Scrapy爬虫框架
开学已经两个星期了,在实验室摸了几天的鱼?(打酱油)。课一节都没有上过(不是逃课,是还没有开课),会倒是开了不少(各种入学教育啊,讲座啊),在导师快要回来的时候,果断开始了学习,不然印象就不好了(尴尬)。这次就学了哈之前看过但是因为考研的原因没有太多时间来研究的scrapy框架。
开发环境以及工具:win10 + pycharm + SQLite
需要的包就是scrapy、ipython、sqlite3,下载所需要的包就是直接用pip就可以了(sqlite3是python自带的)
pip install scrapy
pip install Ipython然后如果需要在指定文件夹下创建scrapy的话,只需要在cmd中进入指定文件夹,然后使用命令行创建一个scrapy项目:
scrapy startproject 名称将新建的项目在pycharm中打开,在新建的项目的spiders文件下新建一个.py文件。这次爬取的网站是一个找房子的网站,网站是:https://wh.fang.ke.com/loupan/
因为只是测试scrapy框架,所以没必要爬过多的数据,不然ip被封了就不好玩了。网站有100页,以前也讲过去找网址的规律然后获取网站,这次就直接上代码了(这个都是写在spiders下新建的.py文件中的):
#网址前面的部分
url_pre = "https://wh.fang.ke.com/loupan/pg"
#新建一个空列表用于后期保存网址
url_list = []
for i in range(1, 11):
#拼接成完整的网址
url = url_pre + str(i)
#将网址添加到列表中,以便爬取的时候循环
url_list.append(url)
i += 1然后开始找需要爬取的元素,这里我爬取的两个元素一个是标题,另一个是价格,这里找元素用了一个比较偷懒的方法,在火狐中下载插件就连可以了(注意的是最新版的火狐已经不支持firepath这个插件了),这里我用到的火狐插件就是xPath Finder,下载插件的方法不会的可以自行百度。使用方法也很简单,在插件安装完成后,火狐的右上方会出现一个图标:

点击之这个图标,鼠标会变成一个十字型,然后将鼠标拖到你想获得的元素上面,然后点击就会出现元素的路径,如下图所示:

获取楼盘名称的方法也一样,然后可以先在cmd中测试一下,获取一整页中所有的价格或者标题,首先获取网页的shell:
scrapy shell 网站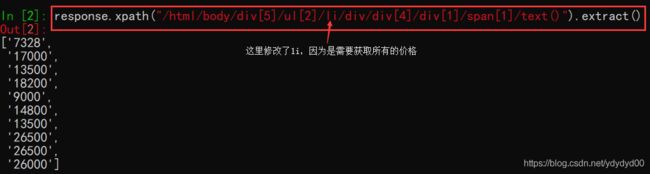
这里为什么是In[2]呢,因为第一条命令单词写错了(尴尬),同理获取标题的方法也一样。然后就可以直接将代码写道spiders文件中的.py文件下了
import scrapy
from ..items import FindhouseItem
#网址前面的部分
url_pre = "https://wh.fang.ke.com/loupan/pg"
#新建一个空列表用于后期保存网址
url_list = []
for i in range(1, 2):
#拼接成完整的网址
url = url_pre + str(i)
#将网址添加到列表中,以便爬取的时候循环
url_list.append(url)
i += 1
class FindHouse(scrapy.Spider):
#爬虫名,运行时候用到
name = "zhaofang"
#爬取的网站区域,这里start_urls后面的s不能掉,不然爬不到数据
start_urls = url_list
def parse(self, response):
# print(response)
#从结构化的数据中提取各种对应的元素
zf = FindhouseItem()
title_list = response.xpath("/html/body/div[5]/ul[2]/li/div/div[1]/a/text()").extract()
price_list = response.xpath("/html/body/div[5]/ul[2]/li/div/div[4]/div[1]/span[1]/text()").extract()
for i,j in zip(title_list,price_list):
zf['title'] = i
zf['price'] = j
#scrapy框架对含有yield的parse()方法的调用是以迭代的是进行的
#yield中断访问,快一点
yield zf以上就是数据的爬取,然后就是对其他文件的配置(按我的文件目录的顺序来),第一个是items.py文件的配置:
#Items主要目标是从非结构化来源提取结构化数据,scrapy爬虫可以将提取的数据作为python语句返回
import scrapy
class FindhouseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#Field对象用于为每个字段指定元数据,Field用于声明项目的对象不会被分配为类属性。
#可以通过Item.fields属性访问它们。
title = scrapy.Field()
price = scrapy.Field()然后是管道文件的配置(pipelines.py):
#sqlite是python自带的轻量级数据库
import sqlite3
#连接数据库,没有则创建
findhouse = sqlite3.connect("findhouse.sqlite")
create_table = 'create table findhouse (title varchar(512), price varchar(128))'
#创建表,有则声明已创建
try:
findhouse.execute(create_table)
except sqlite3.OperationalError as e:
print("yichuanjian")
class FindhousePipeline(object):
#当爬虫被打开的时候调用这个方法
def open_spider(self,spider):
self.con = sqlite3.connect("findhouse.sqlite")
self.con.text_factory=str
self.cu = self.con.cursor()
#爬虫爬取到数据存放到items之后,返回的items对象会触发pipelines对items对象的操作,它主要存放在piplines.py中
def process_item(self, item, spider):
insert_sql = "insert into findhouse (title,price) values('{}','{}')".format(item['title'],item['price'])
self.cu.execute(insert_sql)
self.con.commit()
#我的数据库是坏的,用这个测试一下
# con = 'title:' + str(item['title']) + 'price:' + str(item['price']) + '\n'
# with open(r'F:\Pycharm\FindHouse\FindHouse\spiders\price.csv', 'a', encoding='utf-8') as f:
# f.write(con)
return item
#爬虫关闭调用
def spider_close(self,spider):
self.con.close()最后一个是settings.py,问了实验室的师兄,师兄说最好不要遵守网站的爬虫规则,不然会有很多数据拿不到,只需要对这个文件呢做一个简单的修改即可(True改为False):
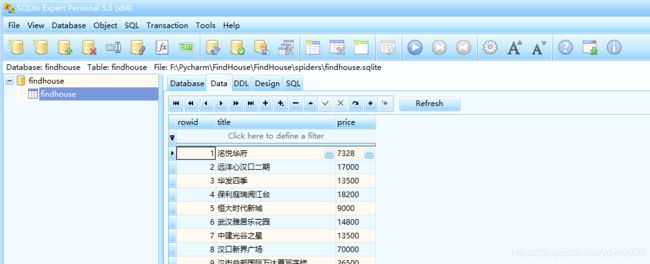
# Obey robots.txt rules
ROBOTSTXT_OBEY = False最后就是爬取的结果了,不知道为什么我的pycharm没有数据库这个选项,然后百度了很多方法也没有解决我的这个问题(就是我太菜了),然后就下了一个sqlite的可视化软(SQLite Expert Pro),这样就可以看到爬取下来的数据了。下面是部分数据的截图: