Day1:SpringBoot入门学习——传智播客学习笔记【微服务电商】
1.了解SpringBoot
什么是SpringBoot
为什么要学习SpringBoot
SpringBoot有什么特点
1.1 什么是SpringBoot
用固定的方式构建一个生产级别的Spring应用(什么是固定方式,即构建所需要的配置,环境等条件都被封装好了),SpringBoot推崇约定大于配置的方式,让我们尽可能快的启动并运行程序(约定大于配置,即我们只要按照它的约定去做,那些配置都它帮我们配置好了)
图标就类似一个开机键——帮助我们尽可能快的启动并运行
1.2 为什么要学习SpringBoot
因为Java被人诟病的就是在编写代码前需要搭建项目:
1. 复杂的配置
比如xml配置文件的配置很复杂(和Java语言的语法/编写思维不同,不易于编写)
2. 混乱的依赖管理
比如在搭建环境的时候你要导入很多库,而且还要选择合适的版本,因为版本之间也可能存在冲突,并且在依赖版本出现冲突时,想要查出错误也是比较困难

那么这时候就出现了SpringBoot
SpringBoot简化了基于Spring的应用开发,只需要“run”就能创建一个独立的,生产级别的Spring应用,而且还为Spring平台即第三方库提供了开箱即用的设置(提供了默认设置,其中存放默认配置的包就是 启动器starter),而且还会对配置做些适当的优化,绝大多数SpringBoot应用只需要很少的Spring配置
1.3 SpringBoot特点
1.为Spring开发提供了快捷,便利的入门体验(不用手动搭建环境)
2.开箱即用
3.提供了大型项目常用的非功能性的特性,如内嵌服务器,安全,指针,健康检测,外部化配置(就是帮我们做了优化)
4.无需XML配置也不会生产代码(配置极其简单)
2.快速入门
要想SpringBoot帮你配置Spring,就需要将SpringBoot作为父工程
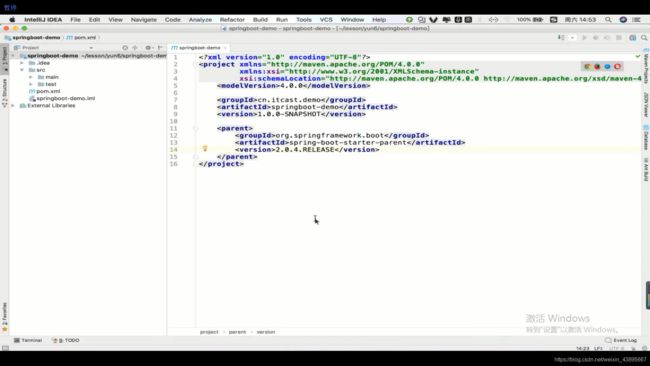
父工程内部已经帮我们导入很多配置
导入之后 如果我们想创建一个web项目 那么就要加上一个web的启动器
那么我们就要编写代码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hKExfbmq-1581855547987)(D:\有道云笔记\[email protected]\14002accb6fa4d3b95f4b5733a7d84f9\clipboard.png)\
只需加上@Spring Boot Application的注解和run方法即可配置完毕,也就可以在浏览器访问,端口号也在下面的日志里可以看到,写个简单的demo就可以访问了
以上SpringMVC就配置完了
由于SpringBoot是使用spring 3.0,所以就可以通过注解的形式配置web.xml(spring 2.5不行)
那么还有ApplicationContext.xml呢,里面之前会配置数据库连接池等信息

现在要如何配置呢
我们就需要回顾spring历史
Spring 1.0时代:几乎都是用xml配置任何的bean(很麻烦)```
Spring 2.0时代:出现了注解,但还不是很完善并没有完全取代xml配置,而且在事务配置的时候,xml也非常的方便,以及上面的数据库的配置,都是xml比较的方便(因为这个bean比较复杂,有几个属性),所以都是xml结合注解一起使用
Spring 3.0时代及以后:注解以及很完善了,所以Spring推荐使用Java配置l来代替xml
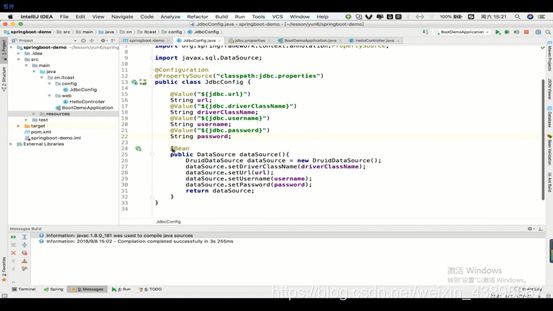
Java配置(就以上面的配置连接池为例)
1.首先由于是配置数据库,所以要导入连接池依赖(这里用的是druid)
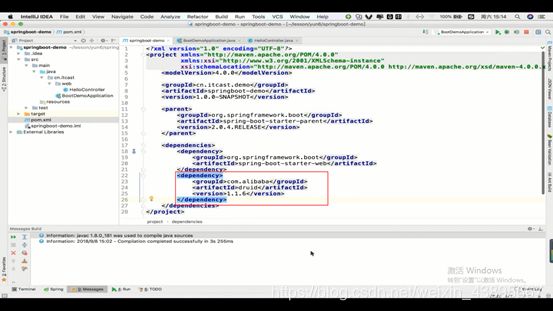
2.Java配置是通过用Java的一个类作为配置类,那么就要在这个类上做一个注解来代替xml
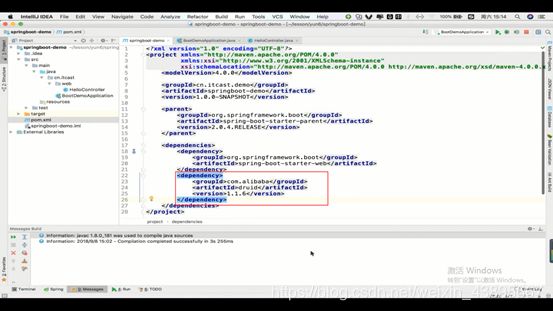
3.那么原先的xml配置是通过导入库的全路径类名来找到该类再通过反射的原理创建对象,那么这里用Java的配置类配置的连接池也要把连接池对象返回回去(即要用@Bean先注解连接池对象,再return回去),那么就还有这个连接池对象里面的各个属性(既然使用Java类配置,属性就只需要用setXX()方法即可赋值)。

那么这下属性的值和之前xml配置数据库一样,同样可以通过properties来配置外部属性
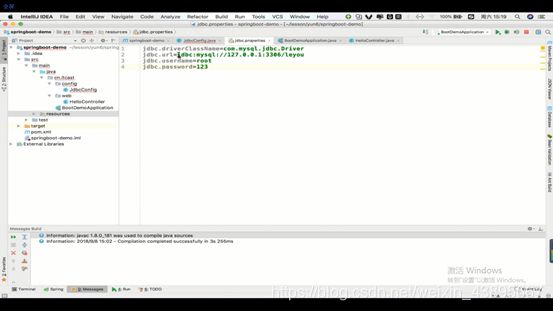
只需要再加上注解@propertySource(里面的路径可以通过点击查看源码 看到value)
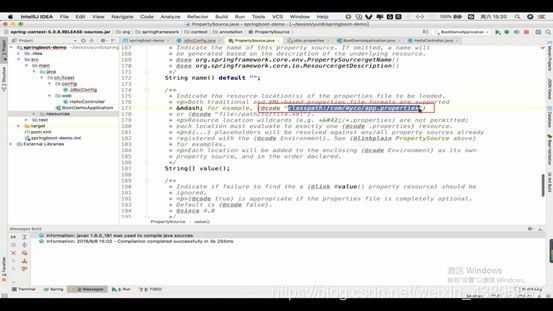
以及各个属性的配置也要写上
通过这些配置,我们用断点来验证下是否创建好了数据库连接池
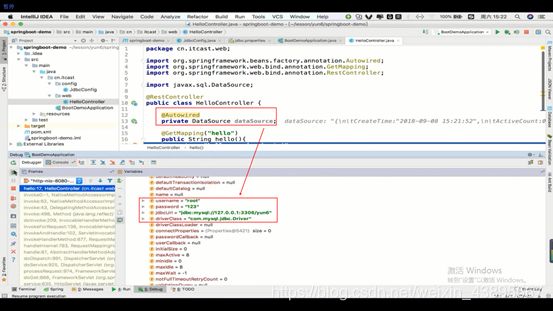
发现没有任何问题,这种配置也是比之前的要简单
但这里还有一个麻烦你就是配置属性时使用了很多的注解(引用外部属性的注解)
我们用SpringBoot提供的两种方法实现
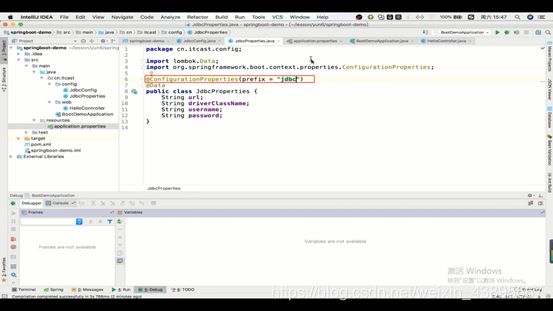
1.通过另一个注解(@ConfigurationProperty)来实现
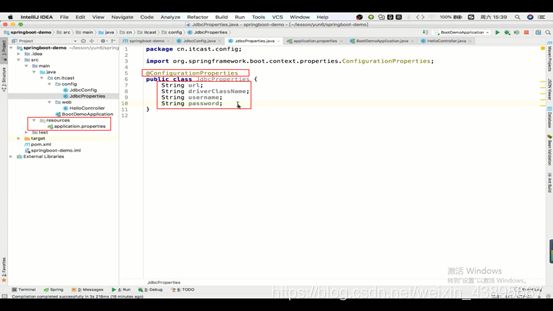
这里有个小问题,就是原本的Properties配置文件的属性是jdbc.url(是有jdbc前缀的,为什么要有前缀呢,因为不可能只有一个数据库,而多个数据库时就是通过这个前缀来区分,那么就是说jdbc是要的,而我们这里的属性只有url要怎么解决呢 ,只需要在配置中加上前缀变量prefix=jdbc
接下来要加上getXXX()方法,可以直接通过右击添加,还有一种办法就通过lombok
先要添加依赖
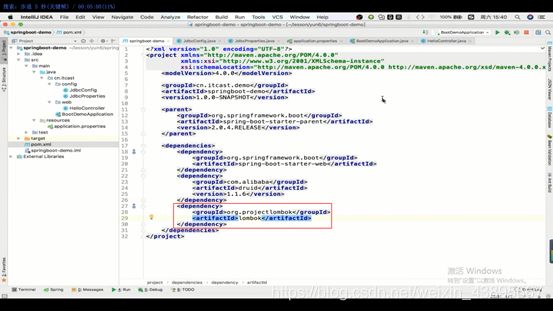
然后加上@Data注解,那么会实现再编译时就可以帮我们加上getXXX(),toString()等方法
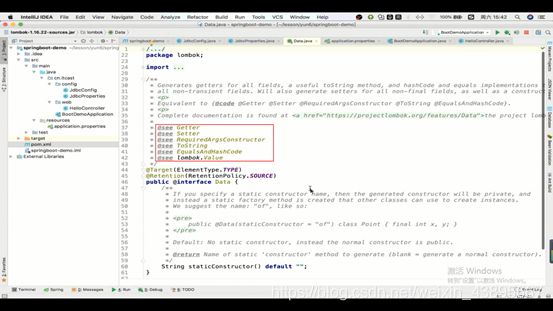
可以查看一下源代码,也就帮我们编写好了下面那些方法
那么就可以开始调用属性了,有两种方法
1.直接通过配置bean,然后调用属性(在JdbcProperties类上加上@Component,即传统的将这个类的对象放在Spring容器,然后在其他地方就可以注入)
2.通过在调用的类上注解@EnableConfigurationProperties(即使用我们之前注解过的@ConfigurationProperties类)然后指明是哪个类(JdbcProperties.class),然后在数据库对象里就可以直接调用这个配置类里的getXXX()方法(用我们之前调用lombok实现的getXXX()方法)
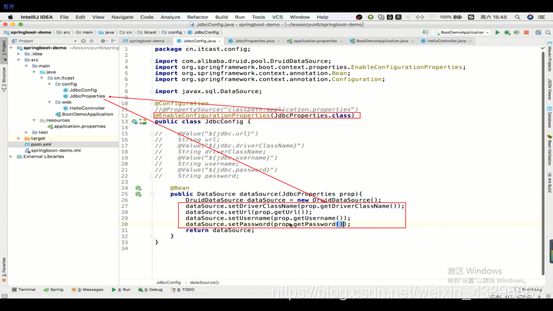
2.通过直接返回连接池的时候,Spring自动取寻找变量
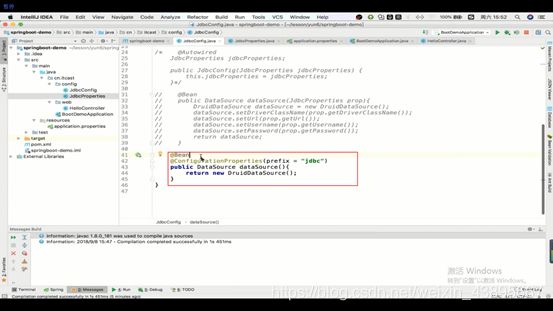
即在return连接池时,因为有@ConfigurationProperties,就去找Properties文件,然后根据设置的前缀以及连接池的每个属性一 一对应找到每个属性并调用连接池自己的set()方法赋值
那么上面介绍的两种方法有什么特点/区别?
1.通过创建一个JdbcProperties类作为配置类,这样可以让所要调用它的地方都可以调用,即可以多次使用,多次调用
2.直接返回的方式,一般就是一次调用的时候适用
解决了配置方式的问题,还有一个Properties配置文件的问题
实际上Properties配置文件有一些弊端:
1.数据存在冗余,比如jdbc,每个属性都有jdbc
2.数据类型单一,一般就是用String
所以我们一般更新成yaml(也称yml)配置文件,里面的语法稍有变化(=变成:)
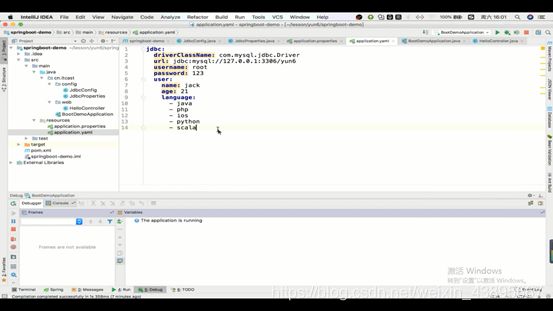
不仅实现了在同一个前缀下(jdbc)不会冗余,而且可以配置各种类型,如String(name),int(age),List(language)
那么在同时配置了yaml和properties,而且名字和前缀名都一样(就上上面这样),那么最后的配置属性就是取这两个配置文件的属性并集,重复的属性则是以properties的为准
那么配置到此结束
回到配置SpringBoot的启动器中,我们仅仅配置了SpringBoot的启动器,而之前所有的例如文件上传解析器,拦截器,监听器等都没有配置,是怎么实现的呢
我们可以看到特别的地方也就是注解和run()方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UXXZwrkA-1581855548090)(D:\有道云笔记\[email protected]\5dbc7f5246414c10aa7e32f0581f195b\clipboard.png)]
1.注解
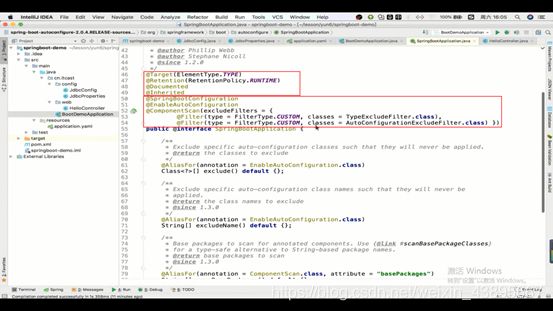
上面四个是原注解不用看,下面三个我们一个一个分析
1.@SpringBootConfiguration
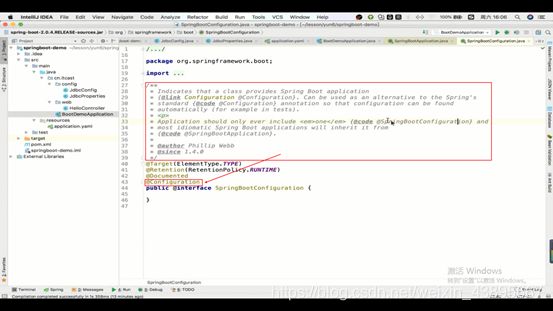
上面的注释解释了:当这个注解在里面又注解了@Configuration,那么相当于这个注解就是一个@Configuration,而且它还是SpringBoot标准的@Configuration注解
那么就可以使用@Bean注解(@Configuration类(配置类)就可以用)
2.@EnableAutoConfiguration
使用自动配置
启动自动配置的开关
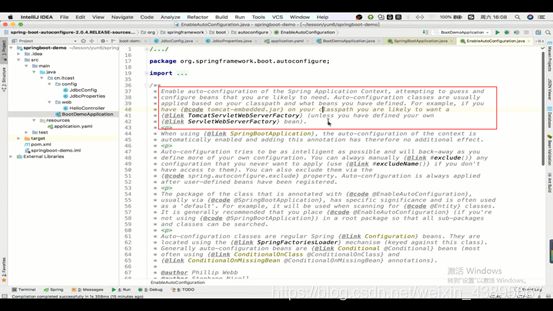
注释上解释的是:开启Spring应用的自动配置,猜测你可能需要的,自动配置类是通过你所定义的类路径或者你所定义的Bean,例如你添加了tomcat的jar包,那么就会猜测你可能想要的是TomcatServletWebFactory这个工厂并帮你配置好,总而言之就是你引入了什么依赖,那么他就会帮你配置好
3.@ConponentScan)
看名字我们就知道是用于扫描的,例如我们直接编写的Controller,为什么就直接生效了,一般是要添加扫描包的注解
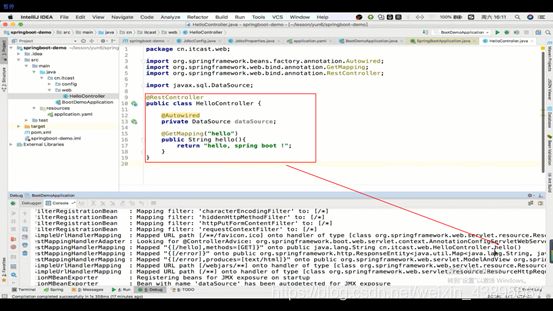
帮助Configuration配置扫描指令,等同于xml配置里的context:component-scan
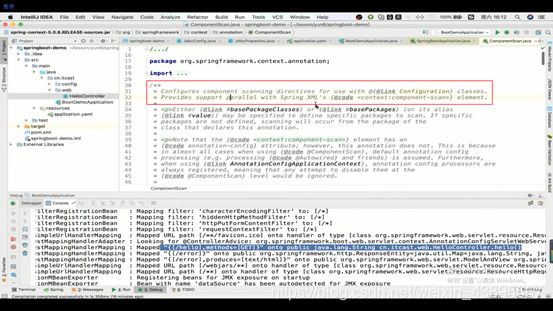
那么它下面有一个属性basePackages,用于做扫描的包的路径
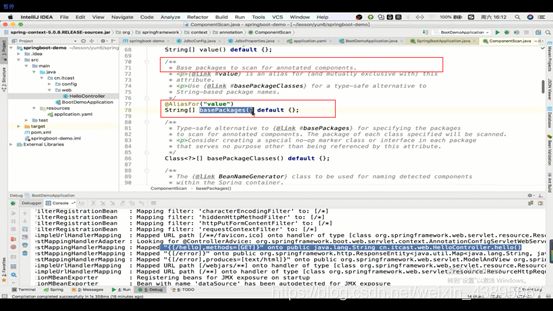
而且当你的配置里并没有指定这个basePackages时,那么就会添加默认的扫描路径,即配置类(有@configuration)的包的路径就是扫描路径,
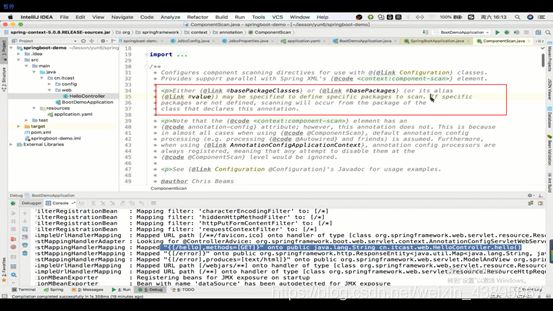
例如这个配置类就没有添加扫描路径,那么它的路径就是上一层,也就是可以扫描到同层的config和web目录下的类
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ippdZJx0-1581855548109)(D:\有道云笔记\lsh3824263@163.com\9c1501d927024f16b9729aa0456d6ac7\clipboard.png)]](http://img.e-com-net.com/image/info8/ff843d28cb5c4f16be67fb6acee3bed2.jpg)
原先的扫描方式有两个弊端(spring和springmvc分开来扫描)
1.可能存在重复扫描的问题
若Spring和SpringMVC都要用到mapper,就会重复扫描同一个包
2.可能存在父子容器的问题
比如Spring扫描的包和SpringMVC扫描的包里面的对象会发生交互就会产生难以调节的bug,不好解决
所以用这种统一扫描方式(统一扫描,不管是service层的,还是其他的如拦截器,过滤器等)比原先的扫描方式更好。
2.run()方法

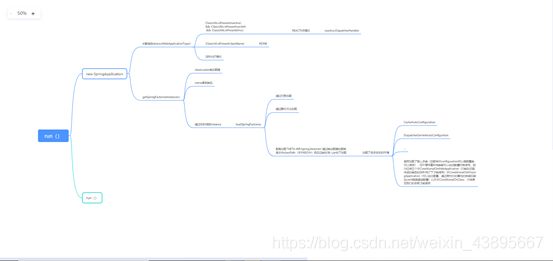
源码过程用脑图展示
SpringBoot的实践
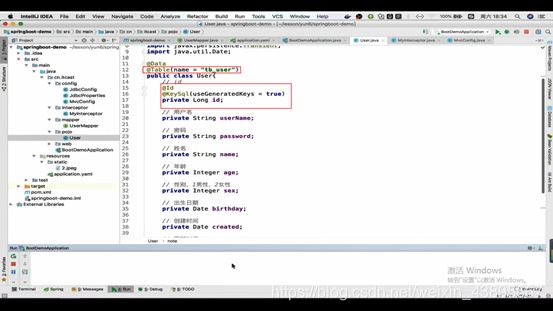
1.实体类
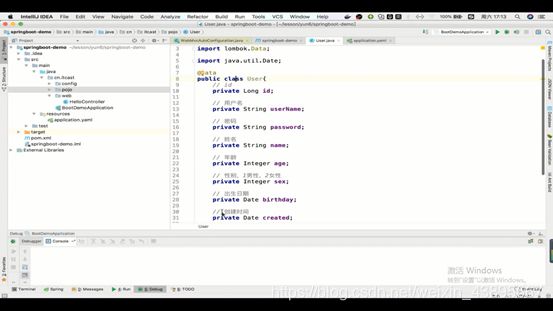
其get()等方法都交由@Data注解处理
2.整合SpringMVC
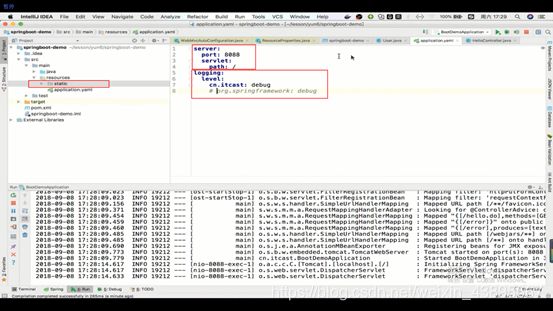
可通过application.yaml覆盖SpringBoot自动帮我们配置的一些关于SpringMVC的配置
例如端口号,访问路径,日志等级
其中日志等级:level是一个map类型,那么在yaml就可以以key:value的形式,左边key是包,右边value是字符串
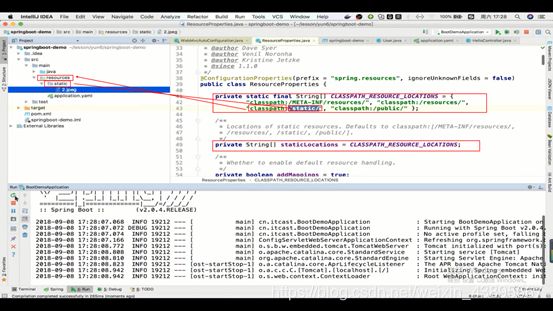
静态资源(虽然后端并不存储静态资源,是交由前端处理)
静态资源则SpringBoot配置的路径是下面这四种,而classpath就是resources包,所以我们在它的下一层创建一个包,将我们的静态资源丢进去,就可以访问到了
拦截器(拦截器里面的逻辑是由我们自己实现的,所以SpringBoot不能帮我们配置)
里面配置日志:通过日志工厂getLogger()方法获得,参数是获得日志的类,因为日志是以类为单位记录
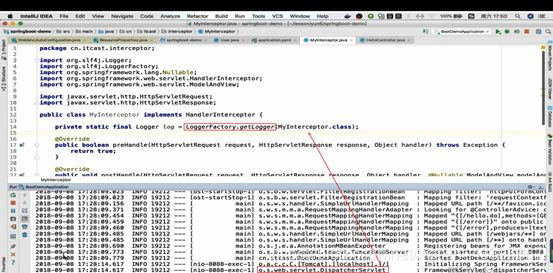
然而每次想要使用log都需要new过于麻烦,那么slf4j有个注解可以帮我们自动生成log,日志通过logger.debug完成
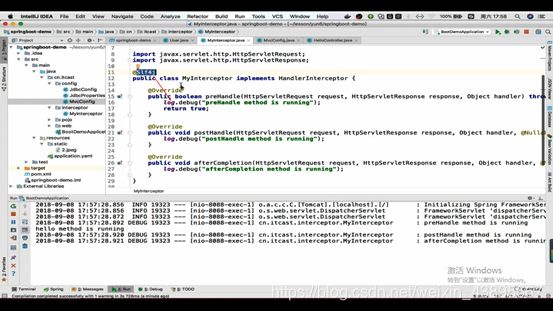
配置拦截器中还需要配置一个实现WebMvcConfigurer的接口(里面有添加拦截器等多功能的方法)的类(并且用@configuration注解,表示配置类)
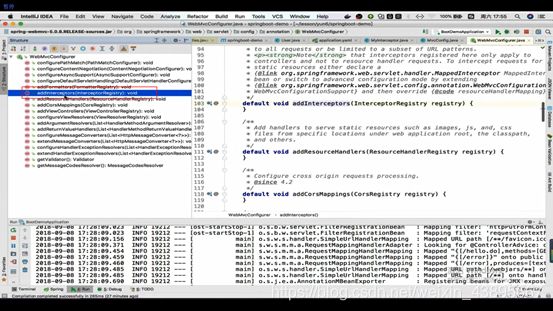
通过重写接口的方法,实现添加拦截器,参数直接通过new一个我们自己的拦截器就可以添加进程序中,并且配置拦截路径
3.整合JDBC
配置连接池
DBCP、C3P0、
Druid:速度和C3P0差不多,但又监听功能,可以把每条sql的总耗时,平均耗时都展示出来,用于排查效率低的sql进行优化(阿里巴巴的产品)
HikariCP(追光者):速度最快
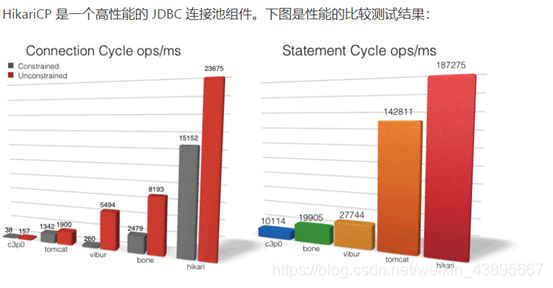
所以为了性能,我们选择使用HikariCp,而且SpringBoot默认就是配置HikariCP
接下来我们就要配置连接池的依赖,以及数据库连接驱动的依赖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pQaygnN1-1581855548136)(C:\Users\Lishier\AppData\Roaming\Typora\typora-user-images\image-20200215162040901.png)]](http://img.e-com-net.com/image/info8/6e26752c130544cc9475790f8336dbe9.jpg)
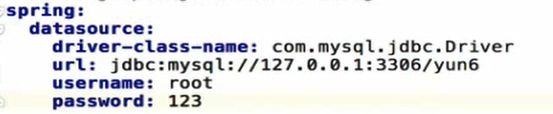
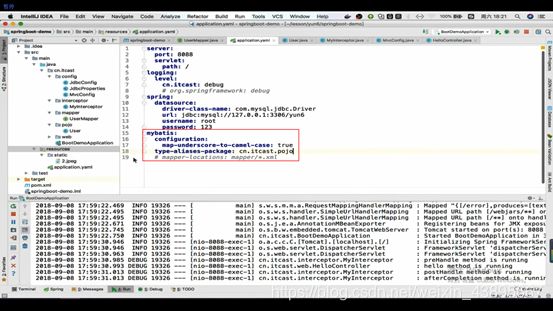
配置完了连接池,数据库驱动,那么就要配置数据库的四个属性(回到.yaml配置文件)
4.配置mybatis
由于SpringBoot并没有给mybatis写启动器,那么mybatis里面要配置的内容(如sqlSessionFactory,dataSource,configLocation,mapperLocation等就不会自动配置,要我们手动配置,那就很麻烦,而mybatis公司就自己写了个启动器,那么我们就要去导入这个启动器)
 那就开始配原来.xml配置的mybatis的属性
那就开始配原来.xml配置的mybatis的属性
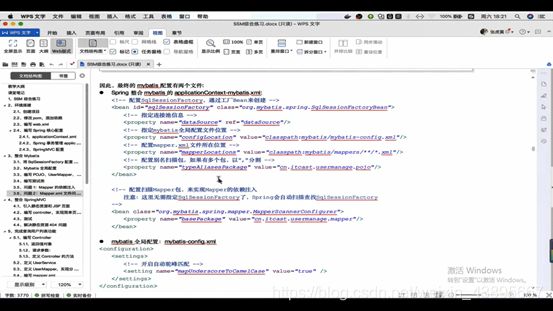
其中包括
sqlSessionFactory:这种导包的mybatis的启动器肯定帮我们配置号了
dataSource:同理,启动器配置了
configLocation:扫描mybatis.xml配置文件位置的,我们通过启动器自动配置,已经没有这个配置文件,所以也不用自己配(其中原本配置文件有配个属性叫mapUnderscoreToCamelCase(驼峰)我们也可以配置)
mapperLocation:扫描mapper.xml文件的地址,mapper.xml是由我们自己编写,地址自然也是,所以这个地址需要我们自己配置,但是这里的mapper.xml之前就是存放sql语句的,而这种存放sql语句的操作很繁琐且一般单表的sql操作几乎没得优化(性能固定),我们会让别人主动帮我们完成(通用mapper),所以如果我们只用单表sql操作,那么这个mapper.xml就不存在也就不需要配置它的地址属性了(留着之后讲)
typeAliasesPackage:别名扫描包,肯定要自己配置,而且有多个包可以用,隔开
MapperScannerConfigurer:mapper扫描器,扫描mapper的,但这里启动器没有这个属性,是用到@MapperScanner注解完成扫描
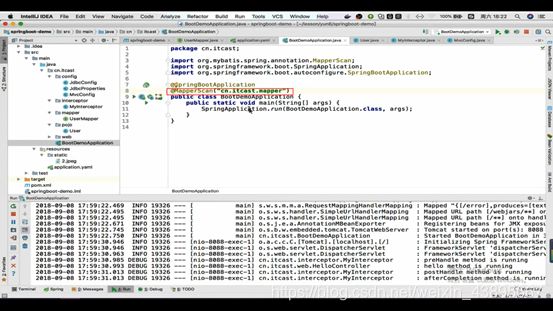
接到上面没讲的通用mapper:
[https://github.com/abel533/Mapper/wiki/1.3-spring-boot]:
上GitHub:搜索mapper

导入依赖
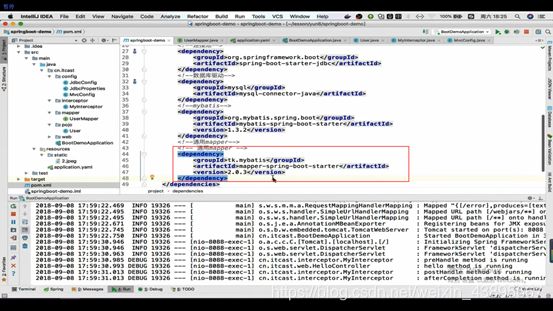
继承了这个类后就可以使用单表sql操作了
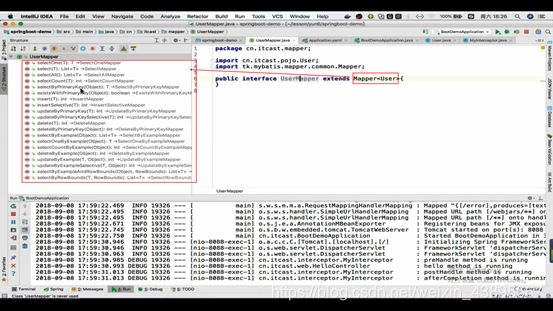
而且这有个注意事项:
当导入了这个通用mapper的依赖后,发现这个依赖里面已经有其他的依赖(如mybatis,jdbc,mybatis-springboot-start)那么我们就可以把上面的重复依赖(如mybatis和jdbc连接池的依赖)删去,因为它会帮我们配置好能用的版本,而且mybatis的峰值也会帮我们配置成true(那么之前配置的也可以注释掉)
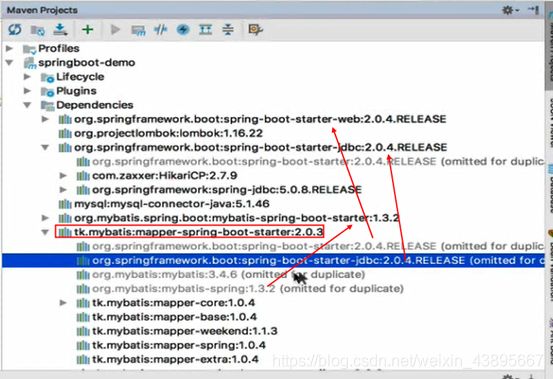
峰值不用再配置
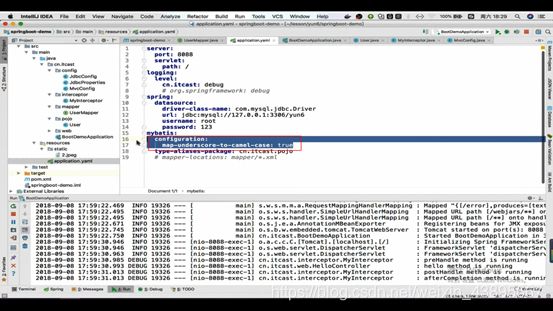
@MapperScan导入的包不用mybatis用通用mapper的
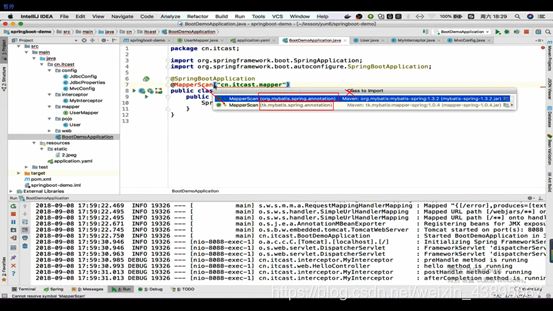
讲完任何配置通用mapper,接下来来使用通用mapper编写一个demo
首先以select x1x from x2x where x3x = x4x
x3x:是属性名,在对应的属性(pojo类上的属性)加上对应的属性名(数据库的列属性)
x2x:是表名,通过在持久层pojo类里加上@Table注释,就可以知道去哪个表查询
x1x,x4x方法调用时的参数
还有一个注意事项:pojo类里的属性不一定全是数据库里的属性,有一些并不是那么在一些(select *)操作上就不用显示出来,那么就在该属性上加上@Transient
导入测试(也是要用Springboot提供的test的启动器)依赖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-enJpAR1N-1581855548161)(C:\Users\Lishier\AppData\Roaming\Typora\typora-user-images\image-20200215205126064.png)]](http://img.e-com-net.com/image/info8/f5e39346da874f758bcc6a9880e20db1.jpg)
右键点击UserMapper接口->点击生成test
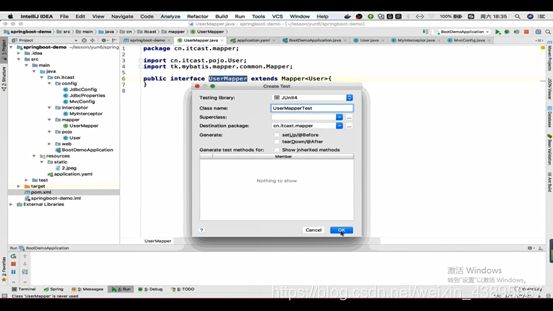
编写测试类
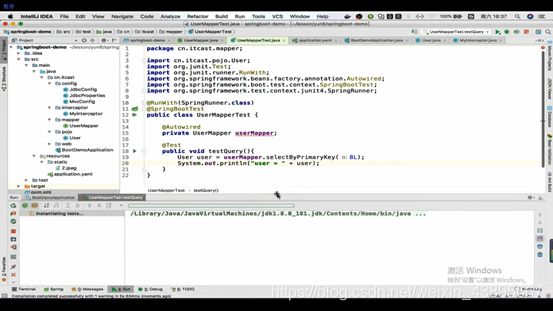
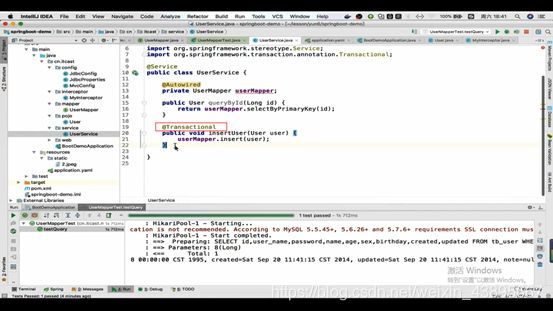
5.配置Service
配置service非常的简单,当我们引入了jdbc启动器的时候,事务就已经配置好了,只需要在需要添加事务的方法上加上@Transactional即可
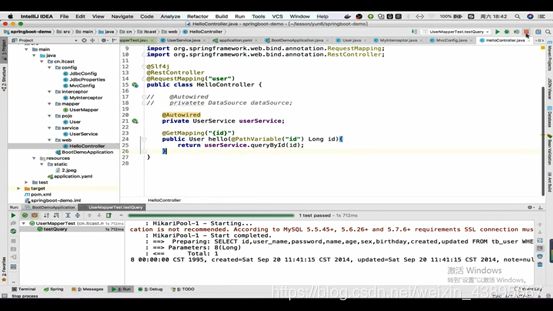
6.尝试ssm运行一遍
改一下Controller层,将UserService注入,然后通过url接收({id}),再把对应的id传到方法内,调用queryByid()方法
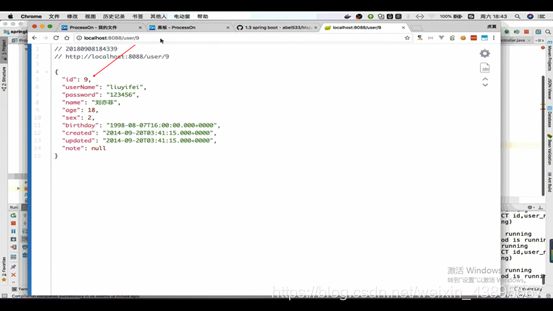
能够成功的访问查询queryById()方法
由于是用typora编辑,排版还不是很会,仅当笔记记录,请见谅,如果有好的方法也可以分享给我,谢谢