- RCNN: 直接使用object proposal 方法得到image crops 送入神经网络中,但是crops 的大小不一样,因此使用 ROI Pooling,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量,这个ROI pooling 类似普通的pooling, 但是图像大小不固定。比如某个ROI区域坐标为 (x1,y1,x2,y2) ,那么输入size为 (y2−y1)∗(x2−x1) ,如果pooling的输出size为 pooled_height∗pooled_width ,那么每个网格的size为 (y2−y1)pooled_height∗(x2−x1)/pooled_width. 但是这些 crops 之间要重复计算特征。 (代码见roi_pooling_layer.cpp中的Forward_cpu,对于backward 见下图)
- Fast RCNN: 解决RCNN中重复计算的问题,将整幅图像(push the entire image once through a feature extractor) 送入一个特征提取器中,对object proposals 在得到的feature上进行crop。 因此share the feature extraction.

但是RCNN 和 Fast RCNN都依赖于 额外的object proposal 方法。接下来,就有各种大牛提出的使用神经网络进行object proposal 的方法,然后对这些proposals(论文中叫anchors)进行分类和回归shift to fit the GT(通常通过最小化分类和回归结合的损失函数),对于一个anchor a, 首先找最好匹配的ground truth box, 如果找到了,则为‘positive anchor’,我们赋予对应的class label, encode 这个box![]() 。如果没有找到匹配的,这个anchor的label set to 0.
。如果没有找到匹配的,这个anchor的label set to 0.
if an anchor is encoding as ![]() , the loss of the anchor is:
, the loss of the anchor is:
![]() 第一部分loss 是 regression of localization 的 loss, 第二部分loss 是 classification 的loss。
第一部分loss 是 regression of localization 的 loss, 第二部分loss 是 classification 的loss。
通俗地讲,SSD,YOLO,Faster RCNN等都是在原图上预先画了很多个框框,然后判断这些框框是不是前景.这和传统的滑窗有点像,anchor代表了不同size和比例的滑窗.但feature map的感受野更大一点,特征提取的也更好.
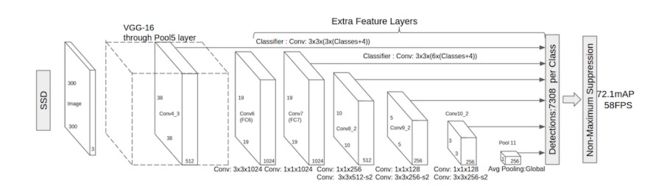
- SSD:这个方法中使用了multibox 和 RPN(faster rcnn)进行 box proposal。faster R-CNN是通过改变Anchor的大小来实现scalable的,SSD是改变Feature map大小来实现的。 将输出一系列 离散化(discretization) 的 bounding boxes,这些 bounding boxes 是在 不同层次(layers) 上的 feature maps 上生成的,并且有着不同的 aspect ratio。feature map cell 就是将 feature map 切分成 8×8 或者 4×4 之后的一个个 格子;而 default box 就是每一个格子上,一系列固定大小的 box,即图中虚线所形成的一系列 boxes。产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性。

-
-
损失函数:这个与Faster R-CNN中的RPN是一样的,不过RPN是预测box里面有object或者没有,所以,没有分类,SSD直接用的softmax分类。location的损失,还是一样,都是用predict box和default box/Anchor的差 与 ground truth box和default box/Anchor的差 进行对比,求损失。
YOLO 和 SSD
-
-
-
-
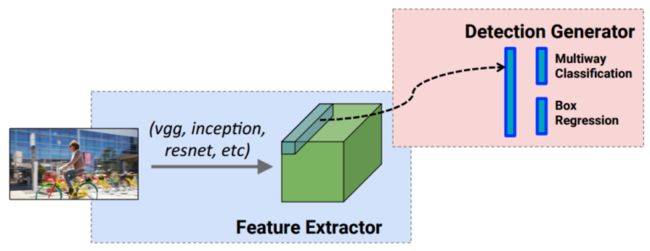
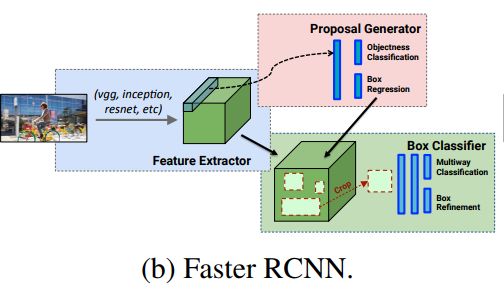
- Faster RCNN: detection happens in two stages. the first one is region proposal network(RPN). the second stage, the box proposals are used to crop features from the conv5 to feed to the remainder nets(fc6 and fc7) in order to predict the class and box refinement. (each anchors obtained by RPN, would be duplicated computated. so the running time depends on the number of regions proposed by RPN).
RPN 详解:
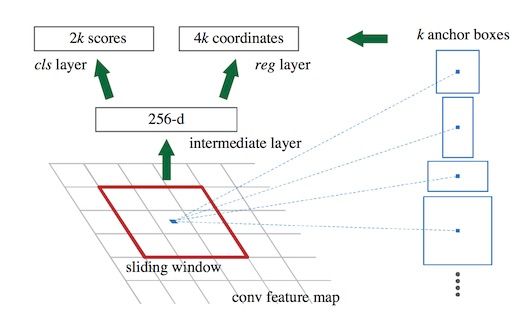
论文中将 conv5 得到的feature map手动划分为n*n的矩形框(从SSD 学习得到)(论文中设为n=3,3虽然很小,但是在高层feature map的size也很小,因此矩形框可以感知很大范围)。 准备后续选取proposals,对每个矩形窗口的中心点当做一个基准点, 然后绕着这个基准点选取k(k=9)个不同scale , aspect ratio 的anchor(论文中3个scale,3个aspect ratio)对于每个anchor在后面使用softmax进行二分类, 有两个score输出用来表示是一个物体的概率和不是一个物体的概率, 然后再接上一个bounding box 的regressor。
但是RPN也有缺点,最大的问题就是对小物体检测效果很差,假设输入为512*512,经过网络后得到的feature map是32*32,那么feature map上的一个点就要负责周围至少是16*16的一个区域的特征表达,那对于在原图上很小的物体它的特征就难以得到充分的表示,因此检测效果比较差。但是 SSD相当好一些,因为它可以理解有multi-scale 的RPN。而最后一层的feature map往往都比较抽象,对于小物体不能很好地表达特征,而SSD允许从CNN各个level的feature map预测检测结果,这样就能很好地适应不同scale的物体,对于小物体可以由更底层的feature map做预测。这就是SSD和RPN最大的不同,其他地方几乎一样。
rpn二分类,是在conv4 这一层feature map上再进行1x1的卷积生成512-d或256-d的向量判断当前9个anchor是不是有Object.
SSD细分类,然后会在多层feature map上面预测,预测预先确定好了'anchor'是什么Object.弥补了yolo只在最后一层分成7x7的框,捡了许多漏检的.
RPN的loss函数可以表示为:

在训练时,要选择正负样本,不然负样本过多,对正样本的预测准确率很低。多任务训练,提出来不同的方法:
1)alternating training训练时,先独立训练RPN,然后用RPN的网络权重对Fast RCNN网络进行初始化,并用RPN输出的proposal作为Fast RCNN的输入,不断迭代这个过程。
2) approximate joint training: 将RPN与 Fast RCNN 融入一起训练。 ignore the derivative of the proposal boxes
3) Non- approximate training: 对立与上一种方法。不ignore。
- YOLO: Faster RCNN需要对anchor box进行判断是否是物体,然后再进行物体识别,分成了两步。
YOLO(You Only Look Once)则把物体框的选择与识别进行了结合,一步输出,即变成”You Only Look Once”。 加快速度的YOLO带来了一定的局限性,由于出事图片需要被缩放到固定大小,可能对不同缩放比例的物体覆盖不全,每一个单元格只能用来选择一个物体框,并只预测一个类别,所以当多个物体中心落入一个单元格使,YOLO无法识别到小物体。- 把缩放成统一大小的图片分割成S×S的单元格
- 每一个单元格负责输出B个矩形框,每一个框带四个位置信息(x, y, w, h),与一个该框是物体的概率,用Pr(Object)或者C(Confidence)表示
- 每一个单元格再负责输出C个类别的概率,用Pr(Class∣Object)表示
- 最终输出层应有S×S×(B∗5+C)个单元
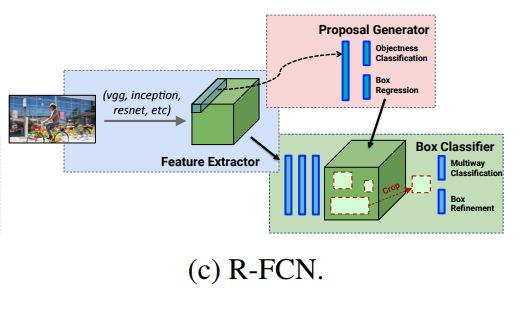
- R-FCN
Faster RCNN 中最后fc6 和 fc7 的特征计算是重复计算,在R-FCN提出了一种提高的方法。将Crop放在网络的最后相当于网络中没有fully connect layer,所有都是用convolutional layer 实现。