深入学习java源码之stream.peek()与stream.concat()
深入学习java源码之stream.peek()与stream.concat()
Java8为集合类引入了另一个重要概念:流(stream)。一个流通常以一个集合类实例为其数据源,然后在其上定义各种操作。流的API设计使用了管道(pipelines)模式。对流的一次操作会返回另一个流。如同IO的API或者StringBuffer的append方法那样,从而多个不同的操作可以在一个语句里串起来。
Function接口
Function
T—函数的输入类型
R-函数的输出类型
该函数式接口唯一的抽象方法apply接收一个参数,有返回值
Function接口定义中有两个泛型,按着接口文档说明第一个泛型是输入类型,第二泛型是结果类型。
compose方法接收一个Function参数before,该方法说明是返回一个组合的函数,首先会应用before,然后应用当前对象,换句话说就是先执行before对象的apply,再执行当前对象的apply,将两个执行逻辑串起来。
andThen方法接收一个Function参数after,与compose方法相反,它是先执行当前对象的apply方法,再执行after对象的方法。
@FunctionalInterface
public interface Function {
R apply(T t);
default Function compose(Function before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default Function andThen(Function after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
}
该函数式接口唯一的抽象方法apply接收一个参数,有返回值。
我们在FunctionTest中定义了compute方法,方法的第一个参数是要运算的数据,第二个参数是函数式接口Function的实例,当执行compute方法时,会将第一个参数交给第二个参数Function中的apply方法处理,然后返回结果。
这样我们可以将方法定义的更抽象,代码重用性也就越高,每次将要计算的数据和计算逻辑一起作为参数传递给compute方法就可以。是不是有点体验到函数式编程的灵活之处。
注:因为表达式只有一行语句 num -> num + 2 可以省略了return 关键字 如果为了更加直观可以写成 num -> return num + 2
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
int i2 = functionTest.add2(2);
int i3 = functionTest.add3(2);
int i4 = functionTest.add4(2);
}
//逻辑提前定义好
public int add2(int i){
return i + 2;
}
//逻辑提前定义好
public int add3(int i){
return i + 3;
}
//逻辑提前定义好
public int add4(int i){
return i + 4;
}
}
//函数式接口代替
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
int result2 = functionTest.compute(5, num -> num + 2);
int result3 = functionTest.compute(5, num -> num + 2);
int result4 = functionTest.compute(5, num -> num + 2);
int results = functionTest.compute(5, num -> num * num);
}
//调用时传入逻辑
public int compute(int i, Function function){
Integer result = function.apply(i);
return result;
}
}
定义了compute1和compute2两个方法,compute1方法第一个参数是要计算的数据,第二个参数是后执行的函数,第一个是先执行的函数,因为输入输出都是数字类型,所以泛型都指定为Integer类型,通过after.compose(before);将两个函数串联起来然后执行组合后的Funtion方法apply(i)。当调用compute1(5,i -> i 2,i -> i i)时,先平方再乘以2所以结果是50。而compute2方法对两个Function的调用正好相反,所以结果是100。
public class FunctionTest {
public static void main(String[] args) {
FunctionTest functionTest = new FunctionTest();
System.out.println(functionTest.compute1(5,i -> i * 2,i -> i * i));//50
System.out.println(functionTest.compute2(5,i -> i * 2,i -> i * i));//100
}
public int compute1(int i, Function after,Function before){
return after.compose(before).apply(i);
}
public int compute2(int i, Function before,Function after){
return before.andThen(after).apply(i);
}
}
BiFunction接口
另一个很常用的函数式接口BiFunction
@FunctionalInterface
public interface BiFunction {
R apply(T t, U u);
default BiFunction andThen(Function after) {
Objects.requireNonNull(after);
return (T t, U u) -> after.apply(apply(t, u));
}
} BiFunction接口实际上就是可以有两个参数的Function,同样前两个泛型代表着入参的类型,第三个代表结果类型。
看下compute方法,前两个参数是待计算数据,第三个是一个BiFunction,因为入参和结果都是数组所以三个泛型都定义为Integer。最后一个参数是Function。计算逻辑是先执行BiFunction然后将结果传给Funciton在计算最后返回结果,所以使用了andThen方法。我们想一下,BiFunction的andThen方法为什么接收的是Function类型的参数而不是BiFunction,答案很简单,因为BiFunction的apply方法接收两个参数,但是任何一个方法不可能有两个返回值,所以也没办法放在BiFunction前面执行,这也是为什么BiFunction没有compose方法的原因。
public class BiFunctionTest {
public static void main(String[] args) {
BiFunctionTest2 biFunctionTest2 = new BiFunctionTest2();
System.out.println(biFunctionTest2.compute(4,5,(a,b) -> a * b,a -> a * 2));
}
public int compute(int a, int b, BiFunction biFunction,
Function function){
return biFunction.andThen(function).apply(a,b);
}
} 通过BiFunction这个函数,可以将一个类型转换为另一个类型,比如下面的例子:
//定义一个function 输入是String类型,输出是 EventInfo 类型, EventInfo是一个类。
Function times2 = fun -> { EventInfo a = new EventInfo(); a.setName(fun); return a;};
String[] testintStrings={"1","2","3","4"};
//将String的Array转换成map,调用times2函数进行转换
Map eventmap1=Stream.of(testintStrings).collect(Collectors.toMap(inputvalue->inputvalue, inputvalue->times2.apply(inputvalue))); 如果Collectors.toMap的转换过程很简单,比如输入和输出类型相同,则不需要另外定义Function,例如:
Map eventmap2=Stream.of(testStrings).collect(Collectors.toMap(inputvalue->inputvalue, inputvalue->(inputvalue+”a”)));
Supplier接口
默认抽象方法get不接收参数,有返回值
@FunctionalInterface
public interface Supplier {
T get();
} 类似工厂模式
这里使用构造方法引用的方式创建Supplier实例,通过get直接返回String对象
public class SupplierTest {
public static void main(String[] args) {
Supplier supplier = String::new;
String s = supplier.get();
}
}
Predicate函数式接口
@FunctionalInterface
public interface Predicate {
boolean test(T t);
} 接收一个参数,返回布尔类型,使用方式
定义了一个接收一个参数返回布尔值的lambda表达式,赋值给predicate,就可以直接对传入参数进行校验。
这段程序的逻辑是找到集合里大于5的数据,打印到控制台。
public class PredicateTest {
public static void main(String[] args) {
Predicate predicate = s -> s.length() > 5;
System.out.println(predicate.test("hello"));
}
} 我们具体分析一下conditionFilter方法,第一个参数是待遍历的集合,第二个参数是Predicate类型的实例,还记得Predicate接口中的抽象方法定义吗,接收一个参数返回布尔类型。list
public class PredicateTest {
public static void main(String[] args) {
List list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
PredicateTest predicateTest = new PredicateTest();
List result = predicateTest.conditionFilter(list, integer -> integer > 5);
result.forEach(System.out::println);
}
public List conditionFilter(List list, Predicate predicate){
return list.stream().filter(predicate).collect(Collectors.toList());
}
} 调用conditionFilter方法,方法引用实例化一个Consumer对象,把结果输出到控制台。
List result = predicateTest.conditionFilter(list, integer -> integer > 5).forEach(System.out::println);
Predicate在stream api中进行一些判断的时候非常常用。
public class PredicateTest {
public static void main(String[] args) {
List list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
PredicateTest predicateTest = new PredicateTest();
//输出大于5的数字
List result = predicateTest.conditionFilter(list, integer -> integer > 5);
result.forEach(System.out::println);
System.out.println("-------");
//输出大于等于5的数字
result = predicateTest.conditionFilter(list, integer -> integer >= 5);
result.forEach(System.out::println);
System.out.println("-------");
//输出小于8的数字
result = predicateTest.conditionFilter(list, integer -> integer < 8);
result.forEach(System.out::println);
System.out.println("-------");
//输出所有数字
result = predicateTest.conditionFilter(list, integer -> true);
result.forEach(System.out::println);
System.out.println("-------");
}
//高度抽象的方法定义,复用性高
public List conditionFilter(List list, Predicate predicate){
return list.stream().filter(predicate).collect(Collectors.toList());
}
} stream()会将当前list作为源创建一个Stream对象,collect(Collectors.toList())是将最终的结果封装在ArrayList中
filter方法接收一个Predicate类型参数用于对目标集合进行过滤。里面并没有任何具体的逻辑,提供了一种更高层次的抽象化,我们可以把要处理的数据和具体的逻辑通过参数传递给conditionFilter即可
Predicate还提供了另外三个默认方法和一个静态方法
and方法接收一个Predicate类型,也就是将传入的条件和当前条件以并且的关系过滤数据。or方法同样接收一个Predicate类型,将传入的条件和当前的条件以或者的关系过滤数据。negate就是将当前条件取反。
public List conditionFilterNegate(List list, Predicate predicate){
return list.stream().filter(predicate.negate()).collect(Collectors.toList());
}
public List conditionFilterAnd(List list, Predicate predicate,Predicate predicate2){
return list.stream().filter(predicate.and(predicate2)).collect(Collectors.toList());
}
public List conditionFilterOr(List list, Predicate predicate,Predicate predicate2){
return list.stream().filter(predicate.or(predicate2)).collect(Collectors.toList());
} 大于5并且是偶数
result = predicateTest.conditionFilterAnd(list, integer -> integer > 5, integer1 -> integer1 % 2 == 0);
result.forEach(System.out::println);//6 8 10
System.out.println("-------");大于5或者是偶数
result = predicateTest.conditionFilterOr(list, integer -> integer > 5, integer1 -> integer1 % 2 == 0);
result.forEach(System.out::println);//2 4 6 8 9 10
System.out.println("-------");条件取反
result = predicateTest.conditionFilterNegate(list,integer2 -> integer2 > 5);
result.forEach(System.out::println);// 1 2 3 4 5
System.out.println("-------");isEqual方法返回类型也是Predicate,也就是说通过isEqual方法得到的也是一个用来进行条件判断的函数式接口实例。而返回的这个函数式接口实例是通过传入的targetRef的equals方法进行判断的。我们看一下具体用法
System.out.println(Predicate.isEqual("test").test("test"));//true
Optional类
Optional并不是一系列函数式接口,它是一个class,主要作用就是解决Java中的NPE(NullPointerException)。空指针异常在程序运行中出现的频率非常大,我们经常遇到需要在逻辑处理前判断一个对象是否为null的情况。
Optional类如何避免空指针问题,首先,ofNullable方法接收一个可能为null的参数,将参数的值赋给Optional类中的成员变量value,ifPresent方法接收一个Consumer类型函数式接口实例,再将成员变量value交给Consumer的accept方法处理前,会校验成员变量value是否为null,如果value是null,则什么也不会执行,避免了空指针问题。
如果传入的内容是空,则什么也不会执行,也不会有空指针异常
public void ifPresent(Consumer consumer) {
if (value != null)
consumer.accept(value);
}
String str = "hello";
Optional optional = Optional.ofNullable(str);
optional.ifPresent(s -> System.out.println(s));//value为hello,正常输出
如果为空时想返回一个默认值
orElseGet方法接收一个Supplier,还记得前面介绍的Supplier么,不接受参数通过get方法直接返回结果,类似工厂模式,上面代码就是针对传入的str变量,如果不为null那正常输出,如果为null,那返回一个默认值"welcome"
public T orElseGet(Supplier other) {
return value != null ? value : other.get();
}
String str = null;
Optional optional = Optional.ofNullable(str);
System.out.println(optional.orElseGet(() -> "welcome"));
方法引用
(方法引用和lambda一样是Java8新语言特性)
方法引用是lambda表达式的一种特殊形式,如果正好有某个方法满足一个lambda表达式的形式,那就可以将这个lambda表达式用方法引用的方式表示,但是如果这个lambda表达式的比较复杂就不能用方法引用进行替换。实际上方法引用是lambda表达式的一种语法糖。
方法引用共分为四类:
1.类名::静态方法名
2.对象::实例方法名
3.类名::实例方法名
4.类名::new
前两种方式类似,等同于把lambda表达式的参数直接当成instanceMethod|staticMethod的参数来调用。比如System.out::println等同于x->System.out.println(x);Math::max等同于(x, y)->Math.max(x,y)。
类名::静态方法名
Student类有两个属性name和score并提供了初始化name和score的构造方法,并且在最下方提供了两个静态方法分别按score和name进行比较先后顺序。
接下来的需求是,按着分数由小到大排列并输出
sort方法接收一个Comparator函数式接口,接口中唯一的抽象方法compare接收两个参数返回一个int类型值,下方是Comparator接口定义
@FunctionalInterface
public interface Comparator {
int compare(T o1, T o2);
} public class Student {
private String name;
private int score;
public Student(){
}
public Student(String name,int score){
this.name = name;
this.score = score;
}
public static int compareStudentByScore(Student student1,Student student2){
return student1.getScore() - student2.getScore();
}
}
Student student1 = new Student("zhangsan",60);
Student student2 = new Student("lisi",70);
Student student3 = new Student("wangwu",80);
Student student4 = new Student("zhaoliu",90);
List students = Arrays.asList(student1,student2,student3,student4);
students.sort((o1, o2) -> o1.getScore() - o2.getScore());
students.forEach(student -> System.out.println(student.getScore())); compareStudentByScore静态方法,同样是接收两个参数返回一个int类型值,而且是对Student对象的分数进行比较,所以我们这里就可以 使用类名::静态方法名 方法引用替换lambda表达式
students.sort(Student::compareStudentByScore);
students.forEach(student -> System.out.println(student.getScore()));我们再自定义一个用于比较Student元素的类
public class StudentComparator {
public int compareStudentByScore(Student student1,Student student2){
return student2.getScore() - student1.getScore();
}
}StudentComparator中定义了一个非静态的,实例方法compareStudentByScore,同样该方法的定义满足Comparator接口的compare方法定义,所以这里可以直接使用 对象::实例方法名 的方式使用方法引用来替换lambda表达式。
StudentComparator studentComparator = new StudentComparator();
students.sort(studentComparator::compareStudentByScore);
students.forEach(student -> System.out.println(student.getScore()));
第三种,类名::实例方法名 。这种方法引用的方式较之前两种稍微有一些不好理解,因为无论是通过类名调用静态方法还是通过对象调用实例方法这都是符合Java的语法,使用起来也比较清晰明了。
等同于把lambda表达式的第一个参数当成instanceMethod的目标对象,其他剩余参数当成该方法的参数。比如String::toLowerCase等同于x->x.toLowerCase()。
可以这么理解,前两种是将传入对象当参数执行方法,第三种是调用传入对象的方法。
Student类中静态方法的定义改进
作为一个工具正常使用,但是有没有觉得其在设计上是不合适的或者是错误的。这样的方法定义放在任何一个类中都可以正常使用,而不只是从属于Student这个类,那如果要定义一个只能从属于Student类的比较方法下面这个实例方法更合适一些
public int compareByScore(Student student){
return this.getScore() - student.getScore();
}接收一个Student对象和当前调用该方法的Student对象的分数进行比较即可。现在我们就可以使用 类名::实例方法名 这种方式的方法引用替换lambda表达式了。
sort方法接收的lambda表达式不应该是两个参数么,为什么这个实例方法只有一个参数也满足了lambda表达式的定义(想想这个方法是谁来调用的)。这就是 类名::实例方法名 这种方法引用的特殊之处:当使用 类名::实例方法名 方法引用时,一定是lambda表达式所接收的第一个参数来调用实例方法,如果lambda表达式接收多个参数,其余的参数作为方法的参数传递进去。
students.sort(Student::compareByScore);
students.forEach(student -> System.out.println(student.getScore()));最初的lambda表达式是这样的
那使用 类名::实例方法名 方法引用时,一定是o1来调用了compareByScore实例方法,并将o2作为参数传递进来进行比较。是不是就符合了compareByScore的方法定义。
students.sort((o1, o2) -> o1.getScore() - o2.getScore());将列表中的字符串转换为全小写
List proNames = Arrays.asList(new String[]{"Ni","Hao","Lambda"});
List lowercaseNames3 = proNames.stream().map(String::toLowerCase).collect(Collectors.toList());
等价于
List lowercaseNames1 = proNames.stream().map(name -> {return name.toLowerCase();}).collect(Collectors.toList());
第四种是构造器引用,构造器引用语法如下:类名::new,把lambda表达式的参数当成ClassName构造器的参数 。
例如BigDecimal::new等同于x->new BigDecimal(x)。
和前面类似只要符合lambda表达式的定义即可。
Supplier函数式接口的get方法,不接收参数有返回值,正好符合无参构造方法的定义
@FunctionalInterface
public interface Supplier {
T get();
}
Supplier supplier = Student::new; 上面就是使用了Student类构造方法引用创建了supplier实例,以后通过supplier.get()就可以获取一个Student类型的对象,前提是Student类中存在无参构造方法。
我们给Test1新添加了一个构造方法,该构造方法接收一个参数,不返回值,编译通过。(仅为展示构造方法引用的用法)
public class Test1 {
public static void main(String[] args) {
List list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
//构造方法引用
list.forEach(Test1::new);
}
Test1(Integer i){
System.out.println(i);
}
}
Stream语法
Java8中的Stream与lambda表达式可以说是相伴相生的,通过Stream我们可以更好的更为流畅更为语义化的操作集合。Stream api都位于java.util.stream包中。其中就包含了最核心的Stream接口,一个Stream实例可以串行或者并行操作一组元素序列。
Java8中,所有的流操作会被组合到一个 stream pipeline中,这点类似linux中的pipeline概念,将多个简单操作连接在一起组成一个功能强大的操作。一个 stream pileline首先会有一个数据源,这个数据源可能是数组、集合、生成器函数或是IO通道,流操作过程中并不会修改源中的数据;然后还有零个或多个中间操作,每个中间操作会将接收到的流转换成另一个流(比如filter);最后还有一个终止操作,会生成一个最终结果(比如sum)。流是一种惰性操作,所有对源数据的计算只在终止操作被初始化的时候才会执行。
总结一下流操作由3部分组成
1.源
2.零个或多个中间操作
3.终止操作 (到这一步才会执行整个stream pipeline计算)
两句话理解Stream:
1.Stream是元素的集合,这点让Stream看起来用些类似Iterator;
2.可以支持顺序和并行的对原Stream进行汇聚的操作;
public interface Stream extends BaseStream> {
Stream filter(Predicate predicate);
Stream map(Function mapper);
void forEach(Consumer action);
.
.省略
.
} 大家可以把Stream当成一个装饰后的Iterator。原始版本的Iterator,用户只能逐个遍历元素并对其执行某些操作;包装后的Stream,用户只要给出需要对其包含的元素执行什么操作,比如“过滤掉长度大于10的字符串”、“获取每个字符串的首字母”等,具体这些操作如何应用到每个元素上,就给Stream就好了!原先是人告诉计算机一步一步怎么做,现在是告诉计算机做什么,计算机自己决定怎么做。当然这个“怎么做”还是比较弱的。
import com.google.common.collect.Lists;
//Lists是Guava中的一个工具类
List nums = Lists.newArrayList(1,null,3,4,null,6);
nums.stream().filter(num -> num != null).count(); 上面这段代码是获取一个List中,元素不为null的个数。这段代码虽然很简短,但是却是一个很好的入门级别的例子来体现如何使用Stream,正所谓“麻雀虽小五脏俱全”。我们现在开始深入解刨这个例子,完成以后你可能可以基本掌握Stream的用法!

可以很清楚的看见:原本一条语句被三种颜色的框分割成了三个部分。红色框中的语句是一个Stream的生命开始的地方,负责创建一个Stream实例;绿色框中的语句是赋予Stream灵魂的地方,把一个Stream转换成另外一个Stream,红框的语句生成的是一个包含所有nums变量的Stream,进过绿框的filter方法以后,重新生成了一个过滤掉原nums列表所有null以后的Stream;蓝色框中的语句是丰收的地方,把Stream的里面包含的内容按照某种算法来汇聚成一个值,例子中是获取Stream中包含的元素个数。如果这样解析以后,还不理解,那就只能动用“核武器”–图形化,一图抵千言!

使用Stream的基本步骤:
1.创建Stream;
2.转换Stream,每次转换原有Stream对象不改变,返回一个新的Stream对象(**可以有多次转换**);
3.对Stream进行聚合(Reduce)操作,获取想要的结果;
存在一个字符串集合,我们想把所有长度大于5的字符串转换成大写输出到控制台,之前我们可能会直接这么做
List list = Arrays.asList("hello","world","helloworld");
for (int i = 0; i < list.size(); i++) {
if(list.get(i).length() > 5){
System.out.println(list.get(i).toUpperCase());
}
} 换成使用stream api
List list = Arrays.asList("hello","world","helloworld");
list.stream().filter(s -> s.length() > 5).map(s -> s.toUpperCase()).forEach(System.out::println); 1行代码直接搞定,而且这种链式编程风格从语义上看逻辑很清晰。
stream方法先构造了一个该集合的Stream对象,filter方法取出长度大于5的字符串,map方法将所有字符串转大写,forEach输出到控制台。
filter方法,接收一个Predicate函数式接口类型作为参数,并返回一个Stream对象,从上一篇我们知道可以由一个接收一个参数返回布尔类型的lambda表达式来创建Predicate函数式接口实例,所以看到filter接收的参数是s -> s.length() > 5
map方法,接收Function函数式接口类型,接收一个参数,有返回值s -> s.toUpperCase() 正是做了这件事情
forEach方法,接收Consumer函数式接口类型,接收一个参数,不返回值 这里使用方法引用的其中一种形式System.out::println来创建了Consumer实例。
所以通过上面的例子可以看出函数式编程和stream api结合的非常紧密。大家应该也注意到了在介绍每个方法时,我们提到了有中间操作和终止操作,终止操作意味着我们需要一个结果了,当程序遇到终止操作时才会真正执行。中间操作是指在终止操作之前所有的方法,这些方法以方法链的形式组织在一起处理一些列逻辑,如果只有中间操作而没有终止操作的话即使运行程序,代码也不会执行的。
实际上map方法中可以使用另一种方法引用的形式来处理,类方法引用。语法:类名::方法名
List list = Arrays.asList("hello","world","helloworld");
list.stream().filter(s -> s.length() > 5).map(String::toUpperCase).forEach(System.out::println); map方法接收一个Function函数式接口的实现,那就肯定需要一个输入并且有一个输出,但是我们看下toUpperCase方法的定义
public String toUpperCase() {
return toUpperCase(Locale.getDefault());
}有返回值,但是没有入参,乍一看也不符合Function接口中apply方法的定义啊。这也是类方法引用的特点,虽然toUpperCase没有明确的入参,因为此时toUpperCase的输入是调用它的那个对象,编译器会把调用toUpperCase方法的那个对象当做参数,也就是lambda表达式s -> s.toUpperCase()中的s参数。所以也满足一个输入一个输出的定义。
最常用的创建流的几种方式:
//第一种 通过Stream接口的of静态方法创建一个流
Stream stream = Stream.of("hello", "world", "helloworld");
//第二种 通过Arrays类的stream方法,实际上第一种of方法底层也是调用的Arrays.stream(values);
String[] array = new String[]{"hello","world","helloworld"};
Stream stream3 = Arrays.stream(array);
//第三种 通过集合的stream方法,该方法是Collection接口的默认方法,所有集合都继承了该方法
Stream stream2 = Arrays.asList("hello","world","helloworld").stream();
//第四种
通过Stream接口的静态工厂方法(注意:Java8里接口可以带静态方法);
//第五种
通过Collection接口的默认方法(默认方法:Default method,也是Java8中的一个新特性,就是接口中的一个带有实现的方法)–stream(),把一个Collection对象转换成Stream 1. of方法:有两个overload方法,一个接受变长参数,一个接口单一值
Stream integerStream = Stream.of(1, 2, 3, 5);
Stream stringStream = Stream.of("taobao"); 2. generator方法:生成一个无限长度的Stream,其元素的生成是通过给定的Supplier(这个接口可以看成一个对象的工厂,每次调用返回一个给定类型的对象)
Stream.generate(new Supplier() {
@Override
public Double get() {
return Math.random();
}
});
Stream.generate(() -> Math.random());
Stream.generate(Math::random);
三条语句的作用都是一样的,只是使用了lambda表达式和方法引用的语法来简化代码。每条语句其实都是生成一个无限长度的Stream,其中值是随机的。这个无限长度Stream是懒加载,一般这种无限长度的Stream都会配合Stream的limit()方法来用。
3. iterate方法:也是生成无限长度的Stream,和generator不同的是,其元素的生成是重复对给定的种子值(seed)调用用户指定函数来生成的。其中包含的元素可以认为是:seed,f(seed),f(f(seed))无限循环
Stream.iterate(1, item -> item + 1).limit(10).forEach(System.out::println);这段代码就是先获取一个无限长度的正整数集合的Stream,然后取出前10个打印。千万记住使用limit方法,不然会无限打印下去。
Collection接口有一个stream方法,所以其所有子类都都可以获取对应的Stream对象。
public interface Collection extends Iterable {
//其他方法省略
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
}
} 2. filter: 对于Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素;

同时获取最大 最小 平均值等信息
List list1 = Arrays.asList(1, 3, 5, 7, 9, 11);
IntSummaryStatistics statistics = list1.stream().filter(integer -> integer > 2).mapToInt(i -> i * 2).skip(2).limit(2).summaryStatistics();
System.out.println(statistics.getMax());//18
System.out.println(statistics.getMin());//14
System.out.println(statistics.getAverage());//16 将list1中的数据取出大于2的,每个数进行平方计算,skip(2)忽略前两个,limit(2)再取出前两个,summaryStatistics对取出的这两个数计算统计数据。mapToInt接收一个ToIntFunction类型,也就是接收一个参数返回值是int类型。
3. map: 对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗;

stream().map(),您可以将对象转换为其他对象。
Stream的map方法,map方法接收一个Function函数式接口实例,这里的map和Hadoop中的map概念完全一致,对每个元素进行映射处理。然后传入lambda表达式将每个元素转换大写,通过collect方法将结果收集到ArrayList中。
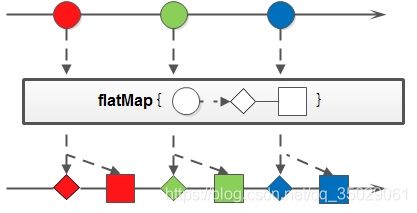
Stream map(Function mapper);//map函数定义 4. flatMap:和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中;
map方法是将一个容器里的元素映射到另一个容器中。
flatMap方法,可以将多个容器的元素全部映射到一个容器中,即为扁平的map。
Stream> inputStream = Stream.of(
Arrays.asList(1),
Arrays.asList(2, 3),
Arrays.asList(4, 5, 6)
);
Stream outputStream = inputStream.
flatMap((childList) -> childList.stream()); flatMap 把 input Stream 中的层级结构扁平化,就是将最底层元素抽出来放到一起,最终 output 的新 Stream 里面已经没有 List 了,都是直接的数字。
求每个元素平方的例子
Stream> listStream =
Stream.of(Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6));
List collect1 = listStream.flatMap(theList -> theList.stream()).
map(integer -> integer * integer).collect(Collectors.toList()); 首先我们创建了一个Stream对象,Stream中的每个元素都是容器List
peek: 生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer实例),新Stream每个元素被消费的时候都会执行给定的消费函数;

limit: 对一个Stream进行截断操作,获取其前N个元素,如果原Stream中包含的元素个数小于N,那就获取其所有的元素;

skip: 返回一个丢弃原Stream的前N个元素后剩下元素组成的新Stream,如果原Stream中包含的元素个数小于N,那么返回空Stream;

List nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
System.out.println(“sum is:”+nums.stream().filter(num -> num != null).distinct().mapToInt(num -> num * 2).peek(System.out::println).skip(2).limit(4).sum());
2
4
6
8
10
12
sum is:36 这段代码演示了上面介绍的所有转换方法(除了flatMap),简单解释一下这段代码的含义:给定一个Integer类型的List,获取其对应的Stream对象,然后进行过滤掉null,再去重,再每个元素乘以2,再每个元素被消费的时候打印自身,在跳过前两个元素,最后去前四个元素进行加和运算(解释一大堆,很像废话,因为基本看了方法名就知道要做什么了。这个就是声明式编程的一大好处!)。
在对于一个Stream进行多次转换操作,每次都对Stream的每个元素进行转换,而且是执行多次,这样时间复杂度就是一个for循环里把所有操作都做掉的N(转换的次数)倍啊。其实不是这样的,转换操作都是lazy的,多个转换操作只会在汇聚操作的时候融合起来,一次循环完成。我们可以这样简单的理解,Stream里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在汇聚操作的时候循环Stream对应的集合,然后对每个元素执行所有的函数。
Stream中的一个静态方法,generate方法
generate接收一个Supplier
public static Stream generate(Supplier s) {
Objects.requireNonNull(s);
return StreamSupport.stream(
new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);
} 适合生成连续不断的流或者一个全部是随机数的流
Stream.generate(UUID.randomUUID()::toString).findFirst().ifPresent(System.out::println);使用UUID.randomUUID()::toString 方法引用的方式创建了Supplier,然后取出第一个元素,这里的findFirst返回的是 Optional,因为流中有可能没有元素,为了避免空指针,在使用前 ifPresent 进行是否存在的判断。
另一个静态方法,iterate
public static Stream iterate(final T seed, final UnaryOperator f) {
Objects.requireNonNull(f);
final Iterator iterator = new Iterator() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator,
Spliterator.ORDERED | Spliterator.IMMUTABLE), false);
} iterate方法有两个参数,第一个是seed也可以称作种子,第二个是一个UnaryOperator,UnaryOperator实际上是Function的一个子接口,和Funciton区别就是参数和返回类型都是同一种类型
@FunctionalInterface
public interface UnaryOperator extends Function {
} iterate方法第一次生成的元素是UnaryOperator对seed执行apply后的返回值,之后所有生成的元素都是UnaryOperator对上一个apply的返回值再执行apply,不断循环。
f(f(f(f(f(f(n))))))......
//从1开始,每个元素比前一个元素大2,最多生成10个元素
Stream.iterate(1,item -> item + 2).limit(10).forEach(System.out::println);我们在使用stream api时也要注意一些陷阱,比如下面这个例子
//Stream陷阱 distinct()会一直等待产生的结果去重,将distinct()和limit(6)调换位置,先限制结果集再去重就可以了
IntStream.iterate(0,i -> (i + 1) % 2).distinct().limit(6).forEach(System.out::println);如果distinct()一直等待那程序会一直执行不断生成数据,所以需要先限制结果集再去进行去重操作就可以了。
汇聚操作(也称为折叠)接受一个元素序列为输入,反复使用某个合并操作,把序列中的元素合并成一个汇总的结果。比如查找一个数字列表的总和或者最大值,或者把这些数字累积成一个List对象。Stream接口有一些通用的汇聚操作,比如reduce()和collect();也有一些特定用途的汇聚操作,比如sum(),max()和count()。注意:sum方法不是所有的Stream对象都有的,只有IntStream、LongStream和DoubleStream是实例才有。
下面会分两部分来介绍汇聚操作:
可变汇聚:把输入的元素们累积到一个可变的容器中,比如Collection或者StringBuilder;
其他汇聚:除去可变汇聚剩下的,一般都不是通过反复修改某个可变对象,而是通过把前一次的汇聚结果当成下一次的入参,反复如此。比如reduce,count,allMatch;
可变汇聚对应的只有一个方法:collect,正如其名字显示的,它可以把Stream中的要有元素收集到一个结果容器中(比如Collection)。先看一下最通用的collect方法的定义(还有其他override方法):
R collect(Supplier supplier,
BiConsumer accumulator,
BiConsumer combiner); 先来看看这三个参数的含义:Supplier supplier是一个工厂函数,用来生成一个新的容器;BiConsumer accumulator也是一个函数,用来把Stream中的元素添加到结果容器中;BiConsumer combiner还是一个函数,用来把中间状态的多个结果容器合并成为一个(并发的时候会用到)。看晕了?来段代码!
List nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
List numsWithoutNull = nums.stream().filter(num -> num != null).
collect(() -> new ArrayList(),
(list, item) -> list.add(item),
(list1, list2) -> list1.addAll(list2)); 上面这段代码就是对一个元素是Integer类型的List,先过滤掉全部的null,然后把剩下的元素收集到一个新的List中。进一步看一下collect方法的三个参数,都是lambda形式的函数。
第一个函数生成一个新的ArrayList实例;
第二个函数接受两个参数,第一个是前面生成的ArrayList对象,二个是stream中包含的元素,函数体就是把stream中的元素加入ArrayList对象中。第二个函数被反复调用直到原stream的元素被消费完毕;
第三个函数也是接受两个参数,这两个都是ArrayList类型的,函数体就是把第二个ArrayList全部加入到第一个中;
但是上面的collect方法调用也有点太复杂了,没关系!我们来看一下collect方法另外一个override的版本,其依赖[Collector]
这样清爽多了!Java8还给我们提供了Collector的工具类–[Collectors],其中已经定义了一些静态工厂方法,比如:Collectors.toCollection()收集到Collection中, Collectors.toList()收集到List中和Collectors.toSet()收集到Set中。这样的静态方法还有很多,这里就不一一介绍了,大家可以直接去看JavaDoc。下面看看使用Collectors对于代码的简化:
List numsWithoutNull = nums.stream().filter(num -> num != null).
collect(Collectors.toList()); 其他汇聚
– reduce方法:reduce方法非常的通用,后面介绍的count,sum等都可以使用其实现。reduce方法有三个override的方法,本文介绍两个最常用的。先来看reduce方法的第一种形式,其方法定义如下:
Optional
接受一个BinaryOperator类型的参数,在使用的时候我们可以用lambda表达式来。
List
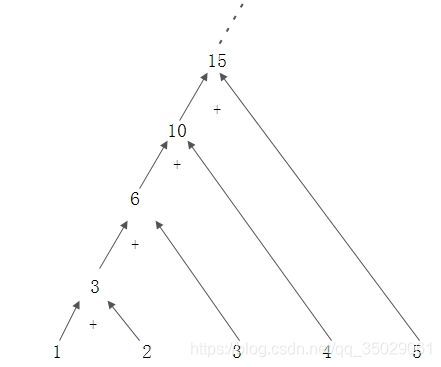
System.out.println("ints sum is:" + ints.stream().reduce((sum, item) -> sum + item).get());
可以看到reduce方法接受一个函数,这个函数有两个参数,第一个参数是上次函数执行的返回值(也称为中间结果),第二个参数是stream中的元素,这个函数把这两个值相加,得到的和会被赋值给下次执行这个函数的第一个参数。要注意的是:**第一次执行的时候第一个参数的值是Stream的第一个元素,第二个参数是Stream的第二个元素**。这个方法返回值类型是Optional,这是Java8防止出现NPE的一种可行方法,这里就简单的认为是一个容器,其中可能会包含0个或者1个对象。
这个过程可视化的结果如图:
reduce方法还有一个很常用的变种:
T reduce(T identity, BinaryOperator
这个定义上上面已经介绍过的基本一致,不同的是:它允许用户提供一个循环计算的初始值,如果Stream为空,就直接返回该值。而且这个方法不会返回Optional,因为其不会出现null值。下面直接给出例子,就不再做说明了。
List ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce(0, (sum, item) -> sum + item)); – count方法:获取Stream中元素的个数。比较简单,这里就直接给出例子,不做解释了。
List ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().count()); – 搜索相关
– allMatch:是不是Stream中的所有元素都满足给定的匹配条件
– anyMatch:Stream中是否存在任何一个元素满足匹配条件
– findFirst: 返回Stream中的第一个元素,如果Stream为空,返回空Optional
– noneMatch:是不是Stream中的所有元素都不满足给定的匹配条件
– max和min:使用给定的比较器(Operator),返回Stream中的最大|最小值
下面给出allMatch和max的例子,剩下的方法读者当成练习。
List item < 100));
ints.stream().max((o1, o2) -> o1.compareTo(o2)).ifPresent(System.out::println); 给出一个String类型的数组,求其中所有不重复素数的和
List l = Arrays.asList(numbers);
int sum = l.stream()
.map(e -> new Integer(e))
.filter(e -> Primes.isPrime(e))
.distinct()
.reduce(0, (x,y) -> x+y); // equivalent to .sum()
System.out.println("distinctPrimarySum result is: " + sum); reduce方法用来产生单一的一个最终结果,根据一定的规则将Stream中的元素进行计算后返回一个唯一的值。
流有很多预定义的reduce操作,如sum(),max(),min()等。
统计年龄在25-35岁的男女人数、比例
Map result = persons.parallelStream().filter(p -> p.getAge()>=25 && p.getAge()<=35).
collect(
Collectors.groupingBy(p->p.getSex(), Collectors.summingInt(p->1))
);
System.out.print("boysAndGirls result is " + result);
System.out.println(", ratio (male : female) is " + (float)result.get(Person.MALE)/result.get(Person.FEMALE)); 一个参数的Reduce
Stream s = Stream.of(1, 2, 3, 4, 5, 6);
/**
* 也可以写成Lambda语法:
* Integer sum = s.reduce((a, b) -> a + b).get();
*/
Integer sum = s.reduce(new BinaryOperator() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer + integer2;
}
}).get();
/**
* 求最大值,也可以写成Lambda语法:
* Integer max = s.reduce((a, b) -> a >= b ? a : b).get();
*/
Integer max = s.reduce(new BinaryOperator() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer >= integer2 ? integer : integer2;
}
}).get(); 两个参数的Reduce
相对于一个参数的方法来说,它多了一个T类型的参数;实际上就相当于需要计算的值在Stream的基础上多了一个初始化的值。
Stream s = Stream.of("test", "t1", "t2", "teeeee", "aaaa", "taaa");
/**
* 以下结果将会是: [value]testt1t2teeeeeaaaataaa
* 也可以使用Lambda语法:
* System.out.println(s.reduce("[value]", (s1, s2) -> s1.concat(s2)));
*/
System.out.println(s.reduce("[value]", new BinaryOperator() {
@Override
public String apply(String s, String s2) {
return s.concat(s2);
}
})); 三个参数的Reduce
分析下它的三个参数:
identity: 一个初始化的值;这个初始化的值其类型是泛型U,与Reduce方法返回的类型一致;注意此时Stream中元素的类型是T,与U可以不一样也可以一样,这样的话操作空间就大了;不管Stream中存储的元素是什么类型,U都可以是任何类型,如U可以是一些基本数据类型的包装类型Integer、Long等;或者是String,又或者是一些集合类型ArrayList等;后面会说到这些用法。
accumulator: 其类型是BiFunction,输入是U与T两个类型的数据,而返回的是U类型;也就是说返回的类型与输入的第一个参数类型是一样的,而输入的第二个参数类型与Stream中元素类型是一样的。
combiner: 其类型是BinaryOperator,支持的是对U类型的对象进行操作;
第三个参数combiner主要是使用在并行计算的场景下;如果Stream是非并行时,第三个参数实际上是不生效的。
因此针对这个方法的分析需要分并行与非并行两个场景。
非并行
/**
* 以下reduce生成的List将会是[aa, ab, c, ad]
* Lambda语法:
* System.out.println(s1.reduce(new ArrayList(), (r, t) -> {r.add(t); return r; }, (r1, r2) -> r1));
*/
Stream s1 = Stream.of("aa", "ab", "c", "ad");
System.out.println(s1.reduce(new ArrayList(),
new BiFunction, String, ArrayList>() {
@Override
public ArrayList apply(ArrayList u, String s) {
u.add(s);
return u;
}
}, new BinaryOperator>() {
@Override
public ArrayList apply(ArrayList strings, ArrayList strings2) {
return strings;
}
}));
/**
* 模拟Filter查找其中含有字母a的所有元素,打印结果将是aa ab ad
* lambda语法:
* s1.reduce(new ArrayList(), (r, t) -> {if (predicate.test(t)) r.add(t); return r; },
(r1, r2) -> r1).stream().forEach(System.out::println);
*/
Stream s1 = Stream.of("aa", "ab", "c", "ad");
Predicate predicate = t -> t.contains("a");
s1.reduce(new ArrayList(), new BiFunction, String, ArrayList>() {
@Override
public ArrayList apply(ArrayList strings, String s) {
if (predicate.test(s)) strings.add(s);
return strings;
}
},
new BinaryOperator>() {
@Override
public ArrayList apply(ArrayList strings, ArrayList strings2) {
return strings;
}
}).stream().forEach(System.out::println); 并行
当Stream是并行时,第三个参数就有意义了,它会将不同线程计算的结果调用combiner做汇总后返回。
注意由于采用了并行计算,前两个参数与非并行时也有了差异!
举个简单点的例子,计算4+1+2+3的结果,其中4是初始值:
/**
* lambda语法:
* System.out.println(Stream.of(1, 2, 3).parallel().reduce(4, (s1, s2) -> s1 + s2
, (s1, s2) -> s1 + s2));
**/
System.out.println(Stream.of(1, 2, 3).parallel().reduce(4, new BiFunction() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer + integer2;
}
}
, new BinaryOperator() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer + integer2;
}
}));
等价于
System.out.println(Stream.of(1, 2, 3).map(n -> n + 4).reduce((s1, s2) -> s1 * s2));
按非并行的方式来看它是分了三步的,每一步都要依赖前一步的运算结果!那应该是没有办法进行并行计算的啊!可实际上现在并行计算出了结果并且关键其结果与非并行时是不一致的!
那要不就是理解上有问题,要不就是这种方式在并行计算上存在BUG。
暂且认为其不存在BUG,先来看下它是怎么样出这个结果的。猜测初始值4是存储在一个变量result中的;并行计算时,线程之间没有影响,因此每个线程在调用第二个参数BiFunction进行计算时,直接都是使用result值当其第一个参数(由于Stream计算的延迟性,在调用最终方法前,都不会进行实际的运算,因此每个线程取到的result值都是原始的4),因此计算过程现在是这样的:线程1:1 + 4 = 5;线程2:2 + 4 = 6;线程3:3 + 4 = 7;Combiner函数: 5 + 6 + 7 = 18!
/**
* lambda语法:
* System.out.println(Stream.of(1, 2, 3).parallel().reduce(4, (s1, s2) -> s1 + s2
, (s1, s2) -> s1 * s2));
*/
System.out.println(Stream.of(1, 2, 3).parallel().reduce(4, new BiFunction() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer + integer2;
}
}
, new BinaryOperator() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer * integer2;
}
}));
等价于
System.out.println(Stream.of(1, 2, 3).map(n -> n + 4).reduce((s1, s2) -> s1 * s2));
以上示例输出的结果是210!
它表示的是,使用4与1、2、3中的所有元素按(s1,s2) -> s1 + s2(accumulator)的方式进行第一次计算,得到结果序列4+1, 4+2, 4+3,即5、6、7;然后将5、6、7按combiner即(s1, s2) -> s1 * s2的方式进行汇总,也就是5 * 6 * 7 = 210。
使用函数表示就是:(4+1) * (4+2) * (4+3) = 210;
reduce的这种写法可以与以下写法结果相等(但过程是不一样的,三个参数时会进行并行处理):
这种方式有助于理解并行三个参数时的场景,实际上就是第一步使用accumulator进行转换(它的两个输入参数一个是identity, 一个是序列中的每一个元素),由N个元素得到N个结果;第二步是使用combiner对第一步的N个结果做汇总。如果第一个参数的类型是ArrayList等对象而非基本数据类型的包装类或者String,第三个函数的处理上可能容易引起误解
分组与分区
会经常使用到Collectors这个类,这个类实际上是一个封装了很多常用的汇聚操作的一个工厂类。我们之前用到过
//将结果汇聚到ArrayList中
Collectors.toList();//将结果汇聚到HashSet中
Collectors.toSet();以及更为通用的
//将结果汇聚到一个指定类型的集合中
Collectors.toCollection(Supplier collectionFactory); Stream分组
在实际开发中,对于将一个集合的内容进行分组或分区这种需求也非常常见,所以我们继续学习下Collectors类中的groupingBy和partitioningBy方法。
public static Collector groupingBy(Function classifier){
//...
}groupingBy接收一个Function类型的变量classifier,classifier被称作分类器,收集器会按着classifier作为key对集合元素进行分组,然后返回Collector收集器对象,假如现在有一个实体Student
public class Student {
private String name;
private int score;
private int age;
public Student(String name,int score,int age){
this.name = name;
this.score = score;
this.age = age;
}
public String getName() {
return name;
}
}我们现在按Student的name进行分组,如果使用sql来表示就是select * from student group by name; 再看下使用Stream的方式
Map> collect = students.stream().collect(Collectors.groupingBy(Student::getName)); 这里我们使用方法引用(类名::实例方法名)替代lambda表达式(s -> s.getName())的方式来指定classifier分类器,使集合按Student的name来分组。
注意到分组后的返回类型是Map
那如果按name分组后,想求出每组学生的数量,就需要借助groupingBy另一个重载的方法
public static Collector groupingBy(Function classifier,Collector downstream){
//...
}第二个参数downstream还是一个收集器Collector对象,也就是说我们可以先将classifier作为key进行分组,然后将分组后的结果交给downstream收集器再进行处理
//按name分组 得出每组的学生数量 使用重载的groupingBy方法,第二个参数是分组后的操作
Map collect1 = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.counting())); Collectors类这里也帮我们封装好了用于统计数量的counting()方法,这里先了解一下counting()就是将收集器中元素求总数即可
我们还可以对分组后的数据求平均值
Map collect2 = students.stream().collect(Collectors.groupingBy(Student::getName, Collectors.averagingDouble(Student::getScore))); averagingDouble方法接收一个ToDoubleFunction参数
@FunctionalInterface
public interface ToDoubleFunction {
double applyAsDouble(T value);
} ToDoubleFunction实际上也是Function系列函数式接口中的其中一个特例,接收一个参数,返回Double类型(这里是接收一个Student返回score)。因为分组后的集合中每个元素是Student类型的,所以我们无法直接对Student进行求平均值
//伪代码
Collectors.averagingDouble(Student))所以需要将Student转成score再求平均值,Collectors.averagingDouble(Student::getScore))。
给出一个String类型的数组,找出其中所有不重复的素数,并统计其出现次数
public void primaryOccurrence(String... numbers) {
List l = Arrays.asList(numbers);
Map r = l.stream()
.map(e -> new Integer(e))
.filter(e -> Primes.isPrime(e))
.collect( Collectors.groupingBy(p->p, Collectors.summingInt(p->1)) );
System.out.println("primaryOccurrence result is: " + r); Collectors.groupingBy(p->p, Collectors.summingInt(p->1))
它的意思是:把结果收集到一个Map中,用统计到的各个素数自身作为键,其出现次数作为值。
Stream分区
collect方法
1.
2.
针对上面的Student,我们现在再加一个需求,分别统计一下及格和不及格的学生(分数是否>=60)
这时候符合Stream分区的概念了,Stream分区会将集合中的元素按条件分成两部分结果,key是Boolean类型,value是结果集,满足条件的key是true
Map> collect3 = students.stream().collect(Collectors.partitioningBy(student -> student.getScore() >= 60));
System.out.println(collect3.get(true));//输出及格的Student
System.out.println(collect3.get(false));//输出不及格的Student partitioningBy方法接收一个Predicate作为分区判断的依据,满足条件的元素放在key为true的集合中,反之放在key为false的集合中
//partitioningBy方法
public static Collector partitioningBy(Predicate predicate) {
return partitioningBy(predicate, toList());
}collect含义与Reduce有点相似;
仍旧先分析其参数(参考其JavaDoc):
supplier:动态的提供初始化的值;创建一个可变的结果容器(JAVADOC);对于并行计算,这个方法可能被调用多次,每次返回一个新的对象;
accumulator:类型为BiConsumer,注意这个接口是没有返回值的;它必须将一个元素放入结果容器中(JAVADOC)。
combiner:类型也是BiConsumer,因此也没有返回值。它与三参数的Reduce类型,只是在并行计算时汇总不同线程计算的结果。它的输入是两个结果容器,必须将第二个结果容器中的值全部放入第一个结果容器中(JAVADOC)。
可见Collect与分并行与非并行两种情况。
下面对并行情况进行分析。
直接使用上面Reduce模拟Filter的示例进行演示(使用lambda语法):
/**
* 模拟Filter查找其中含有字母a的所有元素,打印结果将是aa ab ad
*/
Stream s1 = Stream.of("aa", "ab", "c", "ad");
Predicate predicate = t -> t.contains("a");
System.out.println(s1.parallel().collect(() -> new ArrayList(),
(array, s) -> {if (predicate.test(s)) array.add(s); },
(array1, array2) -> array1.addAll(array2))); 根据以上分析,这边理解起来就很容易了:每个线程都创建了一个结果容器ArrayList,假设每个线程处理一个元素,那么处理的结果将会是[aa],[ab],[],[ad]四个结果容器(ArrayList);最终再调用第三个BiConsumer参数将结果全部Put到第一个List中,因此返回结果就是打印的结果了。
JAVADOC中也在强调结果容器(result container)这个,那是否除集合类型,其结果R也可以是其它类型呢?
先看基本类型,由于BiConsumer不会有返回值,如果是基本数据类型或者String,在BiConsumer中加工后的结果都无法在这个函数外体现,因此是没有意义的。
那其它非集合类型的Java对象呢?如果对象中包含有集合类型的属性,也是可以处理的;否则,处理上也没有任何意义,combiner对象使用一个Java对象来更新另外一个对象?至少目前我没有想到这个有哪些应用场景。它不同Reduce,Reduce在Java对象上是有应用场景的,就因为Reduce即使是并行情况下,也不会创建多个初始化对象,combiner接收的两个参数永远是同一个对象,如假设人有很多条参加会议的记录,这些记录没有在人本身对象里面存储而在另外一个对象中;人本身对象中只有一个属性是最早参加会议时间,那就可以使用reduce来对这个属性进行更新。当然这个示例不够完美,它能使用其它更快的方式实现,但至少通过Reduce是能够实现这一类型的功能的。
想把结果放到Set中或者替他的集合容器,也可以这样
list.stream().map(s -> s.toUpperCase()).collect(Collectors.toSet());//放到Set中或者更为通用的
list.stream().map(s -> s.toUpperCase()).collect(Collectors.toCollection(TreeSet::new));//自定义容器类型我们可以自己制定结果容器的类型Collectors的toCollection接受一个Supplier函数式接口类型参数,可以直接使用构造方法引用的方式。
collect(Collectors.toList())转换成list集合
List list = people.stream().map(Person::getName).collect(Collectors.toList());
Collectors.toSet():转换成set集合。
Collectors.toCollection(TreeSet::new):转换成特定的set集合。
TreeSet collect2 = Stream.of(1, 3, 4).collect(Collectors.toCollection(TreeSet::new));
Collectors.toMap(x -> x, x -> x + 1):转换成map。
Map collect1 = Stream.of(1, 3, 4).collect(Collectors.toMap(x -> x, x -> x + 1));
可以将一个类型转换为另一个类型
//定义一个function 输入是String类型,输出是 EventInfo 类型, EventInfo是一个类。
Function times2 = fun -> { EventInfo a = new EventInfo(); a.setName(fun); return a;};
String[] testintStrings={"1","2","3","4"};
//将String 的Array转换成map,调用times2函数进行转换
Map eventmap1=Stream.of(testintStrings).collect(Collectors.toMap(inputvalue->inputvalue, inputvalue->times2.apply(inputvalue)));
Map eventmap2=Stream.of(testStrings).collect(Collectors.toMap(inputvalue->inputvalue, inputvalue->(inputvalue+”a”)));
Collectors.minBy(Integer::compare):求最小值,相对应的当然也有maxBy方法。
Collectors.averagingInt(x->x):求平均值,同时也有averagingDouble、averagingLong方法。
System.out.println(Stream.of(1, 2, 3).collect(Collectors.averagingInt(x->x)));
Collectors.summingInt(x -> x)):求和。
int total = employees.stream().collect(Collectors.summingInt(Employee::getSalary)));
Collectors.summarizingDouble(x -> x):可以获取最大值、最小值、平均值、总和值、总数。
DoubleSummaryStatistics summaryStatistics = Stream.of(1, 3, 4).collect(Collectors.summarizingDouble(x -> x));
summaryStatistics.getAverage();//平均值
Collectors.groupingBy(x -> x):分组
有三种方法,查看源码可以知道前两个方法最终调用第三个方法,第二个参数默认HashMap::new 第三个参数默认Collectors.toList(),参考SQL的groupBy。
Map> map = Stream.of(1, 3, 3, 4).collect(Collectors.groupingBy(x -> x));
Map map = Stream.of(1, 3, 3, 4).collect(Collectors.groupingBy(x -> x, Collectors.counting()));
HashMap hashMap = Stream.of(1, 3, 3, 4).collect(Collectors.groupingBy(x -> x, HashMap::new, Collectors.counting()));
根据部门将员工分组:
Map> byDept
= employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
计算不同部门的员工工资总额
Map totalByDept
= employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.summingInt(Employee::getSalary)));
划分及格和不及格的学生
Map> passingFailing =
students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
Collectors.partitioningBy(x -> x > 2),把数据分成两部分,key为ture/false。第一个方法也是调用第二个方法,第二个参数默认为Collectors.toList()。
Map> collect5 = Stream.of(1, 3, 4).collect(Collectors.partitioningBy(x -> x > 2));
Map collect4 = Stream.of(1, 3, 4).collect(Collectors.partitioningBy(x -> x > 2, Collectors.counting()));
Collectors.joining(","):拼接字符串。
System.out.println(Stream.of("a", "b", "c").collect(Collectors.joining(",")));
String joined = things.stream()
.map(Object::toString)
.collect(Collectors.joining(", "));
Collectors.reducing(0, x -> x + 1, (x, y) -> x + y)):在求累计值的时候,还可以对参数值进行改变,这里是都+1后再求和。跟reduce方法有点类似,但reduce方法没有第二个参数。
System.out.println(Stream.of(1, 3, 4).collect(Collectors.reducing(0, x -> x + 1, (x, y) -> x + y)));
Collectors.collectingAndThen(Collectors.joining(","), x -> x + "d"):先执行collect操作后再执行第二个参数的表达式。这里是先拼接字符串,再在最后+ "d"。
String str= Stream.of("a", "b", "c").collect(Collectors.collectingAndThen(Collectors.joining(","), x -> x + "d"));
Collectors.mapping(...):跟map操作类似,只是参数有点区别。
System.out.println(Stream.of("a", "b", "c").collect(Collectors.mapping(x -> x.toUpperCase(), Collectors.joining(","))));
熟能生巧
把所有长度大于5的字符串转换成大写输出到控制台
List list = Arrays.asList("hello","world","helloworld");
list.stream().filter(s -> s.length() > 5).map(s -> s.toUpperCase()).forEach(System.out::println);
filter方法,接收一个Predicate函数式接口类型作为参数,并返回一个Stream对象,从上一篇我们知道可以由一个接收一个参数返回布尔类型的lambda表达式来创建Predicate函数式接口实例,所以看到filter接收的参数是s -> s.length() > 5
map方法,接收Function函数式接口类型,接收一个参数,有返回值s -> s.toUpperCase() 正是做了这件事情
forEach方法,接收Consumer函数式接口类型,接收一个参数,不返回值 这里使用方法引用的其中一种形式System.out::println来创建了Consumer实例。
实际上map方法中可以使用另一种方法引用的形式来处理,类方法引用。语法:类名::方法名
List list = Arrays.asList("hello","world","helloworld");
list.stream().filter(s -> s.length() > 5).map(String::toUpperCase).forEach(System.out::println); 遍历集合
for(Object o: list) { // 外部迭代
System.out.println(o);
}
可以写成:
list.stream().forEach(o -> {System.out.println(o);}); //forEach函数实现内部迭代 List shapes = ...
shapes.stream()
.filter(s -> s.getColor() == BLUE)
.forEach(s -> s.setColor(RED)); 以集合类对象shapes里面的元素为数据源,生成一个流。然后在这个流上调用filter方法,挑出蓝色的,返回另一个流。最后调用forEach方法将这些蓝色的物体喷成红色。
还有一个方法叫parallelStream(),顾名思义它和stream()一样,只不过指明要并行处理,以期充分利用现代CPU的多核特性。
shapes.parallelStream(); // 或shapes.stream().parallel()给出一个String类型的数组,找出其中所有不重复的素数
List l = Arrays.asList(numbers);
List r = l.stream()
.map(e -> new Integer(e))
.filter(e -> Primes.isPrime(e))
.distinct()
.collect(Collectors.toList());
System.out.println("distinctPrimary result is: " + r); 第一步:传入一系列String(假设都是合法的数字),转成一个List,然后调用stream()方法生成流。
第二步:调用流的map方法把每个元素由String转成Integer,得到一个新的流。map方法接受一个Function类型的参数,上面介绍了,Function是个函数接口,所以这里用λ表达式。
第三步:调用流的filter方法,过滤那些不是素数的数字,并得到一个新流。filter方法接受一个Predicate类型的参数,上面介绍了,Predicate是个函数接口,所以这里用λ表达式。
第四步:调用流的distinct方法,去掉重复,并得到一个新流。这本质上是另一个filter操作。
第五步:用collect方法将最终结果收集到一个List里面去。collect方法接受一个Collector类型的参数,这个参数指明如何收集最终结果。在这个例子中,结果简单地收集到一个List中。我们也可以用Collectors.toMap(e->e, e->e)把结果收集到一个Map中,它的意思是:把结果收到一个Map,用这些素数自身既作为键又作为值。toMap方法接受两个Function类型的参数,分别用以生成键和值,Function是个函数接口,所以这里都用λ表达式。
当遇到eager方法时,前面的lazy方法才会被依次执行。而且是管道贯通式执行。这意味着每一个元素依次通过这些管道。例如有个元素“3”,首先它被map成整数型3;然后通过filter,发现是素数,被保留下来;又通过distinct,如果已经有一个3了,那么就直接丢弃,如果还没有则保留。这样,3个操作其实只经过了一次循环。
除collect外其它的eager操作还有forEach,toArray,reduce等。
将流中字符全部转成大写返回一个新的集合
List list = Arrays.asList("hello", "world", "helloworld");
List collect = list.stream().map(s -> s.toUpperCase()).collect(Collectors.toList()); List alpha = Arrays.asList("a", "b", "c", "d");
List collect = alpha.stream().map(String::toUpperCase).collect(Collectors.toList());
List num = Arrays.asList(1,2,3,4,5);
List collect1 = num.stream().map(n -> n * 2).collect(Collectors.toList());
System.out.println(collect1); //[2, 4, 6, 8, 10]
Integer[] nums= new Integer[]{2,5,1,3,6};
Arrays.asList(nums)
.stream().map(x->x*x)
.forEach(System.out::println);;
找出2001年发生的所有交易并按交易额排序
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2001", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
transactions.stream()
.filter(x->x.getTime().equals("2001"))
.sorted((x,y)->Integer.compare(x.getAccount(), y.getAccount()))
.map(Transaction::getAccount)
.forEach(System.out::println);
交易员都在那些城市呆过
List transactions = null;
Trader keke = new Trader("keke","hunan");
Trader array = new Trader("array","sichuan");
Trader object = new Trader("object","beijing");
Trader vicky = new Trader("vicky","hunan");
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
transactions.stream()
.map(x->x.getTrader())
.map(x->x.getCity())
.distinct()
.forEach(System.out::println);
查找所有来自湖南的交易员,并按姓名排序
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
transactions.stream()
.filter(x->x.getTrader().getCity().equals("hunan"))
.map(Transaction::getTrader)
.sorted((x,y)->x.getName().compareTo(y.getName()))
.forEach(System.out::println);
返回所有交易员的姓名字符串,并按字符顺序排序
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
String string = transactions.stream()
.map(x->x.getTrader().getName())
.sorted()
.reduce("",String::concat);
System.out.println(string);
System.out.println("================="
);
String string2 = transactions.stream()
.map(x->x.getTrader().getName())
.sorted()
.collect(Collectors.joining(","));
System.out.println(string2);
有没有交易员在上海工作的
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
boolean b = transactions.stream()
.anyMatch(x->x.getTrader().getCity().equals("shanghai"));
System.out.println("有交易员是否在上海生活"+b);
打印所有生活在湖南的交易员的所有交易额
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
Optional all = transactions.stream()
.filter(x->x.getTrader().getCity().equals("hunan"))
.map(Transaction::getAccount)
.reduce(Integer::sum);
System.out.println("生活在湖南的交易员的所有交易额"+all.get());
所有交易中最高的交易额
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
Optional min = transactions.stream()
.map(Transaction::getAccount)
.reduce(Integer::min);
System.out.println("所有交易中最高的交易额"+min.get());
找到交易额最小的交易
transactions = Arrays.asList(
new Transaction(array, "2001", 998),
new Transaction(keke, "2001", 999),
new Transaction(object, "2008", 200),
new Transaction(vicky, "2018", 1998),
new Transaction(keke, "2017", 500));
Optional transaction = transactions.stream()
.sorted((x,y)->x.getAccount().compareTo(y.getAccount()))
.findFirst();
System.out.println(transaction.get().getTrader().getName()+transaction.get().getTrader().getCity()+transaction.get().getAccount());
| Modifier and Type | Method and Description |
|---|---|
boolean |
allMatch(Predicate predicate) 返回此流的所有元素是否与提供的谓词匹配。 |
boolean |
anyMatch(Predicate predicate) 返回此流的任何元素是否与提供的谓词匹配。 |
static |
builder() 返回一个 |
|
collect(Collector collector) 使用 Collector对此流的元素执行 mutable reduction |
|
collect(Supplier 对此流的元素执行 mutable reduction操作。 |
static |
concat(Stream a, Stream b) 创建一个懒惰连接的流,其元素是第一个流的所有元素,后跟第二个流的所有元素。 |
long |
count() 返回此流中的元素数。 |
Stream |
distinct() 返回由该流的不同元素(根据 |
static |
empty() 返回一个空的顺序 |
Stream |
filter(Predicate predicate) 返回由与此给定谓词匹配的此流的元素组成的流。 |
Optional |
findAny() 返回描述流的一些元素的 |
Optional |
findFirst() 返回描述此流的第一个元素的 |
|
flatMap(Function> mapper) 返回由通过将提供的映射函数应用于每个元素而产生的映射流的内容来替换该流的每个元素的结果的流。 |
DoubleStream |
flatMapToDouble(Function mapper) 返回一个 |
IntStream |
flatMapToInt(Function mapper) 返回一个 |
LongStream |
flatMapToLong(Function mapper) 返回一个 |
void |
forEach(Consumer action) 对此流的每个元素执行操作。 |
void |
forEachOrdered(Consumer action) 如果流具有定义的遇到顺序,则以流的遇到顺序对该流的每个元素执行操作。 |
static |
generate(Supplier 返回无限顺序无序流,其中每个元素由提供的 |
static |
iterate(T seed, UnaryOperator 返回有序无限连续 |
Stream |
limit(long maxSize) 返回由此流的元素组成的流,截短长度不能超过 |
|
map(Function mapper) 返回由给定函数应用于此流的元素的结果组成的流。 |
DoubleStream |
mapToDouble(ToDoubleFunction mapper) 返回一个 |
IntStream |
mapToInt(ToIntFunction mapper) 返回一个 |
LongStream |
mapToLong(ToLongFunction mapper) 返回一个 |
Optional |
max(Comparator comparator) 根据提供的 |
Optional |
min(Comparator comparator) 根据提供的 |
boolean |
noneMatch(Predicate predicate) 返回此流的元素是否与提供的谓词匹配。 |
static |
of(T... values) 返回其元素是指定值的顺序排序流。 |
static |
of(T t) 返回包含单个元素的顺序 |
Stream |
peek(Consumer action) 返回由该流的元素组成的流,另外在从生成的流中消耗元素时对每个元素执行提供的操作。 |
Optional |
reduce(BinaryOperator 使用 associative累积函数对此流的元素执行 reduction ,并返回描述减小值的 |
T |
reduce(T identity, BinaryOperator 使用提供的身份值和 associative累积功能对此流的元素执行 reduction ,并返回减小的值。 |
U |
reduce(U identity, BiFunction 执行 reduction在此流中的元素,使用所提供的身份,积累和组合功能。 |
Stream |
skip(long n) 在丢弃流的第一个 |
Stream |
sorted() 返回由此流的元素组成的流,根据自然顺序排序。 |
Stream |
sorted(Comparator comparator) 返回由该流的元素组成的流,根据提供的 |
Object[] |
toArray() 返回一个包含此流的元素的数组。 |
A[] |
toArray(IntFunction 使用提供的 |
支持顺序和并行聚合操作的一系列元素。 以下示例说明了使用Stream和IntStream的汇总操作 :
int sum = widgets.stream() .filter(w -> w.getColor() == RED) .mapToInt(w -> w.getWeight()) .sum(); 在这个例子中, widgets是Collection 。 我们通过Collection.stream()创建一个Widget对象的流,过滤它以产生仅包含红色小部件的流,然后将其转换为表示每个红色小部件的权重的int值。 然后将该流相加以产生总重量。
除了Stream ,其为对象引用的流,存在原语特为IntStream , LongStream和DoubleStream ,所有这些都称为“流”和符合此处描述的特征和限制。
为了执行计算,流operations被组合成流管道 。 流管线由源(其可以是阵列,集合,生成函数,I / O通道等)组成,零个或多个中间操作 (其将流转换成另一个流,例如filter(Predicate) )以及终端操作 (产生结果或副作用,如count()或forEach(Consumer) )。 流懒惰 源数据上的计算仅在终端操作启动时执行,源元素仅在需要时才被使用。
集合和流动,同时具有一些表面上的相似之处,具有不同的目标。 集合主要关注其元素的有效管理和访问。 相比之下,流不提供直接访问或操纵其元素的手段,而是关心声明性地描述其源和将在该源上进行聚合的计算操作。 但是,如果提供的流操作不提供所需的功能,则可以使用BaseStream.iterator()和BaseStream.spliterator()操作来执行受控遍历。
流管道,如上面的“小部件”示例,可以被视为流源上的查询 。 除非源是明确设计用于并发修改(例如ConcurrentHashMap ),否则在查询流源时可能会导致不可预测或错误的行为。
大多数流操作接受描述用户指定行为的参数,例如上面示例中传递给mapToInt的lambda表达式w -> w.getWeight() 。 为了保持正确的行为,这些行为参数 :
这些参数始终是functional interface的实例 ,例如Function ,并且通常是lambda表达式或方法引用。 除非另有说明,否则这些参数必须为非空值 。
流只能运行(调用中间或终端流操作)一次。 这排除了例如“分叉”流,其中相同的源提供两条或多条流水线,或同一流的多遍。 如果流实现可能会丢失IllegalStateException,如果它检测到该流被重用。 然而,由于一些流操作可能返回其接收器而不是新的流对象,所以在所有情况下可能无法检测到重用。
Streams有一个BaseStream.close()方法和实现AutoCloseable ,但几乎所有的流实例实际上不需要在使用后关闭。 一般来说,只有来源为IO通道的流(如Files.lines(Path, Charset)返回的流 )才需要关闭。 大多数流都由集合,数组或生成函数支持,这些函数不需要特殊的资源管理。 (如果流确实需要关闭,则可以在try -with-resources语句中将其声明为资源。)
流管线可以顺序执行,也可以在parallel中执行。 此执行模式是流的属性。 流被创建为具有顺序或并行执行的初始选择。 (例如, Collection.stream()创建一个顺序流,并且Collection.parallelStream()创建一个并行的)。执行模式的选择可以由BaseStream.sequential()或BaseStream.parallel()方法修改,并且可以使用BaseStream.isParallel()方法进行查询。
必须是non-interfering (他们不修改流源); 和
在大多数情况下必须是stateless (它们的结果不应该取决于在流管道的执行期间可能改变的任何状态)。
java源码
package java.util.stream;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Arrays;
import java.util.Collection;
import java.util.Comparator;
import java.util.Iterator;
import java.util.Objects;
import java.util.Optional;
import java.util.Spliterator;
import java.util.Spliterators;
import java.util.concurrent.ConcurrentHashMap;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.util.function.BinaryOperator;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.IntFunction;
import java.util.function.Predicate;
import java.util.function.Supplier;
import java.util.function.ToDoubleFunction;
import java.util.function.ToIntFunction;
import java.util.function.ToLongFunction;
import java.util.function.UnaryOperator;
public interface Stream extends BaseStream> {
Stream filter(Predicate predicate);
Stream map(Function mapper);
IntStream mapToInt(ToIntFunction mapper);
LongStream mapToLong(ToLongFunction mapper);
DoubleStream mapToDouble(ToDoubleFunction mapper);
Stream flatMap(Function> mapper);
IntStream flatMapToInt(Function mapper);
LongStream flatMapToLong(Function mapper);
DoubleStream flatMapToDouble(Function mapper);
Stream distinct();
Stream sorted();
Stream sorted(Comparator comparator);
Stream peek(Consumer action);
Stream limit(long maxSize);
Stream skip(long n);
void forEach(Consumer action);
void forEachOrdered(Consumer action);
Object[] toArray();
A[] toArray(IntFunction generator);
T reduce(T identity, BinaryOperator accumulator);
Optional reduce(BinaryOperator accumulator);
U reduce(U identity,
BiFunction accumulator,
BinaryOperator combiner);
R collect(Supplier supplier,
BiConsumer accumulator,
BiConsumer combiner);
R collect(Collector collector);
Optional min(Comparator comparator);
Optional max(Comparator comparator);
long count();
boolean anyMatch(Predicate predicate);
boolean allMatch(Predicate predicate);
boolean noneMatch(Predicate predicate);
Optional findFirst();
Optional findAny();
// Static factories
public static Builder builder() {
return new Streams.StreamBuilderImpl<>();
}
public static Stream empty() {
return StreamSupport.stream(Spliterators.emptySpliterator(), false);
}
public static Stream of(T t) {
return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false);
}
@SafeVarargs
@SuppressWarnings("varargs") // Creating a stream from an array is safe
public static Stream of(T... values) {
return Arrays.stream(values);
}
public static Stream iterate(final T seed, final UnaryOperator f) {
Objects.requireNonNull(f);
final Iterator iterator = new Iterator() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator,
Spliterator.ORDERED | Spliterator.IMMUTABLE), false);
}
public static Stream generate(Supplier s) {
Objects.requireNonNull(s);
return StreamSupport.stream(
new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);
}
public static Stream concat(Stream a, Stream b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator) a.spliterator(), (Spliterator) b.spliterator());
Stream stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}
public interface Builder extends Consumer {
@Override
void accept(T t);
default Builder add(T t) {
accept(t);
return this;
}
Stream build();
}
}
参数类型
T - 流元素的类型
S -的实现流的类型 BaseStream
流的基本界面,它们是支持顺序和并行聚合操作的元素序列。 以下示例说明了使用流类型Stream和IntStream的汇总操作 ,计算红色小部件的权重之和:
int sum = widgets.stream() .filter(w -> w.getColor() == RED) .mapToInt(w -> w.getWeight()) .sum();
| Modifier and Type | Method and Description |
|---|---|
void |
close() 关闭此流,导致此流管道的所有关闭处理程序被调用。 |
boolean |
isParallel() 返回此流是否要执行终端操作,将并行执行。 |
Iterator |
iterator() 返回此流的元素的迭代器。 |
S |
onClose(Runnable closeHandler) 返回带有附加关闭处理程序的等效流。 |
S |
parallel() 返回平行的等效流。 |
S |
sequential() 返回顺序的等效流。 |
Spliterator |
spliterator() 返回此流的元素的拼接器。 |
S |
unordered() 返回等效的流,即 unordered 。 |
package java.util.stream;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.Collection;
import java.util.Iterator;
import java.util.Spliterator;
import java.util.concurrent.ConcurrentHashMap;
import java.util.function.IntConsumer;
import java.util.function.Predicate;
public interface BaseStream>
extends AutoCloseable {
Iterator iterator();
Spliterator spliterator();
boolean isParallel();
S sequential();
S parallel();
S unordered();
S onClose(Runnable closeHandler);
@Override
void close();
}
可以保存资源的对象(如文件或套接字句柄),直到它关闭。 AutoCloseable对象的close()方法在退出已在资源规范头中声明对象的try -with-resources块时自动调用。 这种结构确保迅速释放,避免资源耗尽异常和可能发生的错误。
实际上,基类实现自动关闭是可能的,实际上是可行的,尽管不是所有的子类或实例都将保存可释放的资源。 对于必须以完全一般性操作的代码,或者当知道AutoCloseable实例需要资源释放时,建议使用try资源结构。 然而,使用设施,例如当Stream同时支持I / O基和非I / O基的形式, try -with资源块是一般不必要使用非I / O基形式时。
| Modifier and Type | Method and Description |
|---|---|
void |
close() 关闭此资源,放弃任何潜在资源。 |
package java.lang;
public interface AutoCloseable {
void close() throws Exception;
}
参数类型
T - 函数输入的类型
R - 函数的结果类型
Functional Interface:
这是一个功能界面,因此可以用作lambda表达式或方法引用的赋值对象。
表示接受一个参数并产生结果的函数。
这是一个functional interface的功能方法是apply(Object) 。
| Modifier and Type | Method and Description |
|---|---|
default |
andThen(Function after) 返回一个组合函数,首先将该函数应用于其输入,然后将 |
R |
apply(T t) 将此函数应用于给定的参数。 |
default |
compose(Function before) 返回一个组合函数,首先将 |
static |
identity() 返回一个总是返回其输入参数的函数。 |
package java.util.function;
@FunctionalInterface
public interface Function {
R apply(T t);
default Function compose(Function before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default Function andThen(Function after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static Function identity() {
return t -> t;
}
}
参数类型
T - T输入的类型
表示一个参数的谓词(布尔值函数)。
| Modifier and Type | Method and Description |
|---|---|
default Predicate |
and(Predicate other) 返回一个组合的谓词,表示该谓词与另一个谓词的短路逻辑AND。 |
static |
isEqual(Object targetRef) 返回根据 |
default Predicate |
negate() 返回表示此谓词的逻辑否定的谓词。 |
default Predicate |
or(Predicate other) 返回一个组合的谓词,表示该谓词与另一个谓词的短路逻辑或。 |
boolean |
test(T t) 在给定的参数上评估这个谓词。 |
package java.util.function;
@FunctionalInterface
public interface Predicate {
boolean test(T t);
default Predicate and(Predicate other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
default Predicate negate() {
return (t) -> !test(t);
}
default Predicate or(Predicate other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
static Predicate isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
参数类型
T - 函数输入的类型
表示产生一个int值结果的函数。 这是int Function生产原始专业化 。
| Modifier and Type | Method and Description |
|---|---|
int |
applyAsInt(T value) 将此函数应用于给定的参数。 |
package java.util.function;
@FunctionalInterface
public interface ToIntFunction {
int applyAsInt(T value);
}
参数类型
T - 函数输入的类型
表示产生长期效果的函数。 这是long生产原始专业Function 。
| Modifier and Type | Method and Description |
|---|---|
long |
applyAsLong(T value) 将此函数应用于给定的参数。 |
package java.util.function;
@FunctionalInterface
public interface ToLongFunction {
long applyAsLong(T value);
}
参数类型
T - 函数输入的类型
表示产生双值结果的函数。 这是double Function生产原始专业化 。
| Modifier and Type | Method and Description |
|---|---|
double |
applyAsDouble(T value) 将此函数应用于给定的参数。 |
package java.util.function;
@FunctionalInterface
public interface ToDoubleFunction {
double applyAsDouble(T value);
}
参数类型
T - 可比较此比较器的对象类型
比较功能,对一些对象的集合施加了一个整体排序 。 可以将比较器传递给排序方法(如Collections.sort或Arrays.sort ),以便对排序顺序进行精确控制。 比较器还可以用来控制某些数据结构(如顺序sorted sets或sorted maps ),或对于不具有对象的集合提供的排序natural ordering 。
通过比较c上的一组元素S的确定的顺序对被认为是与equals一致当且仅当c.compare(e1, e2)==0具有用于S每e1和e2相同布尔值e1.equals(e2)。
当使用能够强制排序不一致的比较器时,应注意使用排序集(或排序图)。 假设具有显式比较器c的排序集(或排序映射)与从集合S中绘制的元素(或键) 一起使用 。 如果88446235254451上的c强制的排序与equals不一致,则排序集(或排序映射)将表现为“奇怪”。 特别是排序集(或排序图)将违反用于设置(或映射)的一般合同,其按equals定义。
例如,假设一个将两个元件a和b ,使得(a.equals(b) && c.compare(a, b) != 0)到空TreeSet与比较c 。 因为a和b与树集的角度不相等,所以第二个add操作将返回true(并且树集的大小将增加),即使这与Set.add方法的规范相反。
注意:这通常是一个好主意比较,也能实现java.io.Serializable,因为它们可能被用来作为排序的序列化数据结构的方法(如TreeSet , TreeMap )。 为了使数据结构成功序列化,比较器(如果提供)必须实现Serializable 。
对于数学上的倾斜,即限定了施加顺序 ,给定的比较器c上一组给定对象的S强加关系式为:
{(x, y) such that c.compare(x, y) <= 0}. 这个总订单的商是:
{(x, y) such that c.compare(x, y) == 0}. 它从合同compare,该商数是S的等价关系紧随其后,而强加的排序是S, 总订单 。 当我们说S上的c所规定的顺序与等于一致时,我们的意思是排序的商是由对象' equals(Object)方法定义的等价关系:
{(x, y) such that x.equals(y)}. 与Comparable不同,比较器可以可选地允许比较空参数,同时保持对等价关系的要求。
| Modifier and Type | Method and Description |
|---|---|
int |
compare(T o1, T o2) 比较其两个参数的顺序。 |
static |
comparing(Function keyExtractor) 接受从类型 |
static |
comparing(Function keyExtractor, Comparator keyComparator) 接受提取从一个类型排序键的功能 |
static |
comparingDouble(ToDoubleFunction keyExtractor) 接受从类型 |
static |
comparingInt(ToIntFunction keyExtractor) 接受从类型 |
static |
comparingLong(ToLongFunction keyExtractor) 接受提取功能 |
boolean |
equals(Object obj) 指示某个其他对象是否等于此比较器。 |
static |
naturalOrder() 返回一个以自然顺序比较 |
static |
nullsFirst(Comparator comparator) 返回一个空友好的比较是认为 |
static |
nullsLast(Comparator comparator) 返回一个比较容易的比较器,它将 |
default Comparator |
reversed() 返回一个比较器,强制该比较器的相反顺序。 |
static |
reverseOrder() 返回一个与 自然排序相反的比较器。 |
default Comparator |
thenComparing(Comparator other) 用另一个比较器返回一个字典顺序比较器。 |
default > |
thenComparing(Function keyExtractor) 返回具有提取 |
default Comparator |
thenComparing(Function keyExtractor, Comparator keyComparator) 返回具有提取要与给定 |
default Comparator |
thenComparingDouble(ToDoubleFunction keyExtractor) 返回具有提取 |
default Comparator |
thenComparingInt(ToIntFunction keyExtractor) 返回具有提取 |
default Comparator |
thenComparingLong(ToLongFunction keyExtractor) 返回具有提取 |
package java.util;
import java.io.Serializable;
import java.util.function.Function;
import java.util.function.ToIntFunction;
import java.util.function.ToLongFunction;
import java.util.function.ToDoubleFunction;
import java.util.Comparators;
@FunctionalInterface
public interface Comparator {
int compare(T o1, T o2);
boolean equals(Object obj);
default Comparator reversed() {
return Collections.reverseOrder(this);
}
default Comparator thenComparing(Comparator other) {
Objects.requireNonNull(other);
return (Comparator & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
default Comparator thenComparing(
Function keyExtractor,
Comparator keyComparator)
{
return thenComparing(comparing(keyExtractor, keyComparator));
}
default > Comparator thenComparing(
Function keyExtractor)
{
return thenComparing(comparing(keyExtractor));
}
default Comparator thenComparingInt(ToIntFunction keyExtractor) {
return thenComparing(comparingInt(keyExtractor));
}
default Comparator thenComparingLong(ToLongFunction keyExtractor) {
return thenComparing(comparingLong(keyExtractor));
}
default Comparator thenComparingDouble(ToDoubleFunction keyExtractor) {
return thenComparing(comparingDouble(keyExtractor));
}
public static > Comparator reverseOrder() {
return Collections.reverseOrder();
}
@SuppressWarnings("unchecked")
public static > Comparator naturalOrder() {
return (Comparator) Comparators.NaturalOrderComparator.INSTANCE;
}
public static Comparator nullsFirst(Comparator comparator) {
return new Comparators.NullComparator<>(true, comparator);
}
public static Comparator nullsLast(Comparator comparator) {
return new Comparators.NullComparator<>(false, comparator);
}
public static Comparator comparing(
Function keyExtractor,
Comparator keyComparator)
{
Objects.requireNonNull(keyExtractor);
Objects.requireNonNull(keyComparator);
return (Comparator & Serializable)
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2));
}
public static > Comparator comparing(
Function keyExtractor)
{
Objects.requireNonNull(keyExtractor);
return (Comparator & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
public static Comparator comparingInt(ToIntFunction keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator & Serializable)
(c1, c2) -> Integer.compare(keyExtractor.applyAsInt(c1), keyExtractor.applyAsInt(c2));
}
public static Comparator comparingLong(ToLongFunction keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator & Serializable)
(c1, c2) -> Long.compare(keyExtractor.applyAsLong(c1), keyExtractor.applyAsLong(c2));
}
public static Comparator comparingDouble(ToDoubleFunction keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator & Serializable)
(c1, c2) -> Double.compare(keyExtractor.applyAsDouble(c1), keyExtractor.applyAsDouble(c2));
}
}
参数类型
T - 操作输入的类型
表示接受单个输入参数并且不返回结果的操作。 与大多数其他功能界面不同, Consumer预计将通过副作用进行操作。
| Modifier and Type | Method and Description |
|---|---|
void |
accept(T t) 对给定的参数执行此操作。 |
default Consumer |
andThen(Consumer after) 返回一个组合的 |
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Consumer {
void accept(T t);
default Consumer andThen(Consumer after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
参数类型
R - 函数结果的类型
表示一个接受int值参数并产生结果的函数。 这是int对-consuming原始专业化Function 。
| Modifier and Type | Method and Description |
|---|---|
R |
apply(int value) 将此函数应用于给定的参数。 |
package java.util.function;
@FunctionalInterface
public interface IntFunction {
R apply(int value);
}
参数类型
T - 函数的第一个参数的类型
U - 函数的第二个参数的类型
R - 函数结果的类型
表示接受两个参数并产生结果的函数。 这是Function的二元专业化 。
| Modifier and Type | Method and Description |
|---|---|
default |
andThen(Function after) 返回一个组合函数,首先将此函数应用于其输入,然后将 |
R |
apply(T t, U u) 将此函数应用于给定的参数。 |
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface BiFunction {
R apply(T t, U u);
default BiFunction andThen(Function after) {
Objects.requireNonNull(after);
return (T t, U u) -> after.apply(apply(t, u));
}
}
参数类型
T - 操作数的类型和运算符的结果
表示对同一类型的两个操作数的操作,产生与操作数相同类型的结果。 对于操作数和结果都是相同类型的情况,这是BiFunction的专业化 。
| Modifier and Type | Method and Description |
|---|---|
static |
maxBy(Comparator comparator) 返回一个 |
static |
minBy(Comparator comparator) 返回 |
package java.util.function;
import java.util.Objects;
import java.util.Comparator;
@FunctionalInterface
public interface BinaryOperator extends BiFunction {
public static BinaryOperator minBy(Comparator comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
public static BinaryOperator maxBy(Comparator comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
}
参数类型
T - 操作的第一个参数的类型
U - 操作的第二个参数的类型
表示接受两个输入参数并且不返回结果的操作。 这是Consumer的二元专业化 。 与大多数其他功能界面不同,预计BiConsumer将通过副作用进行操作。
| Modifier and Type | Method and Description |
|---|---|
void |
accept(T t, U u) 对给定的参数执行此操作。 |
default BiConsumer |
andThen(BiConsumer after) 返回一个组合的 |
@FunctionalInterface
public interface BiConsumer {
void accept(T t, U u);
default BiConsumer andThen(BiConsumer after) {
Objects.requireNonNull(after);
return (l, r) -> {
accept(l, r);
after.accept(l, r);
};
}
}