深入Android系统 Binder-4-驱动
Binder驱动
Binder 驱动是整个Binder框架的核心,这部分就会详细介绍
消息协议、内存共享机制、对象传递的具体细节了
应用层和驱动的消息协议
Binder应用层的IPCThreadState和Binder驱动之间通过ioctl来传递数据,因此,定义了一些ioctl命令:
| 命令 | 说明 | 数据格式 |
|---|---|---|
BIDNER_WRITE_READ |
向驱动读取和写入数据,既可以单独读写,也可以同时读写。通过传入的数据中有无读写数据来控制 | struct binder_write_read |
BINDER_SET_IDLE_TIMEOUT |
有定义未使用 | int64_t |
BINDER_SET_MAX_THREADS |
设置线程池的最大线程数,达到上限后驱动将不会通知应用层启动新线程 | size_t |
BINDER_SET_IDLE_PRIORITY |
有定义未使用 | int |
BINDER_SET_CONTEXT_MGR |
将本进程设置为Binder系统的管理进程,只有ServiceManager进程才会使用这个命令 |
int |
BINDER_THREAD_EXIT |
通知驱动当前线程要退出了,以便驱动清理和该线程相关的数据 | int |
BINDER_VERSION |
获取Binder的版本号 |
struct binder_verison |
表中的命令中。最常用的命令是BIDNER_WRITE_READ,其余都是一些辅助性命令。BIDNER_WRITE_READ使用的数据格式定义如下:
struct binder_write_read {
binder_size_t write_size; //计划向驱动写入的字节长度
binder_size_t write_consumed; //实际写入驱动的长度,书中称驱动实际读取的字节长度
binder_uintptr_t write_buffer;//传递给驱动数据的buffer指针,也就是真正要写入的数据
binder_size_t read_size; //计划从驱动中读取的字节长度
binder_size_t read_consumed; //实际从驱动中读取到的字节长度
binder_uintptr_t read_buffer; //接收存放读取到的数据的指针
};
存放在read_buffer和write_buffer中的数据也是有格式的,格式是消息ID加上binder_transaction_data,binder_transaction_data定义如下:
struct binder_transaction_data {
union {
__u32 handle;
binder_uintptr_t ptr;
} target; // BpBinder对象使用handle,BBinder使用ptr
binder_uintptr_t cookie; // 对于BBinder对象,这里是BBinder的指针
__u32 code; // Binder服务的函数号码
__u32 flags;
pid_t sender_pid; // 发送方的进程ID
uid_t sender_euid; // 发送方的euid
binder_size_t data_size; // 整个数据区的大小
binder_size_t offsets_size; // IPC对象区域的大小
union {
struct {
binder_uintptr_t buffer; // 指向数据区开头的指针
binder_uintptr_t offsets;// 指向数据区中IPC对对象区的指针
} ptr;
__u8 buf[8];
} data;
};
结构binder_transaction_data中:
data.ptr指向传递给驱动的数据区的起始地址传递给驱动的数据区就是从应用层传递下来的Parcel对象的数据区
- 在
Parcel对象中如果打包了IPC对象(也就是Binder对象),或者文件描述符,数据区中会有一段空间专门用来保存这部分数据。- 因此使用
data.ptr.offsets表示数据区IPC对象的起始位置 - 用
offsets_size表示数据区IPC对象的大小
- 因此使用
Binder消息则根据发送和接收分为两套,从命名上也比较容易区分:
发送类型的指的是消息从应用层到驱动的过程,通常以BC_开头接收类型的指的是消息从驱动到应用层的过程,通常以BR_开头
发送给驱动的Binder命令列表
| 命令 | 说明 |
|---|---|
BC_TRANSACTION |
发送Binder调用的数据 |
BC_REPLY |
返回Binder调用的返回值 |
BC_ACQUIRE_RESULT |
回应BR_ATTEMPT_ACQUIRE命令 |
BC_FREE_BUFFER |
释放通过mmap分配的内存块 |
BC_INCREFS |
增加Binder对象的弱引用计数 |
BC_ACQUIRE |
增加Binder对象的强引用计数 |
BC_DECREFS |
减少Binder对象的弱引用计数 |
BC_RELEASE |
减少Binder对象的强引用计数 |
BC_INCREFS_DONE |
回应BC_INCREFS指令 |
BC_ACQUIRE_DONE |
回应BC_ACQUIRE指令 |
BC_ATTEMPT_ACQUIRE |
将Binder对象的弱引用升级为强引用 |
BC_REGISTER_LOOPER |
把当前线程注册为线程池的主线程 |
BC_ENTER_LOOPER |
通知驱动,线程可以进入数据的发送和接收 |
BC_EXIT_LOOPER |
通知驱动,当前线程退出数据的发送和接收 |
BC_REQUEST_DEATH_NOTYFICATION |
通知驱动接收某个Binder服务的死亡通知 |
BC_CLEAR_DEATH_NOTYFICATION |
通知驱动不再接收某个Binder服务的死亡通知 |
BC_DEAD_BINDER_DONE |
回应BR_DEAD_BINDER命令 |
驱动返回的命令列表
| 命令 | 说明 |
|---|---|
BR_ERROR |
驱动内部出错了 |
BR_OK |
命令成功 |
BR_TRANSACTION |
Binder调用命令 |
BR_REPLY |
返回Binder调用的结果 |
BR_ACQUIRE_RESULT |
未使用 |
BR_DEAD_REPLY |
向驱动发送Binder调用时,如果对方已经死亡,则驱动回应此命令 |
BR_TRANSACTION_COMPLETE |
回应BR_TRANSACTION命令 |
BR_INCREFS |
要求增加Binder对象的弱引用计数 |
BR_ACQUIRE |
要求增加Binder对象的强引用计数 |
BR_DECREFS |
要求减少Binder对象的弱引用计数 |
BR_RELEASE |
要求减少Binder对象的强引用计数 |
BR_ATTEMPT_ACQUIRE |
要求将Binder对象的弱引用变成强引用 |
BR_NOOP |
命令成功 |
BR_SPAWN_LOOPER |
通知创建Binder线程 |
BR_FINISHED |
未使用 |
BR_DEAD_BINDER |
通知关注的Binder已经死亡 |
BR_CLEAR_DEATH_NOTYFICATION_DONE |
回应BC_CLEAR_DEATH_NOTYFICATION |
BR_FAILED_REPLY |
如果Binder调用的函数号不正确,回复本消息 |
Binder消息序列图
前面列出的两个命令列表看上去指令蛮多的,其实可以分为四类:
Binder线程管理相关Binder方法调用相关Binder对象引用计数管理相关Binder对象死亡通知相关
看下面两个序列图:
Binder调用的消息序列图:

Binder对象引用计数管理的消息序列图:

Binder驱动分析
Binder驱动中定义的操作函数如下:
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
Binder驱动中并没有实现常用的read、write操作。数据的传输都是通过ioctl操作来完成的。
Binder驱动中定义了很多的数据结构,一些主要的数据结构如下:
| 数据结构 | 说明 |
|---|---|
binder_proc |
每个使用open打开Binder设备文件的进程都会在驱动中创建一个biner_proc的结构,用来记录该进程的各种信息和状态。例如:Binder节点表、节点引用表等 |
binder_thread |
每个Binder线程在Binder驱动中都有一个binder_thread结构,记录线程相关的信息,例如要完成的任务等 |
binder_node |
binder_proc中有一张Binder节点对象表,表项是binder_node结构。代表进程中的BBinder对象,记录BBinder对象的指针、引用计数等数据 |
binder_ref |
binder_proc中还有一张节点引用表,表项是binder_ref结构。代表进程中的BpBinder对象,保存所引用的对象binder_node指针。BpBinder中的mHandler值,就是它在索引表中的位置 |
binder_buffer |
驱动通过mmap的方式创建了一块大的缓存区,每次Binder传输数据,会在缓存区分配一个binder_buffer的结构来保存数据 |
在Binder驱动中,大量使用红黑树来管理数据。Binder驱动中是由内核提供的实现,具体表现是生命的一个全局变量binder_procs:
static HLIST_HEAD(binder_procs);
所有进程的binder_proc结构体都将插入到这个变量代表的红黑树中。以binder_open的代码为例:
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc;
struct binder_device *binder_dev;
binder_debug(BINDER_DEBUG_OPEN_CLOSE, "%s: %d:%d\n", __func__,
current->group_leader->pid, current->pid);
proc = kzalloc(sizeof(*proc), GFP_KERNEL);//分配空间给binder_proc结构体
//......
get_task_struct(current->group_leader);// 获取当前进程的task结构
proc->tsk = current->group_leader;
//......
INIT_LIST_HEAD(&proc->todo);// 初始化binder_porc中的todo队列
//......
filp->private_data = proc;// 将proc保存到文件结构中,供下次调用使用
mutex_lock(&binder_procs_lock);
// 将proc插入到全局变量binder_procs中
hlist_add_head(&proc->proc_node, &binder_procs);
mutex_unlock(&binder_procs_lock);
//......
return 0;
}
binder_open函数主要功能是:
- 打开
Binder驱动的设备文件 - 为当前进程创建和初始化
binder_proc结构体proc - 将proc插入到红黑树
binder_procs中 - 将proc放入到file结构的
private_data字段中 - 调用驱动的其他操作时可以从
file结构中取出代表当前进程的binder_proc
Binder的内存共享机制
前面介绍了,用户进程打开Binder设备后,会调用mmap在驱动中创建一块内存空间用于接收传递给本进程的Binder数据。我们看下mmap的代码(这部分是9.0的源码,和书中的结构有些不同):
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
if (proc->tsk != current->group_leader)
return -EINVAL;
// 检查要求分配的空间是否大于SZ_4M的定义
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
// 检查mmap的标记,不能带有FORBIDDEN_MMAP_FLAGS
if (vma->vm_flags & FORBIDDEN_MMAP_FLAGS) {
ret = -EPERM;
failure_string = "bad vm_flags";
goto err_bad_arg;
}
//fork 的子进程无法复制映射空间,并且不允许修改属性
vma->vm_flags |= VM_DONTCOPY | VM_MIXEDMAP;
vma->vm_flags &= ~VM_MAYWRITE;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
// 真正内存分配的逻辑在 binder_alloc_mmap_handler中
ret = binder_alloc_mmap_handler(&proc->alloc, vma);
//......
}
int binder_alloc_mmap_handler(struct binder_alloc *alloc,
struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
const char *failure_string;
struct binder_buffer *buffer;
mutex_lock(&binder_alloc_mmap_lock);
//如果已分配缓存区,goto 错误
if (alloc->buffer) {
ret = -EBUSY;
failure_string = "already mapped";
goto err_already_mapped;
}
//在用户进程分配一块内存作为缓冲区
area = get_vm_area(vma->vm_end - vma->vm_start, VM_ALLOC);
//如果内存分配失败,goto 对应错误
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
//把分配的缓冲区指针放在binder_proc的buffer字段
alloc->buffer = area->addr;
//重新配置下内存起始地址和偏移量
alloc->user_buffer_offset =
vma->vm_start - (uintptr_t)alloc->buffer;
mutex_unlock(&binder_alloc_mmap_lock);
//创建物理页结构体
alloc->pages = kzalloc(sizeof(alloc->pages[0]) *
((vma->vm_end - vma->vm_start) / PAGE_SIZE),
GFP_KERNEL);
alloc->buffer_size = vma->vm_end - vma->vm_start;
//在内核分配struct buffer的内存空间
buffer = kzalloc(sizeof(*buffer), GFP_KERNEL);
//这部分和书中着实不太一样,看的晕晕的
//目前只看出内存地址关联部分
buffer->data = alloc->buffer;
list_add(&buffer->entry, &alloc->buffers);
buffer->free = 1;
binder_insert_free_buffer(alloc, buffer);
// 异步传输将可用空间大小设置为映射大小的一半
alloc->free_async_space = alloc->buffer_size / 2;
barrier();
alloc->vma = vma;
alloc->vma_vm_mm = vma->vm_mm;
/* Same as mmgrab() in later kernel versions */
atomic_inc(&alloc->vma_vm_mm->mm_count);
return 0;
// ......对应的错误信息
}
内存分配时:
- 首先调用get_vm_area在用户进程分配一块地址空间
- 接着在内核中也分配同样页数大小的空间
- 然后把它们的物理内存地址绑定在一起
- 这样应用和内核间就能共享一块空间了
当发生Binder调用时:
- 数据会从调用进程复制到内核空间中
- 驱动会在服务进程的缓冲区中寻找一块合适大小的空间来存放数据
- 因为服务进程的用户空间的缓冲区和内核空间的缓冲区是共享的
- 所以服务进程不需要将数据再从内核空间复制到用户空间
- 节省了一次复制过程
- 提高了Binder通信效率
驱动的ioctl操作
ioctl在驱动中的实现是binder_ioctl函数,用来处理ioctl操作的命令,这些命令最常见的就是BINDER_WRITE_READ,用于Binder调用,先看下这个命令的处理过程:
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
// 检查binder_stop_on_user_error的值是否小于2,这个值表示Binder中的错误数
// 大于2则挂起当前进程到binder_user_error_wait的等待队列上
ret = wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
if (ret)
goto err_unlocked;
// 获取当前线程的数据结构
thread = binder_get_thread(proc);
if (thread == NULL) {
ret = -ENOMEM;
goto err;
}
switch (cmd) {
case BINDER_WRITE_READ:
//调用 binder_ioctl_write_read 方法
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
break;
}
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
// 这里应该就是就是一次拷贝,把数据复制到内核中
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
if (bwr.write_size > 0) {
// 如果命令时传递给驱动的数据,调用 binder_thread_write 处理
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
//省略异常处理和log打印
}
if (bwr.read_size > 0) {
// 如果命令时读取驱动的数据,调用 binder_thread_read 处理
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
trace_binder_read_done(ret);
binder_inner_proc_lock(proc);
// 如果进程的todo队列不为空,唤醒用户进程处理
if (!binder_worklist_empty_ilocked(&proc->todo))
binder_wakeup_proc_ilocked(proc);
binder_inner_proc_unlock(proc);
//省略异常处理和log打印
}
// 异常处理
}
BINDER_WRITE_READ命令有可能是向驱动写数据,也可能是从驱动读数据
- 写数据,通过
binder_thread_write方法 - 读数据,通过
binder_thread_read方法 - 在下一节调用过程会细讲这两个方法
除了BINDER_WRITE_READ命令外,还有像BINDER_SET_MAX_THREADS、BINDER_SET_CONTEXT_MGR等辅助通信的命令,大家可以阅读下源码。
学习的重点还是看调用过程的数据读写部分
Binder调用过程
Binder调用是Binder驱动中最核心的活动,整个过程几乎涉及了Binder驱动所有的数据结构。我们先从调用的整体流程上来看下:
-
Binder调用从客户进程中发起- 通过
ioctl操作来运行驱动的binder_ioctl
- 通过
-
驱动接收到命令
BC_TRANSACTION后- 找到代表服务进程的binder_proc结构体
- 在服务进程的缓冲区分配一块内存来保存从客户进程传递的数据
- ioctl回复消息BR_TRANSACTION_COMPLETED
-
---------到这里,本次ioctl调用结束---------
-
客户进程收到回复消息后- 再次调用ioctl进入等待,准备读取数据,直到调用结果返回
服务进程无法知道何时会有Binder调用到达,因此它至少由一个线程在ioctl上等待。
驱动会在有调用到达时唤醒等待的线程,并将数据传给服务进程- 同一时刻可能有多个
Binder调用到达驱动为每个调用创建一个binder_transaction的结构体- 将
结构体中的work字段插入到服务进程的todo队列中todo队列是一个binder_work结构的列表- 每个进程都会有一个
todo队列来接收需要完成的工作 - 当
服务端的用户进程对ioctl执行读操作时- 会循环执行
todo队列中需要完成的任务 - 直到队列为空才挂起等待
- 会循环执行
客户进程的调用流程
上面刚刚讲到,客户进程发送的Binder调用消息会执行到函数binder_thread_write,这个函数的功能就是处理所有用户进程发送的消息,我们看下和Binder调用有关的部分:
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
//......
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
// 包结构体tr的数据复制到内核
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
// 调用 binder_transaction 函数处理
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
//......
}
对BC_TRANSACTION命令的处理就是调用了binder_transaction函数,binder_transaction函数既要处理BC_TRANSACTION也会处理BC_REPLY消息,我们先看读取的情况,也就是reply=false的情况:
- 找到代表目标进程的节点:
if (tr->target.handle) {
struct binder_ref *ref;
//查找handle对应的引用项
ref = binder_get_ref_olocked(proc, tr->target.handle,
true);
if (ref) {
//引用项的node字段保存了Binder对象节点的指针
//复制给target_node
target_node = binder_get_node_refs_for_txn(
ref->node, &target_proc,
&return_error);
} else {
//......
}
//......
} else {
//把管理进程的节点名放到target_node中
target_node = context->binder_context_mgr_node;
//......
}
- 搜寻目标线程
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
struct binder_transaction *tmp;
tmp = thread->transaction_stack;
//......
while (tmp) {
struct binder_thread *from;
spin_lock(&tmp->lock);
from = tmp->from;
if (from && from->proc == target_proc) {
atomic_inc(&from->tmp_ref);
target_thread = from;
spin_unlock(&tmp->lock);
break;
}
spin_unlock(&tmp->lock);
tmp = tmp->from_parent;
}
}
上面这段代码的逻辑是:
- 如果本次调用不是异步调用,并且调用者线程中的
transaction_stack不为NULL,则在其中查找和本次调用具有相同目标进程的transaction_stack,如果找到,则把它的目标线程设置为本次调用的目标线程。 transaction_stack是一个列表,保存了本线程所有正在执行的Binder调用的binder_transaction结构体。Binder驱动中用binder_transaction来保存一次Binder调用的所有数据,包括传递的数据、通信双发的进程、线程信息等。因为Binder调用涉及两个进程,还要向调用端传递返回值。- 所以,驱动中用结构
binder_transaction保存还没结束的Binder调用。 - 通常情况下执行
Binder调用时不会存在相同进程的Binder调用,因此target_thread的值大多为NULL
- 如果有目标线程,则使用目标线程中的
todo队列,否则使用目标进程的todo队列
if (target_thread)
e->to_thread = target_thread->pid;
e->to_proc = target_proc->pid;
4.为当前的Binder调用创建binder_transaction结构,并用调用的数据填充它。
t = kzalloc(sizeof(*t), GFP_KERNEL);
//......
tcomplete = kzalloc(sizeof(*tcomplete), GFP_KERNEL);
//......
if (!reply && !(tr->flags & TF_ONE_WAY))
t->from = thread;
else
t->from = NULL;
t->sender_euid = task_euid(proc->tsk);
t->to_proc = target_proc;
t->to_thread = target_thread;
t->code = tr->code;
t->flags = tr->flags;
if (!(t->flags & TF_ONE_WAY) &&
binder_supported_policy(current->policy)) {
/* Inherit supported policies for synchronous transactions */
t->priority.sched_policy = current->policy;
t->priority.prio = current->normal_prio;
} else {
/* Otherwise, fall back to the default priority */
t->priority = target_proc->default_priority;
}
5.在目标进程(也就是服务端)的缓冲区分配空间,复制用户进程的数据到内核
t->buffer = binder_alloc_new_buf(&target_proc->alloc, tr->data_size,
tr->offsets_size, extra_buffers_size,
!reply && (t->flags & TF_ONE_WAY));
//......
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
//......
}
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
//......
}
- 这里复制的数据是
Binder调用的参数数据,也是需要传递给服务进程的数据,因此需要缓冲区。这个缓冲区是在目标进程的大的缓冲区中分配的
- 处理传输中的
Binder对象
off_end = (void *)off_start + tr->offsets_size;
sg_bufp = (u8 *)(PTR_ALIGN(off_end, sizeof(void *)));
sg_buf_end = sg_bufp + extra_buffers_size;
off_min = 0;
for (; offp < off_end; offp++) {
//......
}
- 通过参数传递的
Binder对象需要进行转换,这里的for循环就是进行转换操作,内容较多,会在下面处理传递的Binder对象章节进行讲解
- 将本次调用的
binder_transaction结构体链接到线程的binder_stack列表中
if (!(t->flags & TF_ONE_WAY)) {
//......
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
// 书中下面注释部分的代码已经整合到 binder_proc_transaction 函数中了
// 首先,将结构 binder_transaction中的binder_work放到目标目标进程或线程的todo队列
// 然后,创建一个新的binder_work的结构体,并将它放到发送线程的todo队列
if (!binder_proc_transaction(t, target_proc, target_thread)) {
//...... 失败处理
}
}
binder_transaction结构中包含了一个binder_work的结构体,因此它可以被放到todo队列中- 本地调用时
binder_work的type被设置为BINDER_WORK_TRANSACTION后,插入了目标进程或目标线程的todo队列中 - 为了使客户进程能收到回复消息,这里也会创建一个新的
binder_work的结构体,并把它的type设置成了BINDER_WORK_TRANSAXTION_COMPLETET,并将它插入到当前线程的todo队列中
前面介绍过,在binder_thread_write函数执行完后,还会去判断是否需要执行binder_thread_read函数:
- 由于调用端执行完
BC_TRANSACTION后,会立刻执行ioctl的读指令 - 所以,在调用操作上,
binder_thread_read函数算是紧接着binder_thread_write函数后执行的
刚才新建的binder_work的结构体已经插入todo队列了,我们看下binder_thread_read函数会进行哪些和todo队列相关的操作:
while (1) {
//......
// 获得todo队列,获取失败则goto retry
if (!binder_worklist_empty_ilocked(&thread->todo))
list = &thread->todo;
else if (!binder_worklist_empty_ilocked(&proc->todo) &&
wait_for_proc_work)
list = &proc->todo;
else {
binder_inner_proc_unlock(proc);
/* no data added */
if (ptr - buffer == 4 && !thread->looper_need_return)
goto retry;
break;
}
//取出todo队列中的元素
w = binder_dequeue_work_head_ilocked(list);
//......
switch (w->type) {
//......省略大量case语句
case BINDER_WORK_TRANSACTION_COMPLETE: {
binder_inner_proc_unlock(proc);
cmd = BR_TRANSACTION_COMPLETE;
//把返回消息通过put_user放到用户空间的指针中
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
binder_stat_br(proc, thread, cmd);
kfree(w);
binder_stats_deleted(BINDER_STAT_TRANSACTION_COMPLETE);
} break;
//......省略大量case语句
}
//......
}
-
binder_thread_read函数所做的处理就是把回复消息BR_TRANSACTION_COMPLETE复制到用户空间
这样客户进程就可以收到回复消息了 -
到这里,
客户进程的调用结束了。但是,Binder调用才完成一半,接下来,看看服务进程是如何调用数据的。
服务进程的调用流程
服务进程至少有一个线程会在ioctl上等待调用的到来。服务进程调用ioctl时传递的是读数据的请求,所以最后调用的也是binder_thread_read函数,我们看下binder_thread_read函数完整的处理流程:
- 如果保存返回结果的缓冲区中还没有数据,先写入
BR_NOOP消息:
if (*consumed == 0) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
- 进入循环处理所有
todo队列中的工作
while (1) {
//......
}
- 读取线程或进程
todo队列中需要完成的工作
struct binder_work *w = NULL;
//......
if (!binder_worklist_empty_ilocked(&thread->todo))
list = &thread->todo;
else if (!binder_worklist_empty_ilocked(&proc->todo) &&
wait_for_proc_work)
list = &proc->todo;
//......
w = binder_dequeue_work_head_ilocked(list);
- 用
switch语句处理所有类型的工作
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
binder_inner_proc_unlock(proc);
t = container_of(w, struct binder_transaction, work);
} break;
}
- 经过
客户进程的调用流程后,此时的服务进程中已经存在一个类型为BINDER_WORK_TRANSACTION的工作需要处理 - 这里只是取出了和
binder_work关联的binder_transaction结构体指针 - 并保存到变量
t中
- 调整线程的优先级
if (!t)
continue;
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
struct binder_priority node_prio;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
node_prio.sched_policy = target_node->sched_policy;
node_prio.prio = target_node->min_priority;
binder_transaction_priority(current, t, node_prio,
target_node->inherit_rt);
cmd = BR_TRANSACTION;
}
- 这里复制的数据是
Binder调用的参数数据,也是需要传递给服务进程的数据,因此需要缓冲区。这个缓冲区是在目标进程的大的缓冲区中分配的
- 处理传输中的
Binder对象
off_end = (void *)off_start + tr->offsets_size;
sg_bufp = (u8 *)(PTR_ALIGN(off_end, sizeof(void *)));
sg_buf_end = sg_bufp + extra_buffers_size;
off_min = 0;
for (; offp < off_end; offp++) {
//......
}
- 通过参数传递的
Binder对象需要进行转换,这里的for循环就是进行转换操作,内容较多,会在下面处理传递的Binder对象章节进行讲解
- 将本次调用的
binder_transaction结构体链接到线程的binder_stack列表中
if (!(t->flags & TF_ONE_WAY)) {
//......
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
// 书中下面注释部分的代码已经整合到 binder_proc_transaction 函数中了
// 首先,将结构 binder_transaction中的binder_work放到目标目标进程或线程的todo队列
// 然后,创建一个新的binder_work的结构体,并将它放到发送线程的todo队列
if (!binder_proc_transaction(t, target_proc, target_thread)) {
//...... 失败处理
}
}
binder_transaction结构中包含了一个binder_work的结构体,因此它可以被放到todo队列中- 本地调用时
binder_work的type被设置为BINDER_WORK_TRANSACTION后,插入了目标进程或目标线程的todo队列中 - 为了使
客户进程能收到回复消息,这里也会创建一个新的binder_work的结构体,并把它的type设置成了BINDER_WORK_TRANSAXTION_COMPLETET,并将它插入到当前线程的todo队列中
前面介绍过,在binder_thread_write函数执行完后,还会去判断是否需要执行binder_thread_read函数:
- 由于调用端执行完
BC_TRANSACTION后,会立刻执行ioctl的读指令 - 所以,在调用操作上,
binder_thread_read函数算是紧接着binder_thread_write函数后执行的
刚才新建的binder_work的结构体已经插入todo队列了,我们看下binder_thread_read函数会进行哪些和todo队列相关的操作:
while (1) {
//......
// 获得todo队列,获取失败则goto retry
if (!binder_worklist_empty_ilocked(&thread->todo))
list = &thread->todo;
else if (!binder_worklist_empty_ilocked(&proc->todo) &&
wait_for_proc_work)
list = &proc->todo;
else {
binder_inner_proc_unlock(proc);
/* no data added */
if (ptr - buffer == 4 && !thread->looper_need_return)
goto retry;
break;
}
//取出todo队列中的元素
w = binder_dequeue_work_head_ilocked(list);
//......
switch (w->type) {
//......省略大量case语句
case BINDER_WORK_TRANSACTION_COMPLETE: {
binder_inner_proc_unlock(proc);
cmd = BR_TRANSACTION_COMPLETE;
//把返回消息通过put_user放到用户空间的指针中
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
binder_stat_br(proc, thread, cmd);
kfree(w);
binder_stats_deleted(BINDER_STAT_TRANSACTION_COMPLETE);
} break;
//......省略大量case语句
}
//......
}
binder_thread_read函数所做的处理就是把回复消息BR_TRANSACTION_COMPLETE复制到用户空间- 这样
客户进程就可以收到回复消息了
到这里,客户进程的调用结束了。但是,Binder调用才完成一半,接下来,看看服务进程是如何调用数据的。
服务进程的调用流程
服务进程至少有一个线程会在ioctl上等待调用的到来。服务进程调用ioctl时传递的是读数据的请求,所以最后调用的也是binder_thread_read函数,我们看下binder_thread_read函数完整的处理流程:
- 如果保存返回结果的缓冲区中还没有数据,先写入
BR_NOOP消息:
if (*consumed == 0) {
if (put_user(BR_NOOP, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
}
- 进入循环处理所有
todo队列中的工作
while (1) {
//......
}
- 读取线程或进程
todo队列中需要完成的工作
struct binder_work *w = NULL;
//......
if (!binder_worklist_empty_ilocked(&thread->todo))
list = &thread->todo;
else if (!binder_worklist_empty_ilocked(&proc->todo) &&
wait_for_proc_work)
list = &proc->todo;
//......
w = binder_dequeue_work_head_ilocked(list);
- 用
switch语句处理所有类型的工作
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
binder_inner_proc_unlock(proc);
t = container_of(w, struct binder_transaction, work);
} break;
}
- 经过
客户进程的调用流程后,此时的服务进程中已经存在一个类型为BINDER_WORK_TRANSACTION的工作需要处理 - 这里只是取出了和
binder_work关联的binder_transaction结构体指针 - 并保存到变量
t中
- 调整线程的优先级
if (!t)
continue;
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
struct binder_priority node_prio;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
node_prio.sched_policy = target_node->sched_policy;
node_prio.prio = target_node->min_priority;
binder_transaction_priority(current, t, node_prio,
target_node->inherit_rt);
cmd = BR_TRANSACTION;
}
- 如果t为NULL,继续循环
- 否则,开始准备返回的消息
BR_TRANSACTION - 同时,设置线程的优先级
- 如果
调用线程的优先级低于当前线程指定的最低优先级,则把当前线程的优先级设为调用线程的优先级 - 否则,把
当前线程设为指定的最低优先级 - 这意味着
Binder线程会以尽量低的优先级运行
- 如果
- 准备返回的数据
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = from_kuid(current_user_ns(), t->sender_euid);
//......
// 让tr中的data指针指向内核中保存的数据缓冲区
tr.data_size = t->buffer->data_size;
tr.offsets_size = t->buffer->offsets_size;
tr.data.ptr.buffer = (binder_uintptr_t)
((uintptr_t)t->buffer->data +
binder_alloc_get_user_buffer_offset(&proc->alloc));
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
// 把 BR_TRANSACTION 消息复制到用户空间
if (put_user(cmd, (uint32_t __user *)ptr)) {
//......
return -EFAULT;
}
ptr += sizeof(uint32_t);
if (copy_to_user(ptr, &tr, sizeof(tr))) {
//把结构体tr数据复制到用户空间
//......
return -EFAULT;
}
ptr += sizeof(tr);
//......
break;//跳出while循环
这一段代码都是为消息BR_TRANSACTION准备返回数据,要注意的是:
- 调用
copy_to_user复制到用户空间的只是结构体tr的数据 服务进程得到这个结构体之后,会直接读取它里面的data指针的数据- 数据准备完毕后,使用
break语句跳出while循环
- 启动新线程
if (proc->requested_threads == 0 &&
list_empty(&thread->proc->waiting_threads) &&
proc->requested_threads_started < proc->max_threads &&
(thread->looper & (BINDER_LOOPER_STATE_REGISTERED |
BINDER_LOOPER_STATE_ENTERED)) /* the user-space code fails to */
/*spawn a new thread if we leave this out */) {
proc->requested_threads++;
//......
if (put_user(BR_SPAWN_LOOPER, (uint32_t __user *)buffer))
return -EFAULT;
}
当前线程要执行Binder调用,新来的调用也需要线程来处理,因此:
- 函数结束前会检查进程中可用的线程数
- 如果需要创建新线程,则在返回的
buffer数据中增加BR_SPAWN_LOOPER消息,服务进程收到这个消息会启动新的线程
- 如果需要创建新线程,则在返回的
完整的Binder调用过程还需要把回复消息传递给客户进程,这个过程使用的函数还是前面的这些,暂时不分析了。消化一下先
处理传递的Binder对象
前面介绍了Binder对象传递的原理和用户层的实现。(原理上整个人还是晕晕的),我们来看下Binder驱动如何实现Binder对象的传递的。
Binder驱动中,代表每个进程的结构binde_proc中有两个字段:nodes和refs_by_node- 这两个字段各指向两颗红黑树的头
nodes:指向的是Binder节点对象表,储存本进程中Binder实体对象相关的数据refs_by_node:指向的是Binder引用对象表,存储本进程的Binder引用对象的数据以及对应的实体对象的节点指针
来个抽象点的图:
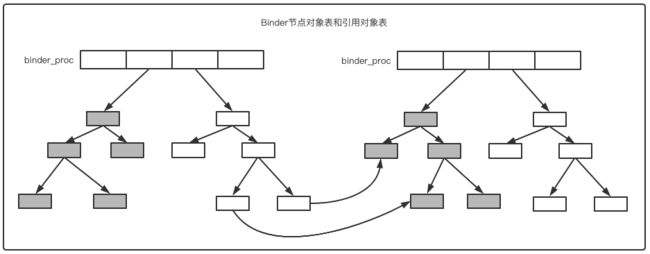
Binder驱动中处理对象转换的代码位于函数binder_transaction中
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
struct flat_binder_object *fp;
fp = to_flat_binder_object(hdr);
ret = binder_translate_binder(fp, t, thread);
} break;
static int binder_translate_binder(struct flat_binder_object *fp,
struct binder_transaction *t,
struct binder_thread *thread)
{
struct binder_node *node;
struct binder_proc *proc = thread->proc;
struct binder_proc *target_proc = t->to_proc;
struct binder_ref_data rdata;
int ret = 0;
//根据binder值查找Binder对象表中的节点
node = binder_get_node(proc, fp->binder);
if (!node) { //没有则新建一个节点
node = binder_new_node(proc, fp);
if (!node)
return -ENOMEM;
}
//......
if (security_binder_transfer_binder(proc->tsk, target_proc->tsk)) {
ret = -EPERM;
goto done;
}
// 在接收端进程中寻找节点的引用,找不到会创建一个新的引用
ret = binder_inc_ref_for_node(target_proc, node,
fp->hdr.type == BINDER_TYPE_BINDER,
&thread->todo, &rdata);
if (ret)
goto done;
// 将传递的binder数据结构的type的值改为 BINDER_TYPE_HANDLE
if (fp->hdr.type == BINDER_TYPE_BINDER)
fp->hdr.type = BINDER_TYPE_HANDLE;
else
fp->hdr.type = BINDER_TYPE_WEAK_HANDLE;
fp->binder = 0;
// rdata.desc存放的是节点引用表中的序号,赋值给handle
fp->handle = rdata.desc;
fp->cookie = 0;
//......
}
上面的流程是
- 通过
binder_get_node函数在发送进程的Binder对象节点表中查找节点- 查找是通过比较数据中的
binder字段和节点中对应的字段进行的 binder字段中存放的是Binder对象的弱引用指针- 如果没找到
- 新建节点
- 把
binder字段、cookie字段的值保存到新节点
- 查找是通过比较数据中的
- 通过
binder_inc_ref_for_node函数在目标进程查找Binder节点的引用。- 没找到会新建一个
引用指的是节点引用表中的refs_by_node节点,包含指向Binder节点的指针
- 把数据的
type字段的值改为BINDER_TYPE_HANDLE或BINDER_TYPE_WEAK_HANDLE - 把
handle字段的值设为在节点引用表的序号,这也是Binder引用对象中handle值的来历
下面再看看如何处理类型BINDER_TYPE_HANDLE或BINDER_TYPE_WEAK_HANDLE的
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
struct flat_binder_object *fp;
fp = to_flat_binder_object(hdr);
ret = binder_translate_handle(fp, t, thread);
} break;
static int binder_translate_handle(struct flat_binder_object *fp,
struct binder_transaction *t,
struct binder_thread *thread)
{
//......
// 通过handle值查找节点引用
node = binder_get_node_from_ref(proc, fp->handle,
fp->hdr.type == BINDER_TYPE_HANDLE, &src_rdata);
if (!node) {
//.....
return -EINVAL;
}
//......
if (node->proc == target_proc) {
// 如果目标进程就是Binder对象的进程,开始转换
if (fp->hdr.type == BINDER_TYPE_HANDLE)
fp->hdr.type = BINDER_TYPE_BINDER;
else
fp->hdr.type = BINDER_TYPE_WEAK_BINDER;
fp->binder = node->ptr;
fp->cookie = node->cookie;
if (node->proc)
binder_inner_proc_lock(node->proc);
binder_inc_node_nilocked(node,
fp->hdr.type == BINDER_TYPE_BINDER,
0, NULL);
//......
} else {
//......
// 如果不是,则在目标进程新建一个Binder节点的引用
ret = binder_inc_ref_for_node(target_proc, node,
fp->hdr.type == BINDER_TYPE_HANDLE,
NULL, &dest_rdata);
//......
fp->handle = dest_rdata.desc;
fp->cookie = 0;
trace_binder_transaction_ref_to_ref(t, node, &src_rdata,
//......
}
}
这部分代码的流程是:
- 通过传输数据的
handle字段在发送进程的节点引用表中查找- 正常情况下是可以找到,不能就错误返回
- 如果目标进程就是Binder对象所在的进程
- 开始进行转换,把数据的
type字段转为BINDER_TYPE_BINDER或BINDER_TYPE_WEAK_BINDERBINDER_WORK_TRANSACTION - 把
binder和cookie字段设置为节点中保存的值
- 开始进行转换,把数据的
- 如果目标进程不是Binder对象所在的进程
- 在目标对象中建立一个节点对象的引用
到这里呢,Binder原理部分就差不多了,已经了解了包括:
- 客户端
调用、接收消息的过程 - 服务端
监听、回复消息的过 - 驱动
传输数据、调度线程的操作
现在,我们再来看最后的一小部分:ServiceManager的作用
ServiceManager的作用
关于ServiceManager,先简单描述:
ServiceManager是Binder架构中用来解析Binder名称的模块ServiceManager本身就是一个Binder服务ServiceManager并没有使用libbinder来构建Binder服务- 2020-09-04 同步了下项目代码,发现也替换成
libbinder那一套了。。。。。 - 不确定是不是更换仓储了
- 要是这样就没意思了,简易版本对于加深
binder理解还是很有帮助的 - 我们暂且按照老的版本来看下吧
- 2020-09-04 同步了下项目代码,发现也替换成
ServiceManager自己实现了一个简单的binder框架来直接和驱动通信。。。
ServiceManager源码路径在:frameworks/native/cmds/servicemanager,主要包含两个文件:
-
binder.c:用来实现简单的Binder通信功能- 简单版本的
binder协议实现 - 直接的
ioctl操作与binder驱动通信 - 不是本节的重点,感兴趣可以参照源码来学习啦
- 简单版本的
-
service_manager.c:用来实现ServiceManager的业务逻辑- 重点是了解
ServiceManager如何响应Binder服务的注册和查询的
- 重点是了解
-
这么重要的服务要在什么时间启动呢?
-
这部分是在
system/core/rootdir/init.rc中配置on post-fs ...... # start essential services start logd start servicemanager start hwservicemanager start vndservicemanager -
hwservicemanager用来支持HIDL -
vndservicemanager第三方厂商使用,应该是从Treble架构中出现的
-
ServiceManager的架构
从ServiceManager的main函数开始:
int main(int argc, char** argv)
{
struct binder_state *bs;
union selinux_callback cb;
char *driver;
if (argc > 1) {
driver = argv[1];
} else {
driver = "/dev/binder";
}
bs = binder_open(driver, 128*1024);
if (!bs) {
//......
// 省略一些宏判断
return -1;
}
if (binder_become_context_manager(bs)) {
ALOGE("cannot become context manager (%s)\n", strerror(errno));
return -1;
}
// 设置selinux callback
cb.func_audit = audit_callback;
selinux_set_callback(SELINUX_CB_AUDIT, cb);
cb.func_log = selinux_log_callback;
selinux_set_callback(SELINUX_CB_LOG, cb);
//......
// 省略一些宏判断,都是为了获取sehandle(检查SELinux权限)
sehandle = selinux_android_service_context_handle();
selinux_status_open(true);
if (sehandle == NULL) {
ALOGE("SELinux: Failed to acquire sehandle. Aborting.\n");
abort();
}
if (getcon(&service_manager_context) != 0) {
ALOGE("SELinux: Failed to acquire service_manager context. Aborting.\n");
abort();
}
binder_loop(bs, svcmgr_handler);
return 0;
}
main函数的流程如下:
- 首先调用
binder_open来打开binder设备和初始化系统- 同时创建一块
128x1024大小的内存空间
- 同时创建一块
- 接着调用
binder_become_context_manager把本进程设置为Binder框架的管理进程-
binder_become_context_manager函数代码如下:int binder_become_context_manager(struct binder_state *bs) { return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0); } -
函数灰常简单,直接通过
ioctl把控制命令BINDER_SET_CONTEXT_MGR发到了驱动
-
- 最后执行
binder_loop(bs, svcmgr_handler),简单处理后,循环等待消息
我们要说一说binder_loop(bs, svcmgr_handler),小弟C语言不熟,感觉这个操作很SAO:
binder_loop的函数定义是:
void binder_loop(struct binder_state *bs, binder_handler func)
- 第二个参数传入的是一个
binder_handler类型
- 再来看下
binder_handler类型的定义:
typedef int (*binder_handler)(struct binder_state *bs,
struct binder_transaction_data *txn,
struct binder_io *msg,
struct binder_io *reply);
- 这是定义了一个
函数指针类型 - 返回值是
int
- 再来看下
binder_loop(bs, svcmgr_handler)中的svcmgr_handler函数的声明
int svcmgr_handler(struct binder_state *bs,
struct binder_transaction_data *txn,
struct binder_io *msg,
struct binder_io *reply)
{
//......
// 省略一些switch语句,稍后详解
return 0;
}
- 传入的指针是
svcmgr_handler函数指针 - 应该会自动转型为
binder_handler指针类型 - 毕竟函数参数、返回值都是一样的
- 这部分是我觉得最神奇的地方。。。。。
- 特意写了个C代码试了下,
- 如果定义的函数的
参数、返回值与typedef定义的函数指针不一致的话,强转编译会失败 - 不过这种操作感觉还是很不正经。。(还是Java更严谨一些)
-
参数理解的差不多了,我们仔细看下
binder_loop的实现,这两个参数传进去干了啥。PS:简化版就是更容易理解些。。。。。。
void binder_loop(struct binder_state *bs, binder_handler func)
{
int res;
struct binder_write_read bwr;
uint32_t readbuf[32];
// 老样子,用来记录写入到驱动的一些相关参数
bwr.write_size = 0;
bwr.write_consumed = 0;
bwr.write_buffer = 0;
// 该属性应该是通知驱动已经准备好接收数据了
readbuf[0] = BC_ENTER_LOOPER;
binder_write(bs, readbuf, sizeof(uint32_t));
for (;;) {
//无限循环
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
// 开始读取数据
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
if (res < 0) {
// 异常通信,退出循环
ALOGE("binder_loop: ioctl failed (%s)\n", strerror(errno));
break;
}
// 读取到数据后
// 调用 binder_parse 进行数据解析
// 顺便把 binder_handler 函数指针也传递进去
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
// 异常情况,退出循环
if (res == 0 || res < 0) {
//......
break;
}
}
}
- 有注释,很很简洁的逻辑
- 最后执行到了
binder_parse函数
- 我们继续跟进
binder_parse函数
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
int r = 1;
uintptr_t end = ptr + (uintptr_t) size;
while (ptr < end) {
//取指令
uint32_t cmd = *(uint32_t *) ptr;
switch(cmd) {
//......
// 由于binder_handler 在这里会被执行到
// 所以我们先重点看这个,当Binder调用过来时
case BR_TRANSACTION: {
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
// 数据检查
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: txn too small!\n");
return -1;
}
binder_dump_txn(txn);
// 如果函数指针存在
if (func) {
unsigned rdata[256/4];
struct binder_io msg;
struct binder_io reply;
int res;
// 一些初始化操作
bio_init(&reply, rdata, sizeof(rdata), 4);
bio_init_from_txn(&msg, txn);
//执行 binder_handler 函数指针指向的函数
res = func(bs, txn, &msg, &reply);
if (txn->flags & TF_ONE_WAY) {
// 这种情况不会返回结果
binder_free_buffer(bs, txn->data.ptr.buffer);
} else {
// 返回结果数据
binder_send_reply(bs, &reply, txn->data.ptr.buffer, res);
}
}
ptr += sizeof(*txn);
break;
}
//......
}
return r;
}
- 还是看注释哈,代码很简洁,注释很详细,哈哈哈
- 到这里,我们可以看出来,真正处理
调用服务的是binder_handler这个函数指针啊 - 也就是说
远程调用的处理逻辑在svcmgr_handler这个函数呀- 666!
- 我们来看下
svcmgr_handler函数
int svcmgr_handler(struct binder_state *bs,
struct binder_transaction_data *txn,
struct binder_io *msg,
struct binder_io *reply)
{
//......
// 如果请求的目标服务不是ServiceManager,直接返回
if (txn->target.ptr != BINDER_SERVICE_MANAGER)
return -1;
// 如果请求消息内容只是简单的测试通路,不需要继续执行,直接返回 0
if (txn->code == PING_TRANSACTION)
return 0;
// 检查收到的消息 id 串
strict_policy = bio_get_uint32(msg);
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
//......
// 检查SELinux 的权限
if (sehandle && selinux_status_updated() > 0) {
struct selabel_handle *tmp_sehandle = selinux_android_service_context_handle();
if (tmp_sehandle) {
selabel_close(sehandle);
sehandle = tmp_sehandle;
}
}
switch(txn->code) {
case SVC_MGR_GET_SERVICE:
case SVC_MGR_CHECK_SERVICE:
// 处理查询或者获取服务的指令
//......
break;
case SVC_MGR_ADD_SERVICE:
// 处理注册服务的的指令
//......
break;
case SVC_MGR_LIST_SERVICES: {
//......
// 处理获取服务列表的指令
}
default:
ALOGE("unknown code %d\n", txn->code);
return -1;
}
//发送返回消息
bio_put_uint32(reply, 0);
return 0;
}
ServiceManager的架构非常简单高效,只有一个循环来和binder驱动进行通信
ServiceManager提供的服务
从svcmgr_handler函数中可以看到,ServiceManager提供了三种服务功能:
- 注册
Binder服务 - 查询
Binder服务 - 获取
Binder服务列表
注册Binder服务
在case SVC_MGR_ADD_SERVICE中实现的注册Binder服务功能,具体的实现函数是do_add_service,代码如下:
int do_add_service(struct binder_state *bs, const uint16_t *s, size_t len, uint32_t handle,
uid_t uid, int allow_isolated, uint32_t dumpsys_priority, pid_t spid) {
struct svcinfo *si;
// 一些基础的信息判断
if (!handle || (len == 0) || (len > 127))
return -1;
// 检查调用进程是否有权限注册服务
if (!svc_can_register(s, len, spid, uid)) {
//......省略log打印
return -1;
}
// 查看要注册的服务是否已经存在
si = find_svc(s, len);
if (si) {
// 如果存在,先把以前的Binder对象的引用计数减一
if (si->handle) {
svcinfo_death(bs, si);
}
// 把原先节点中的handle替换成新的handle
si->handle = handle;
} else {
// 服务不存在,则生成新的列表项,初始化后加入列表
si = malloc(sizeof(*si) + (len + 1) * sizeof(uint16_t));
if (!si) {
// 内存申请失败,直接退出
return -1;
}
// 一些初始化操作
si->handle = handle;
si->len = len;
memcpy(si->name, s, (len + 1) * sizeof(uint16_t));
si->name[len] = '\0';
si->death.func = (void*) svcinfo_death;
si->death.ptr = si;
si->allow_isolated = allow_isolated;
si->dumpsys_priority = dumpsys_priority;
si->next = svclist;
svclist = si;
}
// 增加Binder服务的引用计数
binder_acquire(bs, handle);
// 注册该Binder服务的死亡通知
binder_link_to_death(bs, handle, &si->death);
return 0;
}
do_add_service函数的流程是:
-
首先检查调用的进程是否有注册服务的权限
- 这部分是通过SELinux来控制的,后面会学习到
-
接着检查需要注册的服务是否已经存在
- 存在,把原来Binder服务在驱动的引用计数减一
- 不存在
- 新创建一个scvinfo结构
- 填充需要待注册服务的相关信息到结构中
- 把结构加入到服务列表svclist
-
通知内核把Binder服务的引用计数加一
-
注册该服务的死亡通知
有木有发现对于服务已经存在的情况:
- 进行了先减一再加一的操作
- 是不是可以不用操作计数也可以呢?
可以思考下
查询Binder服务
在case SVC_MGR_CHECK_SERVICE中处理查询服务的功能,具体的实现接口是do_find_service函数,代码如下:
uint32_t do_find_service(const uint16_t *s, size_t len, uid_t uid, pid_t spid)
{
struct svcinfo *si = find_svc(s, len);
if (!si || !si->handle) {
return 0;
}
if (!si->allow_isolated) {
// If this service doesn't allow access from isolated processes,
// then check the uid to see if it is isolated.
uid_t appid = uid % AID_USER;
if (appid >= AID_ISOLATED_START && appid <= AID_ISOLATED_END) {
return 0;
}
}
if (!svc_can_find(s, len, spid, uid)) {
return 0;
}
return si->handle;
}
do_find_service函数的主要工作是搜索列表、返回查找到的服务。请注意有一段判断uid的代码:
- 在调用
ServiceManager的addBinder服务时有个参数allowed_isolated,用来指定服务是否允许从沙箱中访问 - 这里的代码应该是判断调用进程是否是一个
隔离进程- 如果
appid在AID_ISOLATED_START(99000)和AID_ISOLATED_END(99999)之间 - 表明这个服务可以通过
allowed_isolated来控制是否允许一般的用户进程来使用其服务
- 如果
结语
终于、终于看完了。
书中后面其实还有ashmem 匿名共享内存的内容(Android自己实现的,在mmap基础上开发的,基于binder通信的内存共享)
想了想暂时不作为binder的笔记内容了,binder涉及的内容已经很复杂了,不过看完之后也是收获颇丰哈。

在码云上查看更多的架构资料:https://gitee.com/androidmaniu/android-notes/blob/master/README.md