解决 Order By 将字符串类型的数字 或 字符串中含数字 按数字排序问题
oracle数据库,字段是varchar2类型即string,而其实存的是数字,这时候不加处理的order by的排序结果,肯定有问题
解决办法:
(1)cast( 要排序的字段名 as integer) ,注意 integer 小写
(2)to_number (要排序的字段名)
如以下例子:
表数据与结构: salary 为 varchar 类型
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary varchar(10) null
);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,'8000');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,'6500');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,'13000');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,'4500');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,'3000');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,'20000');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,'30000');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,'1800');以 salary 降序:
select id,name,age,salary,row_number()over(order by salary desc) rank
from TEST_ROW_NUMBER_OVER t结果:
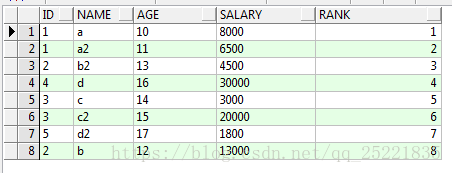
此结果根本不符合我们的预期:
解决办法一:改写:order by cast(salary as integer) desc
select id,name,age,salary,row_number()over(order by cast(salary as integer) desc) rank
from TEST_ROW_NUMBER_OVER t结果: 从结果看出,已经达到预期

增加一行字符串double数据
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,'1888.88');
再执行
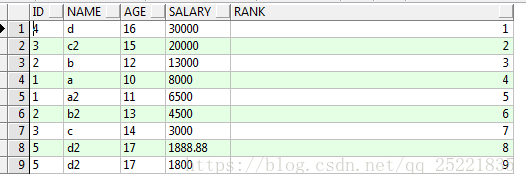
select id,name,age,salary,row_number()over(order by cast(salary as integer) desc) rank
from TEST_ROW_NUMBER_OVER t结果:结果表明在 oracle 中 不论是 integer还是duoble 的 varchar 类型数据,都可以 通过 cast ( 字段名 as integer ) 解决排序问题
解决办法二:order by to_number(salary) desc
select id,name,age,salary,row_number()over(order by to_number(salary) desc) rank
from TEST_ROW_NUMBER_OVER t结果:从结果看出,to_number 也一样有效

再增加两行数据:salary中含中文及数字,按数字进行排序
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(6,'e1',20,'李雷2333');
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(7,'e2',21,'张三23333');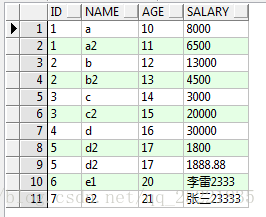
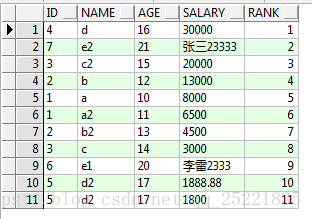
排序:order by to_number(regexp_substr(salary,'[0-9]*[0-9]',1)) desc ,regexp_substr 为截取方法,1为起始位置
select id,name,age,salary,row_number()over
(order by to_number(regexp_substr(salary,'[0-9]*[0-9]',1)) desc) rank
from TEST_ROW_NUMBER_OVER t结果:
REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
__srcstr :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :标识第几个匹配组,默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)