Python_头条项目数据库(2)
数据库
-
数据库设计
-
SQLAlchemy
-
数据库理论
-
分布式ID
-
Redis
数据库设计
1 需求
根据黑马头条前台产品原型图中用户端的部分,进行数据库设计。
- 表结构
- 字段类型、是否允许为null、是否有默认值
- 索引设计
- 数据库引擎的选择
2 注意事项
-
为了查询效率,可以做冗余字段设计(空间换时间的思想,属于一种反范式设计)
-
字段类型的选择
-
整型的存储大小与显示大小
mysql的字段,unsigned int(3), 和unsinged int(6), 能存储的数值范围是否相同。如果不同,分别是多大?
我们建立下面这张表:
CREATE TABLE `test` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `i1` int(3) unsigned zerofill DEFAULT NULL, `i2` int(6) unsigned zerofill DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8插入一些数据后
-

-
-
发现,无论是int(3), int(6), 都可以显示6位以上的整数。但是,当数字不足3位或6位时,前面会用0补齐。
手册解释是这样的:
MySQL还支持选择在该类型关键字后面的括号内指定整数值的显示宽度(例如,INT(4))。该可选显示宽度规定用于显示宽度小于指定的列宽度的值时从左侧填满宽度。显示宽度并不限制可以在列内保存的值的范围,也不限制超过列的指定宽度的值的显示。
也就是说,int的长度并不影响数据的存储精度,长度只和显示有关,为了让大家看的更清楚,我们在上面例子的建表语句中,使用了zerofill。
最终答案:存储范围相同。
-
char 与 varchar 的选择
- char 不可变,查询效率高,可能造成存储浪费
- varchar 可变,查询效率不如char,节省空间
-
常见MySQL数据类型
| 类 型 | 大 小 | 描 述 |
|---|---|---|
| CAHR(Length) | Length字节 | 定长字段,长度为0~255个字符 |
| VARCHAR(Length) | String长度+1字节或String长度+2字节 | 变长字段,长度为0~65 535个字符 |
| TINYTEXT | String长度+1字节 | 字符串,最大长度为255个字符 |
| TEXT | String长度+2字节 | 字符串,最大长度为65 535个字符 |
| MEDIUMINT | String长度+3字节 | 字符串,最大长度为16 777 215个字符 |
| LONGTEXT | String长度+4字节 | 字符串,最大长度为4 294 967 295个字符 |
| TINYINT(Length) | 1字节 | 范围:-128~127,或者0~255(无符号) |
| SMALLINT(Length) | 2字节 | 范围:-32 768~32 767,或者0~65 535(无符号) |
| MEDIUMINT(Length) | 3字节 | 范围:-8 388 608~8 388 607,或者0~16 777 215(无符号) |
| INT(Length) | 4字节 | 范围:-2 147 483 648~2 147 483 647,或者0~4 294 967 295(无符号) |
| BIGINT(Length) | 8字节 | 范围:-9 223 372 036 854 775 808~9 223 372 036 854 775 807,或者0~18 446 744 073 709 551 615(无符号) |
| FLOAT(Length, Decimals) | 4字节 | 具有浮动小数点的较小的数 |
| DOUBLE(Length, Decimals) | 8字节 | 具有浮动小数点的较大的数 |
| DECIMAL(Length, Decimals) | Length+1字节或Length+2字节 | 存储为字符串的DOUBLE,允许固定的小数点 |
| DATE | 3字节 | 采用YYYY-MM-DD格式 |
| DATETIME | 8字节 | 采用YYYY-MM-DD HH:MM:SS格式 |
| TIMESTAMP | 4字节 | 采用YYYYMMDDHHMMSS格式;可接受的范围终止于2037年 |
| TIME | 3字节 | 采用HH:MM:SS格式 |
| ENUM | 1或2字节 | Enumeration(枚举)的简写,这意味着每一列都可以具有多个可能的值之一 |
| SET | 1、2、3、4或8字节 | 与ENUM一样,只不过每一列都可以具有多个可能的值 |
-
索引
-
主键 Primary Key
-
外键 Foreign Key
- 保持数据完整性
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name, ...) REFERENCES tbl_name (index_col_name,...) [ON DELETE reference_option] [ON UPDATE reference_option]例如:
ALTER TABLE `user_resource` CONSTRAINT `FKEEAF1E02D82D57F9` FOREIGN KEY (`user_Id`) REFERENCES `sys_user` (`Id`)CASCADE
在父表上update/delete记录时,同步update/delete掉子表的匹配记录
- ON DELETE:删除主表时自动删除从表。删除从表,主表不变
- ON UPDATE:更新主表时自动更新从表。更新从表,主表不变
SET NULL
在父表上update/delete记录时,将子表上匹配记录的列设为null (要注意子表的外键列不能为not null)
- ON DELETE:删除主表时自动更新从表值为NULL。删除从表,主表不变
- ON UPDATE:更新主表时自动更新从表值为NULL。更新从表,主表不变
NO ACTION
如果子表中有匹配的记录,则不允许对父表对应候选键进行update/delete操作
- ON DELETE:从表记录不存在时,主表才可以删除。删除从表,主表不变
- ON UPDATE:从表记录不存在时,主表才可以更新。更新从表,主表不变
RESTRICT
同no action, 都是立即检查外键约束
SET DEFAULT
父表有变更时,子表将外键列设置成一个默认的值 但Innodb目前不支持
-
索引 Key / Index
- 提升查询效率,减慢增删改速度
-
唯一约束 Unique
- 保证数据不重复
-
-
MySQL数据库引擎
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以 获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。MySQL的核心就是存储引擎。
SHOW ENGINES # 命令来查看MySQL提供的引擎 SHOW VARIABLES LIKE 'storage_engine'; # 查看数据库默认使用哪个引擎InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。InnoDB主要特性有:
1、InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。
InnoDB锁定在行级并且也在SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
2、InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
3、InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上
4、InnoDB支持外键完整性约束
5、存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
6、InnoDB被用在众多需要高性能的大型数据库站点上
InnoDB不创建目录,使用InnoDB时,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为ib_logfile0和ib_logfile1的5MB大小的日志文件
MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。MyISAM主要特性有:
1、大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持
2、当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成
3、每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
4、最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上
5、BLOB和TEXT列可以被索引
6、NULL被允许在索引的列中,这个值占每个键的0~1个字节
7、所有数字键值以高字节优先被存储以允许一个更高的索引压缩
8、每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快
9、可以把数据文件和索引文件放在不同目录
10、每个字符列可以有不同的字符集
11、有VARCHAR的表可以固定或动态记录长度
12、VARCHAR和CHAR列可以多达64KB
使用MyISAM引擎创建数据库,将产生3个文件。文件的名字以表名字开始,扩展名之处文件类型:frm文件存储表定义、数据文件的扩展名为.MYD(MYData)、索引文件的扩展名时.MYI(MYIndex)
MEMORY存储引擎
MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。MEMORY主要特性有:
1、MEMORY表的每个表可以有多达32个索引,每个索引16列,以及500字节的最大键长度
2、MEMORY存储引擎执行HASH和BTREE缩影
3、可以在一个MEMORY表中有非唯一键值
4、MEMORY表使用一个固定的记录长度格式
5、MEMORY不支持BLOB或TEXT列
6、MEMORY支持AUTO_INCREMENT列和对可包含NULL值的列的索引
7、MEMORY表在所由客户端之间共享(就像其他任何非TEMPORARY表)
8、MEMORY表内存被存储在内存中,内存是MEMORY表和服务器在查询处理时的空闲中,创建的内部表共享
9、当不再需要MEMORY表的内容时,要释放被MEMORY表使用的内存,应该执行DELETE FROM或TRUNCATE TABLE,或者删除整个表(使用DROP TABLE)
存储引擎的选择
不同的存储引擎都有各自的特点,以适应不同的需求,如下表所示:

如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
3 头条项目数据库
加入Gitlab项目组,克隆toutiao-backend代码,理解数据库sql文件。
==========================================
理解ORM
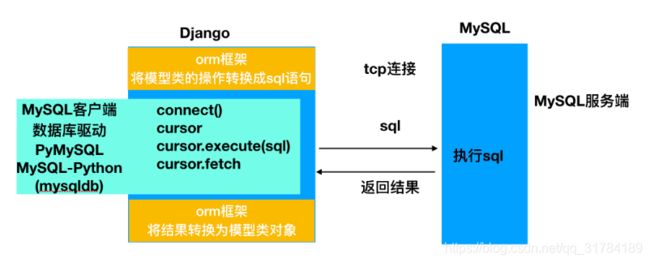
作用
-
省去自己拼写SQL,保证SQL语法的正确性
-
一次编写可以适配多个数据库
-
防止注入攻击
-
在数据库表名或字段名发生变化时,只需修改模型类的映射,无需修改数据库操作的代码
(相比SQL的话,可能需要同步修改涉及到的每一个SQL语句)
思考:
可否在已经存在数据库表的情况下,使用模型类进行操作?

使用ORM的方式选择
- 先创建模型类,再迁移到数据库中
- 优点:简单快捷,定义一次模型类即可,不用写sql
- 缺点:不能尽善尽美的控制创建表的所有细节问题,表结构发生变化的时候,也会难免发生迁移错误
- 先用原生SQL创建数据库表,再编写模型类作映射
- 优点:可以很好的控制数据库表结构的任何细节,避免发生迁移错误
- 缺点:可能编写工作多(编写sql与模型类,似乎有些牵强)
头条项目采用编写原生SQL创建表,之后再编写模型类进行映射的方式。
===================================
SQLAlchemy映射构建
1 简介
SQLAlchemy是Python编程语言下的一款开源软件。提供了SQL工具包及对象关系映射(ORM)工具,使用MIT许可证发行。
SQLAlchemy“采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型”。
SQLAlchemy首次发行于2006年2月,并迅速地在Python社区中最广泛使用的ORM工具之一,不亚于Django的ORM框架。
Flask-SQLAlchemy是在Flask框架的一个扩展,其对SQLAlchemy进行了封装,目的于简化在 Flask 中 SQLAlchemy 的 使用,提供了有用的默认值和额外的助手来更简单地完成日常任务。
2 安装
安装Flask-SQLAlchemy
pip install flask-sqlalchemy
如果使用的是MySQL数据库,还需要安装MySQL的Python客户端库
pip install mysqlclient
3 数据库连接设置
在Flask中使用Flask-SQLAlchemy需要进行配置,主要配置以下几项:
-
SQLALCHEMY_DATABASE_URI数据库的连接信息-
Postgres:
postgresql://user:password@localhost/mydatabase -
MySQL:
mysql://user:password@localhost/mydatabase -
Oracle:
oracle://user:[email protected]:1521/sidname -
SQLite (注意开头的四个斜线):
sqlite:absolute/path/to/foo.db
-
-
SQLALCHEMY_TRACK_MODIFICATIONS在Flask中是否追踪数据修改 -
SQLALCHEMY_ECHO显示生成的SQL语句,可用于调试
这些配置参数需要放在Flask的应用配置(app.config)中。
from flask import Flask
app = Flask(__name__)
class Config(object):
SQLALCHEMY_DATABASE_URI = 'mysql://root:[email protected]:3306/toutiao'
SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLALCHEMY_ECHO = True
app.config.from_object(Config)
其他配置参考如下:
| 名字 | 备注 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用于连接的数据库 URI 。例如:sqlite:tmp/test.dbmysql://username:password@server/db |
| SQLALCHEMY_BINDS | 一个映射 binds 到连接 URI 的字典。更多 binds 的信息见用 Binds 操作多个数据库。 |
| SQLALCHEMY_ECHO | 如果设置为Ture, SQLAlchemy 会记录所有 发给 stderr 的语句,这对调试有用。(打印sql语句) |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或启用查询记录。查询记录 在调试或测试模式自动启用。更多信息见get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式禁用原生 unicode 支持。当使用 不合适的指定无编码的数据库默认值时,这对于 一些数据库适配器是必须的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是引擎默认值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 设定连接池的连接超时时间。默认是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自动回收连接。这对 MySQL 是必要的, 它默认移除闲置多于 8 小时的连接。注意如果 使用了 MySQL , Flask-SQLALchemy 自动设定 这个值为 2 小时。 |
4 模型类字段与选项
字段类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多关系中关系表的名字 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
5 构建模型类映射
例用虚拟机中已有的头条数据库,构建模型类映射,以下面三张表为例
CREATE TABLE `user_basic` (
`user_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`account` varchar(20) COMMENT '账号',
`email` varchar(20) COMMENT '邮箱',
`status` tinyint(1) NOT NULL DEFAULT '1' COMMENT '状态,是否可用,0-不可用,1-可用',
`mobile` char(11) NOT NULL COMMENT '手机号',
`password` varchar(93) NULL COMMENT '密码',
`user_name` varchar(32) NOT NULL COMMENT '昵称',
`profile_photo` varchar(128) NULL COMMENT '头像',
`last_login` datetime NULL COMMENT '最后登录时间',
`is_media` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否是自媒体,0-不是,1-是',
`is_verified` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否实名认证,0-不是,1-是',
`introduction` varchar(50) NULL COMMENT '简介',
`certificate` varchar(30) NULL COMMENT '认证',
`article_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '发文章数',
`following_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '关注的人数',
`fans_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '被关注的人数',
`like_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计点赞人数',
`read_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计阅读人数',
PRIMARY KEY (`user_id`),
UNIQUE KEY `mobile` (`mobile`),
UNIQUE KEY `user_name` (`user_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户基本信息表';
CREATE TABLE `user_profile` (
`user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID',
`gender` tinyint(1) NOT NULL DEFAULT '0' COMMENT '性别,0-男,1-女',
`birthday` date NULL COMMENT '生日',
`real_name` varchar(32) NULL COMMENT '真实姓名',
`id_number` varchar(20) NULL COMMENT '身份证号',
`id_card_front` varchar(128) NULL COMMENT '身份证正面',
`id_card_back` varchar(128) NULL COMMENT '身份证背面',
`id_card_handheld` varchar(128) NULL COMMENT '手持身份证',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`register_media_time` datetime NULL COMMENT '注册自媒体时间',
`area` varchar(20) COMMENT '地区',
`company` varchar(20) COMMENT '公司',
`career` varchar(20) COMMENT '职业',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户资料表';
CREATE TABLE `user_relation` (
`relation_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID',
`target_user_id` bigint(20) unsigned NOT NULL COMMENT '目标用户ID',
`relation` tinyint(1) NOT NULL DEFAULT '0' COMMENT '关系,0-取消,1-关注,2-拉黑',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`relation_id`),
UNIQUE KEY `user_target` (`user_id`, `target_user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户关系表';
首先需要创建SQLAlchemy对象:
-
方式一:
db = SQLAlchemy(app) -
方式二:
db = SQLAlchemy() db.init_app(app)注意此方式在单独运行调试时,对数据库操作需要在Flask的应用上下文中进行,即
with app.app_context(): User.query.all()
定义模型类
class User(db.Model):
"""
用户基本信息
"""
__tablename__ = 'user_basic'
class STATUS:
ENABLE = 1
DISABLE = 0
id = db.Column('user_id', db.Integer, primary_key=True, doc='用户ID')
mobile = db.Column(db.String, doc='手机号')
password = db.Column(db.String, doc='密码')
name = db.Column('user_name', db.String, doc='昵称')
profile_photo = db.Column(db.String, doc='头像')
last_login = db.Column(db.DateTime, doc='最后登录时间')
is_media = db.Column(db.Boolean, default=False, doc='是否是自媒体')
is_verified = db.Column(db.Boolean, default=False, doc='是否实名认证')
introduction = db.Column(db.String, doc='简介')
certificate = db.Column(db.String, doc='认证')
article_count = db.Column(db.Integer, default=0, doc='发帖数')
following_count = db.Column(db.Integer, default=0, doc='关注的人数')
fans_count = db.Column(db.Integer, default=0, doc='被关注的人数(粉丝数)')
like_count = db.Column(db.Integer, default=0, doc='累计点赞人数')
read_count = db.Column(db.Integer, default=0, doc='累计阅读人数')
account = db.Column(db.String, doc='账号')
email = db.Column(db.String, doc='邮箱')
status = db.Column(db.Integer, default=1, doc='状态,是否可用')
class UserProfile(db.Model):
"""
用户资料表
"""
__tablename__ = 'user_profile'
class GENDER:
MALE = 0
FEMALE = 1
id = db.Column('user_id', db.Integer, primary_key=True, doc='用户ID')
gender = db.Column(db.Integer, default=0, doc='性别')
birthday = db.Column(db.Date, doc='生日')
real_name = db.Column(db.String, doc='真实姓名')
id_number = db.Column(db.String, doc='身份证号')
id_card_front = db.Column(db.String, doc='身份证正面')
id_card_back = db.Column(db.String, doc='身份证背面')
id_card_handheld = db.Column(db.String, doc='手持身份证')
ctime = db.Column('create_time', db.DateTime, default=datetime.now, doc='创建时间')
utime = db.Column('update_time', db.DateTime, default=datetime.now, onupdate=datetime.now, doc='更新时间')
register_media_time = db.Column(db.DateTime, doc='注册自媒体时间')
area = db.Column(db.String, doc='地区')
company = db.Column(db.String, doc='公司')
career = db.Column(db.String, doc='职业')
class Relation(db.Model):
"""
用户关系表
"""
__tablename__ = 'user_relation'
class RELATION:
DELETE = 0
FOLLOW = 1
BLACKLIST = 2
id = db.Column('relation_id', db.Integer, primary_key=True, doc='主键ID')
user_id = db.Column(db.Integer, doc='用户ID')
target_user_id = db.Column(db.Integer, doc='目标用户ID')
relation = db.Column(db.Integer, doc='关系')
ctime = db.Column('create_time', db.DateTime, default=datetime.now, doc='创建时间')
utime = db.Column('update_time', db.DateTime, default=datetime.now, onupdate=datetime.now, doc='更新时间')
============================================
SQLAlchemy操作
1 新增
user = User(mobile='15612345678', name='itcast')
db.session.add(user)
db.session.commit()
profile = Profile(id=user.id)
db.session.add(profile)
db.session.commit()
对于批量添加也可使用如下语法
db.session.add_all([user1, user2, user3])
db.session.commit()
2 查询
all()
查询所有,返回列表
User.query.all()
first()
查询第一个,返回对象
User.query.first()
get()
根据主键ID获取对象,若主键不存在返回None
User.query.get(2)
另一种查询方式
db.session.query(User).all()
db.session.query(User).first()
db.session.query(User).get(2)
filter_by
进行过虑
User.query.filter_by(mobile='13911111111').first()
User.query.filter_by(mobile='13911111111', id=1).first() # and关系
filter
进行过虑
User.query.filter(User.mobile=='13911111111').first()
逻辑或
from sqlalchemy import or_
User.query.filter(or_(User.mobile=='13911111111', User.name.endswith('号'))).all()
逻辑与
from sqlalchemy import and_
User.query.filter(and_(User.name != '13911111111', User.mobile.startswith('185'))).all()
逻辑非
from sqlalchemy import not_
User.query.filter(not_(User.mobile == '13911111111')).all()
offset
偏移,起始位置
User.query.offset(2).all()
limit
获取限制数据
User.query.limit(3).all()
order_by
排序
User.query.order_by(User.id).all() # 正序
User.query.order_by(User.id.desc()).all() # 倒序
复合查询
User.query.filter(User.name.startswith('13')).order_by(User.id.desc()).offset(2).limit(5).all()
query = User.query.filter(User.name.startswith('13'))
query = query.order_by(User.id.desc())
query = query.offset(2).limit(5)
ret = query.all()
优化查询
user = User.query.filter_by(id=1).first() # 查询所有字段
select user_id, mobile......
select * from # 程序不要使用
select user_id, mobile,.... # 查询指定字段
from sqlalchemy.orm import load_only
User.query.options(load_only(User.name, User.mobile)).filter_by(id=1).first() # 查询特定字段
聚合查询
from sqlalchemy import func
db.session.query(Relation.user_id, func.count(Relation.target_user_id)).filter(Relation.relation == Relation.RELATION.FOLLOW).group_by(Relation.user_id).all()
关联查询
1. 使用ForeignKey
class User(db.Model):
...
profile = db.relationship('UserProfile', uselist=False)
followings = db.relationship('Relation')
class UserProfile(db.Model):
id = db.Column('user_id', db.Integer, db.ForeignKey('user_basic.user_id'), primary_key=True, doc='用户ID')
...
class Relation(db.Model):
user_id = db.Column(db.Integer, db.ForeignKey('user_basic.user_id'), doc='用户ID')
...
# 测试
user = User.query.get(1)
user.profile.gender
user.followings
2. 使用primaryjoin
class User(db.Model):
...
profile = db.relationship('UserProfile', primaryjoin='User.id==foreign(UserProfile.id)', uselist=False)
followings = db.relationship('Relation', primaryjoin='User.id==foreign(Relation.user_id)')
# 测试
user = User.query.get(1)
user.profile.gender
user.followings
3. 指定字段关联查询
class Relation(db.Model):
...
target_user = db.relationship('User', primaryjoin='Relation.target_user_id==foreign(User.id)', uselist=False)
from sqlalchemy.orm import load_only, contains_eager
Relation.query.join(Relation.target_user).options(load_only(Relation.target_user_id), contains_eager(Relation.target_user).load_only(User.name)).all()
3 更新
-
方式一
user = User.query.get(1) user.name = 'Python' db.session.add(user) db.session.commit() -
方式二
User.query.filter_by(id=1).update({'name':'python'}) db.session.commit()
4 删除
-
方式一
user = User.query.order_by(User.id.desc()).first() db.session.delete(user) db.session.commit() -
方式二
User.query.filter(User.mobile='18512345678').delete() db.session.commit()
5 事务
environ = {'wsgi.version':(1,0), 'wsgi.input': '', 'REQUEST_METHOD': 'GET', 'PATH_INFO': '/', 'SERVER_NAME': 'itcast server', 'wsgi.url_scheme': 'http', 'SERVER_PORT': '80'}
with app.request_context(environ):
try:
user = User(mobile='18911111111', name='itheima')
db.session.add(user)
db.session.flush() # 将db.session记录的sql传到数据库中执行
profile = UserProfile(id=user.id)
db.session.add(profile)
db.session.commit()
except:
db.session.rollback()========================================
数据库理论
1. 复制集与分布式
- 复制集(Replication)
- 数据库中数据相同,起到备份作用
- 高可用 High Available HA
- 分布式(Distribution)
- 数据库中数据不同,共同组成完整的数据集合
- 通常每个节点被称为一个分片(shard)
- 高吞吐 High Throughput
- 复制集与分布式可以单独使用,也可以组合使用(即每个分片都组建一个复制集)
- 关于主(Master)从(Slave)
- 这个概念是从使用的角度来阐述问题的
- 主节点 -> 表示程序在这个节点上最先更新数据
- 从节点 -> 表示这个节点的数据是要通过复制主节点而来
- 复制集 可选 主从、主主、主主从从
- 分布式 每个分片都是主,组合使用复制集的时候,复制集的是从
2. MySQL
1) 主从复制
复制分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
下图描述了这一过程:
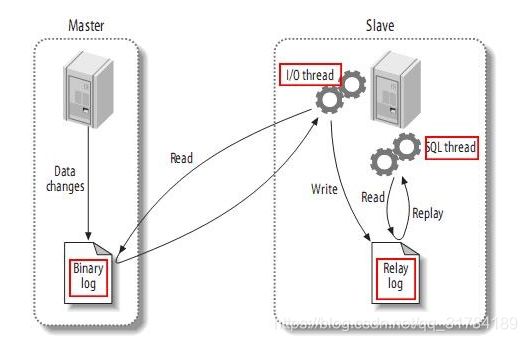
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread处理该过程的最后一步。SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。
利用主从在达到高可用的同时,也可以通过读写分离提供吞吐量。
思考:读写分离对事务是否有影响?
对于写操作包括开启事务和提交或回滚要在一台机器上执行,分散到多台master执行后数据库原生的单机事务就失效了。
对于事务中同时包含读写操作,与事务隔离级别设置有关,如果事务隔离级别为read-uncommitted 或者 read-committed,读写分离没影响,如果隔离级别为repeatable-read、serializable,读写分离就有影响,因为在slave上会看到新数据,而正在事务中的master看不到新数据。
2)分库分表(sharding)
分库分表前的问题
任何问题都是太大或者太小的问题,我们这里面对的数据量太大的问题。
-
用户请求量太大
因为单服务器TPS,内存,IO都是有限的。 解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。
-
单库太大
单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈 解决方法:切分成更多更小的库
-
单表太大
CRUD都成问题;索引膨胀,查询超时 解决方法:切分成多个数据集更小的表。
分库分表的方式方法
一般就是垂直切分和水平切分,这是一种结果集描述的切分方式,是物理空间上的切分。 我们从面临的问题,开始解决,阐述: 首先是用户请求量太大,我们就堆机器搞定(这不是本文重点)。
然后是单个库太大,这时我们要看是因为表多而导致数据多,还是因为单张表里面的数据多。 如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库。
如果是因为单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。 分库分表的顺序应该是先垂直分,后水平分。 因为垂直分更简单,更符合我们处理现实世界问题的方式。
垂直拆分
-
垂直分表
也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
-
垂直分库
垂直分库针对的是一个系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。 切分后,要放在多个服务器上,而不是一个服务器上。为什么? 我们想象一下,一个购物网站对外提供服务,会有用户,商品,订单等的CRUD。没拆分之前, 全部都是落到单一的库上的,这会让数据库的单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。 所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的“治理”,“降级”机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。 数据库往往最容易成为应用系统的瓶颈,而数据库本身属于“有状态”的,相对于Web和应用服务器来讲,是比较难实现“横向扩展”的。 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
水平拆分
-
水平分表
针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。不建议采用。
-
水平分库分表
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
-
水平分库分表切分规则
-
-
RANGE
从0到10000一个表,10001到20000一个表;
-
HASH取模 离散化
一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
-
地理区域
比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
-
时间
按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
-
分库分表后面临的问题
-
事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
-
多库结果集合并(group by,order by)
-
跨库join
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。 粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂。
分库分表方案产品
目前市面上的分库分表中间件相对较多,其中基于代理方式的有MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
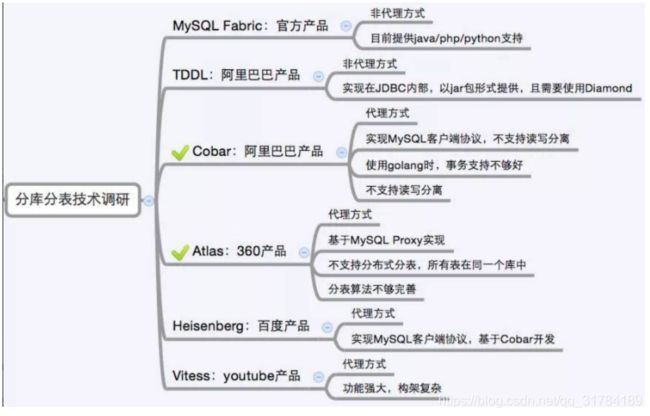
3 黑马头条项目应用
-
主从
-
垂直分表
CREATE TABLE `user_basic` ( `user_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '用户ID', `account` varchar(20) COMMENT '账号', `email` varchar(20) COMMENT '邮箱', `status` tinyint(1) NOT NULL DEFAULT '1' COMMENT '状态,是否可用,0-不可用,1-可用', `mobile` char(11) NOT NULL COMMENT '手机号', `password` varchar(93) NULL COMMENT '密码', `user_name` varchar(32) NOT NULL COMMENT '昵称', `profile_photo` varchar(128) NULL COMMENT '头像', `last_login` datetime NULL COMMENT '最后登录时间', `is_media` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否是自媒体,0-不是,1-是', `is_verified` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否实名认证,0-不是,1-是', `introduction` varchar(50) NULL COMMENT '简介', `certificate` varchar(30) NULL COMMENT '认证', `article_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '发文章数', `following_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '关注的人数', `fans_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '被关注的人数', `like_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计点赞人数', `read_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计阅读人数', PRIMARY KEY (`user_id`), UNIQUE KEY `mobile` (`mobile`), UNIQUE KEY `user_name` (`user_name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户基本信息表'; CREATE TABLE `user_profile` ( `user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID', `gender` tinyint(1) NOT NULL DEFAULT '0' COMMENT '性别,0-男,1-女', `birthday` date NULL COMMENT '生日', `real_name` varchar(32) NULL COMMENT '真实姓名', `id_number` varchar(20) NULL COMMENT '身份证号', `id_card_front` varchar(128) NULL COMMENT '身份证正面', `id_card_back` varchar(128) NULL COMMENT '身份证背面', `id_card_handheld` varchar(128) NULL COMMENT '手持身份证', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `register_media_time` datetime NULL COMMENT '注册自媒体时间', `area` varchar(20) COMMENT '地区', `company` varchar(20) COMMENT '公司', `career` varchar(20) COMMENT '职业', PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户资料表';CREATE TABLE `news_article_basic` ( `article_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '文章ID', `user_id` bigint(20) unsigned NOT NULL COMMENT '用户ID', `channel_id` int(11) unsigned NOT NULL COMMENT '频道ID', `title` varchar(128) NOT NULL COMMENT '标题', `cover` json NOT NULL COMMENT '封面', `is_advertising` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否投放广告,0-不投放,1-投放', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `status` tinyint(1) NOT NULL DEFAULT '0' COMMENT '贴文状态,0-草稿,1-待审核,2-审核通过,3-审核失败,4-已删除', `reviewer_id` int(11) NULL COMMENT '审核人员ID', `review_time` datetime NULL COMMENT '审核时间', `delete_time` datetime NULL COMMENT '删除时间', `reject_reason` varchar(200) COMMENT '驳回原因', `comment_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '累计评论数', `allow_comment` tinyint(1) NOT NULL DEFAULT '1' COMMENT '是否允许评论,0-不允许,1-允许', PRIMARY KEY (`article_id`), KEY `user_id` (`user_id`), KEY `article_status` (`status`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='文章基本信息表'; CREATE TABLE `news_article_content` ( `article_id` bigint(20) unsigned NOT NULL COMMENT '文章ID', `content` longtext NOT NULL COMMENT '文章内容', PRIMARY KEY (`article_id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='文章内容表';
======================================
分布式ID
1 方案选择
-
UUID
UUID是通用唯一识别码(Universally Unique Identifier)的缩写,开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成UUID。
UUID是由128位二进制组成,一般转换成十六进制,然后用String表示。
550e8400-e29b-41d4-a716-446655440000
UUID的优点:
- 通过本地生成,没有经过网络I/O,性能较快
- 无序,无法预测他的生成顺序。(当然这个也是他的缺点之一)
UUID的缺点:
- 128位二进制一般转换成36位的16进制,太长了只能用String存储,空间占用较多。
- 不能生成递增有序的数字
-
数据库主键自增
大家对于唯一标识最容易想到的就是主键自增,这个也是我们最常用的方法。例如我们有个订单服务,那么把订单id设置为主键自增即可。
-
单独数据库 记录主键值
-
业务数据库分别设置不同的自增起始值和固定步长,如
第一台 start 1 step 9 第二台 start 2 step 9 第三台 start 3 step 9
优点:
- 简单方便,有序递增,方便排序和分页
缺点:
- 分库分表会带来问题,需要进行改造。
- 并发性能不高,受限于数据库的性能。
- 简单递增容易被其他人猜测利用,比如你有一个用户服务用的递增,那么其他人可以根据分析注册的用户ID来得到当天你的服务有多少人注册,从而就能猜测出你这个服务当前的一个大概状况。
- 数据库宕机服务不可用。
-
-
Redis
熟悉Redis的同学,应该知道在Redis中有两个命令Incr,IncrBy,因为Redis是单线程的所以能保证原子性。
优点:
- 性能比数据库好,能满足有序递增。
缺点:
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
-
雪花算法-Snowflake
Snowflake是Twitter提出来的一个算法,其目的是生成一个64bit的整数:

- 1bit:一般是符号位,不做处理
- 41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
- 10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID
- 12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
上面只是一个将64bit划分的标准,当然也不一定这么做,可以根据不同业务的具体场景来划分,比如下面给出一个业务场景:
- 服务目前QPS10万,预计几年之内会发展到百万。
- 当前机器三地部署,上海,北京,深圳都有。
- 当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到1024,也就是2^10,那么循环位10位就足够了。
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。

时钟回拨
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,算法会直接抛出异常.
2 黑马头条
使用雪花算法 (代码 toutiao-backend/common/utils/snowflake)
# Twitter's Snowflake algorithm implementation which is used to generate distributed IDs.
# https://github.com/twitter-archive/snowflake/blob/snowflake-2010/src/main/scala/com/twitter/service/snowflake/IdWorker.scala
import time
import logging
class InvalidSystemClock(Exception):
"""
时钟回拨异常
"""
pass
# 64位ID的划分
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12
# 最大取值计算
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5-1 0b11111
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS)
# 移位偏移计算
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS
# 序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS)
# Twitter元年时间戳
TWEPOCH = 1288834974657
logger = logging.getLogger('flask.app')
class IdWorker(object):
"""
用于生成IDs
"""
def __init__(self, datacenter_id, worker_id, sequence=0):
"""
初始化
:param datacenter_id: 数据中心(机器区域)ID
:param worker_id: 机器ID
:param sequence: 其实序号
"""
# sanity check
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id值越界')
if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id值越界')
self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence
self.last_timestamp = -1 # 上次计算的时间戳
def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000)
def get_id(self):
"""
获取新ID
:return:
"""
timestamp = self._gen_timestamp()
# 时钟回拨
if timestamp < self.last_timestamp:
logging.error('clock is moving backwards. Rejecting requests until {}'.format(self.last_timestamp))
raise InvalidSystemClock
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id
def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp
if __name__ == '__main__':
worker = IdWorker(1, 2, 0)
print(worker.get_id())===============================
数据库优化
数据库是Web应用至关重要的一个环节,其性能的优劣会影响整合Web应用,所以需要对数据库进化优化以提高使用性能。以下提供几点方法作为参考。
1 理解索引
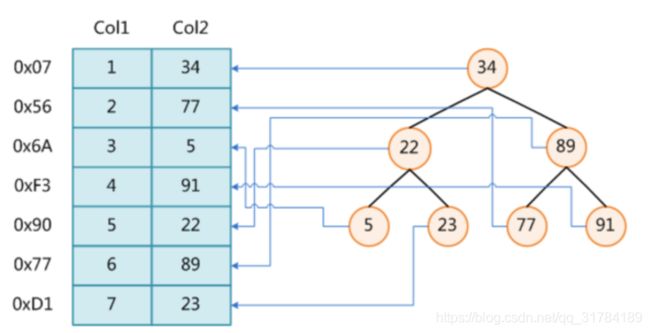
2 SQL查询优化
-
避免全表扫描,应考虑在 where 及 order by 涉及的列上建立索引;
-
查询时使用select明确指明所要查询的字段,避免使用
select *的操作; -
SQL语句尽量大写,如
SELECT name FROM t WHERE id=1对于小写的sql语句,通常数据库在解析sql语句时,通常会先转换成大写再执行。
-
尽量避免在 where 子句中使用!=或<>操作符, MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE;
SELECT id FROM t WHERE name LIKE ‘abc%’ -
对于模糊查询,如:
SELECT id FROM t WHERE name LIKE ‘%abc%’或者
SELECT id FROM t WHERE name LIKE ‘%abc’将导致全表扫描,应避免使用,若要提高效率,可以考虑全文检索;
-
遵循最左原则,在where子句中写查询条件时把索引字段放在前面,如
mobile为索引字段,name为非索引字段 推荐 SELECT ... FROM t WHERE mobile='13911111111' AND name='python' 不推荐 SELECT ... FROM t WHERE name='python' AND mobile='13911111111' 建立了复合索引 key(a, b, c) 推荐 SELECT ... FROM t WHERE a=... AND b=... AND c= ... SELECT ... FROM t WHERE a=... AND b=... SELECT ... FROM t WHERE a=... 不推荐 (字段出现顺序不符合索引建立的顺序) SELECT ... FROM t WHERE b=... AND c=... SELECT ... FROM t WHERE b=... AND a=... AND c=... ...
-
能使用关联查询解决的尽量不要使用子查询,如
子查询 SELECT article_id, title FROM t_article WHERE user_id IN (SELECT user_id FROM t_user WHERE user_name IN ('itcast', 'itheima', 'python')) 关联查询(推荐) SELECT b.article_id, b.title From t_user AS a INNER JOIN t_article AS b ON a.user_id=b.user_id WHERE a.user_name IN ('itcast', 'itheima', 'python');能不使用关联查询的尽量不要使用关联查询;
-
不需要获取全表数据的时候,不要查询全表数据,使用LIMIT来限制数据。
3 数据库优化
- 在进行表设计时,可适度增加冗余字段(反范式设计),减少JOIN操作;
- 多字段表可以进行垂直分表优化,多数据表可以进行水平分表优化;
- 选择恰当的数据类型,如整型的选择;
- 对于强调快速读取的操作,可以考虑使用MyISAM数据库引擎;
- 对较频繁的作为查询条件的字段创建索引;唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件;更新非常频繁的字段不适合创建索引;
- 编写SQL时使用上面的方式对SQL语句进行优化;
- 使用慢查询工具找出效率低下的SQL语句进行优化;
- 构建缓存,减少数据库磁盘操作;
- 可以考虑结合使用内在型数据库,如Redis,进行混合存储。
===================================
Redis
1 Redis事务
基本事务指令
Redis提供了一定的事务支持,可以保证一组操作原子执行不被打断,但是如果执行中出现错误,事务不能回滚,Redis未提供回滚支持。
multi开启事务exec执行事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set a 100
QUEUED
127.0.0.1:6379> set b 200
QUEUED
127.0.0.1:6379> get a
QUEUED
127.0.0.1:6379> get b
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
3) "100"
4) "200"
使用multi开启事务后,操作的指令并未立即执行,而是被redis记录在队列中,等待一起执行。当执行exec命令后,开始执行事务指令,最终得到每条指令的结果。
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set c 300
QUEUED
127.0.0.1:6379> hgetall a
QUEUED
127.0.0.1:6379> set d 400
QUEUED
127.0.0.1:6379> get d
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) OK
4) "400"
127.0.0.1:6379>
如果事务中出现了错误,事务并不会终止执行,而是只会记录下这条错误的信息,并继续执行后面的指令。所以事务中出错不会影响后续指令的执行。
Python客户端操作
在Redis的Python 客户端库redis-py中,提供了pipeline (称为流水线 或 管道),该工具的作用是:
- 在客户端统一收集操作指令
- 补充上multi和exec指令,当作一个事务发送到redis服务器执行
from redis import StrictRedis
r = StrictRedis.from_url('redis://127.0.0.1:6381/0')
pl = r.pipeline()
pl.set('a', 100)
pl.set('b', 200)
pl.get('a')
pl.get('b')
ret = pl.execute()
print(ret) # [True, True, b'100', b'200']
watch监视
若在构建的redis事务在执行时依赖某些值,可以使用watch对数据值进行监视。
127.0.0.1:6379> set stock 100
OK
127.0.0.1:6379> watch stock
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incrby stock -1
QUEUED
127.0.0.1:6379> incr sales
QUEUED
127.0.0.1:6379> exec
1) (integer) 99
2) (integer) 1
事务exec执行前被监视的stock值未变化,事务正确执行。
127.0.0.1:6379> set stock 100
OK
127.0.0.1:6379> watch stock
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incrby stock -1
QUEUED
127.0.0.1:6379> incr sales
QUEUED
此时在另一个客户端修改stock的值,执行
127.0.0.1:6379> incrby stock -2
(integer) 98
当第一个客户端再执行exec时
127.0.0.1:6379> exec
(nil)
表明事务需要监视的stock值发生了变化,事务不能执行了。
注意:Redis Cluster 集群不支持事务
2 Redis持久化
redis可以将数据写入到磁盘中,在停机或宕机后,再次启动redis时,将磁盘中的备份数据加载到内存中恢复使用。这是redis的持久化。持久化有如下两种机制。
RDB 快照持久化
redis可以将内存中的数据写入磁盘进行持久化。在进行持久化时,redis会创建子进程来执行。
redis默认开启了快照持久化机制。
进行快照持久化的时机如下
-
定期触发
redis的配置文件
# save # # Will save the DB if both the given number of seconds and the given # number of write operations against the DB occurred. # # In the example below the behaviour will be to save: # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed # # Note: you can disable saving completely by commenting out all "save" lines. # # It is also possible to remove all the previously configured save # points by adding a save directive with a single empty string argument # like in the following example: # # save "" save 900 1 save 300 10 save 60 10000 -
BGSAVE
执行
BGSAVE命令,手动触发RDB持久化 -
SHUTDOWN
关闭redis时触发
AOF 追加文件持久化
redis可以将执行的所有指令追加记录到文件中持久化存储,这是redis的另一种持久化机制。
redis默认未开启AOF机制。
redis可以通过配置如下项开启AOF机制
appendonly yes # 是否开启AOF
appendfilename "appendonly.aof" # AOF文件
AOF机制记录操作的时机
# appendfsync always # 每个操作都写到磁盘中
appendfsync everysec # 每秒写一次磁盘,默认
# appendfsync no # 由操作系统决定写入磁盘的时机
使用AOF机制的缺点是随着时间的流逝,AOF文件会变得很大。但redis可以压缩AOF文件。
结合使用
redis允许我们同时使用两种机制,通常情况下我们会设置AOF机制为everysec 每秒写入,则最坏仅会丢失一秒内的数据。
3 Redis高可用
为了保证redis最大程度上能够使用,redis提供了主从同步+Sentinel哨兵机制。
Sentinel 哨兵
https://redis.io/topics/sentinel
redis提供的哨兵是用来看护redis实例进程的,可以自动进行故障转移,其功能如下:
- Monitoring. Sentinel constantly checks if your master and slave instances are working as expected.
- Notification. Sentinel can notify the system administrator, another computer programs, via an API, that something is wrong with one of the monitored Redis instances.
- Automatic failover. If a master is not working as expected, Sentinel can start a failover process where a slave is promoted to master, the other additional slaves are reconfigured to use the new master, and the applications using the Redis server informed about the new address to use when connecting.
- Configuration provider. Sentinel acts as a source of authority for clients service discovery: clients connect to Sentinels in order to ask for the address of the current Redis master responsible for a given service. If a failover occurs, Sentinels will report the new address
在redis安装后,会自带sentinel哨兵程序,修改sentinel.conf配置文件
bind 127.0.0.1
port 26380
daemonize yes
logfile /var/log/redis-sentinel.log
sentinel monitor mymaster 127.0.0.1 6380 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
- sentinel monitor mymaster 127.0.0.1 6380 2 说明
- mymaster 为sentinel监护的redis主从集群起名
- 127.0.0.1 6300 为主从中任一台机器地址
- 2 表示有两台以的sentinel认为某一台redis宕机后,才会进行自动故障转移。
启动方式:
redis-sentinel sentinel.conf
高可用方案注意事项
- 至少三个sentinel以上
- sentinel要分散运行在不同的机器上
Python客户端使用
# redis 哨兵
REDIS_SENTINELS = [
('127.0.0.1', '26380'),
('127.0.0.1', '26381'),
('127.0.0.1', '26382'),
]
REDIS_SENTINEL_SERVICE_NAME = 'mymaster'
from redis.sentinel import Sentinel
_sentinel = Sentinel(REDIS_SENTINELS)
redis_master = _sentinel.master_for(REDIS_SENTINEL_SERVICE_NAME)
redis_slave = _sentinel.slave_for(REDIS_SENTINEL_SERVICE_NAME)
使用示例
# 读数据,master读不到去slave读
try:
real_code = redis_master.get(key)
except ConnectionError as e:
real_code = redis_slave.get(key)
# 写数据,只能在master里写
try:
current_app.redis_master.delete(key)
except ConnectionError as e:
logger.error(e)
4 Redis集群
https://redis.io/topics/partitioning
Reids Cluster集群方案,内部已经集成了sentinel机制来做到高可用。
Python客户端
# redis 集群
REDIS_CLUSTER = [
{'host': '127.0.0.1', 'port': '7000'},
{'host': '127.0.0.1', 'port': '7001'},
{'host': '127.0.0.1', 'port': '7002'},
]
from rediscluster import StrictRedisCluster
redis_cluster = StrictRedisCluster(startup_nodes=REDIS_CLUSTER)
# 可以将redis_cluster就当作普通的redis客户端使用
redis_master.delete(key)
注意:
- redis cluster 不支持事务
- redis cluster 不支持多键操作,如mset
5 用途
- 缓存
- 持久存储
- 数据库的统计冗余字段 放到 redis中保存
6 相关补充阅读
- https://redis.io/documentation
- 《Redis实践》 (Redis in action)