Hadoop环境搭建(本地模式,伪分布模式)
一.什么是hadoop?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。
它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
hadoop大数据处理的意义:
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
(----以上摘自百度百科)
二.Hadoop环境搭建
实验环境redhat6.5
实验前关闭iptables和selinux
1.jdk安装
[root@server2 ~]# ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[root@server2 ~]# useradd hadoop
[root@server2 ~]# passwd hadoop
[root@server2 ~]# mv * /home/hadoop/ ##hadoop文件的目录
[root@server2 hadoop]# su - hadoop
[hadoop@server2 ~]$ ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server2 ~]$ tar zxvf jdk-7u79-linux-x64.tar.gz
[hadoop@server2 ~]$ ln -s jdk1.7.0_79/ java
[hadoop@server2 ~]$ ls
hadoop-2.7.3.tar.gz java jdk1.7.0_79 jdk-7u79-linux-x64.tar.gz
设置JDK的环境变量,修改完毕后,执行 source.
[hadoop@server2 ~]$ cd java/bin/
[hadoop@server2 bin]$ pwd
/home/hadoop/java/bin
[hadoop@server2 bin]$ cd
[hadoop@server2 ~]$ vim .bash_profile
PATH=$PATH:$HOME/bin:/home/hadoop/java/bin
[hadoop@server2 ~]$ source .bash_profile
2.安装hadoop
Hadoop部署模式有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器
1).本地模式部署
本地模式是最简单的模式,所有模块都运行与一个JVM进程中,使用的本地文件系统,而不是HDFS,本地模式主要是用于本地开发过程中的运行调试用。下载hadoop安装包后不用任何设置,默认的就是本地模式。
[hadoop@server2 ~]$ tar zxf hadoop-2.7.3.tar.gz
[hadoop@server2 ~]$ pwd
/home/hadoop #存放本地模式hadoop的目录
[hadoop@server2 ~]$ cd hadoop-2.7.3/etc/hadoop/
[hadoop@server2 hadoop]$ vim hadoop-env.sh
25 export JAVA_HOME=/home/hadoop/java
运行MapReduce程序,验证
这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
[hadoop@server2 hadoop-2.7.3]$ vim file
[hadoop@server2 hadoop-2.7.3]$ cat file
hadoop big data
hadoop big data
hadoop big data
hadoop big data
[hadoop@server2 hadoop-2.7.3]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount file file1
![]()
这里可以看到job ID中有local字样,说明是运行在本地模式下的。
查看输出文件:
[hadoop@server2 hadoop-2.7.3]$ ll file1
total 4
-rw-r--r-- 1 hadoop hadoop 22 Mar 24 17:08 part-r-00000
-rw-r--r-- 1 hadoop hadoop 0 Mar 24 17:08 _SUCCESS
输出目录中有_SUCCESS文件说明JOB运行成功,part-r-00000是输出结果文件。
2.)伪分布式模式安装
1. 配置core-site.xml
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/core-site.xml
fs.defaultFS
hdfs://172.25.0.117:9000
fs.defaultFS参数配置的是HDFS的地址。
2.配置hdfs-site.xml
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.replication配置的是HDFS存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1。
3.设置免密登陆
[hadoop@server2 hadoop-2.7.3]$ ssh-keygen
[hadoop@server2 hadoop-2.7.3]$ ssh-copy-id 172.25.0.117
[hadoop@server2 .ssh]$ ssh 172.25.0.117
[hadoop@server2 ~]$ logout
Connection to 172.25.0.117 closed.
4.格式化HDFS
[hadoop@server2 hadoop-2.7.3]$ vim etc/hadoop/slaves
#将locasthost改为ip地址
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs namenode -format

格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。
5.启动NameNode,DataNode,SecondaryNameNode
[hadoop@server2 hadoop-2.7.3]$ sbin/start-dfs.sh
Starting namenodes on [server2]
The authenticity of host 'server2 (172.25.0.117)' can't be established.
RSA key fingerprint is a7:d7:fd:ef:38:37:6a:58:2d:07:9f:68:dd:5a:1e:96.
Are you sure you want to continue connecting (yes/no)? yes
server2: Warning: Permanently added 'server2' (RSA) to the list of known hosts.
server2: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server2.out
172.25.0.117: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server2.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
RSA key fingerprint is a7:d7:fd:ef:38:37:6a:58:2d:07:9f:68:dd:5a:1e:96.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (RSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-server2.out
[hadoop@server2 hadoop-2.7.3]$ jps # JPS命令查看是否已经启动成功,有结果就是启动成功了。
2474 Jps
2089 NameNode
2365 SecondaryNameNode
2182 DataNode
查看服务端口
[hadoop@server2 hadoop-2.7.3]$ netstat -antlp|grep 50070
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 2089/java
tcp 0 0 172.25.0.117:48878 172.25.0.117:50070 TIME_WAIT -
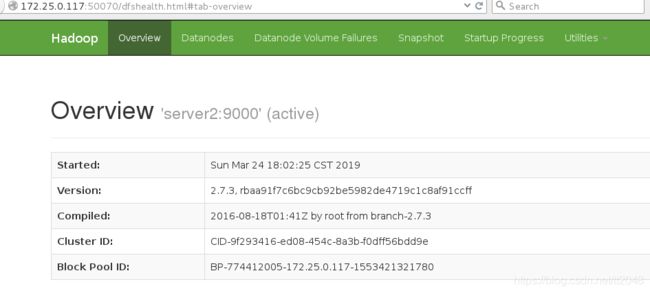
6. HDFS上测试创建目录、上传、下载文件
创建目录
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -mkdir /westos

上传本地文件到HDFS上
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -put /etc/passwd /westos

下载文件到本地
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -get /westos/passwd
[hadoop@server2 hadoop-2.7.3]$ ls
bin file include libexec logs passwd sbin
etc file1 lib LICENSE.txt NOTICE.txt README.txt share
7,配置、启动YARN
1)、 配置mapred-site.xml
默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml。
[hadoop@server2 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@server2 hadoop]$ vim mapred-site.xml
mapreduce.framework.name
yarn
指定mapreduce运行在yarn框架上。
2), 配置yarn-site.xml
[hadoop@server2 hadoop]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法。
3)、 启动Resourcemanager,nodemanager
[hadoop@server2 hadoop-2.7.3]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-server2.out
172.25.0.117: starting nodemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-server2.out
[hadoop@server2 hadoop-2.7.3]$ jps ##查看是否启动成功
2831 ResourceManager
2089 NameNode
2365 SecondaryNameNode
2926 NodeManager
2182 DataNode
3214 Jps
YARN的Web页面,客户端端口号是8088
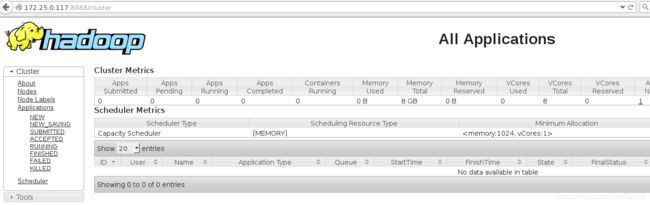
8)运行MapReduce Job
在Hadoop的share目录里,自带了一些jar包,里面带有一些mapreduce实例小例子,位置在share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar,可以运行这些例子体验刚搭建好的Hadoop平台,我们这里来运行最经典的WordCount实例。
创建原始文件:
[hadoop@server2 hadoop-2.7.3]$ vim file
[hadoop@server2 hadoop-2.7.3]$ cat file
hadoop tom cat
harry hadoop cat
将文件上传到HDFS的westos目录中:
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -put file /westos
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -ls /westos
Found 2 items
-rw-r--r-- 1 hadoop supergroup 33 2019-03-24 18:44 /westos/file
运行WordCount MapReduce Job
[hadoop@server2 hadoop-2.7.3]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /westos output
查看输出结果目录
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -ls output
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2019-03-24 19:19 output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 1025 2019-03-24 19:19 output/part-r-00000
output目录中有两个文件,_SUCCESS文件是空文件,有这个文件说明Job执行成功。
part-r-00000文件是结果文件,其中-r-说明这个文件是Reduce阶段产生的结果,mapreduce程序执行时,可以没有reduce阶段,但是肯定会有map阶段,如果没有reduce阶段这个地方有是-m-。
一个reduce会产生一个part-r-开头的文件。
查看输出文件内容
[hadoop@server2 hadoop-2.7.3]$ bin/hdfs dfs -cat output/part-r-00000
cat 2
hadoop 2
harry 1
tom 1
Hadoop各个功能模块的理解
1、 HDFS模块
HDFS负责大数据的存储,通过将大文件分块后进行分布式存储方式,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,HDFS是个相对独立的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
2、 YARN模块
YARN是一个通用的资源协同和任务调度框架,是为了解决Hadoop1.x中MapReduce里NameNode负载太大和其他问题而创建的一个框架。
YARN是个通用框架,不止可以运行MapReduce,还可以运行Spark、Storm等其他计算框架。
3、 MapReduce模块
MapReduce是一个计算框架,它给出了一种数据处理的方式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。它只适用于大数据的离线处理,对实时性要求很高的应用不适用。
9)停止Hadoop
[hadoop@server2 hadoop-2.7.3]$ sbin/hadoop-daemon.sh stop namenode
stopping namenode
[hadoop@server2 hadoop-2.7.3]$ sbin/hadoop-daemon.sh stop datanode
stopping datanode
[hadoop@server2 hadoop-2.7.3]$ sbin/yarn-daemon.sh stop resourcemanager
stopping resourcemanager
[hadoop@server2 hadoop-2.7.3]$ sbin/yarn-daemon.sh stop nodemanager
stopping nodemanager