Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate学习笔记
1.论文要点
1.1 英文
Conversion rate (CVR) prediction is an essential task for ranking system in industrial applications, such as online advertising and recommendation etc. For example, predicted CVR is used in OCPC (optimized cost-per-click) advertising to adjust bid price per click to achieve a win-win of both platform and advertisers. It is also an important factor in recommender systems to balance users’ click preference and purchase preference.
In this paper, we focus on the task of post-click CVR estimation.
Given recommended items, users might click interested ones and further buy some of them. In other words, user actions follow a sequential pattern of impression → click → conversion. In this way, CVR modeling refers to the task of estimating the post-click conversion rate, i.e., pCVR = p(conversion|click,impression).
Among them, we report two critical ones encountered in our real practice: i) sample selection bias (SSB) problem. ii) data sparsity (DS) problem.
sample selection bias (SSB) problem:
As illustrated in Fig.1, conventional CVR models are trained on dataset composed of clicked impressions, while are utilized to make inference on the entire space with samples of all impressions.

Training space is composed of samples with clicked impressions. It is only part of the inference space which is composed of all impressions.
data sparsity (DS) problem:
Conventional methods train CVR model with clicked samples of Sc. The rare occurrence of click event causes training data for CVR modeling to be extremely sparse. Intuitively, it is generally 1-3 orders of magnitude less than the associated CTR task, which is trained on dataset of S with all impressions. Table 1 shows the statistics of our experimental datasets, where number of samples for CVR task is just 4% of that for CTR task. Note that in Sc, (clicked) impressions without conversion are treated as negative samples and impressions with conversion (also clicked) as positive samples.

Sparsity of training data makes CVR model fitting rather difficult.
In this paper, by making good use of sequential pattern of user actions, we propose a novel approach named Entire Space Multitask Model (ESMM), which is able to eliminate the SSB and DS problems simultaneously.

Post-click CVR modeling is to estimate the probability of pCVR = p(z = 1|y = 1, x). Two associated probabilities are: post-view click-through rate (CTR) with pCTR = p(z = 1|x) and post-view click & conversion rate (CTCVR) with pCTCVR = p(y = 1, z = 1|x).
pCTCVR(真实评价) = pCTR(点击率)×![]() pCVR(转化率)
pCVR(转化率)

CTCVR将CTR和CVR网络的输出乘积作为输出。
ESMM introduces two auxiliary tasks of CTR and CTCVR and eliminates the aforementioned problems for CVR modeling simultaneously.
![]()
Here p(y = 1, z = 1|x) and p(y = 1|x) are modeled on dataset of S with all impressions.
pCTR and pCTCVR are the main factors ESMM actually estimated over entire space.
It consists of two loss terms from CTR and CTCVR tasks which are calculated over samples of all impressions, without using the loss of CVR task.
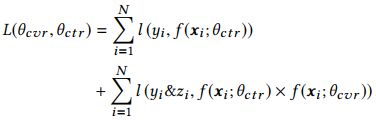
where θctr and θcvr are the parameters of CTR and CVR networks and l(·) is cross-entropy loss function.
Mathematically, Eq.(3) decomposes y → z into two parts: y and y&z, which in fact makes use of the sequential dependence of click and conversion labels.
By exploiting the sequential patten of user actions and learning from un-clicked data with transfer mechanism, ESMM provides an elegant solution for CVR modeling to eliminate SSB and DS problems simultaneously and beats all the competitors.
This method can be easily generalized to user action prediction in scenario with sequential dependence. In the future, we intend to design global optimization models in applications with multistage actions like request → impression → click → conversion.
1.2 翻译
转换率(CVR)预测对于在线广告和推荐等工业应用中的排名系统来说是一项必不可少的任务。例如,预测的CVR用于OCPC(优化的每次点击费用)广告,以将每次点击的出价调整为 实现平台和广告客户的双赢。 这也是推荐系统中平衡用户点击偏好和购买偏好的重要因素。
在本文中,我们专注于点击后CVR估算的任务。
给定推荐的商品,用户可以单击感兴趣的商品,然后再购买其中一些。 换句话说,用户操作遵循展现→点击→转换的顺序模式。 这样,CVR建模是指估算点击后转化率(即pCVR = p(转化|点击,展现))的任务。
其中,我们报告了在实际操作中遇到的两个关键问题:i)样本选择偏差(SSB)问题。 ii)数据稀疏(DS)问题。
样本选择偏差(SSB)问题:
训练样本从整体样本空间的一个较小子集中提取,而训练得到的模型却需要对整个样本空间中的样本做推断预测的现象称之为样本选择偏差。样本选择偏差会伤害学到的模型的泛化性能。
如下图所示,传统的CVR模型是在由点击的展现组成的数据集上训练的,同时利用所有展现的样本对整个空间进行推断。

训练空间由具有点击展现的样本组成。它只是由所有展现组成的推理空间的一部分。
数据稀疏(DS)问题:
常规方法使用点击的Sc样本训练CVR模型。很少发生点击事件,导致用于CVR建模的训练数据极为稀疏。直观地,它通常比关联的CTR任务小1-3个数量级,而CTR任务是在具有所有展示的S数据集上进行训练的。下表1显示了我们实验数据集的统计数据,其中CVR任务的样本数量仅为CTR任务的样本数量的4%。注意,在Sc中,未经转化的(点击)展现数被视为负样本,而经过转化(也被单击)的展现数被视为正样本。

训练数据的稀疏性使CVR模型的拟合变得相当困难。
在本文中,通过充分利用用户操作的顺序模式,我们提出了一种名为“整个空间多任务模型(ESMM)”的新颖方法,该方法能够同时消除SSB和DS问题。

单击后CVR建模是为了估计pCVR = p(z = 1 | y = 1,x)的概率。两个相关的概率是:pCTR = p(z = 1 | x)的浏览后点击率(CTR)和pCTCVR = p(y = 1,z = 1 | X)的浏览后点击率和转化率(CTCVR)。
pCTCVR(真实评价) = pCTR(点击率)×![]() pCVR(转化率)
pCVR(转化率)
CTCVR将CTR和CVR网络的输出乘积作为输出。
ESMM引入了CTR和CTCVR的两个辅助任务,同时消除了CVR建模的上述问题。
![]()
在这里,p(y = 1,z = 1 | x)和p(y = 1 | x)是在具有所有展示的S数据集上建模的。
pCTR和pCTCVR是ESMM在整个空间中实际估算的主要因素。
它由CTR和CTCVR任务的两个损失项组成,它们是根据所有展示的样本计算得出的,而没有使用CVR任务的损失。

其中θctr和θcvr是CTR和CVR网络的参数,l(·)是交叉熵损失函数。
上述等式(3)将y→z分解为两部分:y和y&z,实际上利用了点击和转化标签的顺序依赖性。
通过利用用户操作的顺序模式并使用传输机制从未单击的数据中学习,ESMM为CVR建模提供了一种优雅的解决方案,可同时消除SSB和DS问题并击败所有竞争对手。
该方法可以很容易地推广到具有顺序依赖性的场景中的用户动作预测。 将来,我们打算在应用程序中设计全局优化模型,这些应用程序具有多级操作,例如请求→展现→单击→转换。
2.论文总结
2.1 Motivation
不同于CTR预估问题,CVR预估面临两个关键问题:
Sample Selection Bias (SSB,样本选择偏差) 转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。即是说,训练数据与实际要预测的数据来自不同分布,这个偏差对模型的泛化能力构成了很大挑战。
Data Sparsity (DS,数据稀疏性) 作为CVR训练数据的点击样本远小于CTR预估训练使用的曝光样本。
一些策略可以缓解这两个问题,例如从曝光集中对unclicked样本抽样做欠采样缓解SSB,对转化样本过采样缓解DS等。但无论哪种方法,都没有很好地从实质上解决上面任一个问题。
可以看到:点击—>转化,本身是两个强相关的连续行为,作者希望在模型结构中显示考虑这种“行为链关系”,从而可以在整个空间上进行训练及预测。这涉及到CTR与CVR两个任务,因此使用多任务学习(MTL)是一个自然的选择,论文的关键亮点正在于“如何搭建”这个MTL。
2.2 Model
介绍ESMM之前,我们还是先来思考一个问题——“CVR预估到底要预估什么”,论文虽未明确提及,但理解这个问题才能真正理解CVR预估困境的本质。想象一个场景,一个item,由于某些原因,例如在feeds中的展示头图很丑,它被某个user点击的概率很低,但这个item内容本身完美符合这个user的偏好,若user点击进去,那么此item被user转化的概率极高。CVR预估模型,预估的正是这个转化概率,它与CTR没有绝对的关系,很多人有一个先入为主的认知,即若user对某item的点击概率很低,则user对这个item的转化概率也肯定低,这是不成立的。更准确的说,CVR预估模型的本质,不是预测“item被点击,然后被转化”的概率(CTCVR),而是“假设item被点击,那么它被转化”的概率(CVR)。这就是不能直接使用全部样本训练CVR模型的原因,因为咱们压根不知道这个信息:那些unclicked的item,假设他们被user点击了,它们是否会被转化。如果直接使用0作为它们的label,会很大程度上误导CVR模型的学习。CVR模型旨在预估用户在观察到曝光商品进而点击到商品详情页之后购买此商品的概率,即pCVR = p(conversion|click,impression)。
认识到点击(CTR)、转化(CVR)、点击然后转化(CTCVR)是三个不同的任务后,我们再来看三者的关联:

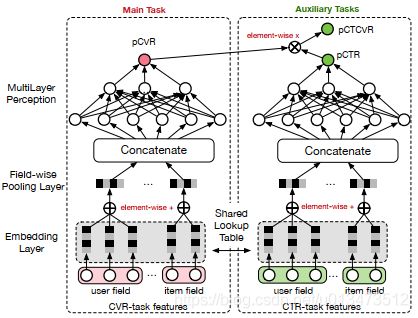
其中z , y 分别表示conversion和click。注意到,在全部样本空间中,CTR对应的label为click,而CTCVR对应的label为click & conversion,这两个任务是可以使用全部样本的。那为啥不绕个弯,通过这学习两个任务,再根据上式隐式地学习CVR任务呢?ESMM正是这么做的,具体结构如下:
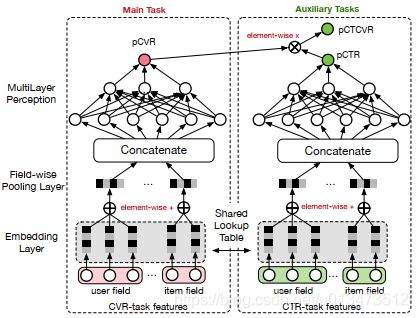
图1. ESMM网络结构
仔细观察上图,留意以下几点:1)共享Embedding CVR-task和CTR-task使用相同的特征和特征embedding,即两者从Concatenate之后才学习各自部分独享的参数;2)隐式学习pCVR 啥意思呢?这里pCVR(粉色节点)仅是网络中的一个variable,没有显示的监督信号。
具体地,反映在目标函数中:

即利用CTCVR和CTR的监督信息来训练网络,隐式地学习CVR,这正是ESMM的精华所在,至于这么做的必要性以及合理性,本节开头已经充分论述了。
再思考下,ESMM的结构是基于“乘”的关系设计——pCTCVR=pCVR*pCTR,是不是也可以通过“除”的关系得到pCVR,即 pCVR = pCTCVR / pCTR ?例如分别训练一个CTCVR和CTR模型,然后相除得到pCVR,其实也是可以的,但这有个明显的缺点:真实场景预测出来的pCTR、pCTCVR值都比较小,“除”的方式容易造成数值上的不稳定。作者在实验中对比了这种方法。
2.3 Experiment
数据集目前还没用同时包含点击、转化信息的公开数据集,作者从淘宝日志中抽取整理了一个数据集Product,并开源了从Product中随机抽样1%构造的数据集Public(约38G)。

表1. Public与Product数据集
实验设置
对比方法:BASE——图1左部所示的CVR结构,训练集为点击集;AMAN——从unclicked样本中随机抽样作为负例加入点击集合;OVERSAMPLING——对点击集中的正例(转化样本)过采样;UNBIAS——使用rejection sampling;DIVISION——分别训练CTR和CVCTR,相除得到pCVR;ESMM-NS——ESMM结构中CVR与CTR部分不share embedding。
上述方法都使用NN结构,relu激活函数,嵌入维度为18,MLP结构为360*200*80*2,adam优化器 with ![]() 。
。
按时间分割,1/2数据训练,其余测试。
衡量指标
在点击样本上,计算CVR任务的AUC;同时,单独训练一个和BASE一样结构的CTR模型,除了ESMM类模型,其他对比方法均以pCTR*pCVR计算pCTCVR,在全部样本上计算CTCVR任务的AUC。
实验结果
如表1所示,ESMM显示了最优的效果。这里有趣的一点可以提下,ESMM是使用全部样本训练的,而CVR任务只在点击样本上测试性能,因此这个指标对ESMM来说是在biased samples上计算的,但ESMM性能还是很牛啊,说明其有很好的泛化能力。
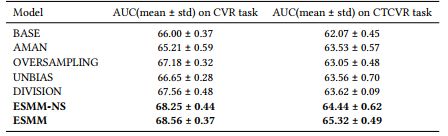
表2. 在Public上的实验结果,AUC以%为单位
在Product数据集上,各模型在不同抽样率上的AUC曲线如图2所示,ESMM显示的稳定的优越性,曲线走势也说明了Data Sparsity的影响还是挺大的。
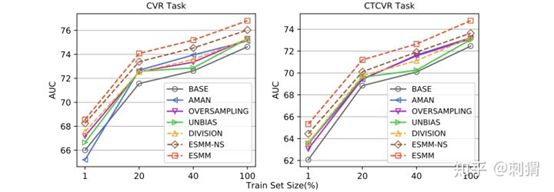
图2. 在Product上,各模型在不同抽样率上的AUC曲线
2.4 Discussion
- ESMM 根据用户行为序列,显示引入CTR和CTCVR作为辅助任务,“迂回” 学习CVR,从而在完整样本空间下进行模型的训练和预测,解决了CVR预估中的2个难题。
- 可以把 ESMM 看成一个新颖的MTL框架,其中子任务的网络结构是可替换的,当中有很大的想象空间。
这个框架的意义:ESMM模型的特别之处在于我们额外关注了任务的Label域信息,通过展现>点击>购买所构成的行为链,巧妙地构建了多目标概率连乘通路。传统MTL中多个task大都是隐式地共享信息、任务本身独立建模,ESMM细腻地捕捉了契合领域问题的任务间显式关系,从feature到label全面利用起来。这个角度对互联网行为建模是一个较有效的模式。
3.GitHub代码
ESMM模型是一个多任务学习(Multi-Task Learning)模型,它同时学习学习点击率和转化率两个目标,即模型直接预测展现转换率(pCTCVR):单位流量获得成交的概率。模型的结构如图1所示。
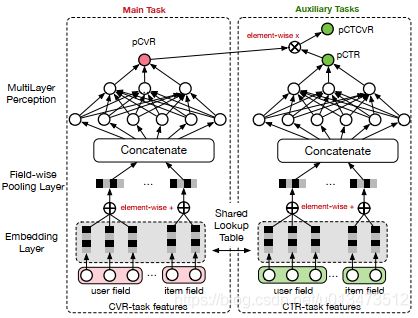
图1. ESMM模型
ESMM模型有两个主要的特点:
- 在整个样本空间建模。区别与传统的CVR预估方法通常使用“点击->成交”事情的日志来构建训练样本,ESMM模型使用“展现->点击->成交”事情的日志来构建训练样本。
- 共享特征表示。两个子任务(CTR预估和CVR预估)之间共享各类实体(产品、品牌、类目、商家等)ID的embedding向量表示。
ESMM模型的损失函数由两部分组成,对应于pCTR 和pCTCVR 两个子任务,其形式如下:
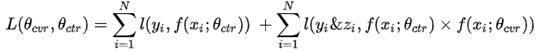
其中,θctr 和θcvr分别是CTR网络和CVR网络的参数,l(·)是交叉熵损失函数。在CTR任务中,有点击行为的展现事件构成的样本标记为正样本,没有点击行为发生的展现事件标记为负样本;在CTCVR任务中,同时有点击和购买行为的展现事件标记为正样本,否则标记为负样本。
ESMM模型由两个结构完全相同的子网络连接而成,我们把子网络对应的模型称之为Base模型。接下来,我们先介绍下如何用tensorflow实现Base模型。
Base模型的实现
在Base模型的网络输入包括user field和item field两部分。user field主要由用户的历史行为序列构成,具体地说,包含了用户浏览的产品ID列表,以及用户浏览的品牌ID列表、类目ID列表等;不同的实体ID列表构成不同的field。网络的embedding层,把这些实体ID都映射为固定长度的低维实数向量;接着之后的field-wise pooling层把同一个field的所有实体embedding向量求和得到对应于当前Field的一个唯一的向量;之后所有Field的向量拼接(concat)在一起构成一个大的隐层向量;接着大的隐层向量之上再接入若干全连接层,最后再连接到只有一个神经元的输出层。
Feature Column构建序列embedding和pooling
具体到tensorflow里,如何实现embedding layer以及field-wise pooling layer呢?
其实,用tensorflow的Feature Column API可以非常容易地实现。
实现embedding layer需要用到tf.feature_column.embedding_column或者tf.feature_column.shared_embedding_columns,这里因为我们希望user field和item field的同一类型的实体共享相同的embedding映射空间,所有选用tf.feature_column.shared_embedding_columns。由于shared_embedding_columns函数只接受categorical_column列表作为参数,因此需要为原始特征数据先创建categorical_columns。
来看下具体的例子,假设在原始特征数据中,behaviorPids表示用户历史浏览过的产品ID列表;productId表示当前的候选产品ID;则构建embedding layer的代码如下:
from tensorflow import feature_column as fc
# user field
pids = fc.categorical_column_with_hash_bucket("behaviorPids", 1000000, dtype=tf.int64)
# item field
pid = fc.categorical_column_with_hash_bucket("productId", 1000000, dtype=tf.int64)
pid_embed = fc.shared_embedding_columns([pids, pid], 100, combiner='sum', shared_embedding_collection_name="pid")需要说明的是,在构建训练样本时要特别注意,behaviorPids列表必须是固定长度的,否则在使用dataset的batch方法时会报tensor shape不一致的错。然而,现实中每个用户浏览过的产品个数肯定会不一样,这时可以截取用户的最近N个浏览行为,当某些用户的浏览商品数不足N个时填充默认值-1(如果ID是用字符串表示的时候,填充空字符串)。那么为什么填充的默认值必须是-1呢?这时因为categorical_column*函数用默认值-1表示样本数据中未登录的值,-1表示的categorical_column经过embedding_column之后被映射到零向量,而零向量在后面的求和pooling操作中不影响结果。
那么,如何实现field-wise pooling layer呢?其实,在用tf.feature_column.embedding_column 或者tf.feature_column.shared_embedding_columnsAPI 时不需要另外实现pooling layer,因为这2个函数同时实现了embedding向量映射和field-wise pooling。大家可能已经主要到了shared_embedding_columns函数的combiner='sum'参数,这个参数就指明了当该field有多个embedding向量时融合为唯一一个向量的操作,'sum'操作即element-wise add。
上面的代码示例,仅针对产品这一实体特征进行了embedding和pooling操作,当有多个不同的实体特征时,仅需要采用相同的方法即可。
实现weighted sum pooling操作
上面的操作实现了行为序列特征的embedding和pooling,但有一个问题就是序列中的每个行为被同等对待了;某些情况下,我们可能希望行为序列中不同的实体ID在做sum pooling时有不同的权重。比如说,我们可能希望行为时间越近的产品的权重越高,或者与候选产品有相同属性(类目、品牌、商家等)的产品有更高的权重。
那么如何实现weighted sum pooling操作呢?答案就是使用weighted_categorical_column函数。我们必须在构建样本时添加一个额外的权重特征,权重特征表示行为序列中每个产品的权重,因此权重特征是一个与行为序列平行的列表(向量),两者的维度必须相同。另外,如果行为序列中有填充的默认值-1,那么权重特征中这些默认值对应的权重必须为0。代码示例如下:
from tensorflow import feature_column as fc
# user field
pids = fc.categorical_column_with_hash_bucket("behaviorPids", 10240, dtype=tf.int64)
pids_weighted = fc.weighted_categorical_column(pids, "pidWeights")
# item field
pid = fc.categorical_column_with_hash_bucket("productId", 1000000, dtype=tf.int64)
pid_embed = fc.shared_embedding_columns([pids_weighted, pid], 100, combiner='sum', shared_embedding_collection_name="pid")
模型函数
Base模型的其他组件就不过多介绍了,模型函数的代码如下:
def my_model(features, labels, mode, params):
net = fc.input_layer(features, params['feature_columns'])
# Build the hidden layers, sized according to the 'hidden_units' param.
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
if 'dropout_rate' in params and params['dropout_rate'] > 0.0:
net = tf.layers.dropout(net, params['dropout_rate'], training=(mode == tf.estimator.ModeKeys.TRAIN))
my_head = tf.contrib.estimator.binary_classification_head(thresholds=[0.5])
# Compute logits (1 per class).
logits = tf.layers.dense(net, my_head.logits_dimension, activation=None, name="my_model_output_logits")
optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate'])
def _train_op_fn(loss):
return optimizer.minimize(loss, global_step=tf.train.get_global_step())
return my_head.create_estimator_spec(
features=features,
mode=mode,
labels=labels,
logits=logits,
train_op_fn=_train_op_fn
)ESMM模型的实现
有了Base模型之后,ESMM模型的实现就已经成功了一大半。剩下的工作就是把两个子模型连接在一块,同时定义好整个模型的损失函数和优化操作即可。
其中tensorflow estimator定义模型函数时,需要为不同mode(训练、评估、预测)下定义构建计算graph的所有操作,并返回想要的tf.estimator.EstimatorSpec。我们使用了Head API来简化了创建EstimatorSpec的过程,但在实现ESMM模型时没有现成的Head可用,必须手动创建EstimatorSpec。
在不同的mode下,模型函数必须返回包含不同图操作(op)的EstimatorSpec,具体地:
For mode == ModeKeys.TRAIN: required fields are loss and train_op.
For mode == ModeKeys.EVAL: required field is loss.
For mode == ModeKeys.PREDICT: required fields are predictions.另外,如果模型需要导出以便提供线上服务,这时必须在mode == ModeKeys.EVAL定义export_outputs操作,并添加到返回的EstimatorSpec中。
实现ESMM模型的关键点在于定义该模型独特的损失函数。上文也提到,ESMM模型的损失函数有2部分构成,一部分对应于CTR任务,另一部分对应于CTCVR任务。具体如何定义,请参考下面的代码:
def build_mode(features, mode, params):
net = fc.input_layer(features, params['feature_columns'])
# Build the hidden layers, sized according to the 'hidden_units' param.
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
if 'dropout_rate' in params and params['dropout_rate'] > 0.0:
net = tf.layers.dropout(net, params['dropout_rate'], training=(mode == tf.estimator.ModeKeys.TRAIN))
# Compute logits
logits = tf.layers.dense(net, 1, activation=None)
return logits
def my_model(features, labels, mode, params):
with tf.variable_scope('ctr_model'):
ctr_logits = build_mode(features, mode, params)
with tf.variable_scope('cvr_model'):
cvr_logits = build_mode(features, mode, params)
ctr_predictions = tf.sigmoid(ctr_logits, name="CTR")
cvr_predictions = tf.sigmoid(cvr_logits, name="CVR")
prop = tf.multiply(ctr_predictions, cvr_predictions, name="CTCVR")
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'probabilities': prop,
'ctr_probabilities': ctr_predictions,
'cvr_probabilities': cvr_predictions
}
export_outputs = {
'prediction': tf.estimator.export.PredictOutput(predictions)
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions, export_outputs=export_outputs)
y = labels['cvr']
cvr_loss = tf.reduce_sum(tf.keras.backend.binary_crossentropy(y, prop), name="cvr_loss")
ctr_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(labels=labels['ctr'], logits=ctr_logits), name="ctr_loss")
loss = tf.add(ctr_loss, cvr_loss, name="ctcvr_loss")
ctr_accuracy = tf.metrics.accuracy(labels=labels['ctr'], predictions=tf.to_float(tf.greater_equal(ctr_predictions, 0.5)))
cvr_accuracy = tf.metrics.accuracy(labels=y, predictions=tf.to_float(tf.greater_equal(prop, 0.5)))
ctr_auc = tf.metrics.auc(labels['ctr'], ctr_predictions)
cvr_auc = tf.metrics.auc(y, prop)
metrics = {'cvr_accuracy': cvr_accuracy, 'ctr_accuracy': ctr_accuracy, 'ctr_auc': ctr_auc, 'cvr_auc': cvr_auc}
tf.summary.scalar('ctr_accuracy', ctr_accuracy[1])
tf.summary.scalar('cvr_accuracy', cvr_accuracy[1])
tf.summary.scalar('ctr_auc', ctr_auc[1])
tf.summary.scalar('cvr_auc', cvr_auc[1])
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics)
# Create training op.
assert mode == tf.estimator.ModeKeys.TRAIN
optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate'])
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)