目标检测(Object Detection)综述--R-CNN/Fast R-CNN/Faster R-CNN/YOLO/SSD
1. 目标检测
1.1 简介
如何理解一张图片?根据后续任务的需要,有三个主要的层次。
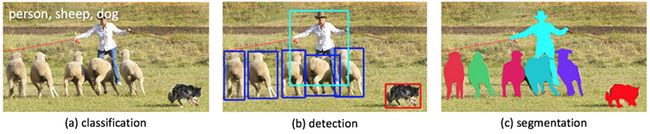
一是分类(Classification),即是将图像结构化为某一类别的信息,用事先确定好的类别(string)或实例ID来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。其中,ImageNet是最权威的评测集,每年的ILSVRC催生了大量的优秀深度网络结构,为其他任务提供了基础。在应用领域,人脸、场景的识别等都可以归为分类任务。
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
本系列文章关注的领域是目标检测,即图像理解的中层次。
1.2 历史研究
1.2.1 深度学习时代之前
在深度学习时代之前,早期的目标检测流程分为三步:候选框生成、特征向量提取和区域分类。
(1)第一阶段,候选框生成,目标是搜索图像中可能包含对象的位置,这些位置又叫「感兴趣区域」(ROI)。直观的思路是用滑动窗口扫描整幅图像。为了捕捉不同尺寸和不同宽高比对象的信息,输入图像被重新分割为不同的尺寸,然后用不同尺寸的窗口滑动经过输入图像。
(2)第二阶段,在图像的每一个位置上,利用滑动窗口获取固定长度的特征向量,从而捕捉该区域的判别语义信息。该特征向量通常由低级视觉描述子编码而成,这些描述子包括 SIFT (Scale Invariant Feature Transform) 、Haar 、HOG(Histogram of Gradients) 、SURF(Speeded Up Robust Features) 等,它们对缩放、光线变化和旋转具备一定的鲁棒性。
(3)第三阶段,学习区域分类器,为特定区域分配类别标签。
通常,这里会使用支持向量机(SVM),因为它在小规模训练数据上性能优异。此外,Bagging、级联学习(cascade learning)和 Adaboost 等分类技术也会用在区域分类阶段,帮助提高目标检测的准确率。
1.2.2 深度学习之后
在将深度卷积神经网络成功应用于图像分类后,基于深度学习技术的目标检测也取得了巨大进步。基于深度学习的新算法显著优于传统的目标检测算法。
目前,基于深度学习的目标检测框架可以分为两大类:
1)二阶检测器(Two-stage),如基于区域的 CNN (R-CNN) 及其变体;
2)一阶检测器(One-stage),如 YOLO 及其变体。
二阶检测器首先使用候选框生成器生成稀疏的候选框集,并从每个候选框中提取特征;然后使用区域分类器预测候选框区域的类别。
一阶检测器直接对特征图上每个位置的对象进行类别预测,不经过二阶中的区域分类步骤。

通常而言,二阶检测器通常检测性能更优,在公开基准上取得了当前最优结果,而一阶检测器更省时,在实时目标检测方面具备更强的适用性。
两者的主要区别在于two stage算法需要先生成proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。
而one stage算法会直接在网络中提取特征来预测物体分类和位置。
2. 双阶段模型
两阶段模型因其对图片的两阶段处理得名,也称为基于区域(Region-based)的方法,我们选取R-CNN系列工作作为这一类型的代表。
传统的计算机视觉方法常用精心设计的手工特征(如SIFT, HOG)描述图像,而深度学习的方法则倡导习得特征,从图像分类任务的经验来看,CNN网络自动习得的特征取得的效果已经超出了手工设计的特征。
RCNN (论文:Rich feature hierarchies for accurate object detection and semantic segmentation) 是将CNN方法引入目标检测领域, 大大提高了目标检测效果,可以说改变了目标检测领域的主要研究思路, 紧随其后的系列文章:( RCNN),Fast RCNN, Faster RCNN 代表该领域当前最高水准。
2.1 RCNN
R-CNN将检测抽象为两个过程:
一是基于图片提出若干可能包含物体的区域(即图片的局部裁剪,被称为Region Proposal),文中使用的是Selective Search算法;
二是在提出的这些区域上运行当时表现最好的分类网络(AlexNet),得到每个区域内物体的类别。
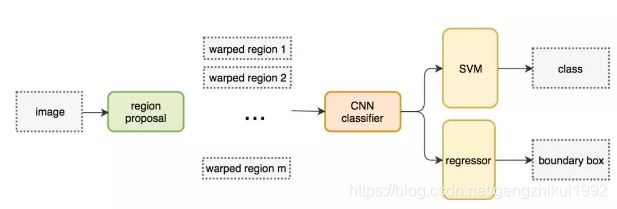
RCNN算法分为4个步骤

1. 候选区域生成: 一张图像生成1K~2K个候选区域 (采用Selective Search 方法)
2. 特征提取: 对每个候选区域,使用深度卷积网络提取特征 (CNN)
3. 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
4. 位置精修: 使用回归器精细修正候选框位置
候选区域生成–Selective Search
1. 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
2. 查看现有小区域,按照合并规则合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
3. 输出所有曾经存在过的区域,所谓候选区域
其中合并规则如下: 优先合并以下四种区域:
1. 颜色(颜色直方图)相近的
2. 纹理(梯度直方图)相近的
3. 合并后总面积小的: 保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域 (例:设有区域a-b-c-d-e-f-g-h。较好的合并方式是:ab-cd-ef-gh -> abcd-efgh -> abcdefgh。 不好的合并方法是:ab-c-d-e-f-g-h ->abcd-e-f-g-h ->abcdef-gh -> abcdefgh)
4. 合并后,总面积在其BBOX中所占比例大的: 保证合并后形状规则。
重叠度(IOU)
物体检测需要定位出物体的bounding box。因为我们算法不可能百分百跟人工标注的数据完全匹配,因此就存在一个定位精度评价公式IOU:它定义了两个bounding box的重叠度。
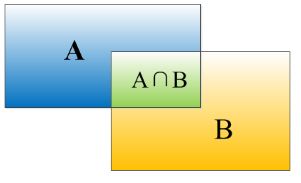
就是矩形框A、B的重叠面积占A、B并集的面积比例。
![]()
RCNN会从一张图片中找出n个可能是物体的bounding box,然后为每个bounding box为做类别分类概率

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
非极大值抑制(NMS)
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4)就这样一直重复,找到所有被保留下来的矩形框。
2.2 Fast R-CNN: 共享卷积运算
R-CNN的想法直接明了,即将检测任务转化为区域上的分类任务,是深度学习方法在检测任务上的试水。这篇论文的很多做法仍然广泛地影响着检测任务上的深度模型革命,后续的很多工作也都是针对改进这一工作而展开,此篇可以称得上"The First Paper"。
然而R-CNN 需要非常多的候选区域以提升准确度,但其实有很多区域是彼此重叠的,因此 R-CNN 的训练和推断速度非常慢。如果我们有 2000 个候选区域,且每一个都需要独立地馈送到 CNN 中,那么对于不同的 ROI,我们需要重复提取 2000 次特征。

以下是R-CNN的流程图:
此外,CNN 中的特征图以一种密集的方式表征空间特征,那么我们能直接使用特征图代替原图来检测目标吗?

将候选区域直接应用于特征图,并使用 ROI 池化将其转化为固定大小的特征图块。

(1) Fast R-CNN 使用特征提取器(CNN)先提取整个图像的特征,而不是从头开始对每个图像块提取多次。
(2)然后,我们可以将创建候选区域的方法直接应用到提取到的特征图上。例如,Fast R-CNN 选择了 VGG16 中的卷积层 conv5 来生成 ROI。
(3)这些关注区域随后会结合对应的特征图以裁剪为特征图块,并用于目标检测任务中。
(4)我们使用 ROI 池化将特征图块转换为固定的大小,并馈送到全连接层进行分类和定位。
Fast-RCNN 不会重复提取特征,因此它能显著地减少处理时间。
以下是 Fast R-CNN 的流程图:

2.3 Faster R-CNN
Faster R-CNN 的流程图与 Fast R-CNN 相同,粗略的讲,Faster R-CNN = RPN + Fast R-CNN。
Fast R-CNN 依赖于外部候选区域方法,如选择性搜索。但这些算法在 CPU 上运行且速度很慢。在测试中,Fast R-CNN 需要 2.3 秒来进行预测,其中 2 秒用于生成 2000 个 ROI。
Faster R-CNN 采用与 Fast R-CNN 相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成 ROI 时效率更高,并且以每幅图像 10 毫秒的速度运行。

3. 单阶段模型
单阶段模型只有一次类别预测和位置回归,卷积运算的共享程度更高,拥有更快的速度和更小的内存占用。
3.1 YOLO
Redmon 等人提出了一种叫做 YOLO(You Only Look Once)的实时检测器。
YOLO 将目标检测看作回归问题,将整个图像分割为固定数量的网格单元(如使用 7 × 7 网格)。每个单元被看作一个候选框,然后网络检测候选框中是否存在一或多个对象。

(1) 对图片进行resize成规定的size(448x448)
(2) 对整张图片进行卷积
(3) 是使用非最大值抑制算法求得目标区域。
基于精细设计的轻量级架构,YOLO 可以 45 FPS 的速度执行预测,使用更简化的骨干网络后速度可达 155 FPS。但是,YOLO 面临以下挑战:
- 对于给定位置,它至多只能检测出两个对象,这使得它很难检测出较小的对象和拥挤的对象。
- 只有最后一个特征图可用于预测,这不适合预测多种尺寸和宽高比的对象。
3.2 SSD: Single Shot Multibox Detector
2016 年,Liu 等人提出另一个一阶检测器 Single-Shot Mulibox Detector (SSD),解决了 YOLO 的缺陷。
SSD 也将图像分割为网格单元,但是在每一个网格单元中,可以生成一组不同尺寸和宽高比的锚点框,从而离散化边界框的输出空间。
参考
干货 | 目标检测入门,看这篇就够了
RCNN- 将CNN引入目标检测的开山之作
【目标检测简史】YOLOv3的实景大片儿
基于深度学习的目标检测算法综述
从RCNN到SSD,这应该是最全的一份目标检测算法盘点