本文是我们学院课程的一部分,该课程的标题为Java开发人员的Elasticsearch教程 。
在本课程中,我们提供了一系列教程,以便您可以开发自己的基于Elasticsearch的应用程序。 我们涵盖了从安装和操作到Java API集成和报告的广泛主题。 通过我们简单易懂的教程,您将能够在最短的时间内启动并运行自己的项目。 在这里查看 !
1.简介
有效,快速和准确的搜索功能是绝大多数现代应用程序和软件平台的组成部分。 您正在运行的是小型电子商务网站,需要为客户提供产品目录搜索,或者您是服务提供商,需要公开API以使开发人员可以过滤用户和公司,或者您正在构建任何这类消息传递应用程序从一开始就必须在历史中查找对话……真正重要的是,尽可能快地提供相关结果可能是您正在开发的产品或平台的另一个竞争优势。 。
目录
-
1.简介 2. Elasticsearch基础
-
-
2.1。 文件资料 2.2。 指标 2.3。 索引设定 2.4。 对应 2.5。 高级映射 2.6。 索引编制 2.7。 内部化(i18n)
3.运行Elasticsearch
-
-
3.1。 独立实例 3.2。 聚类 3.3。 嵌入应用 3.4。 作为容器运行
4. Elasticsearch适合的地方 5.结论 6.接下来
确实,搜索可能具有许多面Kong,目的,目标和不同的规模。 它可能像通过精确的单词匹配查找一样简单,也可能像试图理解一个人正在寻找的单词的意图和上下文含义一样复杂( 语义搜索引擎)。 就规模而言,它可能像查询单个数据库表一样琐碎,也可能像处理数十亿个网页一样复杂以提供所需的结果。 这是一个非常有趣且蓬勃发展的研究领域,多年来发表了许多算法和论文。
如果您是Java / JVM开发人员,则可能听说过Apache Lucene项目,这是一个高性能,功能齐全的索引和搜索库。 这是释放全文搜索功能并将其嵌入到您的应用程序中的第一个也是最好的选择。 尽管它绝对是一个了不起的库,但是许多开发人员发现Apache Lucene的级别太低并且不易于使用。 这就是另外两个伟大的项目Elasticsearch和Apache Solr诞生的原因之一。
在本教程中,我们将讨论Elasticsearch ,重点放在事物的开发方面而不是操作方面。 我们将学习Elasticsearch的基础知识,熟悉术语,并讨论在Java / JVM应用程序或命令行中运行它以及与之通信的不同方法。 在本教程的最后,我们将讨论Elastic Stack,以展示Elasticsearch周围的生态系统及其惊人的功能。
如果您是初级或经验丰富的Java / JVM开发人员,并且对学习Elasticsearch感兴趣,那么本教程绝对适合您。
2. Elasticsearch基础
首先,很高兴回答这个问题:那么, Elasticsearch是什么,它如何帮助我以及为什么要使用它?
Elasticsearch是一个高度可扩展的开源全文本搜索和分析引擎。 它使您可以快速,近乎实时地存储,搜索和分析大量数据。 它通常用作支持具有复杂搜索功能和要求的应用程序的基础引擎/技术。 – https://www.elastic.co/
Elasticsearch是基于Apache Lucene构建的,但是更倾向于通过RESTful API和高级深度分析功能进行通信。 RESTful部分使Elasticsearch特别易于学习和使用。 在撰写本文时, Elasticsearch的最新稳定发行版是5.2 ,而最新发行版本是5.2.0 。 我们绝对应该让Elasticsearch家伙保持如此频繁地发布新版本的步伐,因为5.0.x / 5.1.x分支仅仅成立了几个月……。
从Elasticsearch的角度来看,作为RESTful API的另一个优势是:发送到Elasticsearch或从Elasticsearch接收的每条数据本身都是人类可读的JSON文档(尽管这不是Elasticsearch支持的唯一协议,我们稍后将看到) 。
为了使讨论更切合实际,我们将假装我们正在开发用于管理书籍目录的应用程序。 数据模型将包括类别,作者,出版商,书籍详细信息(例如出版日期,ISBN,等级)和简要说明。

书籍目录
让我们看看如何利用Elasticsearch使我们的书籍目录易于搜索,但是在此之前我们需要对术语有所了解。 尽管在接下来的几节中,我们将讨论Elasticsearch背后的大多数概念,但请随时随时查阅Elasticsearch的官方文档 。
文件资料
简而言之,在Elasticsearch文档的上下文中,它只是任意数据(通常是结构化的)。 它绝对是对您的应用程序有意义的任何事物(例如用户,日志,博客文章,文章,产品等),但这是Elasticsearch可以操纵的基本信息单元。
指标
Elasticsearch将文档存储在索引中,因此,索引只是文档的集合。 公平地讲,将完全不同种类的文档保留在同一索引中会比较方便,但是却很难使用,因此每个索引都可以具有一个或多个类型。 这些类型通过定义每个此类文档应具有的一组公共属性(或字段)来对文档进行逻辑分组。 类型用作有关文档的元数据,对于探索数据的结构以及构建有意义的查询和聚合非常有用。
索引设定
Elasticsearch中的每个索引在创建时都可以具有与之关联的特定设置。 最重要的是分片数和复制因子。 让我们谈论一下。
Elasticsearch是从头开始构建的,可以处理大量索引数据,这些数据很可能会超出单个物理(或虚拟)计算机实例的内存和/或存储能力。 因此, Elasticsearch使用分片作为一种机制,将索引分为几个较小的部分(称为分片),并将其分配到许多节点中。 请注意,一旦设置了分片的数量就无法更改(尽管这不再是完全正确的,但索引可以缩减为更少的分片 )。
确实,分片解决了一个实际的问题,但是由于单个节点故障,它很容易遭受数据丢失问题的困扰。 为了解决此问题, Elasticsearch通过利用复制来支持高可用性。 在这种情况下,根据复制因素, Elasticsearch会维护每个分片的一个或多个副本,并确保每个分片的副本位于不同的节点上。
对应
定义文档类型并将其分配给特定索引的过程称为索引映射,映射类型或仅称为映射。 为了充分利用Elasticsearch ,正确的类型映射可能是您必须进行的最重要的设计练习之一。 让我们花一些时间详细讨论映射。
每个映射都包含可选的元字段(它们通常从下划线'_'字符开始,例如_index , _id , _parent )和常规文档字段(或属性)。 每个字段(或属性)都有一个数据 类型 ,在Elasticsearch中它可以属于以下类别之一:
- 简单数据类型
- 文本 –索引全文值
- 复合数据类型
- 对象 –索引内部对象,这些对象又可能包含内部对象本身
- 专用数据类型
- geo_point –索引纬度-经度对
- 范围数据类型:
- integer_range –索引有符号的32位整数范围
压力不够大,为文档的字段(属性)选择适当的数据类型是快速有效搜索(提供真正相关结果)的关键。 但是有一个问题:每种映射类型中的字段并不完全相互独立。 具有相同名称和相同索引但具有 不同映射类型的字段必须具有相同的映射定义 。 原因是内部将这些字段映射到同一字段 。
回到我们的应用程序数据模型,让我们尝试利用我们刚刚获得的有关数据类型的知识,为books收藏定义最简单的映射类型。

映射图书目录:首次尝试
对于大多数书籍属性,映射数据类型非常简单,但是作者和categories如何呢? 这些属性本质上包含Elasticsearch尚无直接数据类型的值的集合,…还是有?
高级映射
有趣的是, Elasticsearch实际上没有专用的数组或集合类型,但是默认情况下,任何字段都可以包含零个或多个(其数据类型)值。
对于复杂的数据结构, Elasticsearch支持使用对象和嵌套数据类型进行映射,以及在同一索引内的文档之间建立父子关系。 每种方法都有优点和缺点,但是为了学习如何使用这些技术,让我们将categories存储为books映射类型的嵌套属性,而authors将被表示为将books作为父对象的专用映射。
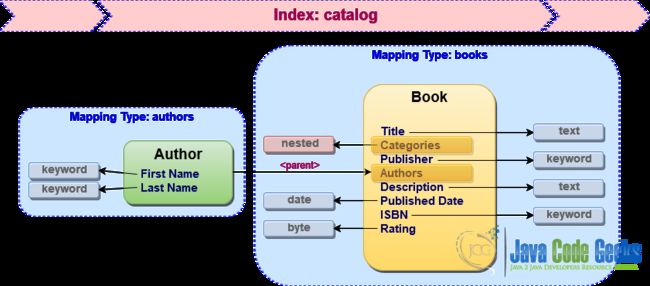
映射图书目录:第二次(也是最后一次)
这些是我们接近catalog索引的最终映射类型。 众所周知, JSON是Elasticsearch的一等公民,因此让我们了解一下典型索引映射在Elasticsearch实际理解的格式中的样子。
{
"mappings": {
"books": {
"_source" : {
"enabled": true
},
"properties": {
"title": { "type": "text" },
"categories" : {
"type": "nested",
"properties" : {
"name": { "type": "text" }
}
},
"publisher": { "type": "keyword" },
"description": { "type": "text" },
"published_date": { "type": "date" },
"isbn": { "type": "keyword" },
"rating": { "type": "byte" }
}
},
"authors": {
"properties": {
"first_name": { "type": "keyword" },
"last_name": { "type": "keyword" }
},
"_parent": {
"type": "books"
}
}
}
}您可能会感到惊讶,但是可能会省略字段和映射类型的明确定义。 Elasticsearch支持动态映射,因此在为文档建立索引时会自动添加新的映射类型和新的字段名称(在这种情况下, Elasticsearch决定应使用的字段数据类型)。
要提及的另一个重要细节是,通过使用特殊的_meta属性,每个映射类型都可以具有与之关联的自定义元数据 。 这是一种非常有用的技术,稍后我们将在本教程中使用。
索引编制
一旦Elasticsearch定义了所有索引及其映射类型(或使用dynamic mapping推断),即可开始分析和索引文档。 这是一个非常复杂但有趣的过程 ,至少涉及分析器 , 令牌生成 器 , 令牌过滤器和字符过滤器 。
Elasticsearch支持大量映射参数 ,可让您精确地根据需要定制索引,分析和搜索阶段。 例如,每个字段(或属性)都可以配置为使用自己的索引时间和搜索时间分析器 ,支持同义词 ,应用词干分析 ,过滤停用词等等。 通过精心设计这些参数,您最终可能会拥有出色的搜索功能,但是相反的情况也是如此,使它们变得松散,并且每次都可能返回许多无关紧要的结果。
如果您不需要所有这些,那么最好使用上一部分中的默认设置,而完全省略这些参数。 但是,这种情况很少发生。 举一个现实的例子,大多数时候我们的应用程序必须支持多种语言(和语言环境)。 幸运的是, Elasticsearch也在这里闪耀。
在继续讨论下一个主题之前,您需要了解一个重要的约束。 一旦配置了映射类型,在大多数情况下, 它们将无法更新,因为它会自动假定相应集合中的所有文档都不再是最新的,应该重新编制索引。
内部化(i18n)
索引和分析文档的过程对文档的本地语言非常敏感。 默认情况下,如果在映射类型中未指定标准分析器 ,则Elasticsearch使用标准分析器 。 它适用于大多数语言,但是Elasticsearch为阿拉伯语,亚美尼亚语,巴斯克语,巴西语,保加利亚语,捷克语,丹麦语,荷兰语,英语,芬兰语,法语,德语,希腊语,印地语,匈牙利语,印度尼西亚语,爱尔兰语,意大利语提供专用的分析器 ,拉脱维亚语,立陶宛语,挪威语,波斯语,葡萄牙语,罗马尼亚语,俄语,西班牙语,瑞典语,土耳其语,泰语等等 。
根据数据模型和业务案例,有几种方法可以用多种语言对同一文档建立索引。 例如,如果文档实例实际上以多种语言存在(翻译),则每种语言都具有一个索引可能是有意义的。
万一文档被部分翻译, Elasticsearch在袖子中还有一个有趣的选项,称为multi-fields 。 多字段允许以不同方式索引同一文档字段(属性)以用于不同目的(例如,支持多种语言)。 回到我们的books映射类型,我们可能已经将title属性定义为一个多字段属性,例如:
"title": {
"type": "text",
"fields": {
"en": { "type": "text", "analyzer": "english" },
"fr": { "type": "text", "analyzer": "french" },
"de": { "type": "text", "analyzer": "german" },
...
}
}这些不是唯一可用的选项,但是它们充分说明了Elasticsearch在满足相当复杂的需求方面的灵活性和成熟度。
3.运行Elasticsearch
Elasticsearch在许多方面都包含了简单性,其中之一是通过任何两个步骤即可在几乎任何平台上入门的非常简单的方法: 下载并运行 。 在接下来的两节中,我们将讨论启动和运行Elasticsearch的许多不同方法。
独立实例
将Elasticsearch作为独立应用程序(或实例)运行是采取最快和最简单的方法。 只需下载您选择的软件包并在Linux / Unix / Mac操作系统上运行shell脚本即可:
bin/elasticsearch或从Windows操作系统上的批处理文件中:
bin\elasticsearch.bat 就是这样,很简单,不是吗? 但是,在继续讨论更高级的选项之前,了解一下运行Elasticsearch实例的实际含义将很有用。 更确切地说,每次我们说要启动Elasticsearch实例时,实际上是在启动node实例。 这样,根据提供的配置(默认情况下,它存储在conf/elastisearch.yml文件中), Elasticsearch目前支持多种节点类型 。 在这方面,可以将每个正在运行的Elasticsearch独立实例配置为作为以下节点类型之一(或组合)运行:
- 数据节点 :此类节点正在维护数据并对该数据执行操作(由
node.data配置设置控制,默认情况下设置为true) - 接收节点 :这些是特殊类型的节点,它们能够应用接收管道以便在对文档建立索引之前对其进行转换和丰富(它由
node.ingest配置设置控制,默认情况下设置为true)
请注意,这还不是一个完整的节点类型列表,我们将在稍后学习更多。
聚类
将Elasticsearch作为独立实例运行对于开发,学习或测试目的是有好处的,但是肯定不是生产系统的选择。 通常,在大多数实际部署中, Elasticsearch配置为在集群中运行:一个或多个节点的集合最好拆分为多个物理实例。 Elasticsearch集群管理所有数据,并在其所有节点上提供联合索引,聚合和搜索功能。
每个Elasticsearch群集均由一个唯一的名称标识,该名称由cluster.name配置设置控制(默认设置为"elasticsearch" )。 节点通过引用其名称加入群集,因此这是非常重要的配置。 最后但并非最不重要的一点是,每个集群都有一个专用的主节点,该主节点负责执行集群范围的动作和操作。
除适用于集群配置外, Elasticsearch还支持其他几种节点类型,除了我们已经知道的那些类型:
- 符合资格的主节点 :这些类型的节点被标记为有资格被选举为主节点 (它由
node.master配置设置控制,默认情况下设置为true) - 仅协调节点 :这是一种特殊类型的节点,仅能路由请求,处理某些搜索阶段并分配批量索引,本质上表现为负载均衡器(当
node.master,node.data时,该节点自动成为仅协调节点和node.ingest设置都设置为false) - 部落节点 :这是一种特殊的仅协调节点 ,可以连接到多个集群并在所有集群中执行搜索或其他操作(由
tribe.*控制tribe.*配置设置)
默认情况下,如果未指定configuration,则每个Elasticsearch节点均配置为符合master资格 , data节点和ingest节点 。 与独立实例类似, Elasticsearch群集实例可以从命令行快速启动:
bin/elasticsearch -Ecluster.name= -Enode.name= 或在Windows平台上:
bin\elasticsearch.bat -Ecluster.name= -Enode.name= 除了分片和复制外, Elasticsearch集群还具有高可用性和可扩展系统的所有属性,这些系统将有机地发展以满足您的应用程序需求。 需要注意的是,尽管投入了大量精力来稳定Elasticsearch集群的实现并涵盖了与不同类型的故障场景相关的许多极端情况,但到目前为止,仍不建议将Elasticsearch用作记录系统(或主要存储引擎)。您的数据)。
嵌入应用
不久之前(直到5.0版本分支), Elasticsearch完全支持在同一JVM进程(通常称为嵌入)中作为应用程序的一部分运行的选项。 尽管当然不建议这样做,但有时它非常有用,并且可以节省很多精力,例如在集成/系统/组件测试运行期间。
这种情况最近有所改变,Elasticsearch的嵌入式版本不再得到正式支持,也不再推荐使用。 幸运的是,如果您确实需要嵌入式实例,例如在从较早的Elasticsearch版本缓慢迁移的同时, 仍然可以 。
@Configuration
public class ElasticsearchEmbeddedConfiguration {
private static class EmbeddedNode extends Node {
public EmbeddedNode(Settings preparedSettings) {
super(
InternalSettingsPreparer.prepareEnvironment(preparedSettings, null),
Collections.singletonList(Netty4Plugin.class)
);
}
}
@Bean(initMethod = "start", destroyMethod = "stop")
Node elasticSearchTestNode() throws NodeValidationException, IOException {
return new EmbeddedNode(
Settings
.builder()
.put(NetworkModule.TRANSPORT_TYPE_KEY, "netty4")
.put(NetworkModule.HTTP_TYPE_KEY, "netty4")
.put(NetworkModule.HTTP_ENABLED.getKey(), "true")
.put(Environment.PATH_HOME_SETTING.getKey(), home().getAbsolutePath())
.put(Environment.PATH_DATA_SETTING.getKey(), data().getAbsolutePath())
.build());
}
@Bean
File home() throws IOException {
return Files.createTempDirectory("elasticsearch-home-").toFile();
}
@Bean
File data() throws IOException {
return Files.createTempDirectory("elasticsearch-data-").toFile();
}
@PreDestroy
void destroy() throws IOException {
FileSystemUtils.deleteRecursively(home());
FileSystemUtils.deleteRecursively(data());
}
}尽管此代码段基于出色的Spring框架 ,但该想法非常简单,可以在任何基于JVM的应用程序中使用。 话虽如此,但请注意并重新考虑长期解决方案,而无需嵌入Elasticsearch 。
作为容器运行
诸如Docker , CoreOS之类的工具的兴起以及容器的巨大普及以及基于容器的部署大大改变了我们对基础架构的看法,在许多情况下,也改变了我们的开发方法。
换句话说,无需下载Elasticsearch并使用shell脚本或批处理文件运行它。 一切都是容器,可以使用单个docker命令将其拉出,配置和运行(很幸运,这里有一个官方的Elasticseach Dockerhub存储库 )。
假设您的机器上已安装Docker ,让我们依靠默认配置运行单个Elasticsearch实例:
docker run -d -p 9200:9200 -p 9300:9300 elasticsearch:5.2.0旋转Elasticsearch集群比使用shell脚本手动完成要复杂一些,但肯定要容易得多。 总的来说, Elasticsearch集群需要多播支持才能使节点彼此自动发现,但是不幸的是,使用Docker,您将需要退回到单播发现 (除非您已订阅以解锁商业功能 )。
docker run -d -p 9200:9200 -p 9300:9300 --name es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es1 -E transport.host=0.0.0.0docker run -d --name es2 --link=es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es2 -E transport.host=0.0.0.0 -E discovery.zen.ping.unicast.hosts=es1docker run -d --name es3 --link=es1 elasticsearch:5.2.0 -E cluster.name=es-catalog -E node.name=es3 -E transport.host=0.0.0.0 -E discovery.zen.ping.unicast.hosts=es1 启动容器后,应创建三个Elasticsearch节点的集群,并可以从http://localhost:9200访问主节点(如果支持本机Docker )。 如果由于某些原因您仍在Docker Machine上 (甚至是较旧的boot2docker ),则主节点将分别在http://处公开。
如果您正在积极使用Docker Compose ,那么某些限制将使您的生活变得复杂。 目前, Elasticsearch映像需要将一些参数传递到入口点(在命令行末尾看到的所有内容都是-E选项),但是Docker Compose还不支持这种功能(尽管您可以将自己的映像构建为解决方法)。
在本教程中,我们将仅使用从Docker容器开始的Elasticsearch ,希望这是您早已采用的方法。
4. Elasticsearch适合的地方
搜索是Elasticsearch的关键功能之一,并且做得非常好。 但是, Elasticsearch不仅限于搜索,还提供了丰富的分析功能,其形状被称为聚合框架 ,该框架基于搜索查询进行数据聚合。 万一您需要对数据进行一些分析, Elasticsearch在这里也非常适合。
尽管可能不会立即显现出来,但Elasticsearch可用于管理时间序列数据 (例如,指标,股票价格),甚至可以反向搜索图像 。 关于Elasticsearch的误解之一是它可以用作数据存储。 从某种程度上讲,它确实存储了数据,但是它没有提供与典型数据存储相同的保证。
5.结论
尽管我们在这里谈论了很多事情,但是Elasticsearch的大量有趣细节和有用功能还没有被涵盖。 我们的重点一直放在事物的开发方面,因此,重点一直放在理解Elasticsearch的基础上并Swift开始。 希望您已经感到兴奋和兴奋,可以马上开始阅读官方文档参考 ,因为还有更多有趣的话题正在讨论中。
6.接下来
在下一部分中,我们将通过探索和使用Elasticsearch公开的无数RESTful API (仅使用命令行和出色的curl / http工具进行武装)来从讨论进入操作。
这篇文章的源代码可以在这里下载。
翻译自: https://www.javacodegeeks.com/2017/02/elasticsearch-java-developers-introduction.html