linux内核分析及应用 -- 中断机制
我们编写的程序在运行的时候,并不会一直占据着 CPU 资源,比如你需要和外部设备做交互(读写磁盘数据、读写网络接口等),那么你就要主动放弃 CPU,当外部设备数据就绪后,就会通过中断机制来通知 CPU 切换回你刚才运行程序的上下文继续往下执行。
另外,即使是 CPU 密集型运算的程序,系统也并不仅仅给一个进程来运行。为了对系统中所有的进程公平起见,一般会通过时钟中断的机制,定期打断当前在 CPU 中的进程,以便切换给其他进程以得到公平运行的机会。
可以这样说,中断响应的机制对于现代操作系统来讲尤为重要,该机制解放了 CPU,对提升系统的利用率起到了非常大的作用。
假如没有中断机制,那么所有条件是否满足的判断都需要 CPU 进行轮询忙等待,这样就会增加系统的开销,浪费 CPU 的资源。
本章通过以下几个问题来分析操作系统的中断机制:
1)为什么要引入中断机制,x86 系统的中断机制。
2)Linux 系统如何对中断机制进行封装和实现。
3)Linux 引入了软中断、tasklet、工作队列等机制是怎样的。
4)系统调用、时钟中断、信号处理机制等在 Linux 中是如何实现的。
4.1 x86 系统的中断机制
先举个例子来说明中断机制带来的好处。假如你的汽车出了问题,要去 4s 店维修,工作人员告诉你,今天就可以取车,但是什么时间点不确定。没有中断机制的情况下,你就什么事情都不能干,在 4S 店刷刷手机,在无聊中干等一天。有了中断机制,工作人员就会说,你现在可以出去干其他事情,等修好了会打电话通知你来取车;这样你就有可能去看一场电影,或者干点别的你想做的任何事情,直到电话响起后,你再确定何时去 4S 店取车。
操作系统中断机制的好处就是让 CPU 把某些需要轮询等待的空闲时间释放出来,化主动为被动,可以把释放出来的时间用于其他逻辑运算的工作,提升 CPU 的有效利用率。
我们平时工作接触最多的操作系统就是 x86 架构的系统了,所以先分析一下 x86 下的中断机制。
4.1.1 x86 中断架构
x86 中断架构如图4-1所示。当我们想通知 CPU 发生中断的时候,可以通过以下两种方式来进行:
int 指令,比如用户自己编写的软件,可以通过 int 指令来实现中断 CPU 的目的。
通过与 CPU 连接的相关芯片(例如 8259A)把外部中断的信号传递给 CPU,例如 8259A 芯片连接了磁盘或者键盘,当这些外部设备就绪,需要通知 CPU 响应的时候,就会发生外部中断。
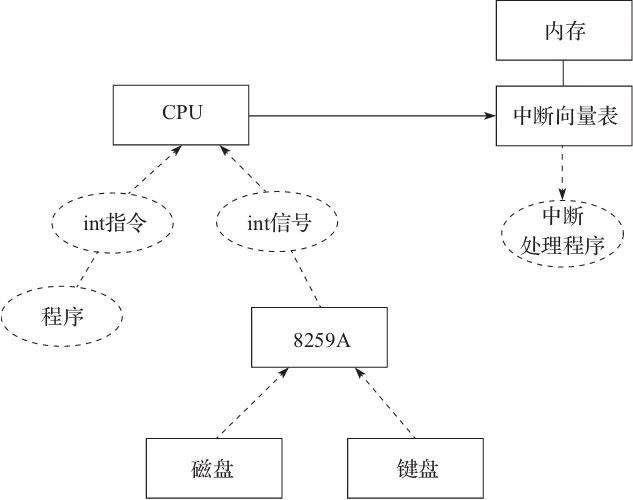
图4-1 x86 中断机制
中断信息注册在内存中的中断向量表中,通过中断向量可以找到相应中断处理的地址,当 CPU 响应相关中断指令或者信号后,就会执行中断处理程序。
4.1.2 x86 在保护模式下的中断
现在我们已经了解了 x86 硬件的中断机制和中断向量的原理。不过,在 x86 的保护模式中,CPU 并非直接访问内存中的中断向量表地址,为了安全,其访问的是中断门数据结构,门的数据也存放在内存中,类似于 GDT(全局描述表)或 IDT(中断描述表)的描述符。中断门的结构如图4-2所示。

图4-2 中断门结构
在中断门结构中,最核心的就是选择子和偏移量。BYTE 3 和 BYTE 2 组成了16位的段选择子,BYTE 7 和 BYTE 6 保存了偏移量的高16位,BYTE 1 和 BYTE 0 保存了偏移量的低16位,组合起来就是32位的段内偏移量。
另外代表属性的 BYTE 5 和 BYTE 4 两个字节中的 P、DPL、S、TYPE 等字段和3.2.2节中的 GDT 中的字段是一致的。
中断门结构中最重要的是保存了程序段的选择子和段内的偏移量,这样就可以找到相应的中断处理程序。门的机制就相当于一个关卡(Gate)做了一道安全检测和拦截。
在访问门描述符时要将描述符当作一个数据段来检查访问权限,要求指定门的选择子的 RPL≤门描述符 DPL,同时当前代码段 CPL≤门描述符 DPL,就如同访问数据段一样,要求访问数据段的程序的 CPL≤待访问的数据段的 DPL,同时选择子的 RPL≤待访问的数据段或堆栈段的 DPL。只有满足了以上条件,CPU 才会进一步从调用门描述符中读取目标代码段的选择子和地址偏移,进行下一步的操作。
要了解 RPL、DPL、CPL 等概念,需要了解 X86 的保护模式。X86 的保护模式核心就是提供特权等级概念,以便对代码和数据进行访问的时候进行保护和控制。特权级分为0,1,2,3四级,数字越小权限越高。
图4-3是特权级在操作系统中应用。
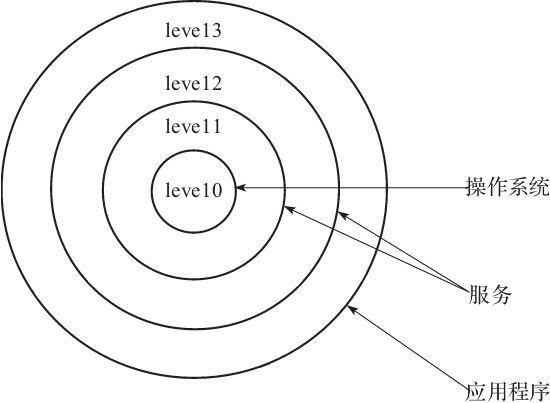
图4-3 特权等级
这些特权等级,通过三个符号来体现 CPL/RPL/DPL:
CPL(Current Privilege Level)是当前进程的权限级别,是当前正在执行的代码所在的段的特权级,存在于 CS 寄存器的低两位。(个人认为可以看成是段描述符未加载入 CS 前,该段的 DPL,加载入 CS 后就存入 CS 的低两位,所以叫 CPL,其值就等于原段 DPL 的值)。
RPL(Request Privilege Level)说明的是进程对段访问的请求权限,是对于段选择子而言的,每个段选择子有自己的 RPL,是进程对段访问的请求权限,有点像函数参数。而且 RPL 对每个段来说不是固定的,两次访问同一段时的 RPL 可以不同。RPL 可能会削弱 CPL 的作用,例如当前 CPL=0 的进程要访问一个数据段,把段选择符中的 RPL 设为3,这样虽然它对该段仍然只有特权为3的访问权限。
DPL(Descriptor Privilege Level)存储在段描述符中,规定访问该段的权限级别,每个段的 DPL 固定。当进程访问一个段时,需要进程特权级检查,一般要求 DPL>=max{CPL,RPL}。
4.2 Linux 对中断的支持和实现
为了更好地支持上层不同的业务场景,Linux 在硬件提供的中断机制之上进行了封装和扩展。下面通过图4-4来介绍 Linux 内核对中断机制的封装。
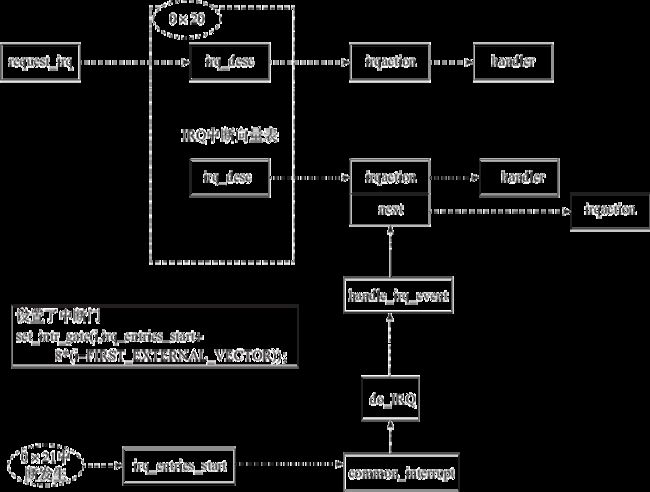
图4-4 Linux 内核中的中断机制
Linux 在启动阶段会通过 set_intr_gate 来设置中断门和中断向量。开发者可以通过 request_irq 来给相应的中断向量设置回调函数。当中断发生的时候,会触发通用中断程序 common_interrupt 并且调用 do_IRQ 来触发相应中断向量的回调函数。下面着重来分析 Linux 中断机制中最关键的三个部分。
4.2.1 初始化 IRQ 中断门
为什么 IRQ 中断可以被响应呢?因为在系统的初始化过程中调用了 init_IRQ,通过设置中断门初始化了中断向量(代码详见:/linux-4.15.8/arch/x86/kernel/irqinit.c):
void __init init_IRQ(void)
{
int i;
for (i = 0; i < nr_legacy_irqs(); i++)
per_cpu(vector_irq, 0)[ISA_IRQ_VECTOR(i)] = irq_to_desc(i);
x86_init.irqs.intr_init();
}
通过下面的 irqs 定义可以发现真正调用的是 native_init_IRQ 函数:
.irqs = {
.pre_vector_init = init_ISA_irqs,
.intr_init = native_init_IRQ,
.trap_init = x86_init_noop,
},
在 native_init_IRQ 函数中,通过 set_intr_gate 设置中断门并且初始化中断向量,从0x20(FIRST_EXTERNAL_VECTOR)开始到256(NR_VECTORS):
void __init native_init_IRQ(void)
{
int i;
…
for_each_clear_bit_from(i, used_vectors, first_system_vector) {
set_intr_gate(i, irq_entries_start +
8 * (i - FIRST_EXTERNAL_VECTOR));
}
…
}
4.2.2 中断响应流程
通过图4-3可以看到,当中断发生的时候,会触发中断处理函数,从 irq_entries_start 处开始:
.align 8
ENTRY(irq_entries_start)
vector=FIRST_EXTERNAL_VECTOR
.rept (FIRST_SYSTEM_VECTOR - FIRST_EXTERNAL_VECTOR)
pushl $(~vector+0x80)
vector=vector+1
jmp common_interrupt
.align 8
.endr
END(irq_entries_start)
上面函数的 .rept 这一行,会重复(FIRST_SYSTEM_VECTOR-FIRST_EXTERNAL_VECTOR)次,根据 native_init_IRQ 可以理解,当传入的中断号不同,则传入的 vector 也不同。
最终会通过 common_interrupt 调用 do_IRQ 函数。
do_IRQ 在获取中断向量通过 handle_irq->generic_handle_irq_desc 调用了 irq 所对应的 irq_desc 结构的 handle_irq:
static inline void generic_handle_irq_desc(struct irq_desc *desc)
{
desc->handle_irq(desc);
}
这些标准的回调函数都是 irq_flow_handler_t 类型:
typedef void (*irq_flow_handler_t)(unsigned int irq,
struct irq_desc *desc);
目前的通用中断子系统实现了以下这些标准流控回调函数,这些函数都定义在 kernel/irq/chip.c 中:
handle_simple_irq 用于简易流控处理。
handle_level_irq 用于电平触发中断的流控处理。
handle_edge_irq 用于边沿触发中断的流控处理。
handle_fasteoi_irq 用于需要响应 eoi 的中断控制器。
handle_percpu_irq 用于只在单一 CPU 响应的中断。
handle_nested_irq 用于处理使用线程的嵌套中断。
最终会执行用户注册的中断处理程序 action。以上几种回调函数,最终都调用了 handle_irq_event。
handle_irq_event 最终调用执行了 handle_irq_event_percpu 函数:
irqreturn_t handle_irq_event_percpu(struct irq_desc *desc)
{
irqreturn_t retval = IRQ_NONE;
unsigned int flags = 0, irq = desc->irq_data.irq;
struct irqaction *action = desc->action;
while (action) {
irqreturn_t res;
…
res = action->handler(irq, action->dev_id); // 执行中断的 action 注册的 handler
…
retval |= res;
action = action->next; // 获取下一个 action 事件
}
…
return retval;
}
handle_irq_event_percpu 将中断向量 desc 注册的 action 链表中的 handler 挨个执行一遍。
4.2.3 中断回调 handler 注册过程
在掌握了 Linux 的中断发生和响应处理机制后,我们发现,中断发生的时候处理最终回调的是在中断向量中注册的 action 中的 handler。那么 handler 是如何注册上去的呢?
内核提供了 request_irq 函数进行注册自定义 handler 的功能:
request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,
const char *name, void *dev)
其调用链为 request_irq->request_threaded_irq->__setup_irq,然后把构建出来的 action 插入到中断向量的 action 链表中:
…
do {
thread_mask |= old->thread_mask;
old_ptr = &old->next;
old = *old_ptr;
} while (old);
shared = 1;
}
…
4.3 Linux 加速中断处理的机制
在中断发生之后,假如中断处理的回调函数需要很长的时间,那么会对系统性能造成很大的影响,比如中断频繁发生的情况下,后续的中断就会得不到响应。Linux 为了解决这个问题提供了几个异步工具来加快中断处理执行的过程,比如软中断、tasklet、工作队列等。
4.3.1 软中断
软中断可以在不触发硬件中断机制的情况下,进行中断业务流程的模拟实现,其原理是通过后台异步线程+队列的方式来模拟异步事件回调的机制。
软中断的注册函数为:
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
软中断的资源是有限的,内核目前只实现了10种类型的软中断,它们是:
enum
{
HI_SOFTIRQ=0,
TIMER_SOFTIRQ,
NET_TX_SOFTIRQ,
NET_RX_SOFTIRQ,
BLOCK_SOFTIRQ,
IRQ_POLL_SOFTIRQ,
TASKLET_SOFTIRQ,
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ, // 没有使用,但有时候可以有一些工具依赖它
RCU_SOFTIRQ, // 最好的 RCU 总是放在最后的软中断
NR_SOFTIRQS
};
注意
内核的开发者们不建议我们擅自增加软中断的数量,如果需要新的软中断,尽可能把它们实现为基于软中断的 tasklet 形式。
下面通过图4-5来说明软中断的响应流程,在软中断实现中,每个 CPU 都维护了一个后台响应的进程 ksoftirqd:
static __init int spawn_ksoftirqd(void)
{
register_cpu_notifier(&cpu_nfb);
…
return 0;
}
early_initcall(spawn_ksoftirqd);
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn= run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
DECLARE_PER_CPU(struct task_struct *, ksoftirqd);
static inline struct task_struct *this_cpu_ksoftirqd(void)
{
return this_cpu_read(ksoftirqd);
}

图4-5 软中断响应流程
通过系统初始化时候的守护线程最终调用了 run_ksoftirqd,其核心实现为 __do_softirq()函数:
static void run_ksoftirqd(unsigned int cpu)
{
..
__do_softirq();
…
}
asmlinkage __visible void __do_softirq(void)
{
unsigned long end = jiffies + MAX_SOFTIRQ_TIME;
unsigned long old_flags = current->flags;
int max_restart = MAX_SOFTIRQ_RESTART; // 启动 ksoftirqd 之前,最大的处理 softirq 的次数,经验值
struct softirq_action *h;
bool in_hardirq;
__u32 pending;
int softirq_bit;
…
// 取得当前被挂起的 softirq,同时这里也解释了为什么 Linux 内核最多支持32个 softirq,因为 pending 只有32位
pending = local_softirq_pending();
account_irq_enter_time(current);
__local_bh_disable_ip(_RET_IP_, SOFTIRQ_OFFSET);
in_hardirq = lockdep_softirq_start();
restart:
set_softirq_pending(0); // 获取 pending 的 softirq 之后,清空所有 pending 的 softirq 标志
local_irq_enable();
h = softirq_vec;
while ((softirq_bit = ffs(pending))) { // 从最低位开始,循环右移逐位处理 pending 的 softirq
unsigned int vec_nr;
int prev_count;
h += softirq_bit - 1;
vec_nr = h - softirq_vec;
prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(vec_nr);
trace_softirq_entry(vec_nr);
h->action(h); // 执行 softirq 的处理函数
…
}
h++;
pending >>= softirq_bit; // 循环右移
}
..
local_irq_disable();
pending = local_softirq_pending();
if (pending) {
if (time_before(jiffies, end) && !need_resched() &&
--max_restart) // 启动 ksoftirqd 的阈值
goto restart;
wakeup_softirqd(); // 启动 ksoftirqd 去处理 softirq,此时说明 pending 的 softirq 比较多,比较频繁,上面的处理过程中,又不断有 softirq 被 pending
}
…
}
在 __do_softirq 执行过程中只要在 pending 中的软中断标志位被设置了,那么就会调用该中断的 action 函数。
最后,软中断处理函数注册后,还需要将该软中断激活才能被执行,激活操作是通过 raise_softirq 函数来实现,它调用了 raise_softirq_irqoff 函数:
inline void raise_softirq_irqoff(unsigned int nr)
{
__raise_softirq_irqoff(nr);
if (!in_interrupt())
// 假如不在中断当中,那么我们尽快唤醒 softirqd 进行下半部的处理
wakeup_softirqd();
}
我们着重关注一下__raise_softirq_irqoff(nr):
void __raise_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
#define or_softirq_pending(x) (local_softirq_pending() |= (x))
__raise_softirq_irqoff 把我们的中断号左移之后进行异或操作合并到 pending 标志位中,便于 softirqd 线程进行处理。
4.3.2 tasklet
在分析软中断的时候,我们已经了解到内核开发者平时不建议我们使用软中断,最好使用 tasklet 机制,因为其本身也是软中断的一部分。
软中断专门实现了 TASKLET_SOFTIRQ,其 action 为:
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable();
list = __this_cpu_read(tasklet_vec.head);
__this_cpu_write(tasklet_vec.head, NULL);
__this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head));
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
if (!test_and_clear_bit(TASKLET_STATE_SCHED,
&t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
local_irq_disable();
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
从 tasklet_action 实现可以发现,只要 tasklet_vec 向量队列中有 tasklet 存在,那么就拿出来执行 func 函数。
tasklet 的结构如下:
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
并且可以通过下面的宏来定义:
#define DECLARE_TASKLET(name, func, data)
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
我们可以通过调用 tasklet_schedule 把 tasklet 提交到 tasklet 队列中:
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
其实执行的是 __tasklet_schedule 函数:
void __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__this_cpu_read(tasklet_vec.tail) = t;
__this_cpu_write(tasklet_vec.tail, &(t->next));
raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_restore(flags);
}
可以发现 __tasklet_schedule 把 tasklet 放到了 tasklet 向量队列的队尾,并且最后通知 softirqd 线程处理 tasklet 信号。
因为 tasklet 机制就是基于 TASKLET_SOFTIRQ 的软中断来实现的,所以只要掌握了软中断机制,tasklet 也就很好理解了。
4.3.3 工作队列
工作队列类似于应用层代码中线程池概念,我们把 work 提交到队列,然后由相关的线程从队列中提取 work 并且执行,其原理如图4-6所示。
当我们创建一个工作队列后(wq),它为每个 CPU 都分配了一个工作队列池(pool_workqueue 结构的 pool),同时会创建一个工作线程 work_thread 和该池中的 worklist 挂钩,来处理提交上来的 work。
可以通过 alloc_workqueue 宏来分配一个工作队列:
#define alloc_workqueue(fmt, flags, max_active, args...)
__alloc_workqueue_key((fmt), (flags), (max_active),
NULL, NULL, ##args)
其参数如下:
name 是 wq 的名称,并且会被当作相应救援线程的名称。
flag 和 max_active 用来控制到底有多少工作项被分配了执行资源,被调度和执行。
Flag 的几种类型说明:
WQ_UNBOUND:unbound 队列中的工作项会被相应的工作者线程池处理,这些线程池管理的工作者不会和任何制定的 CPU 绑定。这样的话,该队列的行为就相当于是提供了一个简单的执行上下文,而不会做并发管理。未绑定的线程池只要有可能就会试图启动工作项的执行。未绑定的队列牺牲了 CPU 的相关性,但是有以下用处。
WQ_FREEZABLE:冻结队列因为参与了系统的挂起操作流程,在该队列上的工作项会被排出(drained),直到被解冻之前都不会执行新的工作项。
WQ_MEM_RECLAIM:所有有可能运行在内存回收流程中的工作队列都需要设置该标记。这样能够确保即使在内存压力比较大的情况下都能有至少一个执行上下文能够运行。
WQ_HIGHPRI:highpri 队列中的工作项会由指定的 CPU 上的工作者线程池来处理。highpri 工作者线程池中的线程具有较高的 nice 值(用 top 或 ps 查看的进程 %nice 指标)。
WQ_CPU_INTENSIVE:CPU 密集型工作队列中的工作项并不会对并发级别产生贡献。换句话说,可以运行的 CPU 密集型工作项不会阻止相同工作者线程池上的工作项的运行。对于绑定的并且希望独占 CPU 周期的工作项,这个 flag 是有用的,因为它们的运行可以被系统进程调度程序调节。虽然 CPU 密集型的工作项不对并发级别做出贡献,但是它们的执行仍然会被并发管理所调节,因为可以运行的那些非 CPU 密集型工作项可以延迟 CPU 密集型工作项的运行。这个标记对于 unbound 工作队列没有什么意义。

图4-6 工作队列原理示意图
从 alloc_workqueue 宏代码发现创建工作队列最终调用了 __alloc_workqueue_key 方法:
struct workqueue_struct *__alloc_workqueue_key(const char *fmt,
unsigned int flags,
int max_active,
struct lock_class_key *key,
const char *lock_name, ...)
{
size_t tbl_size = 0;
va_list args;
struct workqueue_struct *wq;
struct pool_workqueue *pwq;
…
if (flags & WQ_UNBOUND)
tbl_size = nr_node_ids * sizeof(wq->numa_pwq_tbl[0]); // 等待队列的结构体空间大小,一
// 共 nr_node_ids 个
wq = kzalloc(sizeof(*wq) + tbl_size, GFP_KERNEL); // 为 workqueue 申请内存空间
if (!wq)
return NULL;
if (flags & WQ_UNBOUND) {
wq->unbound_attrs = alloc_workqueue_attrs(GFP_KERNEL);
if (!wq->unbound_attrs)
goto err_free_wq;
}
va_start(args, lock_name);
vsnprintf(wq->name, sizeof(wq->name), fmt, args); // 格式化工作队列的 name
va_end(args);
max_active = max_active ?: WQ_DFL_ACTIVE;
max_active = wq_clamp_max_active(max_active, flags, wq->name);
// init wq 下面操作初始化工作队列中的列表
wq->flags = flags;
wq->saved_max_active = max_active;
mutex_init(&wq->mutex);
atomic_set(&wq->nr_pwqs_to_flush, 0);
INIT_LIST_HEAD(&wq->pwqs);
INIT_LIST_HEAD(&wq->flusher_queue);
INIT_LIST_HEAD(&wq->flusher_overflow);
INIT_LIST_HEAD(&wq->maydays);
lockdep_init_map(&wq->lockdep_map, lock_name, key, 0);
INIT_LIST_HEAD(&wq->list);
if (alloc_and_link_pwqs(wq) < 0)
goto err_free_wq;
if (flags & WQ_MEM_RECLAIM) { // WQ_MEM_RECLAIM 场景,在内存紧张的时候,分配一个救援线程来处理 work
struct worker *rescuer;
rescuer = alloc_worker(NUMA_NO_NODE);
if (!rescuer)
goto err_destroy;
rescuer->rescue_wq = wq;
rescuer->task = kthread_create(rescuer_thread, rescuer, "%s",
wq->name);
if (IS_ERR(rescuer->task)) {
kfree(rescuer);
goto err_destroy;
}
wq->rescuer = rescuer;
kthread_bind_mask(rescuer->task, cpu_possible_mask);
wake_up_process(rescuer->task);
}
…
mutex_lock(&wq_pool_mutex);
mutex_lock(&wq->mutex);
for_each_pwq(pwq, wq)
pwq_adjust_max_active(pwq); // 遍历调整每个 pwq 的 max_active 大小
mutex_unlock(&wq->mutex);
list_add_tail_rcu(&wq->list, &workqueues);
mutex_unlock(&wq_pool_mutex);
return wq;
…
}
上面的代码主要初始化了 workqueue 的结构体,申请内存空间,并且初始化 pool_work-queue 的 max_active,假如是 WQ_MEM_RECLAIM 场景会创建一个救援线程。
接着我们分析任务的提交,先来看提交给指定 CPU 的 workqueue 队列,任务会通过 queue_work_on 函数提交,在任务提交后,都会执行 __queue_work 方法:
static void __queue_work(int cpu, struct workqueue_struct *wq,
struct work_struct *work)
{
struct pool_workqueue *pwq;
struct worker_pool *last_pool;
struct list_head *worklist;
unsigned int work_flags;
unsigned int req_cpu = cpu;
…
retry:
if (req_cpu == WORK_CPU_UNBOUND) // 在不需要绑定 CPU 的场景下,找一个未被 work 绑定的 CPU
cpu = wq_select_unbound_cpu(raw_smp_processor_id());
// 除非 work 在其他地方执行,否则使用 pwq
if (!(wq->flags & WQ_UNBOUND))
pwq = per_cpu_ptr(wq->cpu_pwqs, cpu);
else
pwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));
// 假如该 work 之前已经在其他的 pool 中了,那么会在那边继续运行,pool 保证不能重入
last_pool = get_work_pool(work);
if (last_pool && last_pool != pwq->pool) {
struct worker *worker;
spin_lock(&last_pool->lock);
worker = find_worker_executing_work(last_pool, work);
if (worker && worker->current_pwq->wq == wq) {
pwq = worker->current_pwq;
…
insert_work(pwq, work, worklist, work_flags); // 最后把 work 插入到工作队列中
spin_unlock(&pwq->pool->lock);
}
最后我们开每个 pool 都会创建一个 work_thread 来进行后台队列处理:
static struct worker *create_worker(struct worker_pool *pool)
{
struct worker *worker = NULL;
int id = -1;
char id_buf[16];
…
worker = alloc_worker(pool->node); // 从内存中分配 work 空间
…
worker->pool = pool;
worker->id = id;
…
worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf); // 创建一个 work 线程
…
set_user_nice(worker->task, pool->attrs->nice);
kthread_bind_mask(worker->task, pool->attrs->cpumask);
worker_attach_to_pool(worker, pool); // 把 worker 挂到 pool 队列中
spin_lock_irq(&pool->lock);
worker->pool->nr_workers++;
worker_enter_idle(worker);
wake_up_process(worker->task); // 唤醒新创建的 work 线程
spin_unlock_irq(&pool->lock);
return worker;
…
}
create_worker 创建的内核进程会在后台一直工作,处理提交的 worker。
4.4 系统调用
系统调用(syscall)是 Linux 系统中非常重要的概念,操作系统的核心功能,如进程、内存、I/O、文件系统等,都是以系统调用的方式提供给用户态程序的。常见的 Linux 系统调用分类可以参考:https://www.ibm.com/developerworks/cn/linux/kernel/syscall/part1/appendix.html。
系统调用的实现方式也和中断机制有关,在前面介绍 trap_init 方法的时候,其中有一行代码:
set_system_trap_gate(IA32_SYSCALL_VECTOR, entry_INT80_32);
该行注册了系统调用的中断向量:
#define IA32_SYSCALL_VECTOR 0x80
可以发现系统调用的中断向量号为0x80,我们接着看中断处理函数的实现:
ENTRY(entry_INT80_32)
ASM_CLAC
pushl %eax // pt_regs->orig_ax 把系统调用号保存到 pt_regs->org_ax 中
SAVE_ALL pt_regs_ax=$-ENOSYS // 在中断发生前夕,要把所有相关寄存器的内容都保存在堆栈中,这是通过 SAVE_ALL 宏完成的
movl %esp, %eax // 把 esp 栈顶放入到 eax 中,因为 eax 一般都是作为函数调用参数的
call do_syscall_32_irqs_on
在32位系统中,最终调用了 do_syscall_32_irqs_on 函数:
__always_inline void do_syscall_32_irqs_on(struct pt_regs *regs)
{
struct thread_info *ti = pt_regs_to_thread_info(regs);
unsigned int nr = (unsigned int)regs->orig_ax; // 获取系统调用号
…
if (likely(nr < IA32_NR_syscalls)) {
regs->ax = ia32_sys_call_table[nr]( // 执行系统调用的过程
(unsigned int)regs->bx, (unsigned int)regs->cx,
(unsigned int)regs->dx, (unsigned int)regs->si,
(unsigned int)regs->di, (unsigned int)regs->bp);
}
…
}
该函数通过 nr 系统调用号找到了系统调用表中的响应系统调用函数,并且压入 regs 栈中的数据,然后执行以下代码:
__visible const sys_call_ptr_t ia32_sys_call_table[__NR_syscall_compat_max+1] = {
[0 ... __NR_syscall_compat_max] = &sys_ni_syscall,
#include
};
其中 sys_call_table 数组的初始化使用 GCC 的扩展语法,语句[0...__NR_syscall_max]=&sys_ni_syscall 将数组内容全部初始化为未实现版本,然后包含 asm/syscalls_32.h 当中逐项初始化的内容进行初始化。
asm/syscalls_32.h 为编译期间生成的一个头文件,该内容由 /include/uapi/asm-generic/unistd.h 等头文件共同生成,其内容如下:
#include
…
#define __NR3264_lseek 62
__SC_3264(__NR3264_lseek, sys_llseek, sys_lseek)
#define __NR_read 63
__SYSCALL(__NR_read, sys_read)
#define __NR_write 64
__SYSCALL(__NR_write, sys_write)
#define __NR_readv 65
__SC_COMP(__NR_readv, sys_readv, compat_sys_readv)
#define __NR_writev 66
__SC_COMP(__NR_writev, sys_writev, compat_sys_writev)
…
#endif
最后总结系统调用机制如图4-7所示,用户态程序通过0x80号中断进行系统调用,具体调用哪个系统调用函数由 eax 中的参数决定,然后根据系统调用号查找 sys_call_table 中的具体函数,并且嵌入内核,执行该函数调用。
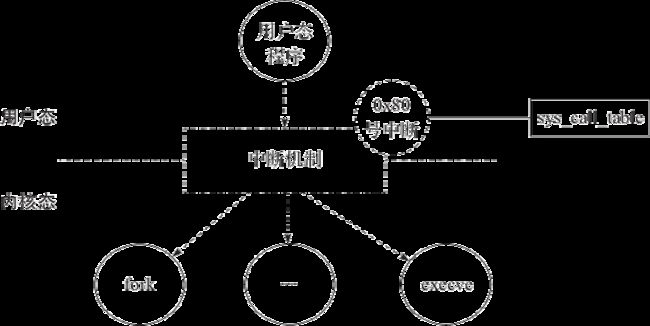
图4-7 系统调用机制
4.5 时钟中断
时钟中断对操作系统来讲是个很重要的概念,特别是像 Linux 这样的分时操作系统,CPU 不能被某几个进程独占,所以需要通过对时间片的划分进行切换(参见1.3.2节)。所以,时钟中断是进程实现被动切换的机制。
要产生时钟中断,必须通过硬件来完成,一般情况下,CPU 都会通过中断控制器连接 8259A 这样的芯片,来产生频率恒定的时钟中断。
跟系统调用一样,时钟中断也是在系统初始化的时候进行初始化的:
main(){
…
time_init();
…
if (late_time_init)
late_time_init();
}
void __init time_init(void)
{
late_time_init = x86_late_time_init;
}
static __init void x86_late_time_init(void)
{
x86_init.timers.timer_init();
tsc_init();// 初始化时钟频率
}
在上面代码中我们发现时钟中断初始化最终调用的方法为:
x86_init.timers.timer_init()和tsc_init()
tsc_init()是用来初始化硬件相关的时钟频率,我们不再展开,这里主要来分析一下 x86_init.timers.timer_init()
.timers = {
.setup_percpu_clockev = setup_boot_APIC_clock,
.timer_init = hpet_time_init,
.wallclock_init = x86_init_noop,
},
在 x86_init 中 timer 的 timer_init 方法为 hpet_time_init,其调用了 setup_default_timer_irq:
void __init setup_default_timer_irq(void)
{
if (!nr_legacy_irqs())
return;
setup_irq(0, &irq0);
}
最后发现时钟中断的注册为 IRQ 中断0,irqaction 为 irq0:
static struct irqaction irq0 = {
.handler = timer_interrupt,
.flags = IRQF_NOBALANCING | IRQF_IRQPOLL | IRQF_TIMER,
.name = "timer"
};
从上面结构体定义发现时钟中断函数为 timer_interrupt:
static irqreturn_t timer_interrupt(int irq, void *dev_id)
{
global_clock_event->event_handler(global_clock_event);
return IRQ_HANDLED;
}
至于其具体的 event_handler 的实现,就不在这里阐述了,读者有兴趣可以自行研究源代码。
4.6 信号处理机制
在 Linux 中,有一种非常常用的机制,用于通知进程触发响应的事件,这就是信号(signal)处理机制。
Linux 把它包装为系统调用给用户态程序进行使用,信号回调注册可以通过以下两个系统调用来完成。
1)sigaction 系统调用:
COMPAT_SYSCALL_DEFINE3(sigaction, int, sig,
const struct compat_old_sigaction __user *, act,
struct compat_old_sigaction __user *, oact)
{
struct k_sigaction new_ka, old_ka;
int ret;
…
ret = do_sigaction(sig, act ? &new_ka : NULL, oact ? &old_ka : NULL);
…
return ret;
}
2)signal 系统调用:
SYSCALL_DEFINE2(signal, int, sig, __sighandler_t, handler)
{
struct k_sigaction new_sa, old_sa;
int ret;
new_sa.sa.sa_handler = handler;
new_sa.sa.sa_flags = SA_ONESHOT | SA_NOMASK;
sigemptyset(&new_sa.sa.sa_mask);
ret = do_sigaction(sig, &new_sa, &old_sa);
return ret ? ret : (unsigned long)old_sa.sa.sa_handler;
}
不管是 signal 还是 sigaction,最终都调用了 do_sigaction 方法,最终返回旧的 action 的 handler:
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
struct task_struct *p = current, *t;
struct k_sigaction *k;
sigset_t mask;
if (!valid_signal(sig) || sig < 1 || (act && sig_kernel_only(sig)))
return -EINVAL;
k = &p->sighand->action[sig-1];
spin_lock_irq(&p->sighand->siglock);
if (oact)
*oact = *k; // 保存旧的 action
if (act) {
sigdelsetmask(&act->sa.sa_mask,
sigmask(SIGKILL) | sigmask(SIGSTOP));
*k = *act; // 设置新的 action
// 对两种 handler 的特殊处理,忽略 SIG_IGN 和 SIG_DFL 信号
if (sig_handler_ignored(sig_handler(p, sig), sig)) {
sigemptyset(&mask);
sigaddset(&mask, sig);
flush_sigqueue_mask(&mask, &p->signal->shared_pending);
for_each_thread(p, t)
flush_sigqueue_mask(&mask, &t->pending);
}
}
spin_unlock_irq(&p->sighand->siglock);
return 0;
}
do_sigaction 的实现很简单,先保存旧的 action,用于系统调用返回,然后设置新的 action。
收到信号的进程对各种信号有不同的处理方法,可以分为三类:
类似于中断的处理程序,对于需要处理的信号,进程可以指定处理函数,由该函数来处理。
忽略某个信号,对该信号不做任何处理,就象未发生过一样。
对该信号的处理保留系统的默认值,这种默认操作,对大部分信号的默认操作是使得进程终止。进程通过系统调用 signal 来指定进程对某个信号的处理行为。
系统的默认行为如下所示,signal 不同,action 的分配也不同:
* +--------------------+------------------+
* | POSIX signal | default action |
* +--------------------+------------------+
* | SIGHUP | terminate |
* | SIGINT | terminate |
* | SIGQUIT | coredump |
* | SIGILL | coredump |
* | SIGTRAP | coredump |
* | SIGABRT/SIGIOT | coredump |
* | SIGBUS | coredump |
* | SIGFPE | coredump |
* | SIGKILL | terminate(+) |
* | SIGUSR1 | terminate |
* | SIGSEGV | coredump |
* | SIGUSR2 | terminate |
* | SIGPIPE | terminate |
* | SIGALRM | terminate |
* | SIGTERM | terminate |
* | SIGCHLD | ignore |
* | SIGCONT | ignore(*) |
* | SIGSTOP | stop(*)(+) |
* | SIGTSTP | stop(*) |
* | SIGTTIN | stop(*) |
* | SIGTTOU | stop(*) |
* | SIGURG | ignore |
* | SIGXCPU | coredump |
* | SIGXFSZ | coredump |
* | SIGVTALRM | terminate |
* | SIGPROF | terminate |
* | SIGPOLL/SIGIO | terminate |
* | SIGSYS/SIGUNUSED | coredump |
* | SIGSTKFLT | terminate |
* | SIGWINCH | ignore |
* | SIGPWR | terminate |
* | SIGRTMIN-SIGRTMAX | terminate |
* +--------------------+------------------+
* | non-POSIX signal | default action |
* +--------------------+------------------+
* | SIGEMT | coredump |
* +--------------------+------------------+
既然已经可以针对相应信号进行注册 action,那么当信号发生的时候,如何来响应信号呢?
Linux 是通过在进程切换的时候,作为钩子点进行统一处理的。
每次进程调度切换之后,都会执行 ret_from_work 函数:
ENTRY(ret_from_fork)
pushl %eax
call schedule_tail
GET_THREAD_INFO(%ebp)
popl %eax
pushl $0x0202 // 重置内核 eflags
popfl
// 当我们执行完 fork,我们同样会跟踪子进程返回的系统调用
movl %esp, %eax
call syscall_return_slowpath
jmp restore_all
END(ret_from_fork)
其中 syscall_return_slowpath 的调用链路为:
if (cached_flags & _TIF_SIGPENDING)
do_signal(regs);
最终 do_signal 调用 handle_signal 对信号进行了处理:
void do_signal(struct pt_regs *regs)
{
struct ksignal ksig;
if (get_signal(&ksig)) {
handle_signal(&ksig, regs);
return;
}
…
}
注意
我们可以让一个进程产生 coredump 文件用于调试。首先可以通过 ulimit-c unlimited 命令不限制 corefile 文件的大小,然后通过 kill-3 pid 来通知进程调用 coredump。
最后我们来简单介绍 kill 命令的实现,它是通过发送信号的系统调用来实现的,这样的系统调用有很多,最终都会调用 __send_signal()函数:
staticint __send_signal(int sig,struct siginfo *info, struct task_struct *t,
int group, int from_ancestor_ns)
{
struct sigpending *pending;
struct sigqueue *q;
int override_rlimit;
……
// 找到需要挂起的队列
pending = group ? &t->signal->shared_pending : &t->pending;
……
// 分配队列项结构
q = __sigqueue_alloc(t, GFP_ATOMIC | __GFP_NOTRACK_FALSE_POSITIVE,
override_rlimit);
if (q) { // 如果分配成功,将该结构添加到挂起队列,并进行初始化
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current,
task_active_pid_ns(t));
q->info.si_uid = current_uid();
break;
case (unsigned long) SEND_SIG_PRIV:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
} else if (!is_si_special(info)) {
if (sig >= SIGRTMIN && info->si_code != SI_USER)
return -EAGAIN;
}
out_set:
signalfd_notify(t, sig); // 唤醒 action 中的等待队列
sigaddset(&pending->signal, sig); // 设置信号 ID 位掩码,即上面所说的那个位图
complete_signal(sig, t, group); // 试着唤醒执行该信号的进程
return 0;
}
发送信号,即将该信号链接到制定进程的信号挂起队列上,最后试着唤醒执行该信号的进程,这样我们就能理解为什么信号的响应都是在执行 ret_from_work 的时候进行。
4.7 Nginx 信号处理机制
很多软件在启动过程中都会注册默认信号处理函数。例如 Nginx,在 main 函数启动的时候就通过 ngx_init_signals 函数进行了信号处理机制初始化:
int ngx_cdecl
main(int argc, char *const *argv)
{
…
if (ngx_init_signals(cycle->log) != NGX_OK) {
return 1;
}
…
其中 ngx_init_signals 函数就是将默认的信号处理回调函数注册到相应的信号:
ngx_int_t
ngx_init_signals(ngx_log_t *log)
{
ngx_signal_t *sig;
struct sigaction sa;
for (sig = signals; sig->signo != 0; sig++) {
ngx_memzero(&sa, sizeof(struct sigaction));
if (sig->handler) {
sa.sa_sigaction = sig->handler;
sa.sa_flags = SA_SIGINFO;
} else {
sa.sa_handler = SIG_IGN;
}
sigemptyset(&sa.sa_mask);
…
return NGX_OK;
}
这些信号相应的默认处理函数也在全局做了定义:
ngx_signal_t signals[] = {
{ ngx_signal_value(NGX_RECONFIGURE_SIGNAL),
"SIG" ngx_value(NGX_RECONFIGURE_SIGNAL),
"reload",
ngx_signal_handler },
{ ngx_signal_value(NGX_REOPEN_SIGNAL),
"SIG" ngx_value(NGX_REOPEN_SIGNAL),
"reopen",
ngx_signal_handler },
{ ngx_signal_value(NGX_NOACCEPT_SIGNAL),
"SIG" ngx_value(NGX_NOACCEPT_SIGNAL),
"",
ngx_signal_handler },
{ ngx_signal_value(NGX_TERMINATE_SIGNAL),
"SIG" ngx_value(NGX_TERMINATE_SIGNAL),
"stop",
ngx_signal_handler },
{ ngx_signal_value(NGX_SHUTDOWN_SIGNAL),
"SIG" ngx_value(NGX_SHUTDOWN_SIGNAL),
"quit",
ngx_signal_handler },
{ ngx_signal_value(NGX_CHANGEBIN_SIGNAL),
"SIG" ngx_value(NGX_CHANGEBIN_SIGNAL),
"",
ngx_signal_handler },
{ SIGALRM, "SIGALRM", "", ngx_signal_handler },
{ SIGINT, "SIGINT", "", ngx_signal_handler },
{ SIGIO, "SIGIO", "", ngx_signal_handler },
{ SIGCHLD, "SIGCHLD", "", ngx_signal_handler },
{ SIGSYS, "SIGSYS, SIG_IGN", "", NULL },
{ SIGPIPE, "SIGPIPE, SIG_IGN", "", NULL },
{ 0, NULL, "", NULL }
};
4.8 本章小结
可以这样认为,除了信号处理机制是结合进程切换过程的实现外,本章提到的其他几种机制,都是结合中断机制来展开的。只要使用操作系统,几乎在所有的地方都会用到中断机制,不管写什么程序,都要结合系统调用来展开。
很多软件在启动过程中都会注册默认信号处理函数,例如 Nginx 等,其他软件也有类似的处理,大家有兴趣也可以自己去阅读其他软件源代码。
本章的内容是承上启下的,因为进程的切换、信号处理等都需要通过中断机制来实现。另外,和操作系统相关的 I/O 也和中断机制有很大的关系,有了中断机制,才能建立更加高效的 I/O 模型,提升系统响应效率。下一章将介绍 I/O 机制。