Semantic Segmentation--ENet:A Deep Neural Network Architecture for Real-Time Semantic..论文解读
ENet
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
原文地址:ENet
代码:
- Introduction
- Caffe
- TensorFlow
- Keras
效果图:

Abstract
许多移动应用需要实时语义分割(Real-time Semantic Segmentation)模型,现有的深度神经网络难以实现,问题在于深度神经网络需要大量的浮点运算,导致运行时间长,从而降低了时效性。ENet即针对这一问题提出的一种新型有效的深度神经网络,相比于现有的模型,在速度加快了18×倍,浮点计算量上减少了75×,参数减少了79×,且有相似的精度。ENet在CamVid, Cityscapes and SUN datasets做了相关对比测试。
Introduction
在Semantic Segmentation领域,已经提出了几种神经网络体系结构,如SegNet或FCN。这些模型大多基于VGG架构,相比于传统方法,虽然精度上去了,但面临着模型参数多和前向推导时间长等问题,这对于许多需要10fp且长时间运行的移动设备难以实用。
本文中提出一种新的神经网络架构:ENet。优化了模型参数,保持模型的高精度和快速的前向推理时间。没有使用任何后端处理(可以配合一些后端处理,提高准确率)。在Cityscapes、CamVid、SUN dataset上做了验证,并使用NVIDIA Jetson TX1嵌入式设备和NVIDIA Titan X GPU上做了benchmark。
Related work
常见的Semantic Segmentation架构是使用两个独立的神经网络架构:一个encoder一个decoder。但是这些模型参数量太大,达不到实时要求。
有一些其他的体系使用更简单的分类器,然后使用条件随机场(CRF)最为后端处理步骤进行级联,但是这个方法难以标记小目标。CNN也可以与RNN相结合,但是这个会降低速度。
Architecture
ENet中bottleneck module
这里的bottleneck借鉴Resnet的思想,如下图:
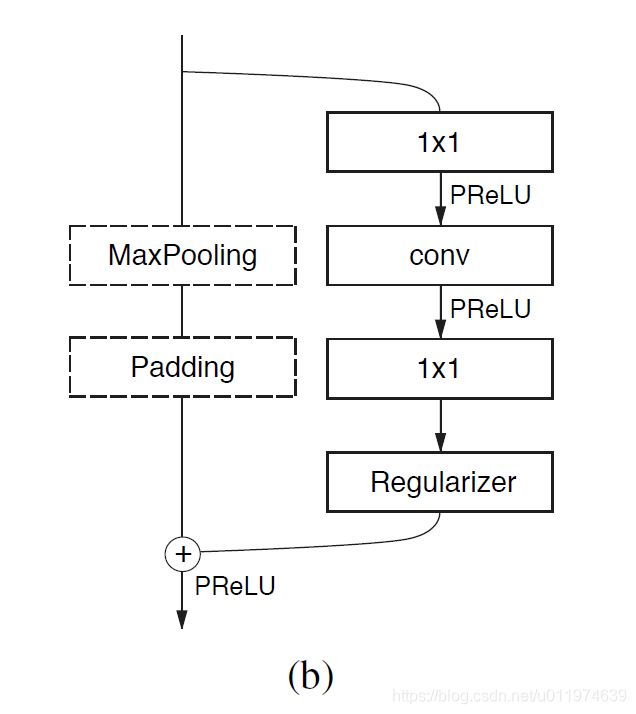
每个block共两条路线,学习残差.这里主要讲在encoder阶段的构成。
分为两种情况:
-
下采样的bottleneck:
- 主线包括三个卷积层,
- 先是 2 × 2 2 × 2 2×2投影做降采样;
- 然后是卷积(有三种可能,Conv普通卷积,asymmetric分解卷积,Dilated空洞卷积)
- 后面再接一个 1 × 1 1 × 1 1×1的做升维
注意每个卷积层后均接Batch Norm和PReLU。
- 辅线包括最大池化和Padding层
- 最大池化负责提取上下文信息
- Padding负责填充通道,达到后续的残差融合
融合后再接PReLU。
- 主线包括三个卷积层,
-
非下采样的bottleneck:
- 主线包括三个卷积层,
- 先是 1 × 1 1 × 1 1×1投影;
- 然后是卷积(有三种可能,Conv普通卷积,asymmetric分解卷积,Dilated空洞卷积)
- 后面再接一个 1 × 1 1 × 1 1×1的做升维
注意每个卷积层后均接Batch Norm和PReLU。
- 辅线直接恒等映射(只有下采样才会增加通道数,故这里不需要padding层)
融合后再接PReLU。
- 主线包括三个卷积层,
整体的架构
架构如下如下图:

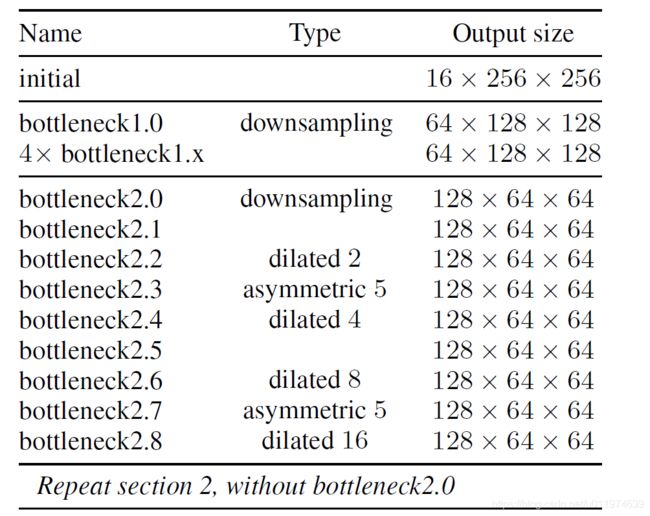
ENet模型大致分为5个Stage:
- **initial:**初始化模块,如下图:

左边是做 3 × 3 / s t r = 2 3×3/str=2 3×3/str=2的卷积,右边是做MaxPooling,将两边结果concat一起,做通道合并,这样可以上来显著减少存储空间。 - **Stage 1:**encoder阶段。包括5个bottleneck,第一个bottleneck做下采样,后面4个重复的bottleneck
- **Stage 2-3:**encoder阶段。stage2的bottleneck2.0做了下采样,后面有时加空洞卷积,或分解卷积。stage3没有下采样,其他都一样。
- **Stage 4~5:**属于decoder阶段。比较简单,一个上采样配置两个普通的bottleneck。
**模型架构在任何投影上都没有使用bias,这样可以减少内核调用和存储操作。**在每个卷积操作中使用Batch Norm。encoder阶段是使用padding配合max pooling做下采样。在decoder时使用max unpooling配合空洞卷积完成上采样。
Design choices(架构设计技巧和思想)
-
Feature map resolution
对图像的下采样有两个缺点:- 1、降低feature map resolution,会丢失细节信息,容易丢失边界信息。
- 2、semantic segmentation输出与输入有相同的分辨率,strong downsampling对应着strong upsampling,这增加了模型的size和计算量
下采样的好处在于可以获取更大的感受野,获取更多的上下文信息,便于分类。针对问题1,有两个解决方案:
- FCN的解决办法是将encoder阶段的feature map塞给decoder,增加空间信息。
- SegNet的解决办法是将encoder阶段做downsampling的indices保留到decoder阶段做upsampling使用。
ENet采用的是SegNet的方法,这可以减少内存需求。同时为了增加更好的上下文信息,使用
dilated conv(空洞卷积)扩大上下文信息。 -
Early downsampling
早期处理高分辨率的输入会耗费大量计算资源,ENet的初始化模型会大大减少输入的大小。这是考虑到视觉信息在空间上是高度冗余的,可以压缩成更有效的表示方式。
这里贴一下paper对于前期处理的观点:our intuition is that the initial network layers should not directly contribute to classification. Instead, they should rather act as good feature extractors and only preprocess the input for later portions of the network.网络的初始层不应该直接面向分类做贡献,而且尽可能的提取输入的特征。
-
Decoder size
相比于SegNet中encoder和decoder的镜像对称,ENet的Encoder和Decoder不对称,由一个较大的Encoder和一个较小的Decoder组成。
贴一下paper对于这样架构的看法:This is motivated by the idea that the encoder should be able to work in a similar fashion to original classification architectures, i.e. to operate on smaller resolution data and provide for information processing and filtering. Instead, the role of the the decoder, is to upsample the output of the encoder, only fine-tuning the details.Encoder主要进行信息处理和过滤,和流行的分类模型相似。而decoder主要是对encoder的输出做上采样,对细节做细微调整。
-
Nonlinear operations
一般在卷积层之前做ReLU和Batch Norm效果会好点,但是在ENet上使用ReLU却降低了精度。
论文分析了ReLU没有起作用的原因是网络架构深度,在类似ResNet的模型上有上百层,而ENet层数很少,较少的层需要快速过滤信息,故最终使用PReLUs。下图是权重的大概分布:

-
Information-preserving dimensionality changes
在Initial Block,将Pooling操作和卷积操作并行,再concat到一起,这将inference阶段时间加速了10倍。同时在做下采样时,原来ResNet的卷积层分支会使用 1 × 1 / s t r = 2 1×1/str=2 1×1/str=2的卷积,这会丢失大量的输入数据。ENet改为 2 × 2 2×2 2×2的卷积核,有效的改善了信息的流动和准确率。 -
Factorizing filters
将 n × n n×n n×n的卷积核拆为 n × 1 n×1 n×1和 1 × n 1×n 1×n(Inception V3提出的)。可以有效的减少参数量,并提高模型感受野。(可以参考我以前写的GoogleNet笔记Inception-V2) -
Dilated convolutions
Dilated convolutions可以有效的提高感受野。有效的使用Dilated convolutions提高了4%的IoU,使用Dilated convolutions是交叉使用,而非连续使用。 -
Regularization
因为数据集本身不大,很快会过拟合。使用L2效果不佳,使用stochastic depth还可以,但琢磨了一下stochastic depth就是Spatial Dropout的特例,故最后选择Spatial Dropout,效果相对好一点。
Experiment
论文评估了ENet在CamVid、Cityscapes、SUN RGB-D三个数据集上的基准表现。实验是与SegNet做对比,使用的是Torch7机器学习库和cuDNN后端。
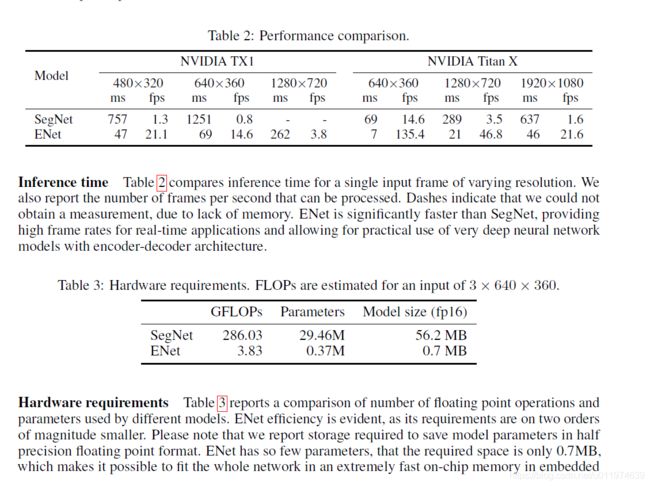
ENet的推理时间很短,快了很多。同时也报告了GPU内核本身的问题,将卷积分解,但是GPU启动的成本超过了计算的成本,这严重限制了计算时间。故可以将BN层与卷积核参数融合加速提高效率。(这是有脚本的,例如BN-absorber.py)
Benchmarks
论文给了一个Benchmarks,所有的训练细节可以参考Caffe程序:
大致的训练细节:
| 项目 | 参数 |
|---|---|
| 优化器 | Adam |
| 训练策略 | 只训练encoder,对输入做分类,再附加decoder,再分类 |
| 学习率 | 5e-4 |
| L2权重衰减 | 2e-4 |
| batch_size | 10 |
- 在CityScapes上表现:

- 在CamVid上表现:

- 在SUN RGB-D上表现:

Conclusion
ENet模型结构并不复杂,多种trick有效的降低了模型的复杂度和计算量,这里有大量的思想值得探讨。主要看下面程序实现。
ENet程序分析
为了程序看起来简洁,这里ENet程序分析选择的是Keras版本PavlosMelissinos/enet-keras。
直接看模型定义,这里看一个简化版本的Enet:
# coding=utf-8
from __future__ import absolute_import, print_function
from keras.engine.topology import Input
from keras.layers.core import Activation, Reshape
from keras.models import Model
from . import encoder, decoder
def transfer_weights(model, weights=None):
"""
Always trains from scratch; never transfers weights
:param model:
:param weights:
:return:
"""
print('ENet has found no compatible pretrained weights! Skipping weight transfer...')
return model
def build(nc, w, h,
loss='categorical_crossentropy',
optimizer='adam',
**kwargs):
data_shape = w * h if None not in (w, h) else -1 # TODO: -1 or None?
inp = Input(shape=(h, w, 3))
enet = encoder.build(inp) # encoder
enet = decoder.build(enet, nc=nc) #decoder
name = 'enet_naive_upsampling'
enet = Reshape((data_shape, nc))(enet) # TODO: need to remove data_shape for multi-scale training
enet = Activation('softmax')(enet)
model = Model(inputs=inp, outputs=enet)
model.compile(optimizer=optimizer, loss=loss, metrics=['accuracy', 'mean_squared_error'])
return model, name
关于encoder的定义:
初始化模块:

# coding=utf-8
from keras.layers.advanced_activations import PReLU
from keras.layers.convolutional import Conv2D, ZeroPadding2D
from keras.layers.core import SpatialDropout2D, Permute
from keras.layers.merge import add, concatenate
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D
def initial_block(inp, nb_filter=13, nb_row=3, nb_col=3, strides=(2, 2)):
# (512-3)/2 + 1 =256(padding=same )
conv = Conv2D(nb_filter, (nb_row, nb_col), padding='same', strides=strides)(inp)
max_pool = MaxPooling2D()(inp)
merged = concatenate([conv, max_pool], axis=3) # 直接拼接
return merged
encoder阶段使用的bottleneck模块:

def bottleneck(inp, output, internal_scale=4, asymmetric=0, dilated=0, downsample=False, dropout_rate=0.1):
# main branch 主线
internal = output // internal_scale
encoder = inp
# 1x1
input_stride = 2 if downsample else 1 #开始的1x1投影,如果是下采样则为2x2
encoder = Conv2D(internal, (input_stride, input_stride),
# padding='same',
strides=(input_stride, input_stride), use_bias=False)(encoder)
# Batch normalization + PReLU
encoder = BatchNormalization(momentum=0.1)(encoder) # enet uses momentum of 0.1, keras default is 0.99
encoder = PReLU(shared_axes=[1, 2])(encoder)
# conv
if not asymmetric and not dilated:
encoder = Conv2D(internal, (3, 3), padding='same')(encoder) # 普通卷积
elif asymmetric: # 卷积拆分 nxn-->1xn + nx1
encoder = Conv2D(internal, (1, asymmetric), padding='same', use_bias=False)(encoder)
encoder = Conv2D(internal, (asymmetric, 1), padding='same')(encoder)
elif dilated: # 空洞卷积
encoder = Conv2D(internal, (3, 3), dilation_rate=(dilated, dilated), padding='same')(encoder)
else:
raise(Exception('You shouldn\'t be here'))
encoder = BatchNormalization(momentum=0.1)(encoder) # enet uses momentum of 0.1, keras default is 0.99
encoder = PReLU(shared_axes=[1, 2])(encoder)
# 1x1
encoder = Conv2D(output, (1, 1), use_bias=False)(encoder)
encoder = BatchNormalization(momentum=0.1)(encoder) # enet uses momentum of 0.1, keras default is 0.99
encoder = SpatialDropout2D(dropout_rate)(encoder)
other = inp
# other branch 旁线
if downsample: # 如果是下采样(只有下采样,通道数才会变化)
other = MaxPooling2D()(other)
other = Permute((1, 3, 2))(other)
pad_feature_maps = output - inp.get_shape().as_list()[3]
tb_pad = (0, 0) # 填充feature map
lr_pad = (0, pad_feature_maps) # 填充通道数
other = ZeroPadding2D(padding=(tb_pad, lr_pad))(other)
other = Permute((1, 3, 2))(other)
encoder = add([encoder, other]) # 残差融合
encoder = PReLU(shared_axes=[1, 2])(encoder)
return encoder
构建encoder模型:
def build(inp, dropout_rate=0.01):
enet = initial_block(inp)
enet = BatchNormalization(momentum=0.1)(enet) # enet_unpooling uses momentum of 0.1, keras default is 0.99
enet = PReLU(shared_axes=[1, 2])(enet)
enet = bottleneck(enet, 64, downsample=True, dropout_rate=dropout_rate) # bottleneck 1.0
for _ in range(4):
enet = bottleneck(enet, 64, dropout_rate=dropout_rate) # bottleneck 1.i
enet = bottleneck(enet, 128, downsample=True) # bottleneck 2.0
# bottleneck 2.x and 3.x
for _ in range(2):
enet = bottleneck(enet, 128) # bottleneck 2.1
enet = bottleneck(enet, 128, dilated=2) # bottleneck 2.2
enet = bottleneck(enet, 128, asymmetric=5) # bottleneck 2.3
enet = bottleneck(enet, 128, dilated=4) # bottleneck 2.4
enet = bottleneck(enet, 128) # bottleneck 2.5
enet = bottleneck(enet, 128, dilated=8) # bottleneck 2.6
enet = bottleneck(enet, 128, asymmetric=5) # bottleneck 2.7
enet = bottleneck(enet, 128, dilated=16) # bottleneck 2.8
return enet
encoder阶段程序看起来较为简单~
关于decoder的定义:
decoder中用的bottleneck模块(简化版本):
# coding=utf-8
from keras.layers.convolutional import Conv2D, Conv2DTranspose, UpSampling2D
from keras.layers.core import Activation
from keras.layers.merge import add
from keras.layers.normalization import BatchNormalization
def bottleneck(encoder, output, upsample=False, reverse_module=False):
internal = output // 4 # 先把输入的通道数给降下来
x = Conv2D(internal, (1, 1), use_bias=False)(encoder)
x = BatchNormalization(momentum=0.1)(x)
x = Activation('relu')(x) # decoder的权重均值偏向于1,使用relu
if not upsample:
x = Conv2D(internal, (3, 3), padding='same', use_bias=True)(x)
else:
x = Conv2DTranspose(filters=internal, kernel_size=(3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization(momentum=0.1)(x)
x = Activation('relu')(x)
x = Conv2D(output, (1, 1), padding='same', use_bias=False)(x) # 把通道数升上去
other = encoder
# 注意到这里上采样使用Conv2D+UpSampling2D完成的
if encoder.get_shape()[-1] != output or upsample:
other = Conv2D(output, (1, 1), padding='same', use_bias=False)(other)
other = BatchNormalization(momentum=0.1)(other)
if upsample and reverse_module is not False:
other = UpSampling2D(size=(2, 2))(other)
if upsample and reverse_module is False:
decoder = x
else:
x = BatchNormalization(momentum=0.1)(x)
decoder = add([x, other]) # 残差融合
decoder = Activation('relu')(decoder) # decoder的权重均值偏向于1,使用relu
return decoder
构建decoder模型:
def build(encoder, nc):
enet = bottleneck(encoder, 64, upsample=True, reverse_module=True) # bottleneck 4.0
enet = bottleneck(enet, 64) # bottleneck 4.1
enet = bottleneck(enet, 64) # bottleneck 4.2
enet = bottleneck(enet, 16, upsample=True, reverse_module=True) # bottleneck 5.0
enet = bottleneck(enet, 16) # bottleneck 5.1
# 反卷积
enet = Conv2DTranspose(filters=nc, kernel_size=(2, 2), strides=(2, 2), padding='same')(enet)
return enet
在decoder阶段的reverse_module参数是用来构建带MaxPool信息的UpMaxPool,可参考enet_unpooling版本的实现。
到这里ENet的Keras版本程序实现算是看完了~
ENet模型复现
我在复现时看的是TimoSaemann/ENet,因为是Caffe程序,可以参考搭建Caffe环境。
准备
首先,先将ENet repository clone下来,后面要用:
git clone --recursive https://github.com/TimoSaemann/ENet.git

编译定制的Caffe框架Caffe-enet(用于支持ENet所需要的层):
cd ENet/caffe-enet
mkdir build && cd build
cmake ..
make all -j8 && make pycaffe
需要注意的是,在编译上述定制caffe-enet需要我们在编译caffe的时候取消注释:
WITH_PYTHON_LAYER := 1
并确保将python layer在PYTHONPATH定义了:
export PYTHONPATH="$CAFFE_PATH/python:$PYTHONPATH"
数据集准备
这一步比较麻烦,先从Cityscapes website上下载数据集。这需要注册账号(最好用带edu的邮箱注册).下载数据集leftImg8bit_trainvaltest.zip (11GB)和对应的标注集gtFine_trainvaltest.zip (241MB)。并clone Cityscapes的脚本:
git clone https://github.com/mcordts/cityscapesScripts.git
执行**/preparation/createTrainIdLabelImags.py**将转化对应的数据集。
将下面文件的caffe_root转为caffe-enet的绝对路径:
- ENet/scripts/BN-absorber-enet.py
- ENet/scripts/compute_bn_statistics.py
- ENet/scripts/create_enet_prototxt.py
- ENet/scripts/test_segmentation.py
将下面文件中的相关路径改为绝对路径:
- ENet/prototxts/enet_solver_encoder.prototxt
- ENet/prototxts/enet_solver_encoder_decoder.prototxt
训练模型
训练模型共分为2步:
- 训练encoder阶段
- 训练encoder+decoder阶段
训练encoder阶段:
创建网络架构文件:
python create_enet_prototxt.py --source ENet/dataset/train_fine_cityscapes.txt --mode train_encoder
创建的prototxt文件包括ENet的架构设置。可根据个人设备定制。
接下来这步是可选的,为ENet添加类权重:
python calculate_class_weighting.py --source ENet/dataset/train_fine_cityscapes.txt --num_classes 19
计算类权重,拷贝终端输出的class_weightings到enet_train_encoder.prototxt和enet_train_encoder_decoder.prototxt文件下的weight_by_label_freqs下方,并设置flag为Ture。
因为我的GPU显存不够,故先在ENet/prototxt/enet_train_encoder_decoder.prototxt下设置batchsize为1。
可以正式的训练了:
ENet/caffe-enet/build/tools/caffe train -solver /ENet/prototxts/enet_solver_encoder.prototxt
训练大约10个小时,完毕后输出如下:
I1215 21:52:47.058895 22595 sgd_solver.cpp:106] Iteration 74960, lr = 5e-06
I1215 21:52:52.798851 22595 solver.cpp:228] Iteration 74980, loss = 0.192035
I1215 21:52:52.798879 22595 solver.cpp:244] Train net output #0: accuracy = 0.771729
I1215 21:52:52.798887 22595 solver.cpp:244] Train net output #1: loss = 0.192033 (* 1 = 0.192033 loss)
I1215 21:52:52.798892 22595 solver.cpp:244] Train net output #2: per_class_accuracy = 0.83268
I1215 21:52:52.798894 22595 solver.cpp:244] Train net output #3: per_class_accuracy = 0
I1215 21:52:52.798897 22595 solver.cpp:244] Train net output #4: per_class_accuracy = 0
I1215 21:52:52.798900 22595 solver.cpp:244] Train net output #5: per_class_accuracy = 0
I1215 21:52:52.798903 22595 solver.cpp:244] Train net output #6: per_class_accuracy = 0.5
I1215 21:52:52.798907 22595 solver.cpp:244] Train net output #7: per_class_accuracy = 0.694915
I1215 21:52:52.798912 22595 solver.cpp:244] Train net output #8: per_class_accuracy = 0.423077
I1215 21:52:52.798915 22595 solver.cpp:244] Train net output #9: per_class_accuracy = 0.848837
I1215 21:52:52.798918 22595 solver.cpp:244] Train net output #10: per_class_accuracy = 0.884995
I1215 21:52:52.798923 22595 solver.cpp:244] Train net output #11: per_class_accuracy = 0.91989
I1215 21:52:52.798926 22595 solver.cpp:244] Train net output #12: per_class_accuracy = 0.980857
I1215 21:52:52.798930 22595 solver.cpp:244] Train net output #13: per_class_accuracy = 0
I1215 21:52:52.798933 22595 solver.cpp:244] Train net output #14: per_class_accuracy = 0
I1215 21:52:52.798959 22595 solver.cpp:244] Train net output #15: per_class_accuracy = 0.922049
I1215 21:52:52.798962 22595 solver.cpp:244] Train net output #16: per_class_accuracy = 0
I1215 21:52:52.798965 22595 solver.cpp:244] Train net output #17: per_class_accuracy = 0
I1215 21:52:52.798969 22595 solver.cpp:244] Train net output #18: per_class_accuracy = 0
I1215 21:52:52.798971 22595 solver.cpp:244] Train net output #19: per_class_accuracy = 0
I1215 21:52:52.798974 22595 solver.cpp:244] Train net output #20: per_class_accuracy = 0
I1215 21:52:52.798979 22595 sgd_solver.cpp:106] Iteration 74980, lr = 5e-06
I1215 21:52:58.191184 22595 solver.cpp:454] Snapshotting to binary proto file /root/模型复现/ENet/ENet/weights/snapshots_encoder/enet_iter_75000.caffemodel
I1215 21:52:58.213759 22595 sgd_solver.cpp:273] Snapshotting solver state to binary proto file /root/模型复现/ENet/ENet/weights/snapshots_encoder/enet_iter_75000.solverstate
I1215 21:52:58.319011 22595 solver.cpp:317] Iteration 75000, loss = 0.192242
I1215 21:52:58.319034 22595 solver.cpp:322] Optimization Done.
I1215 21:52:58.319037 22595 caffe.cpp:254] Optimizatio
接下来第二阶段,训练encoder+decoder阶段:
依旧是先创建模型:
python create_enet_prototxt.py --source ENet/dataset/train_fine_cityscapes.txt --mode train_encoder_decoder
还是要注意设置batchsize。
使用上面训练好的模型,接着开始训练:
ENet/caffe-enet/build/tools/caffe train -solver ENet/prototxts/enet_solver_encoder_decoder.prototxt -weights ENet/weights/snapshots_encoder/NAME.caffemodel
将NAME取代为上一阶段训练保存的的模型名称。
训练大约10个小时,完毕后输出如下:
I1216 11:13:46.340370 5167 sgd_solver.cpp:106] Iteration 74960, lr = 5e-06
I1216 11:13:58.945647 5167 solver.cpp:228] Iteration 74980, loss = 0.343889
I1216 11:13:58.945674 5167 solver.cpp:244] Train net output #0: accuracy = 0.842316
I1216 11:13:58.945682 5167 solver.cpp:244] Train net output #1: loss = 0.343885 (* 1 = 0.343885 loss)
I1216 11:13:58.945685 5167 solver.cpp:244] Train net output #2: per_class_accuracy = 0.986849
I1216 11:13:58.945688 5167 solver.cpp:244] Train net output #3: per_class_accuracy = 0.738194
I1216 11:13:58.945691 5167 solver.cpp:244] Train net output #4: per_class_accuracy = 0.976514
I1216 11:13:58.945695 5167 solver.cpp:244] Train net output #5: per_class_accuracy = 0
I1216 11:13:58.945698 5167 solver.cpp:244] Train net output #6: per_class_accuracy = 0
I1216 11:13:58.945701 5167 solver.cpp:244] Train net output #7: per_class_accuracy = 0
I1216 11:13:58.945704 5167 solver.cpp:244] Train net output #8: per_class_accuracy = 0
I1216 11:13:58.945708 5167 solver.cpp:244] Train net output #9: per_class_accuracy = 0
I1216 11:13:58.945710 5167 solver.cpp:244] Train net output #10: per_class_accuracy = 0.948243
I1216 11:13:58.945713 5167 solver.cpp:244] Train net output #11: per_class_accuracy = 0
I1216 11:13:58.945716 5167 solver.cpp:244] Train net output #12: per_class_accuracy = 0.603895
I1216 11:13:58.945719 5167 solver.cpp:244] Train net output #13: per_class_accuracy = 0.536638
I1216 11:13:58.945722 5167 solver.cpp:244] Train net output #14: per_class_accuracy = 0
I1216 11:13:58.945726 5167 solver.cpp:244] Train net output #15: per_class_accuracy = 0.975269
I1216 11:13:58.945729 5167 solver.cpp:244] Train net output #16: per_class_accuracy = 0
I1216 11:13:58.945732 5167 solver.cpp:244] Train net output #17: per_class_accuracy = 0
I1216 11:13:58.945735 5167 solver.cpp:244] Train net output #18: per_class_accuracy = 0
I1216 11:13:58.945739 5167 solver.cpp:244] Train net output #19: per_class_accuracy = 0
I1216 11:13:58.945741 5167 solver.cpp:244] Train net output #20: per_class_accuracy = 0.00182025
I1216 11:13:58.945768 5167 sgd_solver.cpp:106] Iteration 74980, lr = 5e-06
I1216 11:14:10.935374 5167 solver.cpp:454] Snapshotting to binary proto file /root/模型复现/ENet/ENet/weights/snapshots_decoder/enet_iter_75000.caffemodel
I1216 11:14:10.954293 5167 sgd_solver.cpp:273] Snapshotting solver state to binary proto file /root/模型复现/ENet/ENet/weights/snapshots_decoder/enet_iter_75000.solverstate
I1216 11:14:11.325291 5167 solver.cpp:317] Iteration 75000, loss = 0.386199
I1216 11:14:11.325314 5167 solver.cpp:322] Optimization Done.
I1216 11:14:11.325317 5167 caffe.cpp:254] Optimization Done.
root@DFann:~/模型复现/ENet/ENet/scripts#
到这里,模型算是训练结束了,至于后面的测试等功能,可参考原github的教程~
训练模型遇到的错误
错误1
错误描述:
AttributeError: 'LayerParameter' object has no attribute 'dense_image_data_param'
解决方法:
这是因为.py文件没有找到刚编译的包,指定的地址有问题。
打开create_enet_prototxt.py文件,在最前面:
# 将这个caffe_root目录指定到ENet的目录(就是一开始要改变目录的工作没有完成)
caffe_root = '/root/ENet/ENet/caffe-enet/'
错误2
错误描述:
ImportError: dynamic module does not define module export function (PyInit__caffe)
解决方法:
将默认的python从python3.6切换到python2.7完事。
错误3
错误描述:
ImportError: /lib/x86_64-linux-gnu/libz.so.1: version `ZLIB_1.2.9' not found (required by /root/anaconda3/lib/./libpng16.so.16)
解决方法:
- Download zlib version 1.2.9
- Uncompress the file
- cd to zlib-1.2.9
- Run
./configure
make
make install
错误4
错误描述:
Importing caffe results in ImportError: “No module named google.protobuf.internal” (import enum_type_wrapper)
解决方法:
pip install protobuf
# or
/home/username/anaconda2/bin/pip install protobuf