60:07:7f:8f:0d:fc:3f:44:a5:99:81:cd:01:b1:
a2:0c:b1:9f:5a:0d:7a:9a:d9:5d:01:e2:96:9a:09:93:a5:1b:
45:8e:84:bf:db:8d:dd:28:03:c5:f1:d5:66:f7:f8:65:fa:b9:
dc:76:e4:3a:75:14:4c:25:80:57:0d:d1:4c:10:e9:1e:0e:6b:
51:bb:e8:a3:f9:ef:3b:97:47:3d:ac:32:81:b0:62:e7:32:c8:
77:49:e2:41:92:61:08:f4:43:a4:a8:94:56:eb:09:6e:ca:3a:
49:f6:cb:aa:07:1a:58:13:6c:85:33:f4:50:6f:a0:7b:fd:bc:
06:e3:ec:f5:96:57:4c:91:d3:05:b8:29:98:38:41:14:06:34:
df:1f:29:7e:ad:0f:a2:f9:b1:97:c5:e6:5f:6e:56:eb:a5:23:
51:b5:78:a8:46:af:0c:d9:0e:50:36:4b:2a:e4:3c:c0:30:a7:
f4:9b:89:cd:a9:a4:28:76:e4:bb:b2:dc:ac:12:78:0d:aa:b1:
ab:93:0d:63:ad:c9:f7:3b:a7:b8:33:c6:0f:72:a8:2d:9c:36:
1d:a4:c7:db:5b:cc:d2:67:3c:c7:65:5e:26:d9:36:cd:61:57:
2f:0a:64:8b
输出的证书信息是 APK 合法和有效的凭证, 在对 APK 进行保护时, 其中的很多项都是用来鉴别 APK 是否已经被修改的有力证据。
6.2 MANIFEST.MF
MANIFEST.MF 是签名的清单文件,它是一个文本文件,内容如下:
$ cat MANIFEST.MF |less
Manifest-Version: 1.0
Built-By: Generated-by-ADT
Created-By: Android Gradle 2.3.2
...
Name: res/layout/notification_action.xml
SHA1-Digest: KQ/pWHb9ti0sMJwwHVkIe33ouaI=
...
可以看出,打包该文件的工具是 Android Gradle 2.3.2, 下面的每一组信息都包括 Name 与 SHAl-Digest, 表示 APK 中每个文件 的路径与它的 SHA-1 散列值的 Base64 值。
有时MANIFEST.MF中显示的是SHA-256-Digest而不是SHA1-Digest(jarsigner给apk签名,使用的是SHA256签名算法), 这时只需把下面的openssl sha1改志openssl sha256即可。
以 res/layout/notification_action.xml 文件为例,执行如下命令 , 对比一下它的值:
$ openssl sha1 res/layout/notification_action.xml
SHA1(res/layout/notification_action.xml)= 290fe95876fdb62d2c309c301d59087b7de8b9a2
$ echo 290fe95876fdb62d2c309c301d59087b7de8b9a2 | python3 -c "import sys,binascii; sys.stdout.buffer.write(binascii.unhexlify(input().strip()))" | openssl enc -e -base64
KQ/pWHb9ti0sMJwwHVkIe33ouaI=
如果python3找不到,先在CygWin中执行下apt-cyg install python3。
可以看出, “KQ/pWHb9ti0sMJwwHVkIe33ouaI=” 与 MANIFEST.MF 文件中的值是一样的。这证明了在MANIFEST.MF 文件中存放的是 APK 文件中所有包含的文件列表的 SHA-1 散列值的Base64 值, 从而保证了在进行 APK 签名验证时 APK 中所有的文件均未被修改。
6.3 CERT.SF
CERT.SF 是签名信息文件, 它也是一个文本文件,内容如下:
Signature-Version: 1.0
X-Android-APK-Signed: 2
SHA1-Digest-Manifest: SL/GFzhH9wrdwGTzFJKvInf3pv0=
Created-By: 1.0 (Android)
...
Name: res/layout/notification_action.xml
SHA1-Digest: KQ/pWHb9ti0sMJwwHVkIe33ouaI=
...
一眼看上去,记录的每一组信息也包括 Name 与 SHAl-Digest, 而且 Name 与 SHAl-Digest 的值也与 MANIFEST.MF 文件中的值相同,用文本比较工具和 MANIFEST.MF 比较,差别如下:

CERT.SF 文件的开头部分多了一个 SHAl-Digest-Manifest 的值。 其实,SHA1-Digest-Manifest 的值就是对 MANIFEST.MF 文件内容的 SHA-1 散列值进行 Base64 计算得到的结果。可以执行如下命令进行验证。
$ openssl sha1 < META-INF/MANIFEST.MF
(stdin)= 48bfc6173847f70addc064f31492af2277f7a6fd
$ echo 48bfc6173847f70addc064f31492af2277f7a6fd | python3 -c "import sys,binascii; sys.stdout.buffer.write(binascii.unhexlify(input().strip()))" | openssl enc -e -base64
SL/GFzhH9wrdwGTzFJKvInf3pv0=
CERT.SF 文件的开头部分还多了一个字段 X-Android-APK-Signed, 它的值为 2, 表示使用新版本APK Signature Scheme v2 进行签名。
v2 签名信息不同于以往在 Android 开发中使用 SignApk 得到的 结果。 Android Studio 在新版本的 SDK 构建工具中增加了一个签名工具 apksigner, 它同时支持旧版本的 v1 签名和在 Android 7.0 中 引入的 v2 签名。
用低版本的 SignApk 对 apk 进行签名 , 生成的 CERT.SF 如下:
Signature-Version:1.0
SHA1-Digest-Manifest:2XTV8FrvWWz0GpM/0qDYbV4tshU=
Created-By:1.0 (Android SignApk)
...
Name:res/layout/notification_action.xml
SHAl-Digest:zuZ8hQ7uLD2P25MC0KwmVL+LlRs=
...
每个 Name 所对应的 SHAl-Digest 值与 MANIFEST.MF 输出的内容不一样了, 但 MANIFEST.MF 的内容没有变化。
这是因为, 低版本的 SignApk 在对 APK 进行签名并生成 CERT.SF 时, 会对每栏中的 Name 与 SHAl-Digest 的值单独计算签名, 然后将每个签名结果写入 CERT.SF 的 SHAl-Digest 字段。这样做的结果就是需要逐个验证 APK 中的文件,而这会导致在验证 APK 这个步骤上消耗很长时间。
低版本CERT.SF 计算可以参考: Android中签名原理和安全性分析之META-INF文件讲解
这里简单说个例子:比如MANIFEST.MF中的class.dex文件的记录如下:

我们新建一个test.text文件,把上面的内容复制到test.text中,最后再加上两个\r\n, 如下图:

看hex模式更清楚一些,如下图:

然后和之前计算MANIFEST.MF中的sha值一样流程:
$ openssl sha256 ./test.txt
SHA256(./test.txt)= 3ad9d027ae2bc955e698ec217172d59713c4f5fe163e9d6c08f1c54f24312ebf
$ echo 3ad9d027ae2bc955e698ec217172d59713c4f5fe163e9d6c08f1c54f24312ebf | python3 -c "import sys,binascii; sys.stdout.buffer.write(binascii.unhexlify(input().strip()))" | openssl enc -e -base64
OtnQJ64ryVXmmOwhcXLVlxPE9f4WPp1sCPHFTyQxLr8=
对应 CERT.SF中如下:

参考:
一篇文章带你搞懂DEX文件的结构
Android软件安全权威指南
AndroidManifest.xml 文件格式解析
可能是全网讲最细的安卓resources.arsc解析教程(一)
Android中签名原理和安全性分析之META-INF文件讲解