Pytorch使用tensorboard监视网络训练过程
Pytorch作为一大主流深度学习框架,在1.2版本之后自带tensorboard,这为监视训练过程带来了巨大的便利。但目前的教程多数没有写如何动态监视训练过程。在进行了一些探索后,实现了mnist分类训练动态监视这一功能,特此记录。文中分类demo来自https://blog.csdn.net/KyrieHe/article/details/80516737
- 安装或者升级pytorch环境,安装必要依赖包;
- 搭网络训练,但在代码中要插入如下代码,分为三个部分:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter() #定义writer,使用默认路径
# log_dir = 'dir_to_your_destination'
# writer = SummaryWriter(log_dir) #定义writer
writer.add_scalar('test/loss', test_loss, epoch+1) # add the information to the log file
writer.add_scalar('test/correct', correct, epoch+1)
writer.close()
程序一旦运行到writer.add_scalar后就会生成类似名字为Jan10_13-12-32_DESKTOP-G0RGKWD的文件夹,内有添加的数据
3. 从终端进入当前使用的虚拟环境和目录
4. 使用tensorboard --logdir=dir_to_your_destination --port=2200来启动tensorboard,该命令直行后会有一个连接http://localhost:2200/,将其复制粘贴到(pycharm的终端中可直接点击进入)浏览器中,即可打开
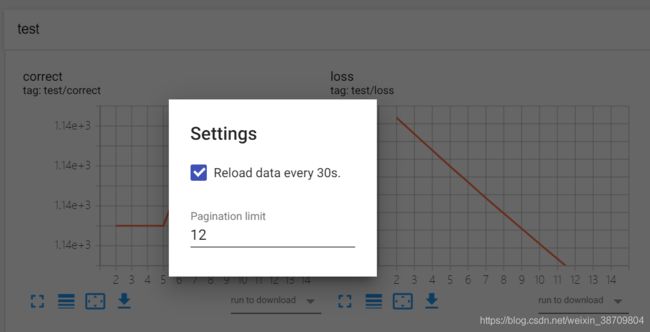
5. 选择要查看的数据进行查看,注意tensorboard是30秒更新一次数据,效果如下图

注意:
- 指定端口和完整日志路径比较容易出现效果,前期尝试中易出现无法打开或者打开后数据不对的情况,稍微多尝试几次
- 本例子只是以标量数据为例,可以添加多种类型的数据,可直接搜索查看tensorboard的官方说明
- 本例子的详细代码见https://github.com/AlvinLXS/Train_NN_with_Tensorboard
完整代码:
#!/usr/bin/env python
# encoding: utf-8
'''
@author: AlvinLXS
@time: 2020.1.10 12:50
@file: train_process.py
@desc: most part of the source codes comes from https://blog.csdn.net/KyrieHe/article/details/80516737
'''
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import argparse #Python 命令行解析工具
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter() #定义writer,使用默认路径
# log_dir = 'dir_to_your_destination'
# writer = SummaryWriter(log_dir) #定义writer
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader,epoch):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, size_average=False).item() # sum up batch loss
pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
writer.add_scalar('test/loss', test_loss, epoch+1) # add the information to the log file
writer.add_scalar('test/correct', correct, epoch+1)
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=30, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.000001, metavar='LR',
help='learning rate (default: 0.01)') # use a small learning rate to slow the train
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {
'num_workers': 1, 'pin_memory': True} if use_cuda else {
}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader,epoch)
if __name__ == '__main__':
main()
writer.close()