mysql-分库分表概述
分库分表概述
互联网系统需要处理大量用户的请求。比如微信日活用户破10亿,海量的用户每天产生海量的数量;美团外卖,每天都是几千万的订单,那这些系统的用户表、订单表、交易流水表等是如何处理呢?
数据量只增不减,历史数据又必须要留存,非常容易成为性能的瓶颈,而要解决这样的数据库瓶颈问题,“读写分离”和缓存往往都不合适,目前比较普遍的方案就是使用NoSQL/NewSQL或者采用分库分表。
使用分库分表时,主要有垂直拆分和水平拆分两种拆分模式,都属于物理空间的拆分。
分库分表方案:只分库、只分表、分库又分表。
垂直拆分:由于表数量多导致的单个库大。将表拆分到多个库中。
水平拆分:由于表记录多导致的单个库大。将表记录拆分到多个表中。
拆分方式
垂直拆分
垂直拆分又称为纵向拆分,垂直拆分是将表按库进行分离,或者修改表结构按照访问的差异将某些列拆分出去。应用时有垂直分库和垂直分表两种方式,一般谈到的垂直拆分主要指的是垂直分库

垂直分表就是将一张表中不常用的字段拆分到另一张表中,从而保证第一张表中的字段较少,避免出现数据库跨页存储的问题,从而提升查询效率。
解决:一个表中字段过多,还有有些字段经常使用,有些字段不经常使用,或者还有text等字段信息。可以考虑使用垂直分表方案
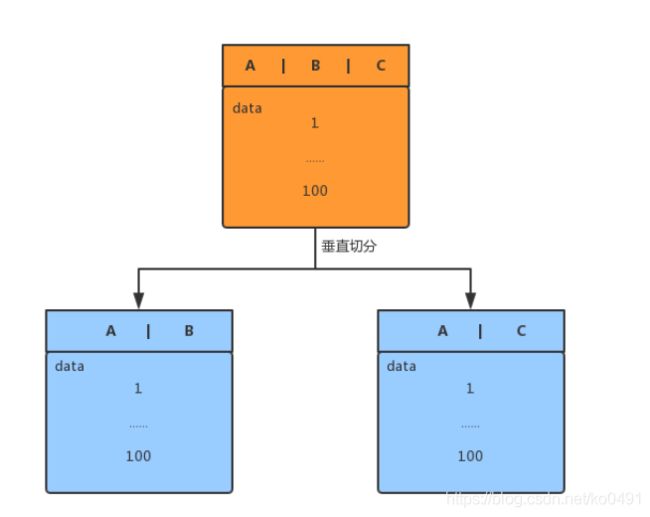
按列进行垂直拆分,即把一条记录分开多个地方保存,每个子表的行数相同。把主键和一些列放到
一个表,然后把主键和另外的列放到另一个表中
垂直拆分优点:
拆分后业务清晰,拆分规则明确;
易于数据的维护和扩展;
可以使得行数据变小,一个数据块 (Block) 就能存放更多的数据,在查询时就会减少 I/O 次
数;
可以达到最大化利用 Cache 的目的,具体在垂直拆分的时候可以将不常变的字段放一起,将
经常改变的放一起;
便于实现冷热分离的数据表设计模式。
垂直拆分缺点:
主键出现冗余,需要管理冗余列;
会引起表连接 JOIN 操作,可以通过在业务服务器上进行 join 来减少数据库压力,提高了系
统的复杂度;
依然存在单表数据量过大的问题;
事务处理复杂
水平拆分
水平拆分又称为横向拆分。 相对于垂直拆分,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个表仅包含数据的一部分
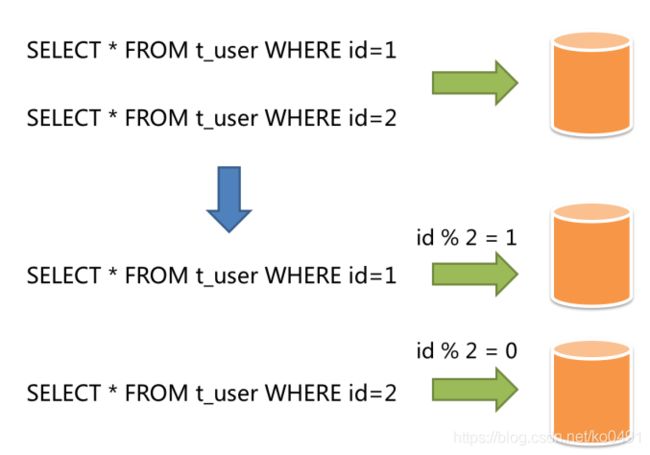
水平分表是将一张含有很多记录数的表水平切分,不同的记录可以分开保存,拆分成几张结构相同的表。如果一张表中的记录数过多,那么会对数据库的读写性能产生较大的影响,虽然此时仍然能够正确地读写,但读写的速度已经到了业务无法忍受的地步,此时就需要使用水平分表来解决这个问题。
水平拆分:解决表中记录过多问题。
垂直拆分:解决表过多或者是表字段过多问题
水平拆分重点考虑拆分规则:例如范围、时间或Hash算法等
水平拆分优点:
拆分规则设计好,join 操作基本可以数据库做;
不存在单库大数据,高并发的性能瓶颈;
切分的表的结构相同,应用层改造较少,只需要增加路由规则即可;
提高了系统的稳定性和负载能力。
水平拆分缺点:
拆分规则难以抽象;
跨库Join性能较差;
分片事务的一致性难以解决;
数据扩容的难度和维护量极大
日常工作中,我们通常会同时使用两种拆分方式,垂直拆分更偏向于产品/业务/功能拆分的过程,在技
术上我们更关注水平拆分的方案
主键策略
在很多中小项目中,我们往往直接使用数据库自增特性来生成主键ID,这样确实比较简单。而在分库分
表的环境中,数据分布在不同的数据表中,不能再借助数据库自增长特性直接生成,否则会造成不同数
据表主键重复。
UUID
UUID是通用唯一识别码(Universally Unique Identifier)的缩写,长度是16个字节,被表示为32个十六进制数字,以“ - ”分隔的五组来显示,格式为8-4-4-4-12,共36个字符,例如:550e8400-e29b-41d4-a716-446655440000。UUID在生成时使用到了以太网卡地址、纳秒级时间、芯片ID码和随机数等信息,目的是让分布式系统中的所有元素都能有唯一的识别信息。使用UUID做主键,可以在本地生成,没有网络消耗,所以生成性能高。但是UUID比较长,没有规律性,耗费存储空间
如果UUID作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,影响性
能
COMB(UUID变种)
COMB(combine)型是数据库特有的一种设计思想,可以理解为一种改进的GUID,它通过组合GUID和系统时间,以使其在索引和检索事有更优的性能。数据库中没有COMB类型,它是JimmyNilsson在他的“The Cost of GUIDs as Primary Keys”一文中设计出来的。
COMB设计思路是这样的:既然UniqueIdentifier数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么我们能不能通过组合的方式,保留UniqueIdentifier的前10个字节,用后6个字节表示GUID生成的时间(DateTime),这样我们将时间信息与UniqueIdentifier组合起来,在保留UniqueIdentifier的唯一性的同时增加了有序性,以此来提高索引效率。解决UUID无序的问题,性能优于UUID。
SNOWFLAKE
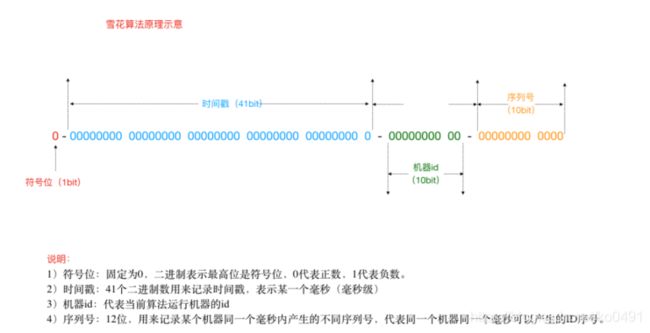
有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成,SnowFlake解决了这种需求。SnowFlake是Twitter开源的分布式ID生成算法,结果是一个long型的ID,long型是8个字节,64-bit。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号,最后还有一个符号位,永远是0
SnowFlake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID重复,并且效率
较高。经测试SnowFlake每秒能够产生26万个ID。缺点是强依赖机器时钟,如果多台机器环境时
钟没同步,或时钟回拨,会导致发号重复或者服务会处于不可用状态。因此一些互联网公司也基于
上述的方案做了封装,例如百度的uidgenerator(基于SnowFlake)和美团的leaf(基于数据库和
SnowFlake)等
数据库ID表
比如A表分表为A1表和A2表,我们可以单独的创建一个MySQL数据库,在这个数据库中创建一张表,这张表的ID设置为自动递增,其他地方需要全局唯一ID的时候,就先向这个这张表中模拟插入一条记录,此时ID就会自动递增,然后我们获取刚生成的ID后再进行A1和A2表的插入。例如,下面DISTRIBUTE_ID就是我们创建要负责ID生成的表,结构如下:
CREATE TABLE DISTRIBUTE_ID (
id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '主键',
createtime datetime DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
当分布式集群环境中哪个应用需要获取一个全局唯一的分布式ID的时候,就可以使用代码连接这
个数据库实例,执行如下SQL语句即可
insert into DISTRIBUTE_ID(createtime) values(NOW());
select LAST_INSERT_ID()
注意:
这里的createtime字段无实际意义,是为了随便插入一条数据以至于能够自动递增ID。
使用独立的MySQL实例生成分布式ID,虽然可行,但是性能和可靠性都不够好,因为你需要代码连接到数据库才能获取到ID,性能无法保障,另外mysql数据库实例挂掉了,那么就无法获取分布式ID了
Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
也可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为

分片
分片概念
分片(Sharding)就是用来确定数据在多台存储设备上分布的技术。Shard这个词的意思是“碎片”,如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库的碎片(DatabaseSharding)。将一个数据库打碎成多个的过程就叫做分片,分片是属于横向扩展方案。分片:表示分配过程,是一个逻辑上概念,表示如何实现分库分表:表示分配结果,是一个物理上概念,表示最终实现的结果
数据库扩展方案:
- 横向扩展:一个库变多个库,加机器数量
- 纵向扩展:一个库还是一个库,优化机器性能,加高配CPU或内存
在分布式存储系统中,数据需要分散存储在多台设备上,分片就是把数据库横向扩展到多个数据库服务器上的一种有效的方式,其主要目的就是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题
分片策略
数据分片是根据指定的分片键和分片策略将数据水平拆分,拆分成多个数据片后分散到多个数据存储节点中。分片键是用于划分和定位表的字段,一般使用ID或者时间字段。而分片策略是指分片的规则,常用规则有以下几种
-
基于范围分片
根据特定字段的范围进行拆分,比如用户ID、订单时间、产品价格等。例如:
{[1 - 100] => Cluster A, [101 - 199] => Cluster B}
优点:新的数据可以落在新的存储节点上,如果集群扩容,数据无需迁移。
缺点:数据热点分布不均,数据冷热不均匀,导致节点负荷不均 -
哈希取模分片
整型的Key可直接对设备数量取模,其他类型的字段可以先计算Key的哈希值,然后再对设备数量
取模。假设有n台设备,编号为0 ~ n-1,通过Hash(Key) % n就可以确定数据所在的设备编号。该
模式也称为离散分片。
优点:实现简单,数据分配比较均匀,不容易出现冷热不均,负荷不均的情况。
缺点:扩容时会产生大量的数据迁移,比如从n台设备扩容到n+1,绝大部分数据需要重新分配和迁移
- 一致性哈希分片
采用Hash取模的方式进行拆分,后期集群扩容需要迁移旧的数据。使用一致性Hash算法能够很大
程度的避免这个问题,所以很多中间件的集群分片都会采用一致性Hash算法。
一致性Hash是将数据按照特征值映射到一个首尾相接的Hash环上,同时也将节点(按照IP地址或者机器名Hash)映射到这个环上。对于数据,从数据在环上的位置开始,顺时针找到的第一个节点即为数据的存储节点。Hash环示意图与数据的分布如下
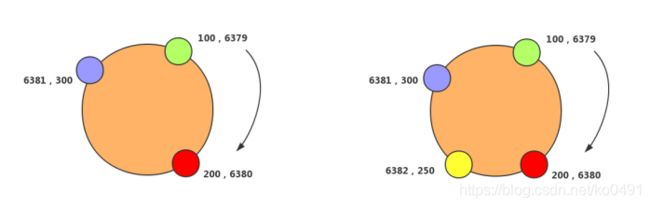
一致性Hash在增加或者删除节点的时候,受到影响的数据是比较有限的,只会影响到Hash环相邻的节点,不会发生大规模的数据迁移
扩容方案
当系统用户进入了高速增长期时,即便是对数据进行分库分表,但数据库的容量,还有表的数据量也总会达到天花板。当现有数据库达到承受极限时,就需要增加新服务器节点数量进行横向扩容。首先来思考一下,横向扩展会有什么技术难度?
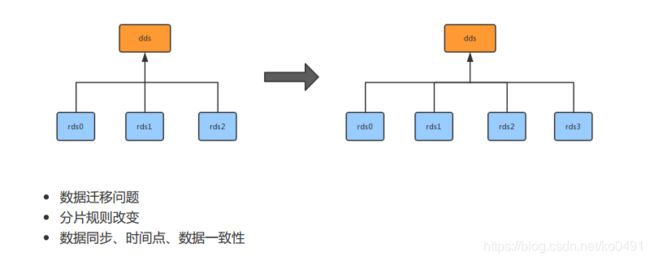
停机扩容
这是一种很多人初期都会使用的方案,尤其是初期只有几台数据库的时候。停机扩容的具体步骤如下:
- 站点发布一个公告,例如:“为了为广大用户提供更好的服务,本站点将在今晚00:00-2:00之间升级,给您带来不便抱歉";
- 时间到了,停止所有对外服务;
- 新增n个数据库,然后写一个数据迁移程序,将原有x个库的数据导入到最新的y个库中。比如分片规则由%x变为%y;
- 数据迁移完成,修改数据库服务配置,原来x个库的配置升级为y个库的配置
*重启服务,连接新库重新对外提供服务
回滚方案:万一数据迁移失败,需要将配置和数据回滚,改天再挂公告
- 优点:简单
- 缺点:
停止服务,缺乏高可用
程序员压力山大,需要在指定时间完成
如果有问题没有及时测试出来启动了服务,运行后发现问题,数据会丢失一部分难以回滚。 - 适用场景:
小型网站
大部分游戏
对高可用要求不高的服务
平滑扩容
数据库扩容的过程中,如果想要持续对外提供服务,保证服务的可用性,平滑扩容方案是最好的选择。平滑扩容就是将数据库数量扩容成原来的2倍,比如:由2个数据库扩容到4个数据库,具体步骤如下
- 新增2个数据库
- 配置双主进行数据同步(先测试、后上线)
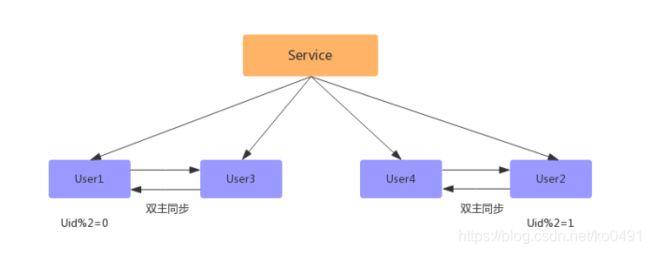
-
数据同步完成之后,配置双主双写(同步因为有延迟,如果时时刻刻都有写和更新操作会存在不准确问题)
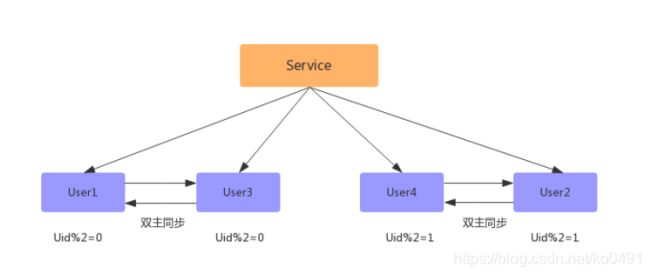
-
数据同步完成后,删除双主同步,修改数据库配置,并重启;
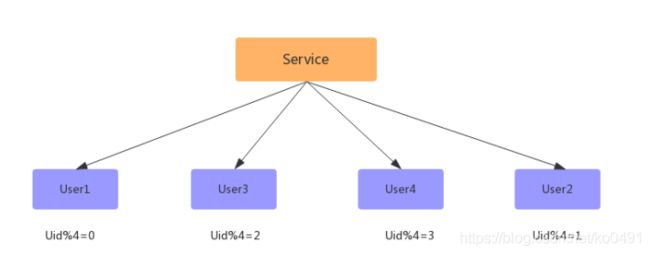
-
此时已经扩容完成,但此时的数据并没有减少,新增的数据库跟旧的数据库一样多的数据,此时还需要写一个程序,清空数据库中多余的数据,如:
User1去除 uid % 4 = 2的数据;
User3去除 uid % 4 = 0的数据;
User2去除 uid % 4 = 3的数据;
User4去除 uid % 4 = 1的数据
平滑扩容方案能够实现n库扩2n库的平滑扩容,增加数据库服务能力,降低单库一半的数据量。其核心原理是:成倍扩容,避免数据迁移
-
优点:
扩容期间,服务正常进行,保证高可用
相对停机扩容,时间长,项目组压力没那么大,出错率低
扩容期间遇到问题,随时解决,不怕影响线上服务
可以将每个数据库数据量减少一半 -
缺点:
程序复杂、配置双主同步、双主双写、检测数据同步等
后期数据库扩容,比如成千上万,代价比较高 -
适用场景:
大型网站
对高可用要求高的服务