Elasticsearch写入原理深入详解
1、题记:
Elasticsearch写入流程,网上有视频、笔记等各种版本,本文结合最新官方文档进行重新梳理,节省大家的时间。
思考如下几个问题?
1、为什么Elasticsarch是近实时,而不是准实时?
2、为什么文档的CRUD操作是实时的?
3、为什么Elasticsearch能做到保证数据不丢失?
4、Refresh、flush的作用是什么? 什么时候使用?
5、Elasticsearch存储怎么让数据保存在磁盘上,而不是在内存上?
本文会给出以上问题的答案。
2、Elasticsearch写入核心概念
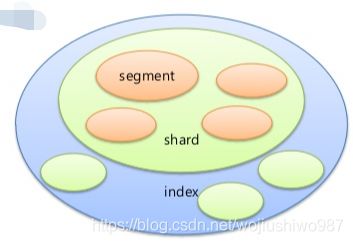
2.1 索引 index
Elasticsearch中的“索引”有点像关系数据库中的数据库。 它是存储/索引数据的地方。
2.2 分片 shard
“分片”是Lucene的一个索引。 它本身就是一个功能齐全的搜索引擎。
“索引”可以由单个分片组成,但通常由多个分片组成,一部分主分片、一部分副本分片。
ES默认5个主分片,1个副本分片;
副本分片的用途:(1)主节点故障时的故障转移;(2)增加的读取吞吐量。
2.3 分段 segment
每个分片包含多个“分段”,其中分段是倒排索引。
分段内的doc数量上限是2的31次方。
默认每秒都会生成一个segment文件.
在分片中搜索将依次搜索每个片段,然后将其结果合并到该分片的最终结果中。
查看索引中分段信息的方法:
GET /test/_segments
2.4 倒排索引
“倒排索引”是Lucene用于使数据可搜索的数据结构。
一图胜千言!如下:索引、分片、分段的关系一目了然。
2.5 translog日志文件:
为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。
translog还用于提供实时CRUD。 当您尝试按ID检索,更新或删除文档时,它会首先检查translog中是否有任何最近的更改,然后再尝试从相关段中检索文档。 这意味着它始终可以实时访问最新的已知文档版本。
2.6、倒排索引是不可变的
写入磁盘的倒排索引永远不会改变。
好处:无需锁定,不用担心多进程操作更改数据导致数据不一致问题。
坏处:经常被问到的问题,更新了词典词库后,老的索引不能生效。如果要使其可搜索,则必须重建整个索引。建议:reindex操作。
2.7 分段不可变
分段是不可变的。更新文档时,它实际上只是将旧文档标记为已删除,并为新文档编制索引。合并过程还会清除这些旧的已删除文档。
3、Elasticsearch写入步骤拆解
步骤1:新document首先写入内存Buffer缓存中。
步骤2:每隔一段时间,执行“commitpoint”操作,buffer写入新Segment中。
步骤3:新segment写入文件系统缓存 filesystem cache。
步骤4:文件系统缓存中的index segment被fsync强制刷到磁盘上,确保物理写入。
此时,新egment被打开供search操作。
步骤5:清空内存buffer,可以接收新的文档写入。
官方解读地址:http://t.cn/EyhPQt5
这是传统意义的写入步骤,实际ES为保证实时性,会做refresh操作。
#4、Elasticsearch refresh和flush
4.1、refresh操作
相比于Lucene的提交操作,ES的refresh是相对轻量级的操作。
先将index-buffer中文档(document)生成的segment写到文件系统之中,这样避免了比较损耗性能io操作,又可以使搜索可见。
默认1s钟刷新一次,所以说ES是近实时的搜索引擎,不是准实时。
注意:实际需要结合自己的业务场景设置refresh频率值。调大了会优化索引速度。注意单位:s代表秒级。
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}
4.2、flush操作
新创建的document数据会先进入到index buffer之后,与此同时会将操作记录在translog之中,当发生refresh时ranslog中的操作记录并不会被清除,而是当数据从filesystem cache中被写入磁盘之后才会将translog中清空。
从filesystem cache写入磁盘的过程就是flush。
步骤1:当translog变得太大时 ,可以执行commit ponit操作。
步骤2:使用fsync刷新文件系统缓存,写入磁盘。
步骤3:旧缓冲区被清除。
flush操作如下:
POST /_flush?wait_for_ongoing
5、图解Elasticsearch写入持久化模型
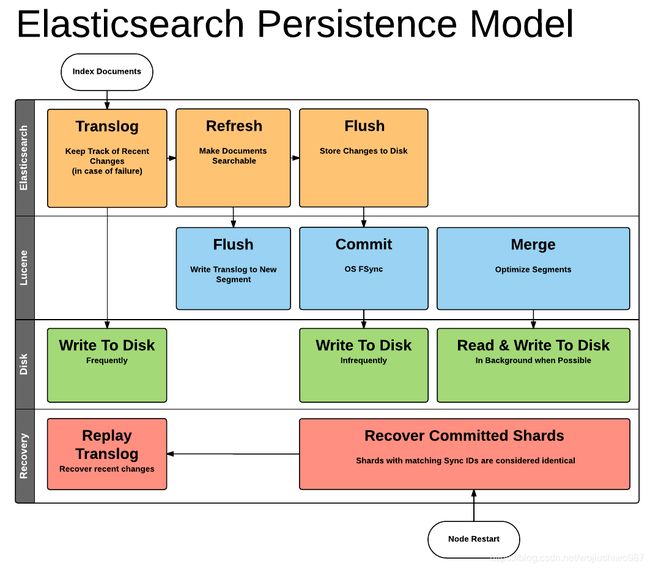
图的示意图要从上往下看。
1、当新的文档写入后,写入 index buffer的同时会写入translog。
2、refresh操作使得写入文档搜索可见;
3、flush操作使得filesystem cache写入磁盘,以达到持久化的目的。
6、小结
相信经过梳理,开篇几个问题的答案便非常清晰了。
知识的累积,需要过程,《高手》中尤其强调第一手文档的重要性。
第一手的官方文档+源码是根基,是最快、最准的方式。
参考:
[1] 官方文档:https://www.elastic.co/guide/en/elasticsearch/guide/master/translog.html
[2] 对比:https://stackoverflow.com/questions/19963406/refresh-vs-flush
[3] http://www.uml.org.cn/bigdata/201801263.asp
[4] https://stackoverflow.com/questions/15426441/understanding-segments-in-elasticsearch
[5] http://www.cnblogs.com/smile361/p/7483561.html
[6] https://blog.csdn.net/R_P_J/article/details/82254494
[7] 读写:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-replication.html

Elasticsearch基础、进阶、实战第一公众号