ZeroMQ介绍
ZeroMQ概述
消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。目前使用较多的消息队列有ZeroMQ外、Rabbit MQ、Kafka MQ等。ZeroMQ是个轻量级消息内核。
1、异步处理
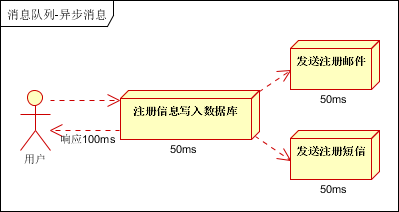
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种(1)串行的方式;(2)并行方式
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。
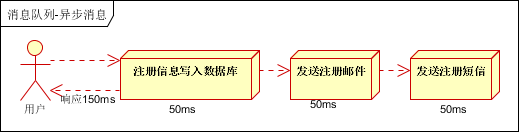
(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
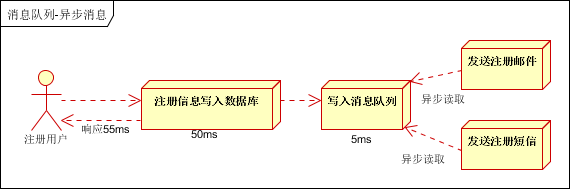
(3)引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
2、应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图:
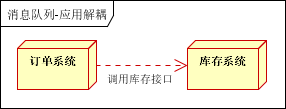
传统模式的缺点:假如库存系统无法访问,则订单减库存将失败,从而导致订单失败,订单系统与库存系统耦合。
引入应用消息队列后的方案,如下图:

订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功;
库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作;
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
ZeroMQ是一种基于消息队列的多线程网络库,其对套接字类型、连接处理、帧、甚至路由的底层细节进行抽象,提供跨越多种传输协议的套接字。ZeroMQ是网络通信中新的一层,介于应用层和传输层之间(按照TCP/IP划分),其是一个可伸缩层,可并行运行,分散在分布式系统间。
ZeroMQ将消息通信分成4种模型,分别是一对一结对模型(Exclusive-Pair)、请求回应模型(Request-Reply)、发布订阅模型(Publish-Subscribe)、推拉模型(Push-Pull)。
python demo
官方的python demo(其他语言demo详见https://github.com/zeromq/zeromq.org/tree/master/content/languages)如下:
server
#
# Hello World server in Python
# Binds REP socket to tcp://*:5555
# Expects b"Hello" from client, replies with b"World"
#
import time
import zmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5555")
while True:
# Wait for next request from client
message = socket.recv()
print("Received request: %s" % message)
# Do some 'work'
time.sleep(1)
# Send reply back to client
socket.send(b"World")client
#
# Hello World client in Python
# Connects REQ socket to tcp://localhost:5555
# Sends "Hello" to server, expects "World" back
#
import zmq
context = zmq.Context()
# Socket to talk to server
print("Connecting to hello world server…")
socket = context.socket(zmq.REQ)
socket.connect("tcp://localhost:5555")
# Do 10 requests, waiting each time for a response
for request in range(10):
print("Sending request %s …" % request)
socket.send(b"Hello")
# Get the reply.
message = socket.recv()
print("Received reply %s [ %s ]" % (request, message))
1. Request-Reply模式:
客户端在请求后,服务端必须回响应

server:
#!/usr/bin/python
#-*-coding:utf-8-*-
import time
import zmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5555")
while True:
message = socket.recv()
print message
#time.sleep(1)
socket.send("server response!")client:
#!/usr/bin/python
#-*-coding:utf-8-*-
import zmq
import sys
context = zmq.Context()
socket = context.socket(zmq.REQ)
socket.connect("tcp://localhost:5555")
while(True):
data = raw_input("input your data:")
if data == 'q':
sys.exit()
socket.send(data)
response = socket.recv();
print response2. Publish-Subscribe模式:
广播所有client,没有队列缓存,断开连接数据将永远丢失。client可以进行数据过滤。
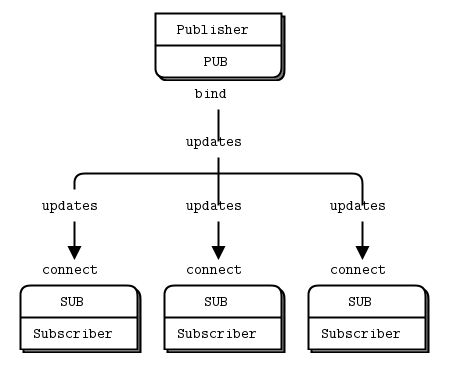
server (Publisher):
#!/usr/bin/python
#-*-coding:utf-8-*-
import zmq
context = zmq.Context()
socket = context.socket(zmq.PUB)
socket.bind("tcp://127.0.0.1:5000")
while True:
msg = raw_input('input your data:')
socket.send(msg)client (Subscriber):
#!/usr/bin/python
#-*-coding:utf-8-*-
import time
import zmq
context = zmq.Context()
socket = context.socket(zmq.SUB)
socket.connect("tcp://127.0.0.1:5000")
socket.setsockopt(zmq.SUBSCRIBE,'')
while True:
print socket.recv()3. Parallel Pipeline模式:
由三部分组成,push进行数据推送,work进行数据缓存,pull进行数据竞争获取处理。跟Publish-Subscribe的区别在于存在一个数据缓存和处理负载。当连接被断开,数据不会丢失,重连后数据继续发送到对端。

server (Worker):
#!/usr/bin/python
#-*-coding:utf-8-*-
import zmq
context = zmq.Context()
recive = context.socket(zmq.PULL)
recive.connect('tcp://127.0.0.1:5557')
sender = context.socket(zmq.PUSH)
sender.connect('tcp://127.0.0.1:5558')
while True:
data = recive.recv()
sender.send(data)client1 (Ventilator):
#!/usr/bin/python
#-*-coding:utf-8-*-
import zmq
import time
context = zmq.Context()
socket = context.socket(zmq.PUSH)
socket.bind('tcp://*:5557')
while True:
data = raw_input('input your data:')
socket.send(data.encode('ascii'))client2 (Sink):
#!/usr/bin/python
#-*-coding:utf-8-*-
import zmq
context = zmq.Context()
socket = context.socket(zmq.PULL)
socket.bind('tcp://*:5558')
while True:
data = socket.recv()
print(data.decode('ascii'))
参考:
[1] 消息队列mq总结
[2] ZeroMQ之push/pull模式
[3] ZeroMQ - 三种模型的python实现