倒排索引原理学习笔记
segment
segment即是倒排索引,
特点是只能 合并或者删除,不能修改
每一次refresh会产生一次 segment, 然后合并存储。
每个搜索请求需要访问所有segment,
参数 说明
index.merge.policy.floor_segment 默认2MB,小于该值的segment优先被合并
index.merge.policy.max_merge_at_once 默认10,一次最多合并多少segment
index.merge.policy.max_merged_segment 默认5GB,超过该值的segment不合并
index.merge.policy.max_merge_at_once_explicit 显式调用一次最多合并多少个segment
refresh: 将document转换为segment的过程,在ES中数据会从index-buffer到filesystem-cache的过程。
倒排索引主要分两个部分
单词词典
倒排文件
es写入工作流程
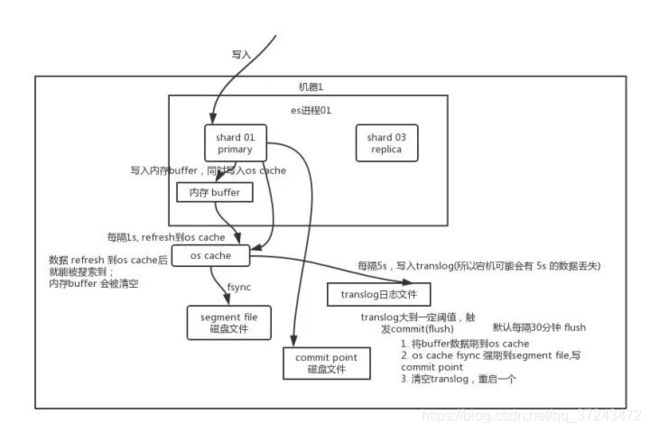
先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据 refresh 到一个新的 segment file 中
但是此时数据不是直接进入 segment file 磁盘文件,而是先进入 os cache 。这个过程就是 refresh。
每隔 1 秒钟,es 将 buffer 中的数据写入一个新的 segment file,每秒钟会产生一个新的磁盘文件 segment file
这个 segment file 中就存储最近 1 秒内 buffer 中写入的数据。
但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作
如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
操作系统里面,磁盘文件其实都有一个东西,叫做 os cache,即操作系统缓存
就是说数据写入磁盘文件之前,会先进入 os cache,先进入操作系统级别的一个内存缓存中去。只要 buffer中的数据被 refresh 操作刷入 os cache中,这个数据就可以被搜索到了。
es读数据流程

可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
客户端发送请求到任意一个 node,成为 coordinate node。
coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
接收请求的 node 返回 document 给 coordinate node。
coordinate node 返回 document 给客户端。
es 搜索数据过程
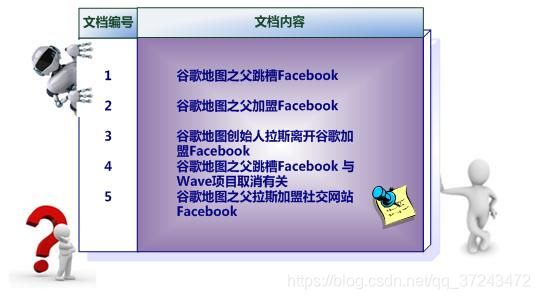
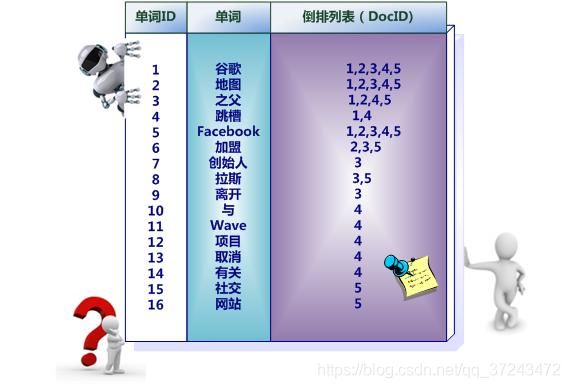
es 最强大的是做全文检索,就是比如你有三条数据:
java真好玩儿啊java好难学啊j2ee特别牛
你根据 java 关键词来搜索,将包含 java的 document 给搜索出来。es 就会给你返回:java真好玩儿啊,java好难学啊。
客户端发送请求到一个 coordinate node。
协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard,都可以。
query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
写请求是写入 primary shard,然后同步给所有的 replica shard;
读请求可以从 primary shard 或 replica shard 读取,采用的是随机轮询算法。
倒排索引基本概念解释
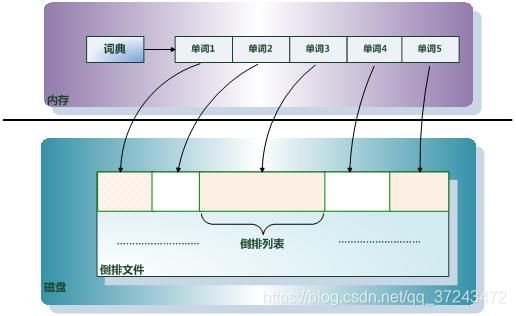
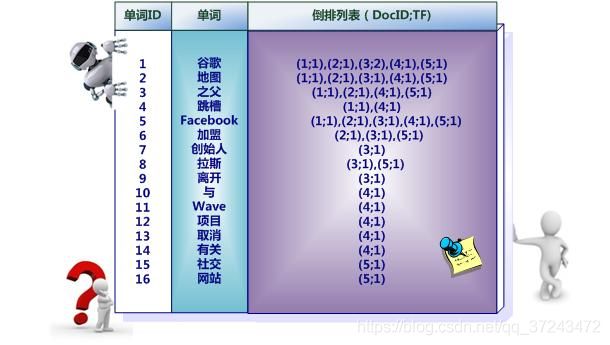
倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
简单示例
lucene 存储词典方式
类HashMap , B+树, FST
FST:
我们就用Alice和Alan这两个单词为例,来看下FST的构造过程。首先对所有的单词做一下排序为“Alice”,“Alan”。
插入“Alan”

插入“Alice”

这样你就得到了一个有向无环图,有这样一个数据结构,就可以很快查找某个人名是否存在。FST在单term查询上可能相比hashmap并没有明显优势,甚至会慢一些。但是在范围,前缀搜索以及压缩率上都有明显的优势。
在通过FST定位到倒排链后,有一件事情需要做,就是倒排链的合并。因为查询条件可能不止一个,例如上面我们想找name=“alan” and age="18"的列表。lucene是如何实现倒排链的合并呢。这里就需要看一下倒排链存储的数据结构
SkipList
为了能够快速查找docid,lucene采用了SkipList这一数据结构。SkipList有以下几个特征:
元素排序的,对应到我们的倒排链,lucene是按照docid进行排序,从小到大。
跳跃有一个固定的间隔,这个是需要建立SkipList的时候指定好,例如下图以间隔是3
SkipList的层次,这个是指整个SkipList有几层
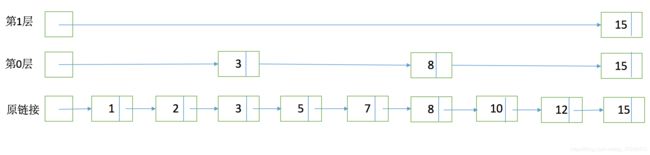
有了这个SkipList以后比如我们要查找docid=12,原来可能需要一个个扫原始链表,1,2,3,5,7,8,10,12。有了SkipList以后先访问第一层看到是然后大于12,进入第0层走到3,8,发现15大于12,然后进入原链表的8继续向下经过10和12。
有了FST和SkipList的介绍以后,我们大体上可以画一个下面的图来说明lucene是如何实现整个倒排结构的:

有了这张图,我们可以理解为什么基于lucene可以快速进行倒排链的查找和docid查找,下面就来看一下有了这些后如何进行倒排链合并返回最后的结果。
倒排合并
假如我们的查询条件是name = “Alice”,那么按照之前的介绍,首先在term字典中定位是否存在这个term,如果存在的话进入这个term的倒排链,并根据参数设定返回分页返回结果即可。这类查询,在数据库中使用二级索引也是可以满足,那lucene的优势在哪呢。假如我们有多个条件,例如我们需要按名字或者年龄单独查询,也需要进行组合 name = “Alice” and age = "18"的查询,那么使用传统二级索引方案,你可能需要建立两张索引表,然后分别查询结果后进行合并,这样如果age = 18的结果过多的话,查询合并会很耗时。那么在lucene这两个倒排链是怎么合并呢。
假如我们有下面三个倒排链需要进行合并。
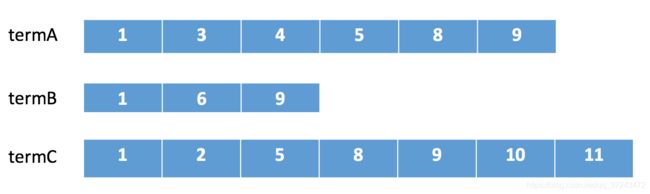
在lucene中会采用下列顺序进行合并:
在termA开始遍历,得到第一个元素docId=1
Set currentDocId=1
在termB中 search(currentDocId) = 1 (返回大于等于currentDocId的一个doc),
因为currentDocId ==1,继续
如果currentDocId 和返回的不相等,执行2,然后继续
到termC后依然符合,返回结果
currentDocId = termC的nextItem
然后继续步骤3 依次循环。直到某个倒排链到末尾。
整个合并步骤我可以发现,如果某个链很短,会大幅减少比对次数,并且由于SkipList结构的存在,在某个倒排中定位某个docid的速度会比较快不需要一个个遍历。可以很快的返回最终的结果。从倒排的定位,查询,合并整个流程组成了lucene的查询过程,和传统数据库的索引相比,lucene合并过程中的优化减少了读取数据的IO,倒排合并的灵活性也解决了传统索引较难支持多条件查询的问题。