poi导入excel中具有子父级关系的数据到目录树的某个节点上
poi导入excel中具有子父级关系的数据到目录树的某个节点上
excle数据格式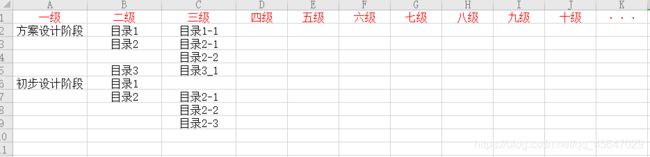
导入过后的树节点

导入后的数据库里面的数据

代码
/**
* @description: 上传目录结构
* @params: [fileViewModel]base64="UEsDBAoAAAAAAIdO4kAAAAAA..." fileName="选中目录的id" fileType="上传文件的格式后缀xlsx"
* @author:
* @Date: 2019/10/10
*/
@Override
public Map<String, List<ImportRowResult>> importFile(FileViewModel fileViewModel) {
if (fileViewModel.getBase64().equals("{}")) {
throw new JrsfException(" 请选择导入的文件");
}
//获取选中的目录节点
String rootFloderId = fileViewModel.getFileName();
JPAQueryFactory queryFactory = new JPAQueryFactory(getDao().getEntityManager());
QFloder qFloder = QFloder.floder;
//查询数据库中所有的目录
List<Floder> floders = queryFactory.selectFrom(qFloder).fetch();
//得到右键选中的根目录的名字
Floder rootFloder = floders.stream().filter(i -> i.getId().equals(rootFloderId)).collect(Collectors.toList()).get(0);
String rootFloderName = rootFloder.getName();
// 查询选中节点下全部数据
List<Floder> floderList = new ArrayList<>();
findFloderChildren(rootFloder, floders, floderList);
// 添加自己
floderList.add(rootFloder);
// 获取导入数据
// Gkbim/static/02409dba142e430cb74170cbf77621eea52f722807cbb191faa27df2909708gf.xlsx
String fileName = path + EvString.getUUID() + fileViewModel.getFileName();
if (!EvString.isEmpty(fileViewModel.getFileType())) {
//加格式后缀
fileName += "." + fileViewModel.getFileType();
}
//生成文件
File file = EvCommonTool.base64ToFile(fileViewModel.getBase64(), fileName);
//读Excel文件
List<ArrayList<String>> arrayLists = ReadExcel(file.getAbsolutePath());
// 移除第一行无用数据
arrayLists.remove(0);
//得到层级关系
for (int i = 0; i < arrayLists.size(); i++) {
int z = 0;
for (int j = 0; j < arrayLists.get(i).size(); j++) {
if (!"null".equals(arrayLists.get(i).get(j))) {
z = j;
}
}
for (int j = 0; j < z; j++) {
if ("null".equals(arrayLists.get(i).get(j))) {
if (!"null".equals(arrayLists.get(i - 1).get(j))) {
arrayLists.get(i).set(j, arrayLists.get(i - 1).get(j));
}
}
}
}
// 生成实体集合
List<Floder> list = getList1(arrayLists, rootFloderId);
List<Floder> insertList = new ArrayList<>();
ArrayList<Floder> collect = list.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(o -> o.getName() + ";" + o.getParentId()))), ArrayList::new));
for (Floder floder : list) {
List<Floder> collect1 = insertList.stream().filter(data -> data.getParentId().equals(floder.getParentId()) && data.getName().equals(floder.getName())).collect(Collectors.toList());
if (collect1.size() > 0) {
continue;
} else {
insertList.add(floder);
}
}
for (Floder floder : insertList) {
Integer sortOrder = queryFactory.selectFrom(qFloder).orderBy(qFloder.sortOrder.desc()).fetch().get(0).getSortOrder();
floder.setSortOrder(++sortOrder);
//设置所属项目
floder.setProj(rootFloder.getProj());
//设置所属文档库类型
floder.setType(rootFloder.getType());
floder.setDeleted(false);
save(floder);
//设置文件夹权限为选中的根节点权限
QRRoleDocPermission qrRoleDocPermission = QRRoleDocPermission.rRoleDocPermission;
List<RRoleDocPermission> rRoleDocPermissionList = queryFactory.selectFrom(qrRoleDocPermission).where(qrRoleDocPermission.floderId.eq(rootFloderId)).fetch();
//通过roleId分组聚合
Map<String, List<RRoleDocPermission>> groupByRoleId = rRoleDocPermissionList.stream().filter(data -> data.getRoleId() != null).collect(Collectors.groupingBy(RRoleDocPermission::getRoleId));
Set<String> roleIdSet = groupByRoleId.keySet();
for (String roleId : roleIdSet) {
List<RRoleDocPermission> rRoleDocPermissions = groupByRoleId.get(roleId);
for (RRoleDocPermission rRoleDocPermission : rRoleDocPermissions) {
RRoleDocPermission rdp = new RRoleDocPermission();
BeanUtils.copyProperties(rRoleDocPermission, rdp);
// 重设id代表新增记录
rdp.setId(EvString.getUUID());
// 加入文件夹id
rdp.setFloderId(floder.getId());
save(rdp);
}
}
}
Map<String, List<ImportRowResult>> map = new HashMap<>();
List<ImportRowResult> successList = new ArrayList<>();
// 删除缓存文件
FileUtils.delPathFile(fileName);
map.put("success", successList);
commonLogService.log_Common("目录管理", "导入目录", rootFloder.getProj());
return map;
}
poi读excel

整理数据得到层级关系

/**
* @description: 读Excel文件
* @params: [filePath]
* @return: java.util.List>
* @author:
* @Date: 2019/10/11
*/
public static List<ArrayList<String>> ReadExcel(String filePath) {
// int column = 5;//column表示excel的列数
List<ArrayList<String>> list = new ArrayList<>();
try {
// 建需要读取的excel文件写入stream
HSSFWorkbook workbook = new HSSFWorkbook(new FileInputStream(filePath));
// 指向sheet下标为0的sheet 即第一个sheet 也可以按在sheet的名称来寻找
HSSFSheet sheet = workbook.getSheetAt(0);
// 获取sheet1中的总行数
int rowTotalCount = sheet.getLastRowNum();
//最大列数
int columnCount = 0;
int temp;
for (int i = 0; i <= rowTotalCount; i++) {
temp = sheet.getRow(i).getLastCellNum();
if (columnCount < temp) {
columnCount = temp;
}
}
//获取总列数
System.out.println("行数为:" + (rowTotalCount + 1) + "列数为:" + columnCount);
for (int i = 0; i <= rowTotalCount; i++) {
// 获取第i列的row对象
HSSFRow row = sheet.getRow(i);
ArrayList<String> listRow = new ArrayList<String>();
for (int j = 0; j < columnCount; j++) {
//下列步骤为判断cell读取到的数据是否为null 如果不做处理 程序会报错
String cell = null;
//如果未null则加上""组装成非null的字符串
if (row.getCell(j) == null) {
cell = row.getCell(j) + "";
listRow.add(cell);
//如果读取到额cell不为null 则直接加入 listRow集合
} else {
// 将每一个单元格的数据设置uuid唯一标识 方便后面根据uuid确定子父级关系
cell = row.getCell(j).toString() + ":" + EvString.getUUID();
listRow.add(cell);
}
// 在第i列 依次获取第i列的第j个位置上的值 %15s表示前后间隔15个字节输出
System.out.printf("%50s", cell);
}
list.add(listRow);
System.out.println();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
生成实体对象集合
/**
* @description: 生成实体对象集合
* @params: [arrayLists, rootId]
* @return: java.util.List
* @author:
* @Date: 2020/1/9
*/
private static List<Floder> getList1(List<ArrayList<String>> arrayLists, String rootId) {
List<Floder> listAll = new ArrayList<>();
for (ArrayList<String> arrayList : arrayLists) {
List<Floder> listFolder = new ArrayList<>();
for (int i = 0; i < arrayList.size(); i++) {
Floder floder = new Floder();
if ("null".equals(arrayList.get(i))) {
continue;
}
String[] split = arrayList.get(i).trim().split(":");
if (i == 0) {
floder.setParentId(rootId);
floder.setName(split[0]);
floder.setId(split[1]);
} else {
floder.setParentId(listFolder.get(i - 1).getId());
floder.setName(split[0]);
floder.setId(split[1]);
}
listFolder.add(floder);
}
listAll.addAll(listFolder);
}
return listAll;
}