java 知识点 18(mybatis缓存、JVM、JMM)
文章目录
-
- 1、mybatis缓存
-
- 1.1、一级缓存
-
- 1.1.1、从日志中看出缓存在作用
- 1.1.2、增删改 会更新缓存
- 1.1.3、手动清理缓存
- 1.2、二级缓存
-
- 1.2.1、开启二级缓存,cache标签
- 1.2.2、开启全局缓存(可以不写)
- 1.2.3、缓存原理
- 1.3、自定义缓存
-
- 1.3.1、使用ehche缓存
- 1.3.2、自己写一个缓存
- 1.3.3、使用redis做缓存
- 2、JVM
-
- 2.1、JVM基础认识
- 2.2、内加载器
- 2.3、native关键字与JNI的作用
- 2.2、区、堆、栈
-
- 2.2.1、堆
- 2.2.2、JProfiler(内存分析工具)
- 3、JMM
-
- 3.1、三大特性解释
- 3.2、三大特性相关关键字
1、mybatis缓存
为什么要使用缓存:减少和数据库交互次数、减少系统开销
什么样的数据能使用缓存:经常查询的数据
mybatis缓存:mybatis默认定义了两级缓存,默认只开启一级缓存。
使用缓存,实体类需要序列化,否者会报错
1.1、一级缓存
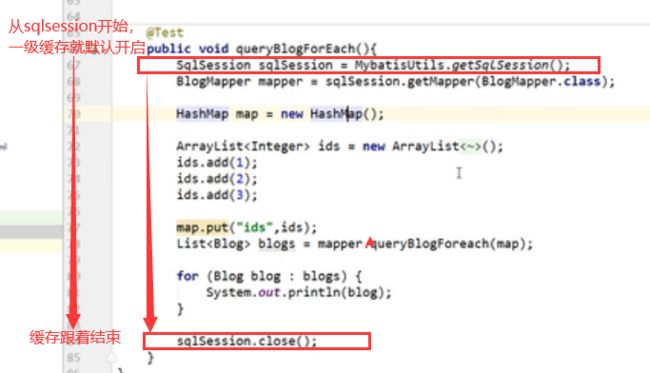
所以一级缓存开启不需要手动写什么代码。
如果需要查看缓存读取与销毁,需要开启日志

1.1.1、从日志中看出缓存在作用
测试:session中查询两条不同的数据,查看日志执行了几次sql

运行结果

我们发现执行了两次sql,那么我们如果查两次同一条数据呢?

我们发现只执行了一次,这就是缓存的作用
1.1.2、增删改 会更新缓存
增删改 会更新缓存,因为增删改会更改数据,查询不会。

所以,只要有增删改语句出现,缓存就会被刷新(也就是会被清空重新载入)
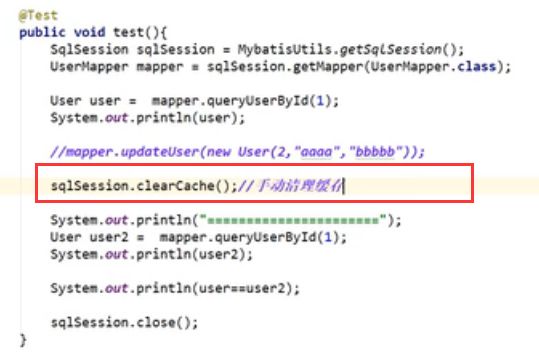
1.1.3、手动清理缓存
sqlSession.clearCache();
1.2、二级缓存
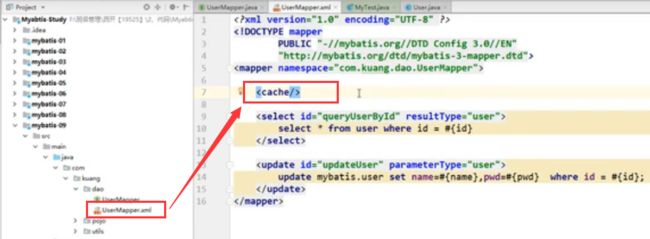
1.2.1、开启二级缓存,cache标签
在对应的**mapper.xm里面添加
就开启二级缓存了
在sql的标签中也可以选择单个标签是否开启缓存

二级缓存的作用
1、一级缓存只作用在一个sqlssion生命周期内,
开启二级缓存,当前会话关闭后可以把数据存传给二级缓存。
2、新会话可以从二级缓存获取数据

cache标签内还可以有对应的属性
<cache
eviction="FIFO" # 创建一个FIFO缓存
flushInterval="60000" # 每隔 60 秒刷新
size="512" # 存储结果对象或列表的 512 个引用
readOnly="true"/> # "true" 返回的对象被认为是只读的
eviction 可以有以下值:
- LRU – 最近最少使用:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
- WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
size(引用数目)属性:
可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性:
为true,只读,速度更快。
为false,可读,速度慢,但更安全,默认值为false。
另外mybatis还可以配置自定义缓存或第三方缓存
1.2.2、开启全局缓存(可以不写)
在mybatis-config.xml里面的setting标签里面写

1.2.3、缓存原理
读取顺序:
1、从二级缓存中查找有没有
2、再到一级缓存里找
3、最后是查询数据库

1.3、自定义缓存
1.3.1、使用ehche缓存
自定义使用ehche缓存
第一步,在pom.xml里面导包

<dependency>
<groupId>org.mybatis.ehcachegroupId>
<artifactId>mybatis-ehcacheartifactId>
<version>1.1.0version>
dependency>
在**mapper.xml中定义使用这个缓存(相当于二级缓存)

然后新建 ehcache.xml (直接建在resource文件夹下就可以)
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<diskStore path="java.io.tmpdir"/>
<defaultCache maxElementsInMemory="1000"
eternal="false"
timeToIdleSeconds="3600"
timeToLiveSeconds="0"
overflowToDisk="true"
maxElementsOnDisk="10000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="FIFO"
/>
<cache name="testCache"
maxEntriesLocalHeap="2000"
eternal="false"
timeToIdleSeconds="3600"
timeToLiveSeconds="0"
overflowToDisk="false"
statistics="true"
memoryStoreEvictionPolicy="FIFO">
cache>
ehcache>
1.3.2、自己写一个缓存
在工具包utils下新建MyCache,继承接口Cache
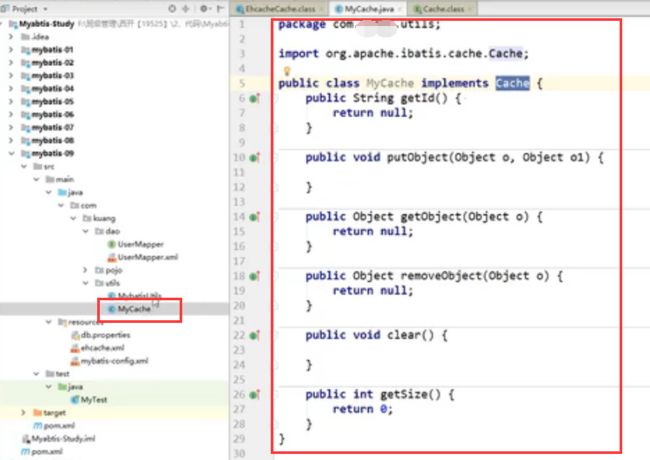
在**mapper.xml中定义使用这个缓存

1.3.3、使用redis做缓存
第一步,首先在系统环境下安装并运行redis
windows下redis的安装与启动:https://blog.csdn.net/a__int__/article/details/103648033
linux下redis的安装与启动:https://blog.csdn.net/a__int__/article/details/108309284
redis中文教程:https://www.redis.net.cn/tutorial/3501.html
第二步,在pom.xml里导包
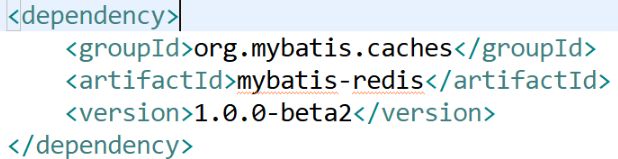
第三步,新建配置文件redis.properties

第四步,mapper中加入MyBatis二级缓存
![]()
第五步,Mybatis全局配置文件中
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="false"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="mapUnderscoreToCamelCase" value="true"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
<setting name="aggressiveLazyLoading" value="true"/>
settings>
configuration>
到这里redis缓存就启用了
2、JVM
思维导图在线工具:https://www.processon.com/
XMind 下载软件:https://www.xmind.cn/xmind/thank-you-for-downloading/
在processon在线工具里面可以搜到很多关于java原理的思维导图

2.1、JVM基础认识
1、jvm在哪儿?
- 物理位置:如果我们从java官网下载一个jdk包,打开后找到jvm.dll就是jvm动态连接文件。
- 运行位置:就像一个软件运行在操作系统上,在java文件被编译成class文件后,执行class文件。

2、java代码是怎么变成程序的?
java代码是怎么变成java程序的?(程序的生成加载过程)
答:首先是java文件(代码),然后被编译成class文件,再通过jvm变成程序。
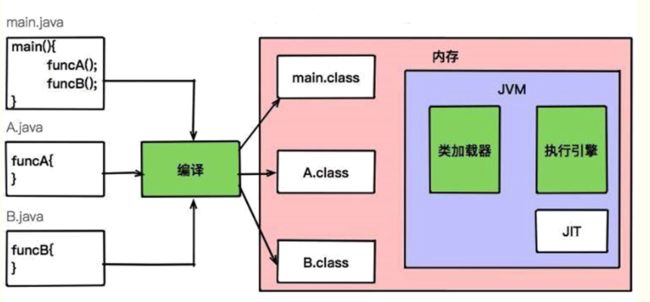
上图是java的程序生成过程(解释型语言),下图是c++等(编译型语言)的程序生成过程,可以对比参考。

3、jvm不只一个公司开发(仅作了解)
-
jvm HotSpot: 我们现在所学的,基本都是由sun公司开发的jvm HotSpot。
-
JRockit:是oracle公司被sun收购之前开发的,被称是业界性能最高的 Java 虚拟机。
-
IBM JVM: 本质也是IBM公司在oracle公司开发的基础之上完成的。
他们三使用了不同的垃圾回收机制,但是垃圾回收的概念和算法是相通的。
2.2、内加载器
内加载器作用:加载class文件
双亲委派机制:一个类收到了加载请求,会把这个请求给父类加载器去执行,如果父类加载器还存在其父类加载器,依次往上传。

2.3、native关键字与JNI的作用
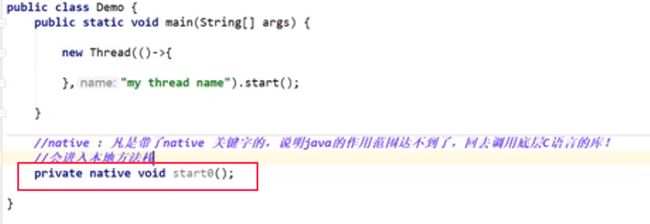
用了native关键字,会进入本地方法栈,本地方法栈会调用本地接口(jni)。
JNI的作用:可以扩展java的使用,调用不同的编程语言(C\C++等)。
随着java的强大,现在native关键字用得越来越少了,还有哪些情况在使用呢?
比如调用打印机驱动程序
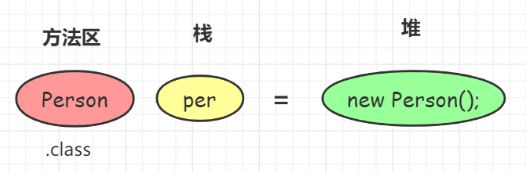
2.2、区、堆、栈
栈:栈里面的东西是有序的,一个一个排队进出(先进后出)。
堆:堆里面的东西是无序的,程序员自己分配进出。
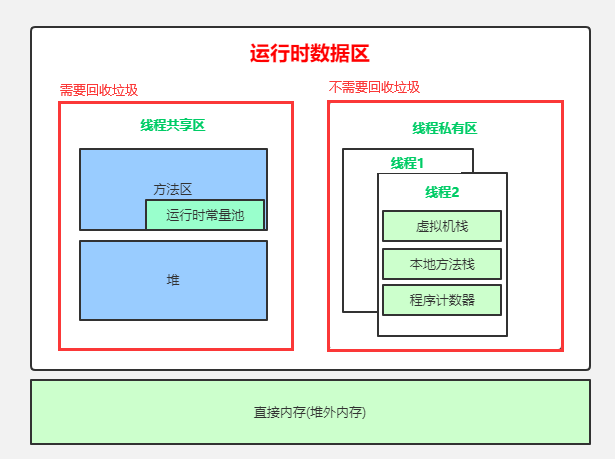
从java 8开始 字符串常量池在堆, 运行时常量池在方法区
方法区: static、final、class、常量池…
栈: 8大基本类型、对象引用、实例方法…
堆: 所有new出来的对象
2.2.1、堆
1、堆内存可以细分为如下区域:
- 新生区 (又细分为edan、survivor1、survivor2)
- 老生区
-永生区(java1.7以前才有,现在被元空间(Matespace)代替了,并放到了堆内存之外。)
真相:99%的对象都是临时对象,在新生区就被回收了
2、GC垃圾回收主要在新生区和老生区进行。
3、OOM:“Out Of Memory”就是“内存用完了”,报错来自java.lang.OutOfMemoryError。
2.2.2、JProfiler(内存分析工具)
ieda安装JProfiler插件

安装完之后手动重启idea,然后再在系统里面安装JProfiler
idea里面的JProfiler插件用来生成JProfiler文件。然后用系统安装的JProfiler打开分析。
3、JMM
JMM即为JAVA 内存模型(java memory model)。
作用:用于定义数据读写的规则(缓存一致性协议)。

JMM内存模型三大特性:原子性、可见性、有序性。
3.1、三大特性解释
原子性:多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰
可见性:一个线程修改了一个变量的值后,其他线程立即可以感知到这个值的修改。
有序性:从单线程角度看,所有操作都是有序的
3.2、三大特性相关关键字
原子性:
在 synchronized 块之间的代码都具有原子性。
可见性:
volatile 类型的变量:在修改后会立即同步给主内存,在使用的时候会从主内存重新读取。依赖主内存为中介,来保证多线程下变量对其他线程的可见性的。
synchronized 关键字:是通过 unlock 之前必须把变量同步回主内存来实现可见性的。
final :是在初始化后就不会更改,所以只要在初始化过程中没有把 this 指针传递出去也能保证对其他线程的可见性。
有序性:
保证有序性的关键字有 volatile 和 synchronized:
volatile 禁止了指令重排序,
synchronized 则由“一个变量在同一时刻只能被一个线程对其进行 lock 操作”来保证。
总结:
synchronized 对三种特性都有支持,十分好用,但是性能稍微差一点,大量使用并发很差
volatile 可以说是 java 虚拟机中提供的最轻量级的同步机制。
java 内存模型对 volatile 专门定义了一些特殊的访问规则。
他能保证多线程中变量对所有线程的可见性,volatile 类型的变量禁止指令重排序优化