filebeat收集K8S日志,写入自动创建的索引
需求
前面我们已经将SpringBoot项目部署在K8S中,此时需要filebeat收集日志并通过ELK进行展示,以用于后续的问题排查及监控。
与传统的日志收集不同:
- pod所在节点不固定,每个pod中运行filebeat,配置繁琐且浪费资源;
- pod的日志目录一般以emptydir方式挂载在宿主机,目录不固定,filebeat无法自动匹配;
- pod持续增多,filebeat需要做到自动检测并收集;
因此最好的收集方式为node节点上的一个filebeat能够收集所有的pod日志,但是这就要求统一的日志收集规则、目录以及输出方式。
下面我们就按这个思路进行思考。
日志目录
K8S中的日志目录有以下三种:
- /var/lib/docker/containers/
- /var/log/containers/
- /var/log/pods/
为什么会有这三种目录呢?这就要从容器运行时(Container Runtime)组件说起了:
- 当Docker 作为 k8s 容器运行时,容器日志的落盘将由 docker 来完成,保存在/var/lib/docker/containers/$CONTAINERID 目录下。Kubelet 会在 /var/log/pods 和 /var/log/containers 下建立软链接,指向 /var/lib/docker/containers/CONTAINERID 该目录下的容器日志文件。
- 当Containerd 作为 k8s 容器运行时, 容器日志的落盘由 Kubelet 来完成,保存至 /var/log/pods/$CONTAINER_NAME 目录下,同时在 /var/log/containers 目录下创建软链接,指向日志文件。
# 1.查看/var/log/containers目录下文件,已被软链到/var/log/pods中的xx.log文件按
# cd /var/log/containers && ll
lrwxrwxrwx 1 root root 107 Jun 15 15:39 kube-apiserver-uvmsvr-3-217_kube-system_kube-apiserver-7fbb97008724e35427262c1ac294c24d7771365b9facf5f5a49c6b15f032e441.log -> /var/log/pods/kube-system_kube-apiserver-uvmsvr-3-217_837ea80229ea9cd5bbf448f4f0386cbc/kube-apiserver/1.log
lrwxrwxrwx 1 root root 107 Aug 21 11:39 kube-apiserver-uvmsvr-3-217_kube-system_kube-apiserver-fd8b454b07b8701045f007bd55551aae60f376d1aee07729779ec516ea505239.log -> /var/log/pods/kube-system_kube-apiserver-uvmsvr-3-217_837ea80229ea9cd5bbf448f4f0386cbc/kube-apiserver/2.log
...只列举部分...
# 2.查看/var/log/pods目录下的文件,xx.log 最终又软链到/var/lib/docker/containers/ 下的xxx-json.log
# cd /var/log/pods
ll /var/log/pods/kube-system_kube-apiserver-uvmsvr-3-217_837ea80229ea9cd5bbf448f4f0386cbc/kube-apiserver/1.log
lrwxrwxrwx 1 root root 165 Jun 15 15:39 /var/log/pods/kube-system_kube-apiserver-uvmsvr-3-217_837ea80229ea9cd5bbf448f4f0386cbc/kube-apiserver/1.log -> /var/lib/docker/containers/7fbb97008724e35427262c1ac294c24d7771365b9facf5f5a49c6b15f032e441/7fbb97008724e35427262c1ac294c24d7771365b9facf5f5a49c6b15f032e441-json.log
无论k8s使用哪种容器运行时,最终的日志都是读取的xxx-json.log,是由容器以json格式stdout输出的,了解这些后我们得到了统一的日志收集规则:
- 统一目录 :/var/log/containers
- 统一的输出方式:stdout
- 统一的日志格式:json
filebeat
在明确统一的日志收集规则后,我们就可以使用DaemonSet运行filebeat,收集k8s的所有pod日志。
ELK官方提供filebeat在k8s中的运行配置文件。
# 下载文件
curl -L -O https://raw.githubusercontent.com/elastic/beats/7.9/deploy/kubernetes/filebeat-kubernetes.yaml
其中filebeat的配置文件以configmap的方式挂载至容器的/etc/filebeat.yml,因此我们只需要修改configmap就可以实现配置文件的修改。
默认的filebeat-kubernetes.yaml虽然能够实现pod日志的收集,但是最终在ELK展示时会有多余字段或字段不全的现象,如:
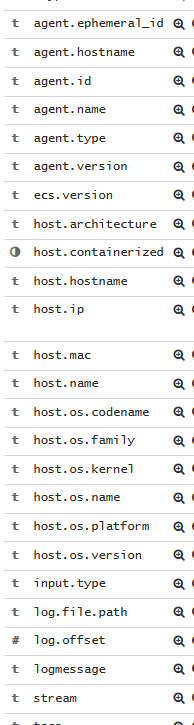
其中host字段、agent字段我们不需要,保留将会增加存储开销,而且没有关于K8S的描述信息,如namespace、node节点信息、image信息等是不显示的。因此我们还需要基于默认配置文件进行微调,来获得我们需要的日志。
1.添加k8s描述信息
k8s描述信息默认不添加,可通过以下方式开启:
processors:
- add_kubernetes_metadata:
default_indexers.enabled: true
default_matchers.enabled: true
效果如下:
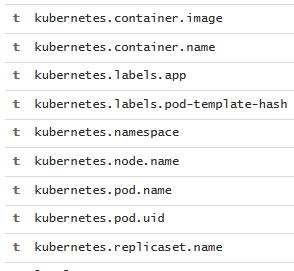
此时pod的基本信息都将会在ELK中展示,对我们排查问题非常便利。
2.删除多余字段
默认收集的字段包括host,agent等无用信息,我们可以自定义进行删除。
processors:
- drop_fields:
#删除的多余字段
fields: ["host", "tags", "ecs", "log", "prospector", "agent", "input", "beat", "offset"]
ignore_missing: true
此时可以通过drop_fields删除多余的字段,但是@timestamp和type不能被删除的。经过测试ecs、agent、tags也未能通过filbebeat删除。
注意:一个filebeat.yml可能由多个processors,如果你在其中一个processors中设置了drop_fields,而在其他processors没有设置,则最终可能导致需要删除的字段被删除后又自动添加。
对于未删除的字段,我们还可以通过logstash进行删除,例如:
remove_field => [ "agent" ]
remove_field => [ "ecs" ]
remove_field => [ "tags" ]
3.多行合并
对于springboot日志,我们一般需要将日志拆分成时间戳、日志级别、信息内容;对于ERROR级别日志还要多行合并,以便友好的展示错误信息。
在filebeat中设置将每行开头时间格式为2020-09-06与之后不匹配此规则的行进行合并。
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.timeout: 30
4.message字段拆分
默认filebeat收集的日志以json格式存储,日志内容存储为message,因此需要在logstash中过滤message并将其拆分后再写入elasticsearch。
grok {
match => {
"message" => "(%{TIMESTAMP_ISO8601:logdatetime} %{LOGLEVEL:level} %{GREEDYDATA:logmessage})|%{GREEDYDATA:logmessage}" }
}
将message中的日志内容再拆分为时间、日志级别、信息内容等字段,以便在ELK中进行搜索。
效果为:

注意:stream:stdout表示日志以stdout输出到json格式的日志中。
logstash自动创建索引
logstash将filebeat收集的日志输出到elasticsearch并创建索引。对于不断增多的pod,我们不可能挨个去手动自定义索引,最好的方式就是logstash根据filebeat的字段自动创建索引。
默认logstash通过metadata中的字段自动创建索引,如:
output {
if [fields][service] == "k8s-log" {
elasticsearch {
hosts => ["192.168.3.101:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
# 可通过以下方式,查看metadata信息
# stdout { codec => rubydebug { metadata => true}}
}
}
此时在elasticsearch中自动创建的索引为filebeat-7.9-2020.09.06,因为通过stdout打印的metadata内容为:
{
....,
"@metadata" => {
"beat" => "filebeat",
"version" => "7.9"
}
}
注意:metadata信息不作为最终的信息在ELK中展示。
由于logtash通过metadata创建的filebeat-7.9-2020-8索引是固定的,因此收集的k8s中所有的pod日志都将写入这个索引。
思考:logstash是否可以根据filebeat的字段自动创建索引,这样将日志写入不同的索引了。
因此我尝试根据pod的命名空间和pod标签自动创建索引。
output {
if [fields][service] == "k8s-log" {
elasticsearch {
hosts => ["192.168.3.101:9200"]
index => "k8s-%{[kubernetes][namespace]}-%{[kubernetes][labels][app]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
#stdout { codec => rubydebug { metadata => true}}
}
}
最终创建的索引为k8s-test-helloworld-2020.09.06,实现自动创建索引的需求了。
最终整合
1.filebeat
# 1.下载初始配置文件
curl -L -O https://raw.githubusercontent.com/elastic/beats/7.9/deploy/kubernetes/filebeat-kubernetes.yaml
# 2.修改configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
paths:
- /var/log/containers/api-*.log
#多行合并
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
multiline.timeout: 30
fields:
#自定义字段用于logstash识别k8s输入的日志
service: k8s-log
#禁止收集host.xxxx字段
#publisher_pipeline.disable_host: true
processors:
- add_kubernetes_metadata:
#添加k8s描述字段
default_indexers.enabled: true
default_matchers.enabled: true
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_fields:
#删除的多余字段
fields: ["host", "tags", "ecs", "log", "prospector", "agent", "input", "beat", "offset"]
ignore_missing: true
output.redis:
hosts: ["192.168.3.44"]
#password: ""
key: "k8s-java-log_test"
db: 1
timeout: 5
#output.logstash:
# hosts: ["192.168.3.101:5044"]
2. logstash
input {
beats {
port => 5044
}
redis {
host => "192.168.3.44"
port => "6379"
db => 1
data_type => "list"
key => "k8s-java-log_test"
type => "k8s-log"
}
}
filter {
if [type] == "k8s-log" {
grok {
match => {
"message" => "(%{TIMESTAMP_ISO8601:logdatetime} %{LOGLEVEL:level} %{GREEDYDATA:logmessage})|%{GREEDYDATA:logmessage}" }
remove_field => [ "message" ]
remove_field => [ "agent" ]
remove_field => [ "ecs" ]
remove_field => [ "tags" ]
}
}
}
output {
if [fields][service] == "k8s-log" {
elasticsearch {
hosts => ["192.168.3.101:9200"]
index => "k8s-%{[kubernetes][namespace]}-%{[kubernetes][labels][app]}-%{+YYYY.MM.dd}"
}
#stdout { codec => rubydebug { metadata => true}}
}
}
最终效果如下:
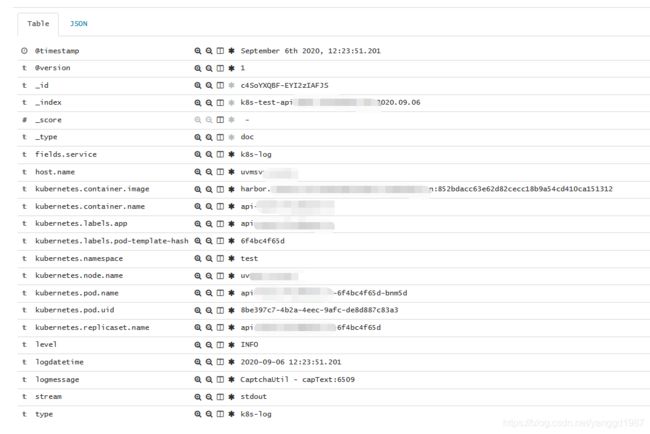
总结
刚开始想到pod的特性时,最初想到使用sidecar模式,即每个pod中都运行一个filebeat进行日志收集,的确比较耗费资源。经过阅读了官方的k8s部署以及k8s的几个日志目录,才确定DaemonSet部署filebeat才是最优方案。
另外,还尝试使用阿里开源的log-pilot,但最终还是选择了ELK官方的部署。