LinkedHashMap源码解析
LinkedHashMap是继承HashMap的,大部分的实现还是由HashMap中的代码来实现的.从听说
LinkedHashMap的时候,只是知道它是一个有序的map集合,它是怎么做到有序的呢,看看它的源码吧.
LinkedHashMap如何排序的
public static void main(String[] args) {
LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("a","aa");
linkedHashMap.put("d","dd");
linkedHashMap.put("c","cc");
linkedHashMap.put("b","bb");
for(Map.Entry<String,String> set :linkedHashMap.entrySet()){
System.out.println("key: "+set.getKey() +","+ "value: "+set.getValue());
}
}
结果:
key: a,value: aa
key: d,value: dd
key: c,value: cc
key: b,value: bb
是按照put的顺序输出的
public static void main(String[] args) {
LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap<>(16,0.75f,true);
linkedHashMap.put("a","aa");
linkedHashMap.put("d","dd");
linkedHashMap.put("c","cc");
linkedHashMap.put("b","bb");
linkedHashMap.put("a","AA");
linkedHashMap.get("d");
for(Map.Entry<String,String> set :linkedHashMap.entrySet()){
System.out.println("key: "+set.getKey() +","+ "value: "+set.getValue());
}
}
结果:
key: c,value: cc
key: b,value: bb
key: a,value: AA
key: d,value: dd
最新操作过的元素会排在最后面
LinkedHashMap储存结构
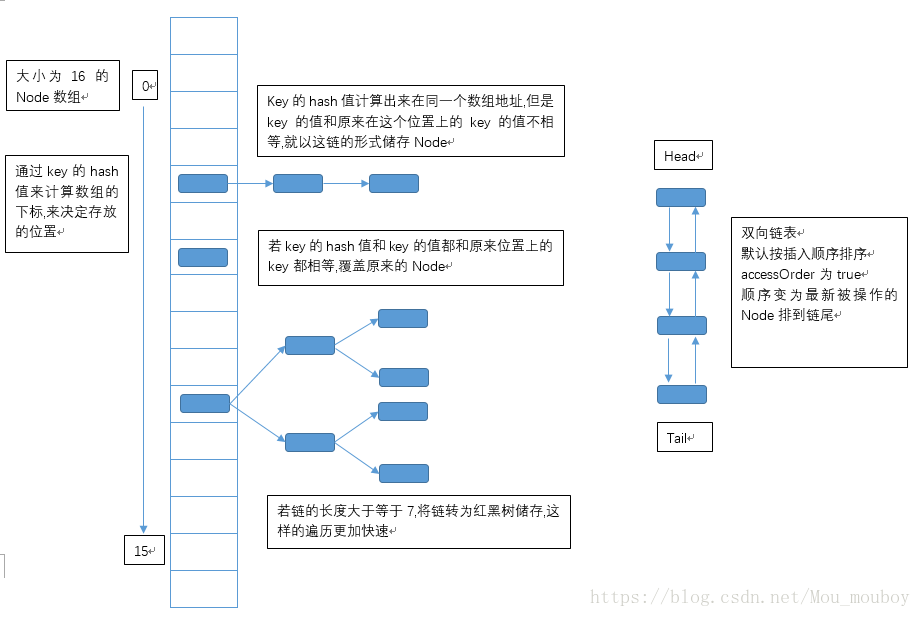
初始化LinkedHashMap
LinkedHashMap<String,String> map = new LinkedHashMap<>();
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
put方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict{
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
get方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
remove方法
调用的是HashMap的remove方法,LinkedHashMap重写了afterNodeRemoval()方法
void afterNodeRemoval(Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}