zeromq - 消息传输性能测试
http://zeromq.org/whitepapers:measuring-performance
简介
性能测试的两个基本原因:
首先,我们希望有一些数字来营销我们的消息传输系统;其次,我们需要一个诊断工具,以帮助我们消除在产品开发过程中的性能问题。至于营销数字,我们希望说,例如,我们能每秒钟传输50万个512字节的消息,延迟时间达100微妙。
然而,如果提供更多的关于系统的行为将是更好的:延迟是否有峰值?如果有,它们多久会发生一次? 峰值有多高? 同样,对于吞吐量: 有峰值吗?多久会有一次?有多高?
我们还想显示性能是如何随着消息的大小而变化的: 消息是1字节时性能是多少?1 MB 时性能是多少? 我们想演示CPU对系统的影响:处理器为单核时性能是多少?双核时是多少?处理器的频率对性能的影响是怎样的?消息是否会使用100%的处理器时间?
测量多种网络架构对性能的影响也是很好的:使用1Gb网络与100Mb的网络有什么却别吗?如果是无限带宽的情况呢?当使用loopback接口,而不是常规的网络连接时,系统的行为会怎样?
为了诊断的发展,一种别样的性能测量是必要的。我们感兴趣的是整个延迟和吞吐量的曲线,而不是计算总计数字。我们感兴趣的是延迟峰值在哪儿发生,而不是延迟峰值是否发生。是在测试开始时?还是在开销增加时?延迟峰值是不是只针对最后几个消息?等等。
一般原则
- 我们测量的系统是离散的。消息离开和到达在一个单独的时间点(至少我们是这么衡量的)。因此,我们不能假设延迟和吞吐量曲线是连续的——根据规则,他们都是非连续的。因此,我们无法衡量一个特定时间点的量延迟和吞吐量。这是不确定的。然而,我们可以测量一个特定消息(s)的延迟和吞吐量。
- 不同物理box上的时钟是不同步的。我们不能想当然的认为,在我们需要的精度下(微妙,甚至是纳秒),不同机器上的时钟是同步的。因此,我们必须把在不同box上测量的时间当做在不同单元上测量的,即,我们不能从一个box上测量的时间减去在另一个box上测量的时间来获得时间间隔——这种操作是不确定的。然而,在不同box上测得的时间间隔是兼容的,我们执行任何种类的操作(加法,减法,等等)。
术语
- N :测试中消息的数量
- On :第n个消息被发送时的时间
- In :第n个消息被接收时的时间
- Ln :第n个消息的延迟(s)
- SOn :第n个消息的发送开销(s)
- ROn :第n个消息的接收开销(s)
- STn :当第n个消息正在被发送时的吞吐量(msg/s)
- RTn :当第n个消息正在被接收时的吞吐量(msg/s)
- SCn :当第n个消息正在被发送时的发送者的CPU使用率(%)
- RCn :当第n个消息正在被发送时的接收者的CPU使用率(%)
- BCn :当第n个消息正在被发送时的broker的CPU使用率(%)
模型
由于在不同box上时钟是不同步的,我们必须同时测量在同一个box的 On 和 In,即发送者和接收者必须在同一台机器上运行。
为了能够测量真实的网络的性能,因此,我们必须增加一个中间box(“ broker ”)的模型。
测试应用程序因此应该这样工作:
- On 和 SCn被测量,消息由发送者发送给broker
- BCn被测量,消息由broker发送给接收者(万一broker是不平凡的,我们也可以测量消息在broker中的时间消耗——也就是说消息在队列中的时间消耗)
- In和RCn被测量,接收者。
最小化测量噪声,应满足以下条件:
- 有一个单独的处理器/核,致力于发送者,以避免其他进程对测量的干扰
- 有一个单独的处理器/核,致力于发送者,以避免其他进程对测量的干扰
- 有一个单独的处理器/核,致力于接收者,以避免其他进程对测量的干扰
- 有一个单独的网络,致力于测量,以避免其他网络流量对测量的干扰
- 测量的值必须存储在预先分配的内存中,而不是在一个文件中,以避免I/O操作队测量的干扰
- 发送者和接收者与代理有独立的连接,以减少相互阻塞。此外,相同的原因,发送者和接收者应该在单独线程中执行。
- 任何统计计算应该在所有的测试已经结束后执行,以避免对测量结果的影响。
测量延迟
延迟测量很容易。发送者和接收者在同一个box上,我们不必关心时钟同步问题。延迟是发送消息和接受消息之间的时间间隔:
![]()
注意:延迟测量时针对一个特定的消息,而不是一个特定的时间点。
测量吞吐量
测试中,虽然有一个显而易见的方法去计算吞吐量,跨度几千个消息
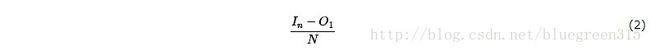
当测试中消息数量减少到1时,这个指标变得几乎是没用的。消息数量越少,上式计算结果的值更多地倾向于延迟,更小地倾向于吞吐量。事实上,当N=1是,结果完全等于延迟。
产生这个问题的原因在于,没有一个方法能一致地聚集发送率和接收率成为一个单独的“吞吐量”这样一个度量。为了解决这个问题,我们将发送率(STn)和接收率(RTn)分开来单独对待。
为了获得真实的数字,我们将首先计算“发送开销” (SOn)和“接受开销” (ROn),前者是发送消息需要的时间,后者是接收消息需要的时间:
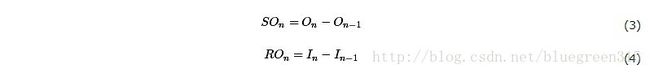
发送者吞吐量可以表示为发送者开销的倒数,接收者的吞吐量表示为接收者开销的倒数:

考虑两个消息,第一个在从测试开始后4.5秒后被发送,第二个在从测试开始后4.7秒后被发送。发送者开销是0.2秒,意味着发送者在发送第二个消息之前需要0.2秒去全速处理第一个消息。为了推断这个值(如果开销不变,我们1秒钟可以发送多少个消息?),我们必须计算相反数:1 / 0.2 = 5 。因此,发送者开销是每秒钟5个消息。
注意,发送者吞吐量和接收者吞吐量都是为特定消息测量的,不是为特定时间点测量的。
然而,当吞吐量非常大的时候,这个方法有一个问题。考虑时间是以微秒计算的,因为大多数情况是在Linux系统上完成的。在这种情况下,随后的两个消息之间的时间间隔可以是1微秒,2微秒,3微秒,4微秒,等等。取这个值得倒数,我们将获得可能的吞吐量值是每秒1,000,000个消息,500,000个消息,333,333个消息,250,000个消息,等等。
这对于任何应用来说都是很粗糙的。此外,如果两个消息在同一微秒内被处理,吞吐量将是不确定的(除数为0)。
解决的方案是测量纳秒级的时间。这种方式将是非常精确的,即使吞吐量超过每秒1,000,000个消息。然而,大多数的操纵系统在测量时间时都是不支持这个数量级的精度的。因此,我们必须使用M个消息代替只用其中2个消息的方法来测量吞吐量。(注意,上述描述的简单的吞吐量测量,只是通用方法中“M=1"这样一个特殊的情况下的。)

请注意,对于M个初始消息,吞吐量是不确定的,因此,为了获得合理的结果,N的量级应该大于M。为了理解M的值对于吞吐量测量的影响,请看下图:
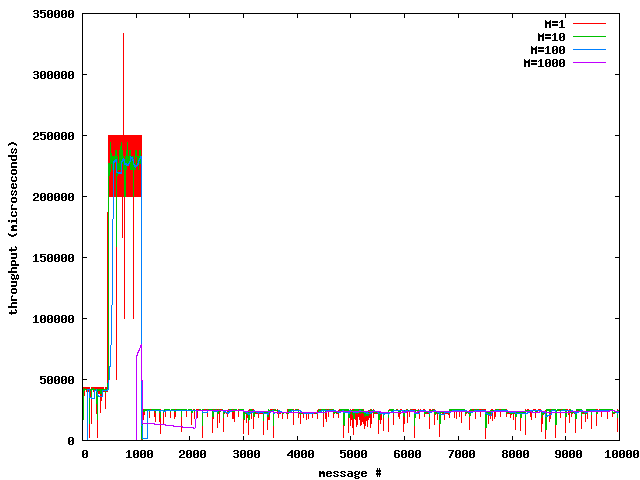
由图可以看出,小的M,吞吐量量曲线震荡很大,而对于大的M,吞吐量遇到临时峰值时,曲线是不敏感的。 M在中值范围(约100)看起来是最全面的图。
延迟和吞吐量之间的关系
理解延迟和吞吐量是非常重要的,并且他们不是独立的度量,相反地,他们是观察数据的两种方式。 这一段解释了两者之间的关系。(我们将使用开销度量代替吞吐量,因为开销的公式更简单一些,况且,开销是吞吐量的倒数,所以是没有什么区别的。)
考虑延迟的定义 ,发送者的开销和接收者的开销,并做一些简单地代数运算,我们将得到下面的公式(公式1,3,4的转换):
![]()
我们可以认为公式右边是离散的,公式也可以表示为:
换句话说,发送者的开销和接收者的开销在特定点的差值决定延迟曲线是稳定,还是上升的,还是下降的。
在吞吐量方面:
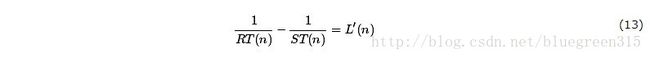
你可以把这个公式作为”排队系统”的通用模型。如果发布者发送消息比消费者接收消息快,消息必须在途中被“排队”,从而增加了延迟时间(在一个“队列”中的时间花费是延迟的一部分)。另一反面,如果发布者发送消息比消费者接收消息慢,“队列”的大小会逐渐下降,同时改善延迟。如果发送和接收率相同,“队列”的大小是静态的,并且延迟是稳定的。
测量CPU使用率
对于CPU使用率的测试,三个参与者(发送者、接收者、broker)应该单独测试,而不考虑事实上发送者和接收者是运行在一个box上。broker的CPU使用率放在消息体中被发送给接收者,让所有的测量结果集中在一个box上。
和其他测量一样,CPU使用率测量的是一个特定的消息,而不是一个特定的时间点。这种方式测量CPU使用率存在一个问题:如果我们是在消息生命周期的特定时刻测量CPU使用率,那是不是意味着我们将永远不会测量生命周期中其他部位的CPU负载了呢?
为了避免这个问题,我们应该确保用于测量CPU使用率的窗口至少和在当前box上执行的消息生命周期的一部分的间隔一样宽。这样,将不会有任何时间片未被测量的情况。
做到这一点的理想的办法是,衡量时钟滴答的次数,处理器在执行的进程中已花费的,在每个消息当前时间 (Tn)的问题 (Un)上,。对特定消息 (Cn),CPU使用率可以用如下公式计算:
![]()
上式显示,CPU使用率计算,要么说是过于消耗资源,并且在相当大的程度上扭曲了测量,要么说用时钟滴答来获得一个单一消息的合理的CPU负载值是非常不精确的。
这两个问题可以通过只测量第n个(比如第100个)消息的Cn,并且假设负荷均匀分布在100个消息之内。
上述推理适用于任何松散的辅助测量的测试——比如说网络利用率测试,中介路由器的负载,其他middle-box等等。
Computing Aggregates
通过测量足够数量的消息后,我们可以获得以下所有测量值的聚集(延迟,发送者吞吐量,接收者吞吐量,CPU使用率,等等):
average
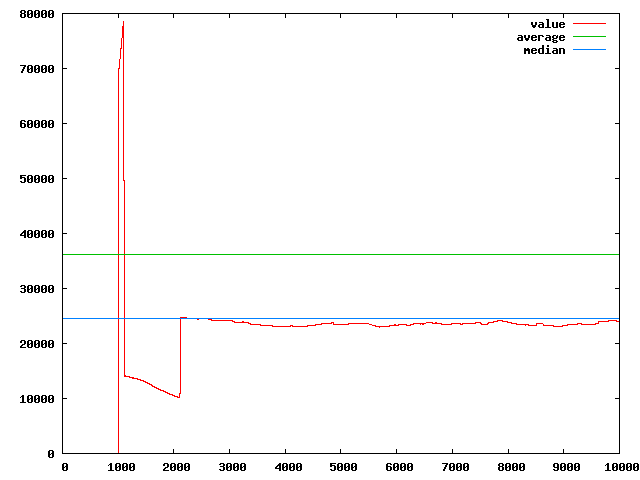
使用均值来表达系统的整体性能是非常有用的。对于用户没有做任何详细的分析,这是消息传输系统性能从长远来看将会如何出现的。然而,他的性能是多峰值的,平均值可能不对英语任何实际的测量值。有些值可能会低于平均值,而另一些可能会高于平均值。计算平均值使用如下公式:
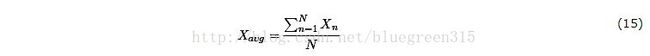
median
中值用于忽略偶然的峰值,测量“正常的性能”。注意,虽然中值在性能或多或少稳定,仅仅偶尔出现峰值时很好地工作,但是当性能在几个替代之附近震荡时,中值就变得相当武断。中值是测量结果按照升序排序的序列中的第N/2个值。如果序列中有偶数个值,就有两个中值,然而,在我们的测试中,我们将会忽略第二个并且仅仅考虑较低的一个中值。
standard robust deviation
Standard robust deviation是图形中“peakiness"的一个度量。峰值的高度和峰值的密度都考虑在内。它可以被认为是峰值高度的平均值。计算Standard robust deviation使用如下公式。可选的”peakiness"度量可以做中值之差的平凡根,或是聚集之后的平方根。我们也可能测量中值的峰值高度去获得“正常波动值X”的值,无视任何“异常”峰值。

percentiles
percentiles是把样本分成两份。比如第99 percentile是较低的值,形成样本的99%,大的值形成样本的1%。特别地,第55 percentile等于中值。
为了理解均值和平均值的区别,见下图:
参数aggregates
有时候我们对取决一个特定参数的特定aggregate值的改变很感兴趣。比如,我们想知道传输不同大小的消息对延迟的影响:6字节消息对延迟的影响是多少?100字节的呢?1KB的呢?
虽然从终端用户的角度来看,只对消息大小这一参数感兴趣,在开发的过程中,我们可能对不同缓冲区大小,批处理大小的影响感兴趣,等等。
一个参数aggregate的例子如下。改图依赖于以消息大小计算的吞吐量中值(同时以字节和消息数来测量):
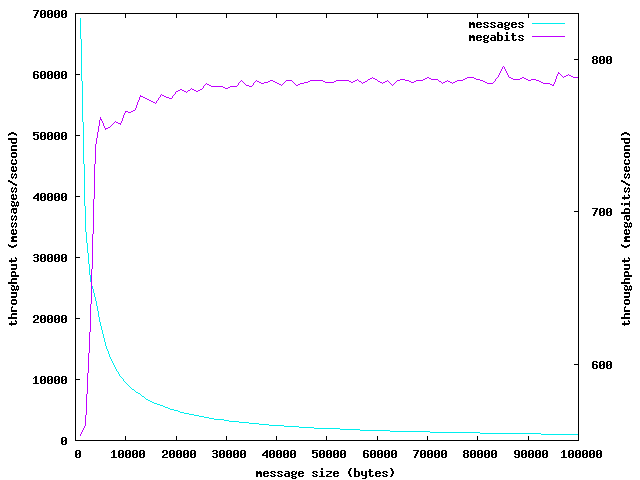
应当指出,消息尺寸与其他应用的参数有一点不同。而在消息大小不变的吞吐量测试上,以每秒钟消息数 和 每秒钟字节数来看, 是同构的,我们可以把他们作为相同度量的两个表示,在测试中,消息大小是一个参数,两个吞吐量变得不同,甚至在某些情况下互为倒数。随着消息尺寸的增长,每秒钟消息数减少 。然而,随着消息尺寸的增长,每秒钟字节数增长,直到接近网络带宽值。
Distributions
Distribution是在测试中用来描述不同值多久出现一次的一种方式。如果我们关心低延迟多久发生,中延迟多久发生,延迟峰值的密度如何,distribution图将会很有用。
在理想的情况下distribution是正常的——以钟形曲线表示。显然,钟形曲线应该尽可能地窄(宽的钟形曲线意味着无数的峰值)。
然而,有时候distribution可能有多个驼峰而不是单一的。这种情况下,被测量的值往往在几个不同的引力中心附近震荡。换句话说,这意味着延迟1小时约震荡0.3ms,然而,下一小时,震荡将会约1.6ms。消息系统的这种行为是及其不可取的,因此在软件测试中,我们应该检查多个驼峰分布。
Distribution可以表示成直方图。在直方图里,没有bins数量的理想的值,多少重叠。不同的值可以解释该系统的不同特征。在这方面应该做更多的调查研究。
另外,我们可能要设计一个“humpiness”度量,这将使我们自动衡量humpiness,而不是通过手工检查直方图。
读图
我们的性能测试中被格式化的输出方式对gnuplot工具是可读的。这种方式,你可以快速、高效的方式检查图表。
延迟
延迟图:
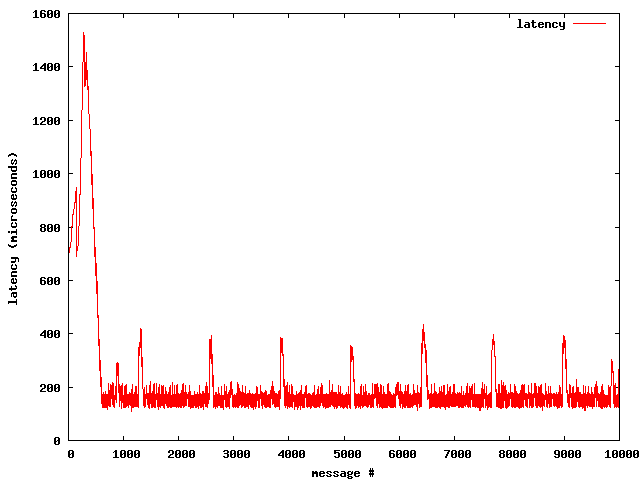
测试中有10,000个消息,图中显示了每一个消息的延迟。我们可以看出,前500个消息的延迟是相当差的(高达1,500微秒),之后稳定在大约150微秒,偶尔峰值可达400微秒。
看待数据的另一种方式,直方图:
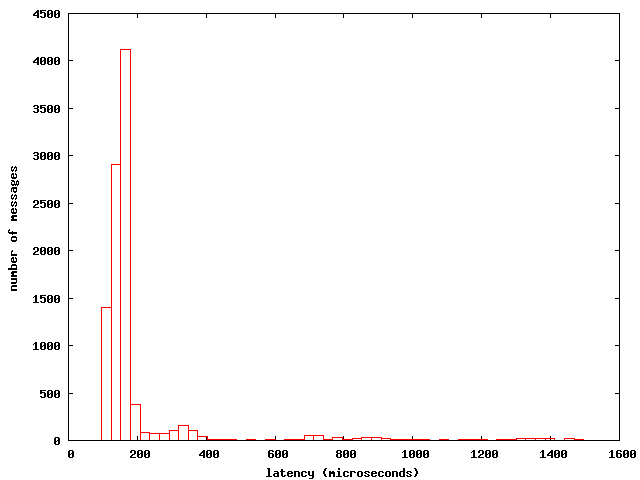
从图中可以看出,大部分的消息(超过4000个)被传输的延迟接近150微秒。在340微秒的地方有一个小驼峰,这意味着,这么高的峰值不是很经常(出现160次),但仍有超过250微秒的峰值(75次),提示,在应用中有一些问题使得延迟偶尔从150微秒上升到340微秒。
吞吐量
前面已经解释过了,没有单一的吞吐量的值——他们有两个。因此,将两个吞吐量曲线绘制成一个单一的图形是有意义的。发送者吞吐量和接收者吞吐量的趋势非常接近。
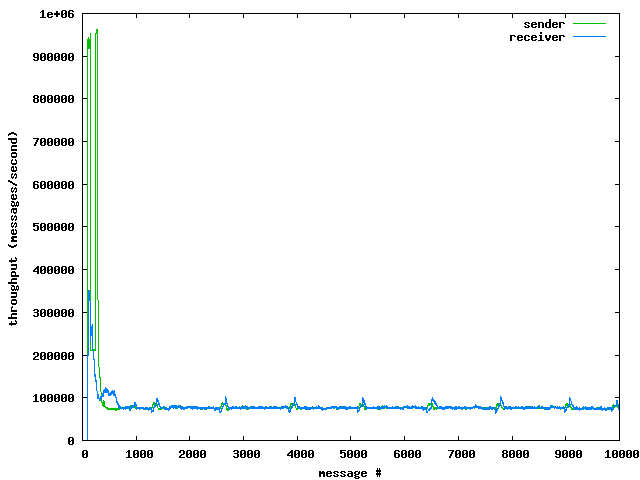
我们可以看到,发送者和接收者的吞吐量的不同在测试开始时。这似乎表明,有一种缓冲涉及较低层的堆栈。然而,500个消息之后,发送者和接收者吞吐量都变得稳定,大约每秒75000个消息,偶尔峰值会降到每秒50,000个消息,升到每秒100,000个消息。
注意gnuplot工具允许你检查有趣的图形细节图:
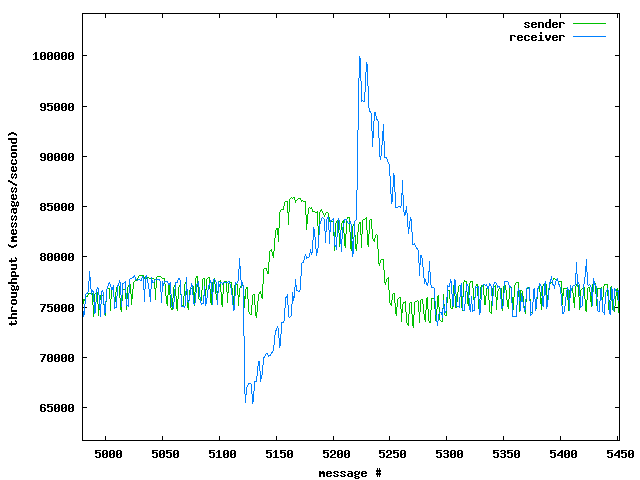
我们以检查延迟时间直方图的方式检查吞吐量直方图,这当然是可能的。
结论
我们的目标是建立一个测试环境,能够测量上述所有的指标。环境也应该是与执行无关的,即他应该是能够检测各种通讯软件,包括从最原始的TCP/IP 到 最先进的商业实现。