2019年CS224N课程笔记-Lecture 18:Constituency Parsing
资源链接:https://www.bilibili.com/video/BV1r4411f7td?p=18
正课内容
1. The spectrum of language in CS
词袋模型<-------------------------- ----- -------------------->复杂形式的语言表达结构
这是真.词‘袋’
语言的语义解释——不仅仅是单词向量
我们怎样才能弄清楚更大的短语的含义?例如:
- The snowboarder is leaping over a mogul
- A person on a snowboard jumps into the air
The snowboarder在语义上相当于A person on a snowboard,但它们的字长不一样
人们之所以可以理解 A person on a snowboard ,是因为the principle of compositionality组合原则,人们知道每个单词的意思,从而知道了 on a snowboard 的意思,知道组件的含义并将他们组合成为更大的组件,人们通过较小元素的语义成分来解释较大文本单元的意义 - 实体,描述性术语,事实,论点,故事,如下图:(小部件组成大机器)


语言理解 - 和人工智能 - 需要能够通过了解较小的部分来理解更大的事物
语言是递归的吗?
认知上有点争议(需要指向无穷大),但是:递归对于描述语言是很自然的,例如
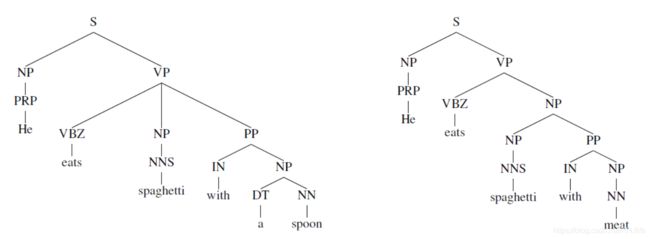
[The person standing next to [the man from [the company that purchased [the firm that you used to work at]]]]
上例包含名词短语的名词短语,包含名词短语,它是语言结构的一个非常强大的先验,如下图
2. 基于词向量空间模型的构建
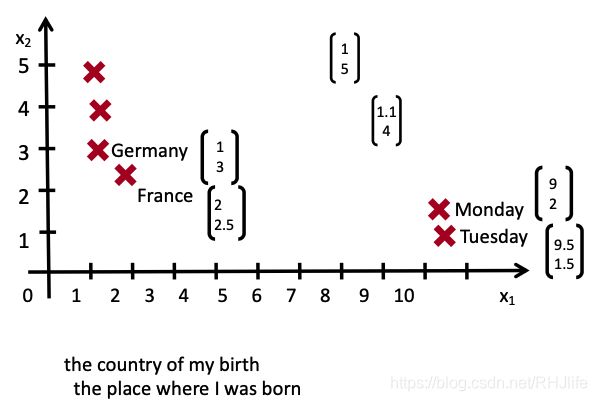
我们怎样表示更长短语的意思呢?
通过将他们映射到相同的向量空间!
我们应该如何将短语映射成向量空间?

组合性使用原则
句子的意思(向量)由以下因素决定:(1) 单词的含义和(2)组合它们的规则。
本节中的模型可以共同学习解析树和组合向量表示
选区句子分析:我们想要什么

学习结构和表现
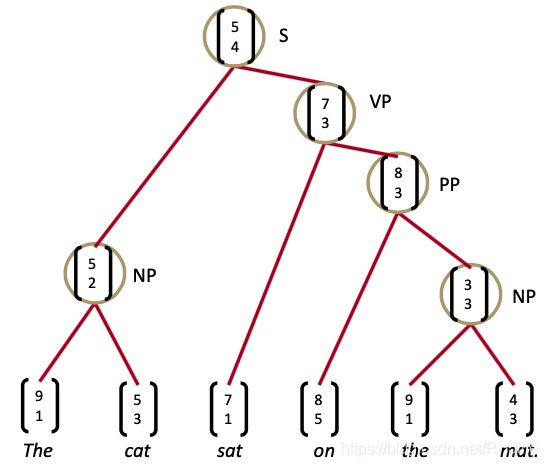
我们需要能够学习如何解析出正确的语法结构,并学习如何基于语法结构,来构建句子的向量表示
递归神经网络与循环神经网络
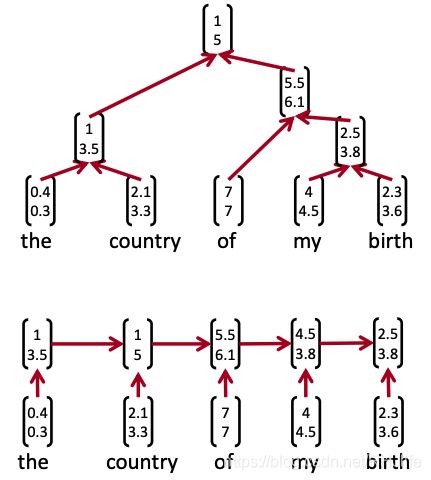
递归神经网络需要一个树结构,而循环神经网络不能在没有前缀上下文的情况下捕捉短语,并且经常在最终的向量中过度捕捉最后一个单词
递归神经网络在结构预测中的应用
如果我们自上而下的工作,那么我们在底层有单词向量,所以我们想要递归地计算更大成分的含义
输入:两个候选的子节点的表示
输出:
- 1、两个节点合并后的语义表示
- 2、新节点的合理程度

递归神经网络定义
(可能认为这不是一个完美的意义构建的模型)

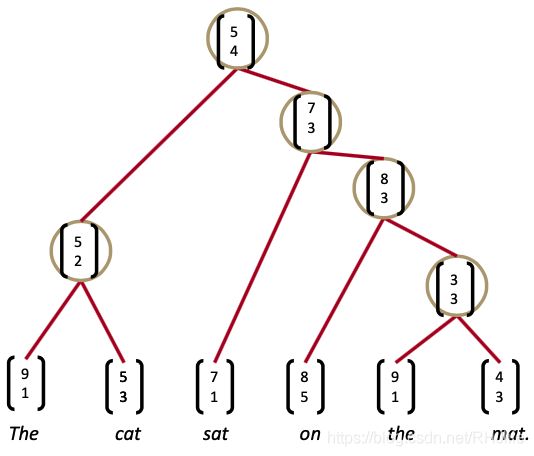
用RNN解析句子(贪婪地)
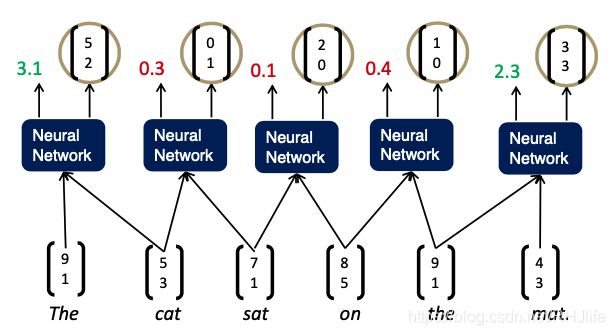
分析句子
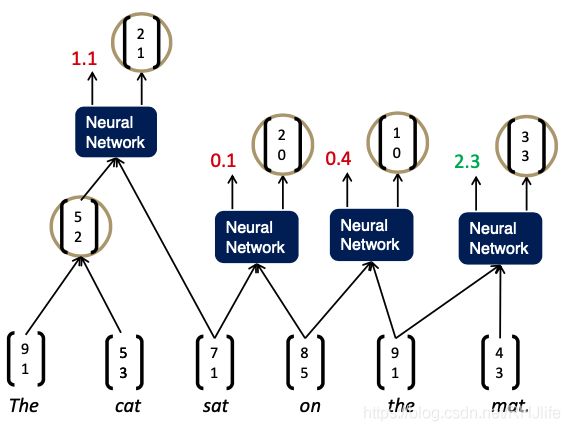
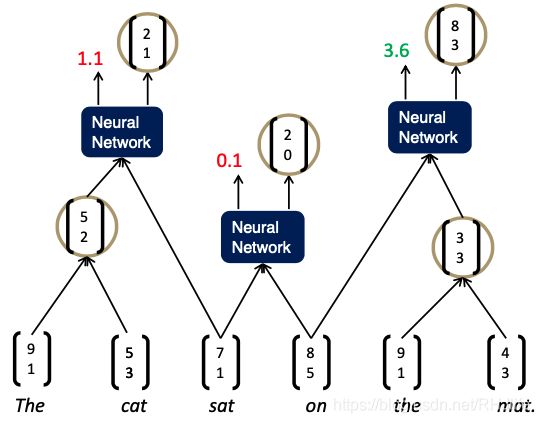
自左向右重复遍历,每次将得分最高的两者组合在一起
Max-Margin Framework - Details/最大利润框架-详细信息/细节
树的得分是通过每个节点的解析决策得分的总和来计算的: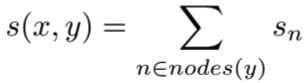

其中:x 是句子,y 是解析树
类似于最大距离分析(Taskar等人。2004年),一个受监督的最大利润目标:
损失![]() 惩罚所有不正确的决策
惩罚所有不正确的决策
结构搜索![]() 是贪婪的(每次加入最佳节点)
是贪婪的(每次加入最佳节点)
相反:使用 Beam search 搜索图
(当没有很好决策时,贪婪策略往往是个不错的选择)
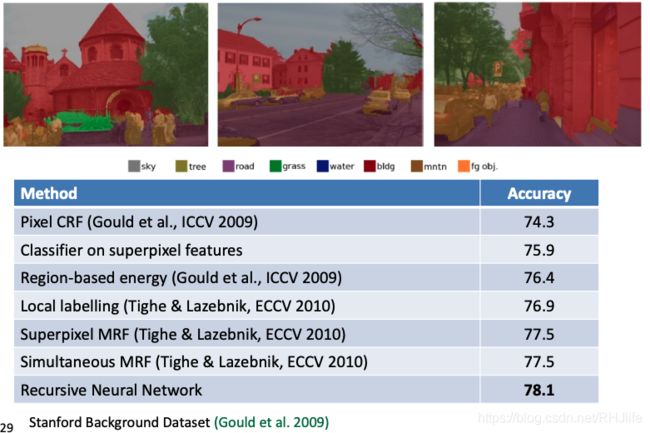
场景解析

与自然语言解析相似的递归神经网络!
- 场景图像的含义也是较小区域的函数
- 它们如何组合成部分以形成更大的对象
- 以及对象如何相互作用
图像解析算法
与自然语言解析相同的递归神经网络!(Socher等人。ICML 2011)

多类分割
3.结构反向传播
Introduced by Goller & Küchler (1996)
和通用的反向传播的规则相同:
递归和树结构导致的计算:
- 从所有节点求和W的导数(如RNN)
- 在每个节点处拆分导数(对于树)
- 从父节点和节点本身添加错误消息
BTS:1)所有节点的和导数
通过示例,您可以假设在每个节点直觉上它是不同的W:

如果我们对每一个事件取不同的导数,我们得到相同的结果:

BTS:2)在每个节点拆分导数
在向前推进期间,使用2个子对象计算父对象

因此,需要计算每种误差:(每个孩子的错误是n维的)
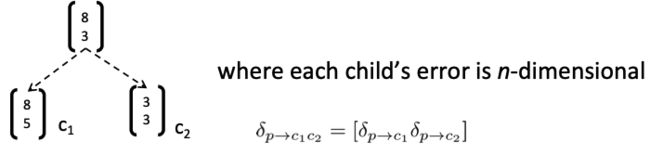
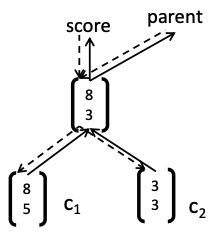
BTS:3)添加错误消息
在每个节点:
- 出现什么(fprop)必须降下来(bprop)
- 总错误消息=来自父级的错误消息+来自自己分数的错误消息
BTS Python代码:forwardProp

BTS Python代码:backProp

讨论:简单树
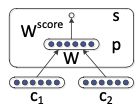
使用单矩阵TreeRNN的结果
单个权重矩阵TreeRNN可以捕获一些现象但不适合更复杂的现象以及更高阶的构成和解析长句
输入词之间没有真正的交互
组合函数对于所有句法类别,标点符号等都是相同的
4.版本2:语法上不带语法的RNN
[Socher, Bauer, Manning, Ng 2013]
- 符号的上下文无关的语法(Context Free Grammar CFG)主干是足以满足基本的句法结构
- 我们使用子元素的离散句法类别来选择组合矩阵
- 对于不同的语法环境,TreeRNN可以针对不同的组合矩阵做得更好
- 结果为我们提供了更好的语义

合成向量文法
问题:速度。波束搜索中的每个候选分数都需要一个矩阵向量积。
解决方案:只计算来自更简单、更快模型(PCFG)的树的子集的分数
- 删除/修剪不太可能的速度候选词
- 每个beam候选项的子项
合成向量语法=PCFG+TreeRNN
解析相关工作
- 产生的CVG解析器和先前扩展PCFG解析器的工作有关
- Klein和Manning(2003a):手工特征工程
- Petrov等人(2006):分解和合并句法类别的学习算法
- 词汇化解析器(Collins,2003;Charniak,2000):用词汇项描述每个类别
- Hall和Klein(2012)在一个因子解析器中结合了几种这样的注释方案。
- CVG将这些概念从离散表示扩展到更丰富的连续表示
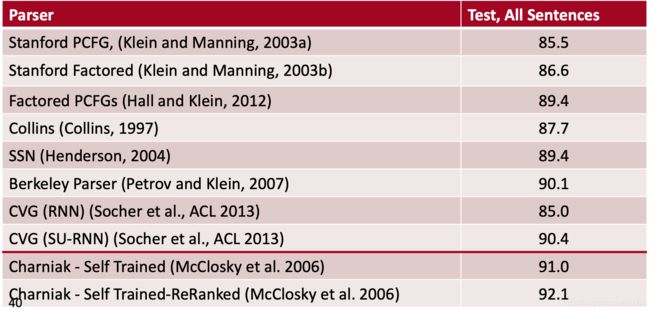
例子
- 标准WSJ拆分,标记为F1
- 基于状态较少的简单PCFG
- 搜索空间快速修剪,矩阵向量积少
- F1高3.8%
SU-RNN / CVG [Socher, Bauer, Manning, Ng 2013]
学习首词的软概念,初始化: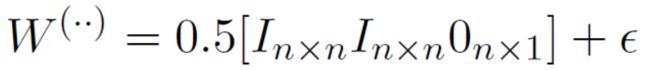
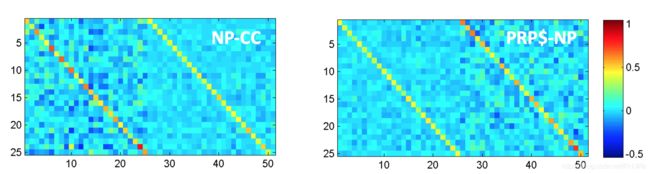

训练该模型会更关注一个短语的哪个孩子更加重要
结果向量表示的分析
所有数字都因季节变化而作了调整
- 所有的数字都根据季节性波动进行了调整
- 所有的数字都被调整以消除通常的季节性模式
奈特·里德不愿对报价置评
- 哈斯科拒绝透露是哪个国家下的订单
- 海岸不愿透露条款
(两个透露的意思差不多)
销售额从1000万美元增长到100万美元,增长了近7%
- 销售额从8830万美元增长到9490万美元,增幅超过7%
- 销售额从日元猛增40%至日元。
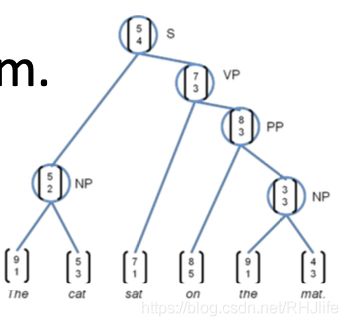
版本3:递归矩阵向量空间的组合性
[Socher, Huval, Bhat, Manning, & Ng, 2012]

这两个词c1、c2在意义上没有相互影响
使组合函数更强大的一种方法是解开权重 W
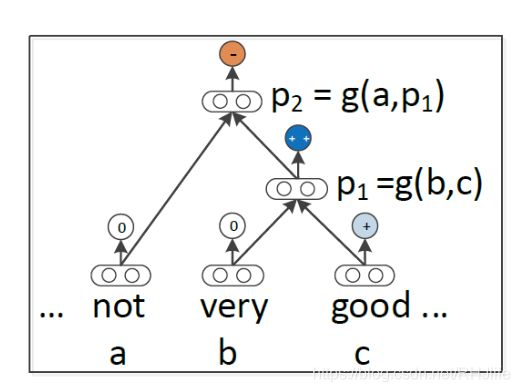
但是,如果单词主要作为运算符,例如 “very” in “very good”,是没有意义的,是用于增加 good 的规模的运算符
提案:新的组合函数
问题是如何定义呢,因为不知道![]() 和
和 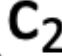 哪个是 operator,比如very good ,就应该讲very视为作用在 good 的矩阵上的向量,想要抓住very~
哪个是 operator,比如very good ,就应该讲very视为作用在 good 的矩阵上的向量,想要抓住very~
递归矩阵向量递归神经网络的组合性

每个单词都拥有一个向量意义和一个矩阵意义
Matrix-vector RNNs
[Socher, Huval, Bhat, Manning, & Ng, 2012]
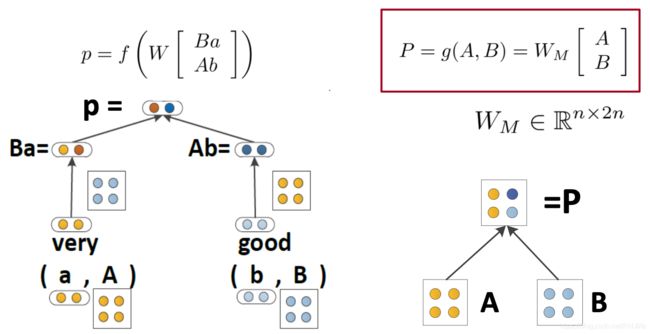
左侧计算得到合并后的向量意义,右侧计算得到合并后的矩阵意义
模型可以捕获运算符语义,即中一个单词修饰了另一个单词的含义
预测情绪分布
语言中非线性的好例子

语义关系分类
MV-RNN 可以学习到大的句法上下文传达语义关系吗?
为包含两个术语的最小成分构建一个单一的组合语义
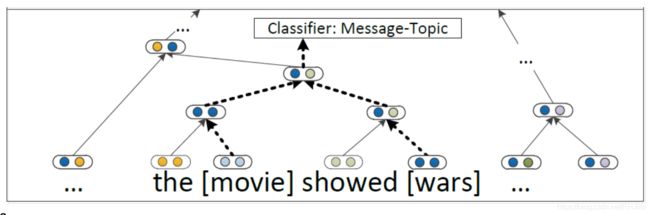

问题:参数量过大,并且获得短语的矩阵意义的方式不够好
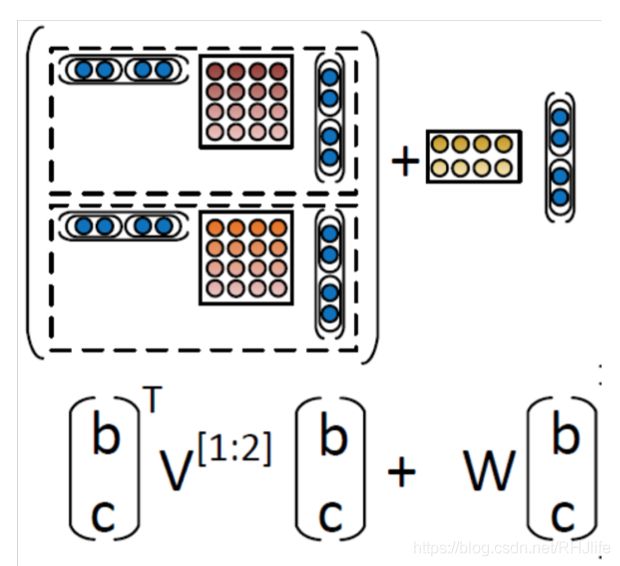
第4版:递归神经张量网络
Socher, Perelygin, Wu, Chuang, Manning, Ng, and Potts 2013
参数小于MV-RNN
允许两个单词或短语向量进行乘法交互
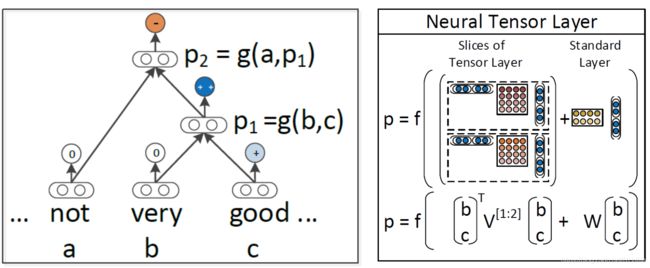
言外之意:情感检测
一段文字的语调是积极的,消极的还是中性的?
某种程度上情绪分析是容易的
较长文档的检测精度~90%,但是

斯坦福情感树库
215154个短语标注在11855个句子中
可以训练和测试
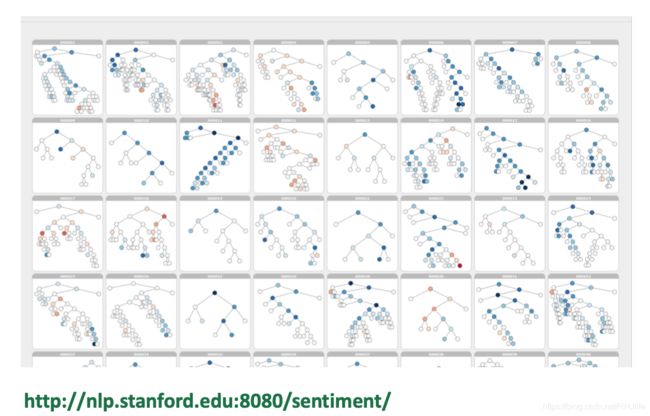
更好的数据集有助于所有模型
严重的否定的情况仍然大部分是不正确的
我们还需要一个更强大的模型!
想法:允许载体的加性和介导的乘法相互作用


在树中使用结果向量作为逻辑回归的分类器的输入
使用梯度下降联合训练所有权重
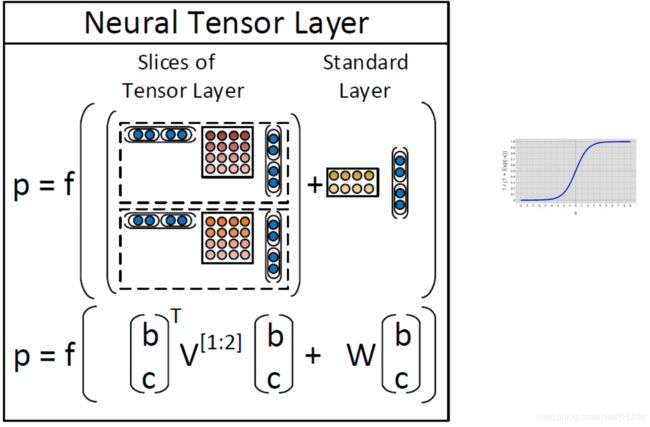
回到最初的使用向量表示单词的意义,但不是仅仅将两个表示单词含义的向量相互作用,左上图是在中间插入一个矩阵,以双线性的方式做注意力并得到了注意力得分。即令两个单词的向量相互作用并且只产生一个数字作为输出,如上中图所示,我们可以拥有三维矩阵,即多层的矩阵(二维),从而得到了两个得分,最后使用 softmax做分类
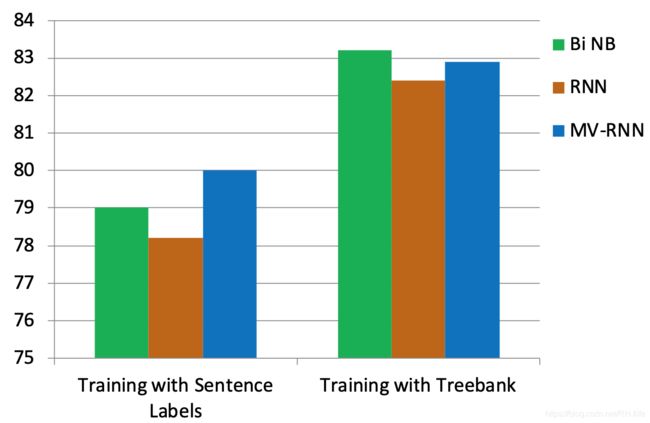
Treebank的正面/负面结果
Classifying Sentences: Accuracy improves to 85.4

树库实验结果
RNTN 可以捕捉类似 X but Y 的结构
RNTN accuracy of 72%, compared to MV-RNN (65%), biword NB (58%) and RNN (54%)
否定结果
双重否定时(表示为肯定),积极反应应该上升

版本5:提高深度学习语义,使用TreeLSTM表示
[Tai et al., ACL 2015; also Zhu et al. ICML 2015]
目标:
- 仍然试图将句子的意思表示为(高维、连续)向量空间中的位置
- 准确处理语义成分和句子含义
- 将广泛使用的链式结构LSTM推广到树
用于顺序合成的长短期存储器(LSTM)单元
门是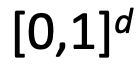 中的向量乘以元素,用于软掩蔽元素
中的向量乘以元素,用于软掩蔽元素
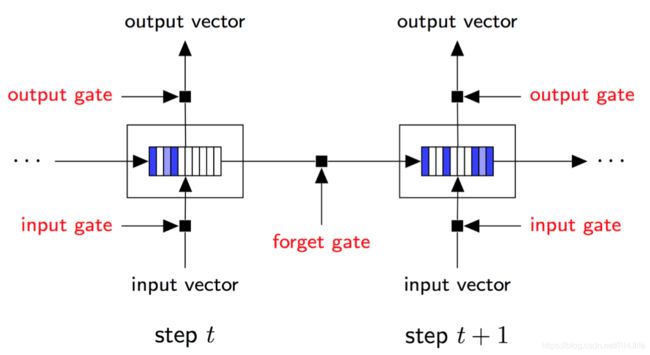 树状结构长短期记忆网络
树状结构长短期记忆网络
[Tai et al., ACL 2015]
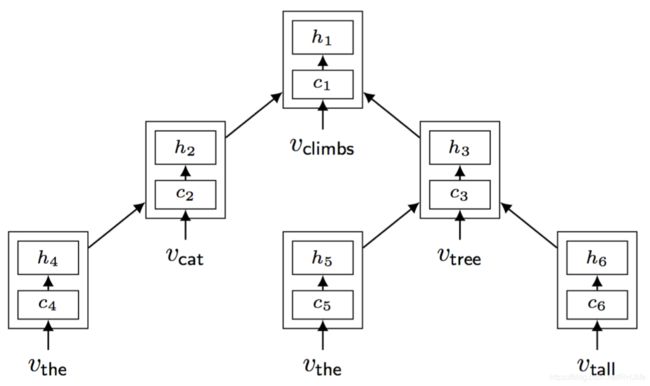
树形结构LSTM
将序列LSTM推广到具有任意分枝因子的树

结果:情绪分析:斯坦福情绪树库

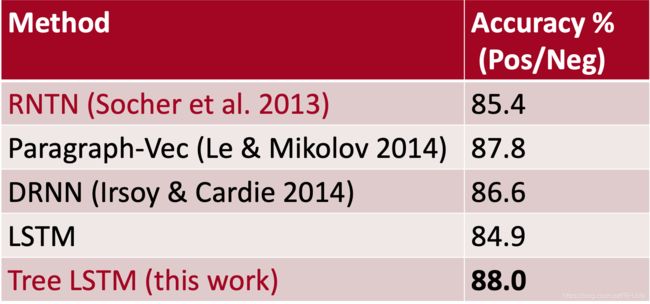
结果:语义相关SICK 2014(涉及成分知识的句子)
忘记Gates/盖茨:选择性国家保护
Stripes = forget gate activations; more white ⇒ more preserved

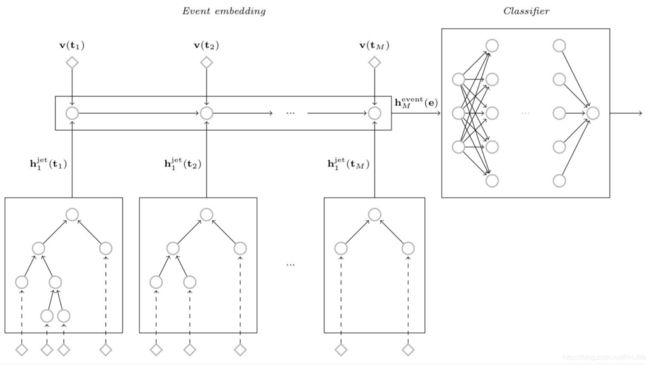
5. QCD-Aware Recursive Neural Networks for Jet Physics Gilles Louppe, Kyunghun Cho, Cyril Becot, Kyle Cranmer (2017)(翻译不出来...)
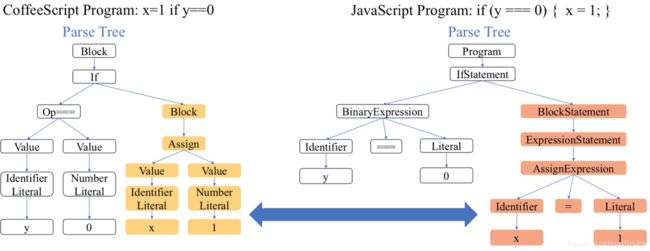
用于程序翻译的树到树神经网络
[Chen, Liu, and Song NeurIPS 2018]
探索使用树结构编码和生成来实现编程语言之间的转换
在生成过程中,您将注意力集中在源树上


以人为中心的人工智能
人工智能将改变经济和社会,改变我们的沟通和工作方式,重塑治理和政治,并挑战国际秩序。人工智能的使命是推进人工智能研究、教育、政策和实践,以改善人类状况