一、GCN简介
GCN总结

GNN模型主要研究图节点的表示(Graph Embedding),图边结构预测任务和图的分类问题,后两个任务也是基于Graph Embedding展开的。目前论文重点研究网络的可扩展性、动态性、加深网络。

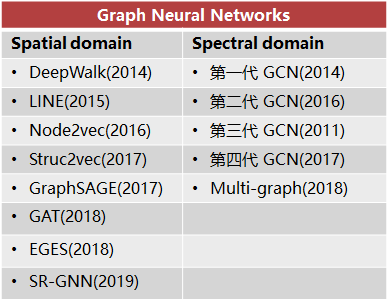
谱卷积有理论支持,但有时候会受到拉普拉斯算子的限制;而空间域卷积更加灵活,主要困难在于选择定量邻域上,没有统一理论。
未来方向:
- 加深网络: 研究表明随着网络层数增加,模型性能急剧下降
- 感受野:节点的感受野是指一组节点,包括中心节点和其近邻节点,有些节点可能只有一个近邻,而有些节点却有数千个近邻
- 可扩展性:大部分图神经网络并不能很好地扩展到大型图上。
- 动态性和异质性:大多数当前的图神经网络都处理静态同质图。一方面,假设图架构是固定的。另一方面,假设图的节点和边来自同一个来源。
GCN模型具备深度学习的三种性质:
- 层级结构(特征一层一层抽取,一层比一层更抽象,更高级)
- 非线性变换 (增加模型的表达能力)
- 端对端训练(不需要再去定义任何规则,只需要给图的节点一个标记,让模型自己学习,融合特征信息和结构信息。)
GCN的四个特征:
- GCN 是对卷积神经网络在 graph domain 上的自然推广
- 它能同时对节点特征信息与结构信息进行端对端学习,是目前对图数据学习任务的最佳选择。
- 图卷积适用性极广,适用于任意拓扑结构的节点与图。
- 在节点分类与边预测等任务上,在公开数据集上效果要远远优于其他方法。
通过谱图卷积的局部一阶近似,来确定卷积网络结构,通过图结构数据中部分有标签的节点数据对卷积神经网络结构模型训练,使网络模型对其余无标签的数据进行进一步分类。
二、spectral domain
1.离散卷积是什么,在CNN中发挥什么作用?
离散卷积本质:加权求和
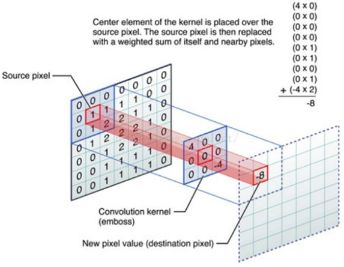
CNN中的卷积本质上就是利用一个共享参数的过滤器(kernel),**通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取**,当然加权系数就是卷积核的权重系数。
那么卷积核的系数如何确定的呢?是随机化初值,然后根据误差函数通过反向传播梯度下降进行迭代优化。这是一个关键点,**卷积核的参数通过优化求出才能实现特征提取的作用,GCN的理论很大一部分工作就是为了引入可以优化的卷积参数。**
2.GCN中的Graph是指什么?为什么要研究GCN?
CNN是Computer Vision里的法宝,效果为什么好呢?原因在上面已经分析过了,可以很有效地提取空间特征。但是有一点需要注意:**CNN处理的图像或者视频数据中像素点(pixel)是排列成成很整齐的矩阵**(如图2所示,也就是很多论文中所提到的Euclidean Structure)。

与之相对应,科学研究中还有很多Non Euclidean Structure的数据,如图3所示。社交网络、信息网络中有很多类似的结构。
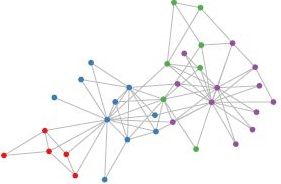
实际上,这样的网络结构(Non Euclidean Structure)就是图论中抽象意义上的拓扑图。
所以,**Graph Convolutional Network中的Graph是指数学(图论)中的用顶点和边建立相应关系的拓扑图。**
那么为什么要研究GCN?原因有二:
(1)因为CNN无法处理非欧几里得结构的数据,学术上的表述是传统的离散卷积在非欧几里得结构的数据上无法保持平移不变性。通俗来说就是在拓扑图中每个顶点的相邻顶点数目都可能不同,那就没办法用一个同样尺寸的卷积核来进行卷积操作;
(2)广义来讲任何数据在赋范空间内都可以建立拓扑关联,谱聚类就是应用了这样的思想,所以说拓扑连接是一种广义的数据结构,GCN有很大的应用空间。
综上,GCN是要为除CV、NLP之外的任务提供一种处理、研究的模型。
3.提供拓扑图空间特征的两种方式
(1)vertex domain(spatial domain)
提取拓扑图上的空间特征,就是把每个顶点的相邻neighbors找出来
a.按照什么条件去找中心vertex的neighbors,如何确定receptive filed?
b.确定了receptive field之后,按照什么方式处理包含不同数目neighbors的特征?
Learning Convolutional Neural Networks for Graphs

这种方法主要的缺点如下:
c.每个顶点提取出来的neighbors不同,使得计算处理必须针对每个顶点
d.提取特征的效果可能没有卷积好
(2)spectral domain
借助图谱的理论来实现拓扑图上的卷积操作。从研究的时间进程来看:首先研究GSP(graph signal processing)的学者定义了graph上的傅里叶变换,进而定义了graph上的卷积,最后与深度学习结合提出了Graph convolutional network.
- Q1 什么是Spectral graph theory?
- 简单的概括就是**借助于图的拉普拉斯矩阵的特征值和特征向量来研究图的性质**
- Q2 GCN为什么要利用Spectral graph theory?
- 这应该是看论文过程中读不懂的核心问题了,要理解这个问题需要大量的数学定义及推导,短期内难以驾驭,有时间再补
4.什么是拉普拉斯矩阵?为什么GCN要用拉普拉斯矩阵?
Graph Fourier Transformation及Graph Convolution定义都用到图的拉普拉斯矩阵,那么首先来介绍一下拉普拉斯矩阵。
对于图 G =(V,E ) G=(V,E)
NO.2:Symmetric normalized Laplacian: Lsy s=D−1/2LD −1/2Lsys=D−1/2LD−1/2
为什么GCN要用拉普拉斯矩阵?
(1)拉普拉斯矩阵是对称矩阵,可以进行特征分解(谱分解),这就和GCN的spectral domain对应上了
(2)拉普拉斯矩阵只在中心顶点和一阶相连的顶点上(1-hop neighbor)有非0元素,其余之处均为0
(3)通过拉普拉斯算子与拉普拉斯矩阵进类比(详见第6节)
5.拉普拉斯矩阵的谱分解(特征分解)
矩阵的谱分解,特征分解,对角化都是同一个概念
不是所有的矩阵都可以特征分解**,其充要条件为n阶方阵存在n个线性无关的特征向量。
但是拉普拉斯矩阵是半正定对称矩阵**(半正定矩阵本身就是对称矩阵)有如下三个性质:
- 对称矩阵一定n个线性无关的特征向量
- 半正定矩阵的特征值一定非负
- 对阵矩阵的特征向量相互正交,即所有特征向量构成的矩阵为正交矩阵。
由上可以知道拉普拉斯矩阵一定可以谱分解,且分解后有特殊的形式。
对于拉普拉斯矩阵其谱分解为: