设计模式的预备知识:类图与设计原则
1 UML类图
(转自:http://blog.csdn.net/tianhai110/article/details/6339565)
在UML类图中,常见的有以下几种关系:
- 泛化(Generalization)
- 实现(Realization)
- 关联(Association)
- 聚合(Aggregation)
- 组合(Composition)
- 依赖(Dependency)
1.1 泛化(Generalization)
【泛化关系、继承关系、A is-a B、A extends B、A -> B】:是一种继承关系,它指定了子类如何特化父类的所有特征和行为例如:老虎是动物的一种.
【箭头指向】:带三角箭头的实线,箭头指向父类

1.2 实现(Realization)
【实现关系,A implements B、A —> B】:是一种类与接口的关系,表示类是接口所有特征和行为的实现
【箭头指向】:带三角箭头的虚线,箭头指向接口

1.3 关联(Association)
【关联关系,A has-a B,A —> B】:是一种拥有的关系,它使一个类知道另一个类的属性和方法;如:老师与学生,丈夫与妻子。
关联可以是双向的,也可以是单向的。双向的关联可以有两个箭头或者没有箭头,单向的关联有一个箭头。
A类中有一个成员变量属于B类,则A关联B,A—>B。
【代码体现】:成员变量
【箭头及指向】:带普通箭头的实心线,指向被拥有者

上图中,老师与学生是双向关联,老师有多名学生,学生也可能有多名老师。但学生与某课程间的关系为单向关联,一名学生可能要上多门课程,课程是个抽象的东西他不拥有学生。
1.4 聚合(Aggregation)
【(由……)聚合关系,has-a】:是整体与部分的关系。如车和轮胎是整体和部分的关系。聚合关系是关联关系的一种,是强的关联关系;
关联和聚合在语法上无法区分,必须考察具体的逻辑关系。是一种特殊的关联关系,但是一般说关联关系是指这两个类在同一层次上,而聚合是 局部 指向 整体的关系。
【代码体现】:成员变量
【箭头及指向】:带空心菱形的实心线,菱形指向整体

1.5 组合(Composition)
【(由……)组合关系,be-composed-of】:是整体与部分的关系.,没有公司就不存在部门 组合关系是关联关系的一种,是比聚合关系还要强的关系,它要求普通的聚合关系中代表整体的对象负责代表部分的对象的生命周期。
注意,组合是不能共享的。即代表部分的对象在每一个时刻只能和一个代表整体的对象发生组合关系,并且由后者排他地负责代表部分的对象的生命周期。这是它和聚合关系的差别。
举例:
大学里,一个社团由一个个学生组成,所以可以说 学生 聚合 为社团,而一个学生可以同时参加多个社团,所以这是一种聚合关系,而不是组合关系。
【代码体现】:成员变量
【箭头及指向】:带实心菱形的实线,菱形指向整体

1.6 依赖(Dependency)
【依赖关系】:是一种使用的关系,所以要尽量不使用双向的互相依赖。
它与关联关系的区别在于,关联的耦合性更强。关联的代码表现往往是成员变量,而依赖关系的代码表现是局部变量和方法的参数这种较弱的关联。
【代码表现】:局部变量、方法的参数或者对静态方法的调用。
【箭头及指向】:带箭头的虚线,指向被使用者。
1.7 小结
各种关系的强弱顺序:泛化= 实现> 组合> 聚合> 关联> 依赖
下面这张UML图,比较形象地展示了各种类图关系:

2 设计原则
2.1 开闭原则OCP
(Open-Close Principle)开闭原则是面向对象设计中“可复用设计”的基石,是面向对象设计中最重要的原则之一,其它很多的设计原则都是实现开闭原则的一种手段。1988年,勃兰特·梅耶(Bertrand Meyer)在他的著作《面向对象软件构造(Object Oriented Software Construction)》中提出了开闭原则,它的原文是这样:“Software entities should be open for extension,but closed for modification”。
实现开闭原则的关键就在于“抽象”。把系统的所有可能的行为抽象成一个抽象底层,这个抽象底层规定出所有的具体实现必须提供的方法的特征。作为系统设计的抽象层,要预见所有可能的扩展,从而使得在任何扩展情况下,系统的抽象底层不需修改;同时,由于可以从抽象底层导出一个或多个新的具体实现,可以改变系统的行为,因此系统设计对扩展是开放的。
我们在软件开发的过程中,一直都是提倡需求导向的。这就要求我们在设计的时候,要非常清楚地了解用户需求,判断需求中包含的可能的变化,从而明确在什么情况下使用开闭原则。
关于系统可变的部分,还有一个更具体的对可变性封装原则(Principle of Encapsulation of Variation, EVP),它从软件工程实现的角度对开闭原则进行了进一步的解释。EVP要求在做系统设计的时候,对系统所有可能发生变化的部分进行评估和分类,每一个可变的因素都单独进行封装。
2.2 里氏代换原则(LSP)
里氏代换原则(Liskov Substitution Principle LSP)面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。 LSP是继承复用的基石,只有当衍生类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
【应用实例】:
LSP讲的是基类和子类的关系。只有当这种关系存在时,里氏代换关系才存在。如果两个具体的类A,B之间的关系违反了LSP的设计,(假设是从B到A的继承关系)那么根据具体的情况可以在下面的两种重构方案中选择一种。
—–创建一个新的抽象类C,作为两个具体类的超类,将A,B的共同行为移动到C中来解决问题。
—–从B到A的继承关系改为委派关系。
【详细解释】:
为了说明,我们先用第一种方法来看一个例子,第二种办法在另外一个原则中说明。我们就看那个著名的长方形和正方形的例子。对于长方形的类,如果它的长宽相等,那么它就是一个正方形,因此,长方形类的对象中有一些正方形的对象。对于一个正方形的类,它的方法有个setSide和getSide,它不是长方形的子类,和长方形也不会符合LSP。
- 长方形
public class Rectangle {
...
setWidth(int width){
this.width=width;
}
setHeight(int height){
this.height=height
}
}- 正方形
public class Square{
...
setWidth(int width){
this.width=width;
this. height=width;
}
setHeight(int height){
this.setWidth(height);
}
}- 改变边长的函数
public void resize(Rectangle r) {
while (r.getHeight() <= r.getWidth) {
r.setHeight(r.getWidth + 1);
}
}那么,如果让正方形当做是长方形的子类,会出现什么情况呢?我们让正方形从长方形继承,然后在它的内部设置width等于height,这样,只要width或者height被赋值,那么width和height会被同时赋值,这样就保证了正方形类中,width和height总是相等的.现在我们假设有个客户类,其中有个方法,规则是这样的,测试传入的长方形的宽度是否大于高度,如果满足就停止下来,否则就增加宽度的值。现在我们来看,如果传入的是基类长方形,这个运行的很好。根据LSP,我们把基类替换成它的子类,结果应该也是一样的,但是因为正方形类的width和height会同时赋值,条件总是满足,这个方法没有结束的时候,也就是说,替换成子类后,程序的行为发生了变化,它不满足LSP。
那么我们用第一种方案进行重构,我们构造一个抽象的四边形类,把长方形和正方形共同的行为放到这个四边形类里面,让长方形和正方形都是它的子类,问题就OK了。对于长方形和正方形,取width和height是它们共同的行为,但是给width和height赋值,两者行为不同,因此,这个抽象的四边形的类只有取值方法,没有赋值方法。上面的例子中那个方法只会适用于不同的子类,LSP也就不会被破坏。
【小结】:
在进行设计的时候,我们尽量从抽象类继承,而不是从具体类继承。如果从继承等级树来看,所有叶子节点应当是具体类,而所有的树枝节点应当是抽象类或者接口。当然这个只是一个一般性的指导原则,使用的时候还要具体情况具体分析。
简单的理解为一个软件实体如果使用的是一个父类,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。也就是说,软件里面,把父类都替换成它的子类,程序的行为没有变化。
2.3 依赖倒置原则(DIP)
依赖倒置原则(Dependence Inversion Principle)是程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
【意图】:
面向过程的开发,上层调用下层,上层依赖于下层,当下层剧烈变动时上层也要跟着变动,这就会导致模块的复用性降低而且大大提高了开发的成本。
面向对象的开发很好的解决了这个问题,一般情况下抽象的变化概率很小,让用户程序依赖于抽象,实现的细节也依赖于抽象。即使实现细节不断变动,只要抽象不变,客户程序就不需要变化。这大大降低了客户程序与实现细节的耦合度。
【实例】:
背景1:公司是福特和本田公司的金牌合作伙伴,现要求开发一套自动驾驶系统,只要汽车上安装该系统就可以实现无人驾驶,该系统可以在福特和本田车上使用,只要这两个品牌的汽车使用该系统就能实现自动驾驶。于是有人做出了分析如图一。
对于图一分析:我们定义了一个AutoSystem类,一个FordCar类,一个HondaCar类。FordCar类和HondaCar类中各有三个方法:Run(启动Car)、Turn(转弯Car)、Stop(停止Car),当然了一个汽车肯定不止这些功能,这里只要能说明问题即可。AutoSystem类是一个自动驾驶系统,自动操纵这两辆车。
public class HondaCar {
public void Run() {
Console.WriteLine("本田开始启动了");
}
public void Turn() {
Console.WriteLine("本田开始转弯了");
}
public void Stop() {
Console.WriteLine("本田开始停车了");
}
} public class FordCar {
publicvoidRun(){
Console.WriteLine("福特开始启动了");
}
publicvoidTurn(){
Console.WriteLine("福特开始转弯了");
}
publicvoidStop(){
Console.WriteLine("福特开始停车了");
}
} public class AutoSystem {
public enum CarType {
Ford, Honda
};
private HondaCar hcar = new HondaCar();
private FordCar fcar = new FordCar();
private CarType type;
public AutoSystem(CarType type) {
this.type = type;
}
private void RunCar() {
if (type == CarType.Ford) {
fcar.Run();
} else {
hcar.Run();
}
}
private void TurnCar() {
if (type == CarType.Ford) {
fcar.Turn();
} else {
hcar.Turn();
}
}
private void StopCar() {
if (type == CarType.Ford) {
fcar.Stop();
} else {
hcar.Stop();
}
}
}背景2:公司的业务做大了,同时成为了通用、三菱、大众的金牌合作伙伴,于是公司要求该自动驾驶系统也能够安装在这3种公司生产的汽车上。于是我们不得不变动AutoSystem:
public class AutoSystem {
public enum CarType {
Ford, Honda, Bmw
};
HondaCar hcar = new HondaCar();
FordCarf car = new FordCar();
BmwCar bcar = new BmwCar();
private CarType type;
public AutoSystem(CarTypetype){
this.type=type;
}
private void RunCar() {
if (type == CarType.Ford) {
fcar.Run();
} else if (type == CarType.Honda) {
hcar.Run();
} else if (type == CarType.Bmw) {
bcar.Run();
}
}
private void TurnCar() {
if (type == CarType.Ford) {
fcar.Turn();
} else if (type == CarType.Honda) {
hcar.Turn();
} else if (type == CarType.Bmw) {
bcar.Turn();
}
}
private void StopCar() {
if (type == CarType.Ford) {
fcar.Stop();
} else if (type == CarType.Honda) {
hcar.Stop();
} else if (type == CarType.Bmw) {
bcar.Stop();
}
}
}分析:这会给系统增加新的相互依赖。随着时间的推移,越来越多的车种必须加入到AutoSystem中,这个“AutoSystem”模块将会被if/else语句弄得很乱,而且依赖于很多的低层模块,只要低层模块发生变动,AutoSystem就必须跟着变动,它最终将变得僵化、脆弱。
导致上面所述问题的一个原因是,含有高层策略的模块,如AutoSystem模块,依赖于它所控制的低层的具体细节的模块(如HondaCar()和FordCar())。如果我们能够找到一种方法使AutoSystem模块独立于它所控制的具体细节,那么我们就可以自由地复用它了。我们就可以用这个模块来生成其它的程序,使得系统能够用在需要的汽车上。OOD给我们提供了一种机制来实现这种“依赖倒置”。

这个简单的类图。这儿有一个“AutoSystem”类,它包含一个“ICar”接口。这个“AutoSystem”类根本不依赖于“FordCar”和“HondaCar”。所以,依赖关系被“倒置”了:“AutoSystem”模块依赖于抽象,那些具体的汽车操作也依赖于相同的抽象。
于是可以添加ICar:
public interface ICar {
void Run();
void Turn();
void Stop();
} public class BmwCar:ICar
{
public void Run() {
Console.WriteLine("宝马开始启动了");
}
public void Turn() {
Console.WriteLine("宝马开始转弯了");
}
public void Stop() {
Console.WriteLine("宝马开始停车了");
}
} public class FordCar:ICar
{
publicvoidRun()
{
Console.WriteLine("福特开始启动了");
}
public void Turn() {
Console.WriteLine("福特开始转弯了");
}
public void Stop() {
Console.WriteLine("福特开始停车了");
}
} public class HondaCar:ICar
{
publicvoidRun()
{
Console.WriteLine("本田开始启动了");
}
public void Turn() {
Console.WriteLine("本田开始转弯了");
}
public void Stop() {
Console.WriteLine("本田开始停车了");
}
} public class AutoSystem {
private ICar icar;
public AutoSystem(ICar icar) {
this.icar = icar;
}
private void RunCar() {
icar.Run();
}
private void TurnCar() {
icar.Turn();
}
private void StopCar() {
icar.Stop();
}
}
现在AutoSystem系统依赖于ICar 这个抽象,而与具体的实现细节HondaCar、FordCar、BmwCar无关,所以实现细节的变化不会影响AutoSystem。对于实现细节只要实现ICar 即可,即实现细节依赖于ICar 抽象。
【小结】:
一个应用中的重要策略决定及业务模型正是在这些高层的模块中。也正是这些模型包含着应用的特性。但是,当这些模块依赖于低层模块时,低层模块的修改将会直接影响到它们,迫使它们也去改变。这种境况是荒谬的。应该是处于高层的模块去迫使那些低层的模块发生改变。应该是处于高层的模块优先于低层的模块。
我的一句理解和总结就是,在编写业务逻辑的时候,尽量使用抽象类或者接口去编程。就想上面例子中的 AutoSystem 是利用接口 ICar 在写业务逻辑,这样具体实现就可以多样化了,高层与底层也就解耦了。
2.4 接口隔离原则(ISP)
接口隔离原则(Interface Segregation Principle):客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
- 使用多个专门的接口比使用单一的总接口要好。
- 一个类对另外一个类的依赖性应当是建立在最小的接口上的。
- 一个接口代表一个角色,不应当将不同的角色都交给一个接口。没有关系的接口合并在一起,形成一个臃肿的大接口,这是对角色和接口的污染。
- “不应该强迫客户依赖于它们不用的方法。接口属于客户,不属于它所在的类层次结构。” 不要强迫客户使用它们不用的方法,如果强迫用户使用它们不使用的方法,那么这些客户就会面临由于这些不使用的方法的改变所带来的改变。
【实例】:
比如说电子商务的系统,有订单这个类,有三个地方会使用到,
- 一个是门户,只能有查询方法;
- 一个是外部系统,有添加订单的方法;
- 一个是管理后台,添加删除修改查询都要用到。

// --这儿不用接口继承,因为可能出现修改了父接口影响了子接口
interface IOrderForPortal {
String getOrder();
} interface IOrderForOtherSys {
String insertOrder();
String getOrder();
} interface IOrderForAdmin { // extendsIOrderForPortal,IOrderForOtherSys
String deleteOrder();
String updateOrder();
String insertOrder();
String getOrder();
} class Order implements IOrderForPortal, IOrderForOtherSys, IOrderForAdmin {
private Order() {
// --什么都不干,就是为了不让直接 new,防止客户端直接New,然后访问它不需要的方法.
}
// 返回给Portal
public static IOrderForPortal getOrderForPortal() {
return (IOrderForPortal) new Order();
}
// 返回给OtherSys
public static IOrderForOtherSys getOrderForOtherSys() {
return (IOrderForOtherSys) new Order();
}
// 返回给Admin
public static IOrderForAdmin getOrderForAdmin() {
return (IOrderForAdmin) new Order();
}
// --下面是接口方法的实现.只是返回了一个String用于演示
public String getOrder() {
return "implemented getOrder";
}
public String insertOrder() {
return "implementedinsertOrder";
}
public String updateOrder() {
return "implementedupdateOrder";
}
public String deleteOrder() {
return "implementeddeleteOrder";
}
} public class TestCreateLimit {
public static void main(String[]
args){
IOrderForPortal orderForPortal =Order.getOrderForPortal();
IOrderForOtherSys orderForOtherSys =Order.getOrderForOtherSys();
IOrderForAdmin orderForAdmin = Order.getOrderForAdmin();
System.out.println("
Portal门户调用方法:"+orderForPortal.getOrder());
System.out.println("OtherSys外部
系统调用方法:"+orderForOtherSys.insertOrder());
System.out.println("Admin管理后台调用方法:"+orderForAdmin.getOrder()+";"+orderForAdmin.insertOrder()+";"+orderForAdmin.updateOrder()+";"+orderForAdmin.deleteOrder());
}
}这样就能很好的满足接口隔离原则了,调用者只能访问它自己的方法,不能访问到不应该访问的方法。
2.5 组合/聚合复用原则(CARP)
要尽量使用合成/聚合,尽量不要使用继承。在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分,新对象通过向这些对象的委派达到复用已有功能的目的。
如我们所知,在面向对象设计里,不同环境中复用已有设计和实现的基本方法:
(1)继承
(2)合成/聚合
【继承复用】:
继承复用通过扩展一个已有对象的实现来得到新的功能,基类明显地捕获共同的属性和方法,而子类通过增加新的属性和方法来扩展超类的实现。继承是类型的复用。
继承复用的优点:
- 新的实现较为容易,因为超类的大部分功能可通过继承关系自动进入子类;
- 修改或扩展继承而来的实现较为容易。
继承复用的缺点:
- 继承复用破坏封装,因为继承将超类的实现细节暴露给子类。“白箱”复用;
- 如果超类的实现发生改变,那么子类的实现也不得不发生改变。
- 从超类继承而来的实现是静态的,不可能再运行时间内发生改变,因此没有足够的灵活性。
【合成/聚合复用】:
由于合成/聚合可以将已有的对象纳入到新对象中,使之成为新对象的一部分,因此新的对象可以调用已有对象的功能。
其优点在于:
- 新对象存取成分对象的唯一方法是通过成分对象的接口;
- 成分对象的内部细节对新对象不可见。 “黑箱”复用;
- 该复用支持封装。
- 该复用所需的依赖较少。
- 每一个新的类可将焦点集中在一个任务上。
该复用可在运行时间内动态进行,新对象可动态引用于成分对象类型相同的对象。
缺点:
通过这种复用建造的系统会有较多的对象需要管理。
- 为了能将多个不同的对象作为组合块(composition block)来使用,必须仔细地对接口进行定义。
【Coad法则】:
Coad法则由Peter Coad提出,总结了一些什么时候使用继承作为复用工具的条件。 Coad法则:
- 子类是超类的一个特殊种类,而不是超类的一个角色。区分“Has-A”和“Is-A”。只有“Is-A”关系才符合继承关系,“Has-A”关系应当用聚合来描述。
- 永远不会出现需要将子类换成另外一个类的子类的情况。如果不能肯定将来是否会变成另外一个子类的话,就不要使用继承。
- 子类具有扩展超类的责任,而不是具有置换掉(override)或注销掉(Nullify)超类的责任。如果一个子类需要大量的置换掉超类的行为,那么这个类就不应该是这个超类的子类。
- 只有在分类学角度上有意义时,才可以使用继承。不要从工具类继承。
【实例】:
Sunny软件公司开发人员在初期的CRM系统设计中,考虑到客户数量不多,系统采用MySQL作为数据库,与数据库操作有关的类如CustomerDAO类等都需要连接数据库,连接数据库的方法getConnection()封装在DBUtil类中,由于需要重用DBUtil类的getConnection()方法,设计人员将CustomerDAO作为DBUtil类的子类,初始设计方案结构如图所示:

随着客户数量的增加,系统决定升级为Oracle数据库,因此需要增加一个新的OracleDBUtil类来连接Oracle数据库,由于在初始设计方案中CustomerDAO和DBUtil之间是继承关系,因此在更换数据库连接方式时需要修改CustomerDAO类的源代码,将CustomerDAO作为OracleDBUtil的子类,这将违反开闭原则。【当然也可以修改DBUtil类的源代码,同样会违反开闭原则。】
现使用合成复用原则对其进行重构。根据合成复用原则,我们在实现复用时应该多用关联,少用继承。因此在本实例中我们可以使用关联复用来取代继承复用,重构后的结构如图2所示:
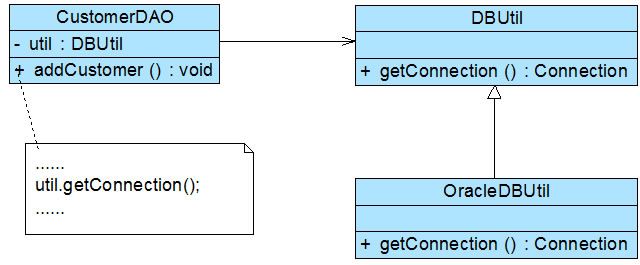
在图2中,CustomerDAO和DBUtil之间的关系由继承关系变为关联关系,采用依赖注入的方式将DBUtil对象注入到CustomerDAO中,可以使用构造注入,也可以使用Setter注入。如果需要对DBUtil的功能进行扩展,可以通过其子类来实现,如通过子类OracleDBUtil来连接Oracle数据库。由于CustomerDAO针对DBUtil编程,根据里氏代换原则,DBUtil子类的对象可以覆盖DBUtil对象,只需在CustomerDAO中注入子类对象即可使用子类所扩展的方法。例如在CustomerDAO中注入OracleDBUtil对象,即可实现Oracle数据库连接,原有代码无须进行修改,而且还可以很灵活地增加新的数据库连接方式。
2.6 迪米特法则(LoD)
迪米特法则又称为最少知识原则(LeastKnowledge Principle, LKP),其定义如下:迪米特法则(Law of Demeter, LoD):一个软件实体应当尽可能少地与其他实体发生相互作用。
如果一个系统符合迪米特法则,那么当其中某一个模块发生修改时,就会尽量少地影响其他模块,扩展会相对容易,这是对软件实体之间通信的限制,迪米特法则要求限制软件实体之间通信的宽度和深度。迪米特法则可降低系统的耦合度,使类与类之间保持松散的耦合关系。
迪米特法则还有几种定义形式,包括:不要和“陌生人”说话、只与你的直接朋友通信等,在迪米特法则中,对于一个对象,其朋友包括以下几类:
(1) 当前对象本身(this);
(2) 以参数形式传入到当前对象方法中的对象;
(3) 当前对象的成员对象;
(4) 如果当前对象的成员对象是一个集合,那么集合中的元素也都是朋友;
(5) 当前对象所创建的对象。
任何一个对象,如果满足上面的条件之一,就是当前对象的“朋友”,否则就是“陌生人”。在应用迪米特法则时,一个对象只能与直接朋友发生交互,不要与“陌生人”发生直接交互,这样做可以降低系统的耦合度,一个对象的改变不会给太多其他对象带来影响。
迪米特法则要求我们在设计系统时,应该尽量减少对象之间的交互,如果两个对象之间不必彼此直接通信,那么这两个对象就不应当发生任何直接的相互作用,如果其中的一个对象需要调用另一个对象的某一个方法的话,可以通过第三者转发这个调用。【简言之,就是通过引入一个合理的第三者来降低现有对象之间的耦合度。】
在将迪米特法则运用到系统设计中时,要注意下面的几点:
- 在类的划分上,应当尽量创建松耦合的类,类之间的耦合度越低,就越有利于复用,一个处在松耦合中的类一旦被修改,不会对关联的类造成太大波及;
- 在类的结构设计上,每一个类都应当尽量降低其成员变量和成员函数的访问权限;
- 在类的设计上,只要有可能,一个类型应当设计成不变类;
在对其他类的引用上,一个对象对其他对象的引用应当降到最低。
下面通过一个简单实例来加深对迪米特法则的理解:
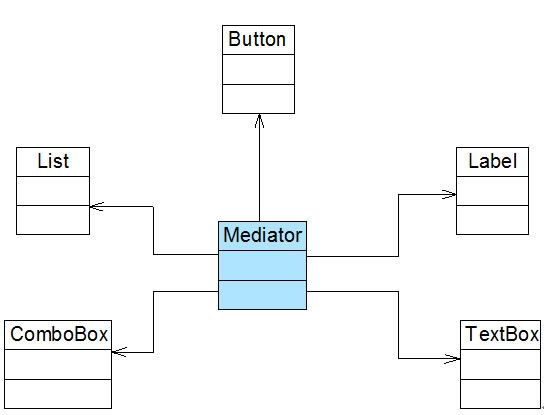
Sunny软件公司所开发CRM系统包含很多业务操作窗口,在这些窗口中,某些界面控件之间存在复杂的交互关系,一个控件事件的触发将导致多个其他界面控件产生响应,例如,当一个按钮(Button)被单击时,对应的列表框(List)、组合框(ComboBox)、文本框(TextBox)、文本标签(Label)等都将发生改变,在初始设计方案中,界面控件之间的交互关系可简化为如图1所示结构:

在图1中,由于界面控件之间的交互关系复杂,导致在该窗口中增加新的界面控件时需要修改与之交互的其他控件的源代码,系统扩展性较差,也不便于增加和删除新控件。 现使用迪米特对其进行重构。
在本实例中,可以通过引入一个专门用于控制界面控件交互的中间类(Mediator)来降低界面控件之间的耦合度。引入中间类之后,界面控件之间不再发生直接引用,而是将请求先转发给中间类,再由中间类来完成对其他控件的调用。当需要增加或删除新的控件时,只需修改中间类即可,无须修改新增控件或已有控件的源代码,重构后结构如图2所示:
2.7 单一职责原则(SRP)
单一职责原则是最简单的面向对象设计原则,它用于控制类的粒度大小。单一职责原则定义如下:
单一职责原则(Single Responsibility Principle, SRP):一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。单一职责原则告诉我们:一个类不能太“累”!在软件系统中,一个类(大到模块,小到方法)承担的职责越多,它被复用的可能性就越小,而且一个类承担的职责过多,就相当于将这些职责耦合在一起,当其中一个职责变化时,可能会影响其他职责的运作,因此要将这些职责进行分离,将不同的职责封装在不同的类中,即将不同的变化原因封装在不同的类中,如果多个职责总是同时发生改变则可将它们封装在同一类中。
单一职责原则是实现高内聚、低耦合的指导方针,它是最简单但又最难运用的原则,需要设计人员发现类的不同职责并将其分离,而发现类的多重职责需要设计人员具有较强的分析设计能力和相关实践经验。
下面通过一个简单实例来进一步分析单一职责原则:
Sunny软件公司开发人员针对某CRM(Customer Relationship Management,客户关系管理)系统中客户信息图形统计模块提出了如图1所示初始设计方案:

在图1中,CustomerDataChart类中的方法说明如下:getConnection()方法用于连接数据库,findCustomers()用于查询所有的客户信息,createChart()用于创建图表,displayChart()用于显示图表。
现使用单一职责原则对其进行重构。在图1中,CustomerDataChart类承担了太多的职责,既包含与数据库相关的方法,又包含与图表生成和显示相关的方法。如果在其他类中也需要连接数据库或者使用findCustomers()方法查询客户信息,则难以实现代码的重用。无论是修改数据库连接方式还是修改图表显示方式都需要修改该类,它不止一个引起它变化的原因,违背了单一职责原则。因此需要对该类进行拆分,使其满足单一职责原则,类CustomerDataChart可拆分为如下三个类:
(1) DBUtil:负责连接数据库,包含数据库连接方法getConnection();
(2) CustomerDAO:负责操作数据库中的Customer表,包含对Customer表的增删改查等方法,如findCustomers();
(3) CustomerDataChart:负责图表的生成和显示,包含方法createChart()和displayChart()。
使用单一职责原则重构后的结构如图2所示:
