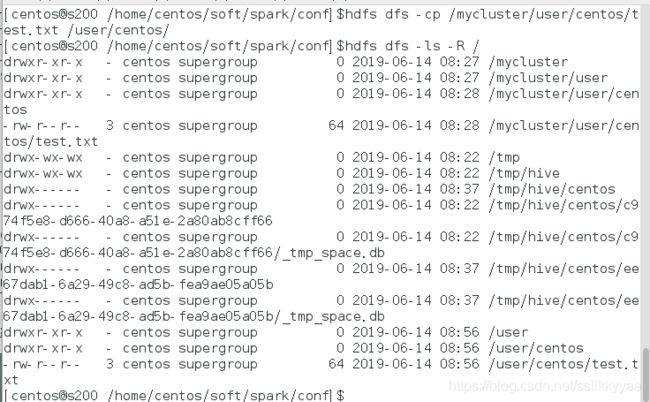
touch data.txt vi data.txt 1,tom,12 2,tomasd,13 3,tomasLee,14
show databases;
use mydb;
show tables;
spark.sql("drop table mydb.tt");
spark.sql("create table mydb.tt(id int,name string , age int)row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile"); 加载数据到hive
$scala>spark.sql("load data local inpath 'file:///home/centos/data.txt' into table mydb.tt"); val df= spark.sql("select * from mydb.tt"); df.show val df= spark.sql("select * from mydb.tt where age>"); df.show
Spark SQL
--------------
使用类似SQL方式访问hadoop,实现MR计算。RDD
df = sc.createDataFrame(rdd);
DataSet === DataFrame ==> //类似于table操作。
SparkSQL java
-----------------
public class SQLJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local") ;
conf.setAppName("SQLJava");
SparkSession session = SparkSession.builder()
.appName("SQLJava")
//设置master方式.
.config("spark.master","local")
.getOrCreate();
Dataset df = session.read().json("file:///d:/scala/json.dat");
df.show();
}
}
将DataFrame转换成RDD的操作
--------------------------
JavaRDD rdd = df1.toJavaRDD();
保存spark的sql计算结果(json)
----------------------------
//保存成json文件。
df.write().json(dir) ;
//设置保存模式
df.mode(SaveMode.APPEND) ;
json文件的读写
---------------
//读取json文件形成df对象
SparkSession.read().json("..");
//将数据框数据写入json文件
SparkSession.write().json("..");
SparkDataFrame以jdbc方式操纵的表
-----------------------------------
1.引入mysql驱动
pom.xml
2.
3.
4.
Spark整合hive
----------------------------------
1.hive的类库需要在spark worker节点。
2.复制core-site.xml(hdfs) + hdfs-site.xml(hdfs) + hive-site.xml(hive)三个文件
到spark/conf下。
3.复制mysql驱动程序到/soft/spark/jars下
...
3.1 hive启动
$$HIVE_HOME/bin/hive
show databases;
use mydb2;
4.启动spark-shell,指定启动模式
spark-shell --master local[4]
$scala>create table tt(id int,name string , age int) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile
//加载数据到hive表
hive> create database mydb
spark.sql("create table mydb.tt(id int,name string , age int)row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile");
spark.sql("drop table mydb.tt");
$scala>spark.sql("load data local inpath 'file:///home/centos/data.txt' into table mydb.tt");
val df= spark.sql("select * from mydb.tt");
df.show
val df= spark.sql("select * from mydb.tt where age>");
df.show
编写java版的SparkSQL操纵hive表
----------------------------------
1.复制配置文件到resources目录下
core-site.xml
hdfs-site.xml
hive-site.xml
2.pom.xml增加依赖
4.0.0com.it18zhangSparkDemo11.0-SNAPSHOTsrc/main/javaorg.apache.maven.pluginsmaven-compiler-plugin1.81.8net.alchim31.mavenscala-maven-plugin3.2.2incrementalcompiletestCompileorg.apache.sparkspark-core_2.112.1.0org.apache.sparkspark-mllib_2.112.1.0mysqlmysql-connector-java5.1.17org.apache.sparkspark-sql_2.112.1.0
3.编程
package com.it18zhang.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.Properties;
/**
* Created by Administrator on 2017/4/3.
*/
public class SQLHiveJava {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local") ;
conf.setAppName("SQLJava");
SparkSession sess = SparkSession.builder()
.appName("HiveSQLJava")
.config("spark.master","local")
.getOrCreate();
sess.sql("use mydb.db");
Dataset df = sess.sql("select * from tt");
df.show();
}
}
分布式SQL引擎
--------------------
1.启动spark集群(完全分布式-standalone)
$>/soft/spark/sbin/start-all.sh
master //201
worker //202 ~ 204
2.创建hive的数据表在默认库下。
$>hive -e "create table tt(id int,name string , age int) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile"
3.加载数据到hive表中.
$>hive -e "load data local inpath 'file:///home/centos/data.txt' into table tt"
$>hive -e "select * from tt"
4.分发三个文件到所有worker节点
5.启动spark集群
$>soft/spark/sbin/start-all.sh
6.启动spark-shell
$>spark-shell --master spark://s201:7077
7.启动thriftserver服务器
$>start
Spark Streaming
-------------------
1.介绍
是spark core的扩展,针对实时数据流处理,具有可扩展、高吞吐量、容错.
数据可以是来自于kafka,flume,tcpsocket,使用高级函数(map reduce filter ,join , windows),
处理的数据可以推送到database,hdfs,针对数据流处理可以应用到机器学习和图计算中。
内部,spark接受实时数据流,分成batch(分批次)进行处理,最终在每个batch终产生结果stream.
2.discretized stream or DStream,
离散流,表示的是连续的数据流。
通过kafka、flume等输入数据流产生,也可以通过对其他DStream进行高阶变换产生。
在内部,DStream是表现为RDD序列。
体验Spark Streaming
----------------------
1.pom.xml
org.apache.sparkspark-streaming_2.112.1.0
2.编写SparkStreamingdemo.scala
/**
* Created by Administrator on 2017/4/3.
*/
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object SparkStreamingDemo {
def main(args: Array[String]): Unit = {
//local[n] n > 1
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
//创建Spark流上下文,批次时长是1s
val ssc = new StreamingContext(conf, Seconds(1))
//创建socket文本流
val lines = ssc.socketTextStream("localhost", 9999)
//压扁
val words = lines.flatMap(_.split(" "))
//变换成对偶
val pairs = words.map((_,1));
val count = pairs.reduceByKey(_+_) ;
count.print()
//启动
ssc.start()
//等待结束
ssc.awaitTermination()
}
}
3.启动nc服务器
[win7]
cmd>nc -lL -p 9999
4.启动spark Streaming程序
5.在nc的命令行输入单词.
hello world
...
6.观察spark计算结果。
...
导出stream程序的jar文件,丢到centos下运行。
-------------------------------------------
4.spark-submit --name wcstreaming
--class com.it18zhang.spark.java.JavaSparkStreamingWordCountApp
--master spark://s201:7077
SparkDemo1-1.0-SNAPSHOT.jar
DStream
-----------------
[注意事项]
1.启动上下文之后,不能启动新的流或者添加新的
2.上下文停止后不能restart.
3.同一JVM只有一个active的streamingcontext
4.停止streamingContext会一同stop掉SparkContext,如若只停止StreamingContext.
ssc.stop(false|true);
5.SparkContext可以创建多个StreamingContext,创建新的之前停掉旧的。
DStream和Receiver
------------------
1.介绍
Receiver是接受者,从source接受数据,存储在内存中共spark处理。
2.源
基本源:fileSystem | socket,内置APAI支持。
高级源:kafka | flume | ...,需要引入pom.xml依赖.
3.注意
使用local模式时,不能使用一个线程.使用的local[n],n需要大于receiver的个数。
Kafka + Spark Streaming
-------------------------
0.启动kafka集群
//启动zk
$>...
//启动kafka
...
1.引入pom.xml
...
org.apache.sparkspark-streaming-kafka-0-10_2.112.1.0
Option[T]
---------------
None //null
Some()
1.java.util.Timer.schedule(TimerTask task, long delay):多长时间(毫秒)后执行任务
2.java.util.Timer.schedule(TimerTask task, Date time):设定某个时间执行任务
3.java.util.Timer.schedule(TimerTask task, long delay,longperiod
java.lang.UnsupportedClassVersionError: cn/support/cache/CacheType : Unsupported major.minor version 51.0 (unable to load class cn.support.cache.CacheType)
at org.apache.catalina.loader.WebappClassL
昨天发了一个提问,启动5个线程将一个List中的内容,然后将5个线程的内容拼接起来,由于时间比较急迫,自己就写了一个Demo,希望对菜鸟有参考意义。。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public c
select list.listname, list.createtime,listcount from dream_list as list , (select listid,count(listid) as listcount from dream_list_user group by listid order by count(
此文转自IBM.
Apache 服务简介
Web 服务器也称为 WWW 服务器或 HTTP 服务器 (HTTP Server),它是 Internet 上最常见也是使用最频繁的服务器之一,Web 服务器能够为用户提供网页浏览、论坛访问等等服务。
由于用户在通过 Web 浏览器访问信息资源的过程中,无须再关心一些技术性的细节,而且界面非常友好,因而 Web 在 Internet 上一推出就得到
1) I love you not because of who you are, but because of who I am when I am with you. 我爱你,不是因为你是一个怎样的人,而是因为我喜欢与你在一起时的感觉。 2) No man or woman is worth your tears, and the one who is, won‘t