hadoop开发中遇到的问题
http://blog.csdn.net/congcong68/article/details/42043093
Windows下的 Eclipse上调试Hadoop2代码,所以我们在windows下的Eclipse配置hadoop-eclipse-plugin-2.6.0.jar插件,并在运行Hadoop代码时出现了一系列的问题,搞了好几天终于能运行起代码。接下来我们来看看问题并怎么解决,提供给跟我同样遇到的问题作为参考。
End of File Exception between local host is: "xwangd/10.169.207.213"; destination host is:
java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764)
at org.apache.hadoop.ipc.Client.call(Client.java:1472)
at org.apache.hadoop.ipc.Client.call(Client.java:1399)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
at com.sun.proxy.$Proxy11.sendHeartbeat(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.sendHeartbeat(DatanodeProtocolClientSideTranslatorPB.java:139)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.sendHeartBeat(BPServiceActor.java:582)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:680)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:850)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1071)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:966)
出错的时候,可以设置logger级别,看下具体原因:export HADOOP_ROOT_LOGGER=DEBUG,console
1. INFO util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable -- hadoop的本地库加载失败。
Hadoop默认会从$HADOOP_HOME/lib/native/Linux-*目录中加载本地库。如果加载成功,输出为:
DEBUG util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
INFO util.NativeCodeLoader - Loaded the native-hadoop library
如果加载失败,则报错为Unable to load native-hadoop library for your platform...
相关的配置:
在Hadoop的配置文件core-site.xml中可以设置是否使用本地库:
[html] view plaincopyprint?
<property>
[html] view plaincopyprint?
<name>hadoop.native.libname>
[html] view plaincopyprint?
<value>truevalue>
[html] view plaincopyprint?
<description>Should native hadoop libraries, if present, be used.description>
[html] view plaincopyprint?
property>
Hadoop默认的配置为启用本地库。另外,可以在环境变量中设置使用本地库的位置:
export JAVA_LIBRARY_PATH=/path/to/hadoop-native-libs
出错原因:
检查native库的版本信息,32bit的版本和64bit的版本在不匹配的机器上会加载失败,检查的命令是file
。 native库依赖的glibc的版本问题。如果在高版本gcc(glibc)的机器上编译的native库,放到低版本的机器上使用,会由于glibc版本不一致导致该错误。
2. java.io.IOException: Failed on local exception: java.io.EOFException; Host Details : local host is: "master/192.168.216.135"; destination host is: "master":54310;
重新格式化namenode
3. maps to localhost, but this does not map back
是因为DNS服务器把 192.168.x.x 的地址都反向解析成 localhost ,而DNS服务器不是自己的,不能改。 解决的办法就是,编辑 ssh 客户端的 /etc/hosts 文件,把出问题的IP 地址和主机名加进去,就不会报这样的错了。
4. java.io.IOException: Incompatible clusterIDsin /home/wangming/hadoop-data/dfs/data
format 前 rm 一下
5. jps命令正常,但是8088端口的WEB页面无法访问
检查一下防火墙,selinux & iptables
6. 8088端口访问正常,但是看不到datanode节点
查看配置中,发现yarn-site.xml中,yarn.resourcemanager.address属性配置的端口号为8080,启动的时候,打开这个端口失败(可能是被其它进程占用,maybe tomcat等),改成8085,重新启动,问题解决。
7. java.io.IOException: Failed on local exception: java.io.EOFException; Host Details : local host is: "master/192.168.216.135"; destination host is: "master":54310;
不知道为什么,重新格式化namenode,再启动,没有再报错。
8. java.lang.IllegalStateException: Invalid shuffle port number -1 returned
参见yarn-site.xml的配置,2.0.5.alpha版本中,这里需要配置成mapreduce.shuffle
9. org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.216.131:54310
一是检查slave机器到master机器的连通性;
二是检查master机器上,是否打开了192.168.216.131:54310的监听(netstat -nap | grep 54310)
注意hostname的问题,同时,namenode与data node的/etc/hosts内容都必须是ip位址与host name的对应,不能使用127.0.0.1代替本机的ip地址,否则hadoop使用hostname找ip时,会以"127.0.0.1"作为ip位址。
10. FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain:
hostname不在hosts列表里面,检查hostname和/etc/hosts文件
11. INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Exiting Datanode 或者 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Removed Block pool
fs.data.dir参数设置的目录权限必需为755,要不启动datanode节点启动就会因为权限检测错误而自动关闭。
Windows 下Hadoop for Eclipse 插件编译
http://doc.okbase.net/congcong68/archive/119982.html
http://blog.csdn.net/xjavasunjava/article/details/12320045
转载自:http://www.cnblogs.com/beanmoon/archive/2013/01/05/2845579.html
由于hadoop主要是部署和应用在linux环境中的,但是目前鄙人自知能力有限,还无法完全把工作环境转移到linux中去(当然还有点小私心啦,windows下那么多好用的程序到linux下用不了还真有点心疼——比如说快播,O(∩_∩)O~),于是便想着用eclipse来远程连接hadoop进行开发,摸索了一番,下面是其步骤:
1. 首先把hadoop-eclipse-plugin-1.0.4.jar(具体版本视你的hadoop版本而定)放到eclipse安装目录的plugins文件夹中,如果重新打开eclipse后看到有如下视图,则说明你的hadoop插件已经安装成功了:

其中的“hadoop installation directory”配置项用于指向你的hadoop安装目录,在windows下你只需要把下载到的hadoop-1.0.4.tar.gz包解压到某个位置,然后指向这个位置即可。
2. 配置eclipse中的Map/Reduce Locations,如下图所示:
其中主机“master”是我在“C:\Windows\System32\drivers\etc\hosts”中自定义的主机名:
218.195.250.80 master
这时如果在eclipse中能看到如下“DFS Locations”,就说明eclipse已经成功连上远程的hadoop了(注意,别忘了把你的视图切换到Map/Reduce视图,而不是默认的Java视图):

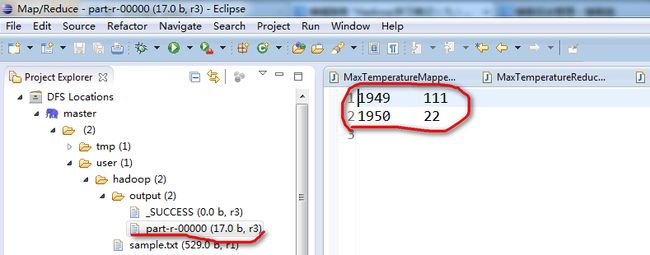
3. 现在我们来测试《hadoop权威指导》中的MaxTemperature例子程序,建立如下三个类:
Run Configuration中的配置参数为:
hdfs://202.193.75.78:49000/user/hadoop/input/core-site.xml //输入文件,此处有换行
hdfs://202.193.75.78:49000/user/hadoop/output5 //输出目录
这时如果我们运行MaxTemperature类,会报如下错:
| 12/04/24 15:32:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 12/04/24 15:32:44 ERROR security.UserGroupInformation: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to 0700 |
这个是Windows下文件权限问题,在Linux下可以正常运行,不存在这样的问题。
解决方法是,修改hadoop-1.0.4/src/core/org/apache/hadoop/fs/FileUtil.java里面的checkReturnValue,注释掉即可(有些粗暴,在Window下,可以不用检查):
重新编译打包hadoop-core-1.0.4.jar,替换掉hadoop-1.0.4根目录下的hadoop-core-1.0.4.jar即可。(我重新打包的时候出了点问题,就直接以从网上下载的hadoop-core-1.0.2.jar代替hadoop-core-1.0.4.jar了,这样也可以正常运行,下载地址:https://skydrive.live.com/?cid=cf7746837803bc50&id=CF7746837803BC50%211276)
(其实还有另一种简单的办法,我们只需要把hadoop-1.0.4/src/core/org/apache/hadoop/fs/FileUtil.java修改之后重新编译过的class文件加入到原来的hadoop-core-1.0.4.jar包中代替原来的FileUtil.class文件即可,这里有一个已经做好的适合于windows环境的hadoop-core-1.0.4.jar包了,你可以直接下载)
另外,我还遇到了这么一个错误:
| org.apache.hadoop.security.AccessControlException:Permission denied:user=Administrator,access=WRITE,inode="tmp":root:supergroup:rwxr-xr-x 。 |
这个错误有些蹊跷,因为我已经在map/reduce locations中配置了用户名是hadoop(hadoop就是我linux上运行hadoop集群的用户名),不知道它为什么还是以Administrator用户身份来方位hadoop的,解决办法如下:
问题原因:本地用户administrator(本机windows用户)想要远程操作hadoop系统,没有权限引起的。
解决办法:
a、如果是测试环境,可以取消hadoop hdfs的用户权限检查。打开conf/hdfs-site.xml,找到dfs.permissions属性修改为false(默认为true)OK了。
b、修改hadoop location参数,在advanced parameter选项卡中,找到hadoop.job.ugi项,将此项改为启动hadoop的用户名即可。(注意第一次设置的时候可能没有hadoop.job.ugi参数,报错后在去看就有了。)
c、因为Eclipse使用hadoop插件提交作业时,会默认以 DrWho 身份去将作业写入hdfs文件系统中,对应的也就是 HDFS 上的/user/hadoop , 由于 DrWho 用户对hadoop目录并没有写入权限,所以导致异常的发生。解决方法为:放开 hadoop 目录的权限 , 命令如下 :$ hadoop fs -chmod 777