web scraper 入门到精通之路
【摘要】来一个插件帮忙翻看一下网页上的数据——webscraper,目的当然是为了学习新知识,希望在此与大家一起进步,一起成长。谢谢大家的过目!为了更加透彻清晰,将采用图文并茂的方式。(如有侵权,请及时联系我) 本文来自于x-team成员:清泓 。「最后更新时间2020年2月23日【持续更新】」
(本人郑重声明:抓取的所有资料著作权归被抓取方所属公司或集团,抓取数据只供学习使用,强烈谴责把数据商业化!!!请勿以身试法!)
本文主要参考文献:[1]
一.安装
安装采用的网站[2]下载,这个网站是一个插件库,实测可行。


下载下来之后,是一个crx文件,然后打开Chrome,重点是:只支持Chrome浏览器!
![]()
1.打开Chrome浏览器设置,找到拓展程序。
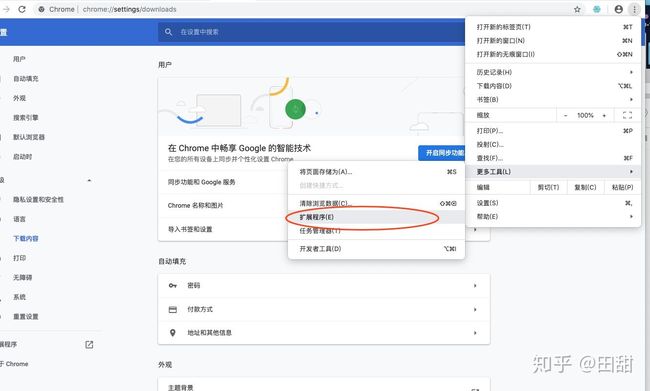
2.打开浏览器开发者模式。
![]()
3.将crx的后缀名改为zip格式并解压。
4.点击拓展程序里面的按钮「加载已解压的拓展程序」。
![]()
5.成功部署webscraper。

基本安装步骤就说到这里了,下面让我们来小试一下牛刀。
二.初步使用,抓取csdn官方博客的所有条目数据。
1.抓取博客第一页的所有标题。
(1)打开网页,打开调试板,找到webscraper,点击进去。

值得注意的是这个调试板必须要弄成下列模式布局,在浏览器下方的布局。

(2)添加请求头,这个就是我们的网页地址https://blog.csdn.net/blogdevteam/。


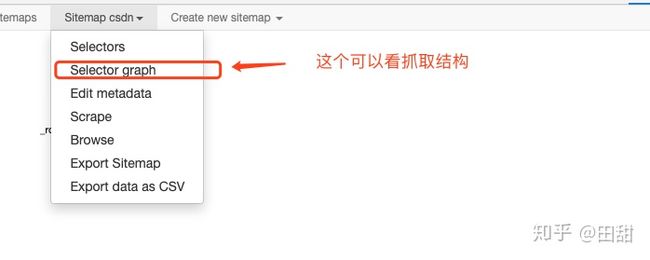
(3)理解工具含义。
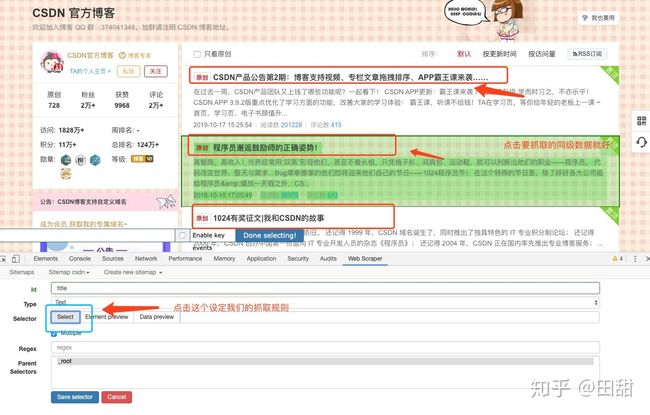
创建选择器时需使用 Element preview 和 Data preview 功能以确保你选中了正确的网页元素及数据。
1)selector - CSS 选择器选取所需元素;[3]
2)multiple - 如果要选择多个记录需勾选此项。从两个或多个选中 multiple 的选择器中提取的数据不会合并到一个单独记录中;
3)delay - 选择器生效前的延迟时长;
4)parent selectors - 为此选择器选择母选择器以产生选择器树形结构;
5)文本选择器(Text selector);
6)链接选择器(Link selector);
7)元素选择器(Element selector)。

(4). Date extraction 选择器。
Date extraction 选择器仅从选中的元素中返回数据。譬如 Text (文本)选择器从选中的元素中提取文本。以下选择器可用作 Date extraction 选择器:

1)Text(文本)选择器;
2)Link(链接)选择器;
3)Link popup(弹出链接)选择器;
4)Image(图像)选择器;
5)Table(表格)选择器;
6)Element attribute(元素属性)选择器;
7)HTML 选择器;
8)Grouped(组块)选择器。
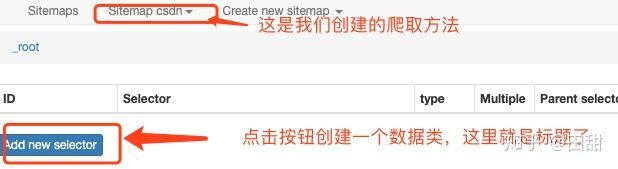
(5). 设定规则



(6).抓取运行和抓取结果。
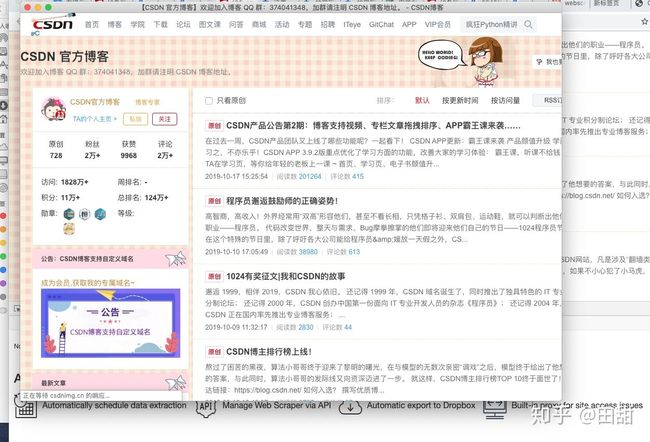

(7). 结果,这就是设定的单页抓取标题的数据。

三.抓取整个博客的标题,描述和日期,阅读数,评论数。
(1)关于多页抓取。
多页抓取分很多情况,需要看一下网站的规则,csdn的博客的分页规则如下:
![]()
当点击第二页博客的数据的时候,网址链接变成了https://blog.csdn.net/blogdevteam//article/list/2?
再看再这个博客内容有多少页。
![]()
可以看到总共37页。

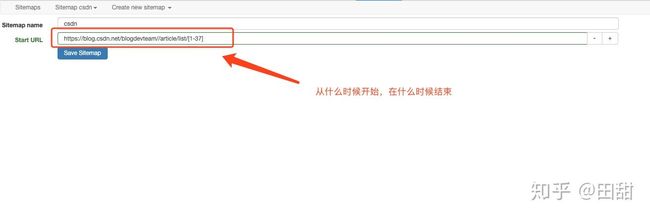
设置完之后保存一下设置,跑一下,测试一下结果是否正确。

可以看到最小页码是1,最大页码是37,抓取数据成功。现在来创建同级数据的多个数据集,道理同上,只是多了一个内容类型而已。现在的结构如下:

接下来多建几个同级的内容。

让我们来试一下效果,action。



这个是有残缺的,每行至多一个数据内容,其余的全没了,是随机的丢失。为什么会出现这种情况呢??????太奇怪了。检查一下:
1.首先结构是没有问题的。

2.单条数据没问题。

3.逐条检查规则没任何问题。

原因定位在multiple!
这个只能配置一个作为起始点。感觉和只能有一个主键key差不多了。

疑似原因的解除如下,设定之后,成功加载出数据,然后导出为Excel文档。


导出Excel文档如下:

注意:一个常见错误是同时创建两个选择器设定选项均选中 multiple,期望结果自然合并。例如,如果同时选择分页链接和导航链接,这些链接无法自然合并。正确的方法是使用元素选择器选用 Element 元素,并将 Data 选择器作为子选择器添加到 Element 选择器中,而不是选中 multiple 选项。
这个要特别注意,当时爬取网站的时候,是把multiple当成了一个类型选择器在使用,正确用法应该在默认_root的目录下新建一个类型选择器进行合并操作,相当于把一撮毛用橡皮筋卷起来,这个element就相当于那个橡皮筋。
2020年2月23日补充说明:(在此感谢热心知友提出的问题,以下提供的图片,也是热心网友提供的)
如下图所示,multiple1图是利用multiple对所选数据进行抓取的,但是,这个会出现一个问题,就是多个元素的批量抓取的时候,容易出现multiple2图出现的情况,单条数据的元素不能完全被抓下来,造成了单条数据的元素缺失,比如说,我抓取的电影,有三个元素,一个是电影标题,第二个元素是电影简介,第三个元素是电影评分,而结果是我们只抓取到了电影简介,或者只抓取到了电影标题。

multiple1(只设置了multiple)

multiple2
解决方案,在_root目录下加一个element类型的元素束,把这些元素捆起来。如下图element3所示:

element3
2020年3月21日补充说明:
添加element的方法:
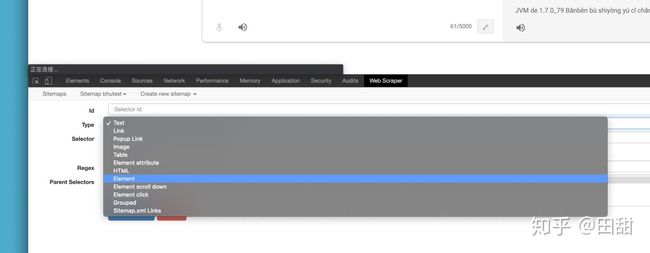
选择element类型的选择器
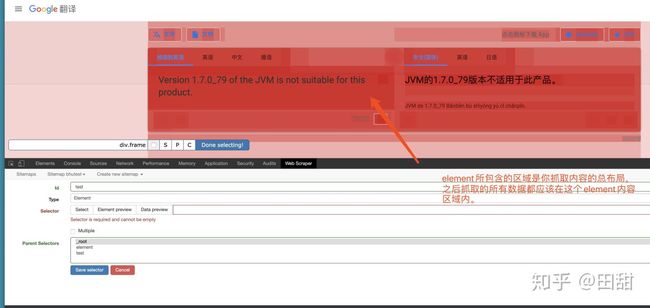
element内容区域其实就是一个母容器

element创建成功
四.关于多级数据的抓取。
二级页面抓取,可以设定一个子数据源的selector。
现在开始,我们来爬 一个处女座程序猿 的博客,做个简单一点的,多级页面的的每页的单个数据源和多级页面的全部正文,这里主要偏向的有两个方面,其一是多级页面的数据抓取,其一是子数据源的桥接点的建立。
1.我们首先来新建一个请求头,然后暂且不抓太多数据,就抓取处女座程序猿的1-5页的博客数据。请求头如下,点击保存。

2.创建父类选择器。

父类选择器创建成功,我们可以在这个父类选择器里面创建新的子类选择器了。

点击父类选择器我们可以再新建一个子类选择器,我们这里先把流程简单化,每个分级都只带一个属性,这个本身是一个桥接点,类型为link,是一个链接,意思就是以标题为链接源,(相当于我们手动点击知乎某个推送标题可以进入具体文章浏览内容)这个当然是分在我们刚才创建的root目录下面的。

3.开始抓取二级页面内容。
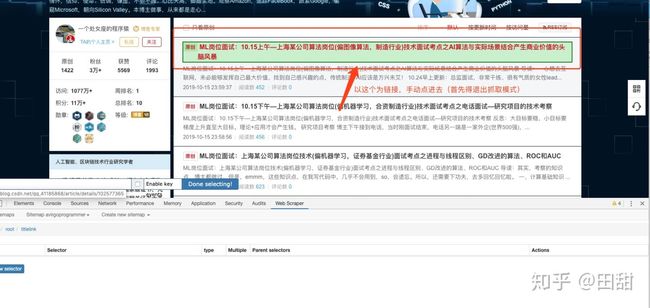
打开子页面之后,我们直接在刚才建立的子选择器里面添加文本类型的选择器就行了,内容选中为整个文章的内容。

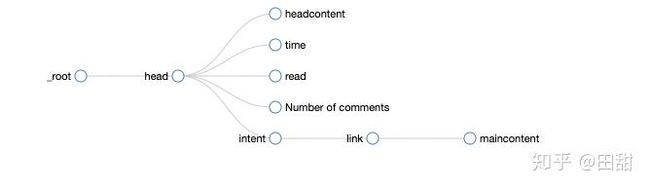
4.整个页面结构图。

五. 多级页面的热身运动到此为止,接下来,是多级页面的多数据抓取,首先思路是:
1.创建一个公共的父类选择器。
2.创建多个分支选择器。
3.在分支选择器的下面创建多个子类分支内容,可以子生子,孙子生孙子。
这个是抓取的数据字段:
{"_id":"zhihu","startUrl":["https://www.zhihu.com/question/352108632"],
"selectors":[{"id":"anwer","type":"SelectorElementScroll","parentSelectors":
["_root"],"selector":"div.List-item:nth-of-type(1)","multiple":true,"delay":0},
{"id":"name","type":"SelectorText","parentSelectors":["anwer"],
"selector":"#Popover13-toggle a","multiple":false,"regex":"","delay":0},
{"id":"Agree with the number","type":"SelectorText","parentSelectors":["anwer"],
"selector":".Voters button","multiple":false,"regex":"","delay":0},
{"id":"content","type":"SelectorText","parentSelectors":["anwer"],
"selector":"span[itemprop='text']","multiple":false,"regex":"","delay":0},
{"id":"Editing time","type":"SelectorText","parentSelectors":
["anwer"],"selector":"a span","multiple":false,"regex":"","delay":0},
{"id":"comment","type":"SelectorText","parentSelectors":["anwer"],
"selector":"button.ContentItem-action:nth-of-type(1)",
"multiple":false,"regex":"","delay":0}]}
六. 关于滚动网页的多数据抓取
以知乎回答为例子:




注意点:选择内容属性的时候,特别是标签属性的时候,一定要选对,选不对会出现数据抓取失败的情况。
2019年11月11日~12日 关于抓取二级页面的固定点击事件中的内容
最近爬取网站的时候,发现二级页面的数据中有一个展开数据的情况,如果不点击的时候会导致收起的页面抓取不到。
抓取海单词[4]数据的实际问题:里面的近反义词有时候是展开的有时候是收起的,webscraper无法自动识别导致所有数据都是空值。在webscraper中写上适合自己的网站实际情况的爬虫。
查看官方文档,我看到了一个好东西,仔细看了一下Element click的功能,嗯,可以,好像这个以前我认为只能获取分页数据的点击跳转页面的东西,好像还有一个作用,可以在当前页面点击按钮然后爬取点击事件结束之后的内容。仔细研究了一下。
4.11 Element click(元素点击)选择器
Element click 选择器使用方式类似 Element 选择器。主要目的也是元素选择,作为子选择器的母选择器。唯一差别在于, Element click 选择器可通过点击按钮同网站交互,以加载新元素。比如采用 JavaScript 以及 AJAX 技术进行导航或页面加载的网页。
4.11.1 配置选项
1)selector - CSS 选择器,用于选择元素,作为子选择器的母选择器。
2)click selector - CSS 选择器,用于点击按钮加载更多元素。
3)click type - 选择器类型,用于指示选择如何得知无新元素并停止点击。
4)click element uniqueness(点击元素独特性)- 选择器如何的是按钮已点击过。
5)multiple - 选中多项记录(默认应选中)。子选择器的 multiple 通常不选。
6)delay- 配置在点击及元素搜索之间的间隔。此项需指定,因为按钮点击后数据未必能立刻加载。因为服务器响应没那么及时,要想不丢失数据,最好设为 2000ms 以上。
7)Discard initial elements(忽略初始元素)- 选择器不会选中在第一次点击按钮前就已经存在的元素。这在去重时很有用。
4.11.2 Click type 点击类型
重点:
1)Click Once 点击一次
Click Once 只会点击按钮一次。如果符合条件的新按钮出现亦会点击。比如导航链接可能只会显示1~5,6~10随后才会显示。此选择器也会对它们(6~10)进行点击。
2)Click More 点击更多
Click More 会点击已有按钮直至无新元素出现。新元素按照有独有文本内容进行认定。
4.11.3 Click element uniqueness 点击元素独特性
当使用 Click Once 同一按钮只会被点击一次。当使用 Click More 会一直点击直到不产生新元素。
1)Unique Text - 有同样文本内容的按钮被视为同一按钮
2)Unique HTML+Text - 有同样 HTML 和文本内容的按钮被视为同一按钮
3)Unique HTML - 有同样 HTML 的按钮被视为同一按钮
4)Unique CSS Selector - 有同样 CSS 选择器的按钮被视为同一按钮
案例:

具体来说:
1.Click type
点击类型,click more 表示点击多次,因为我们要抓取批量数据,这里就选择 click more,还有一个 click once 选项,点击一次
2.Click element uniqueness
这个选项是控制 Web Scraper 什么时候停止抓取数据的。比如说 Unique Text,表示文字改变时停止抓取数据。
我们都知道,一个网站的数据不可能是无穷无尽的,总有加载完的时候,这时候「加载更多」按钮文字可能就变成「没有更多」、「没有更多数据」、「加载完了」等文字,当文字变动时,Web scraper 就会知道没有更多数据了,会自动停止抓取数据。
3.Multiple
这个我们的老朋友了,表示是否多选,这里我们要抓取多条数据,当然要打勾。
4.Discard initial elements
是否丢弃初始元素,这个主要是去除一些网站的重复数据用的,不是很重要,我们这里也用不到,直接选择 Never discard,从不丢弃数据。
5.Delay
延迟时间,因为点击加载更多后,数据加载需要一段时间,delay 就是等待数据加载的时间。一般我们设置要大于等于 2000,因为延迟 2s 是一个比较合理的数据,如果网络不好,我们可以设置更大的数字。
这次海词词典上的应用可以说正好可以应用到这个东西。
这个问题是解决了,说一下实际操作:
首先是我们有自己的服务器的情况下,
我们自己建立一个h5页面,写上链接,本次利用了webscraper抓取二级页面的特性,在第一个页面,人工写入网页链接。然后海词词典的数据。(本人郑重声明:海词词典的所有资料著作权归属海词词典所属公司,抓取数据只供学习使用,强烈谴责把数据商业化!!!请勿以身试法!)
h5编写页面如下图:

在浏览器中打开编写的实际网页显示如下图:

在这里我们利用webscraper抓取二级页面的属性,抓取海词资源。我们可以看到以下这种情况:

这图中还有点击事件的,点击进去还有查看更多。。。
于是应证了我之前所出现的那一点问题。
解决办法把图中第一节的json文件变动一下:
{"_id":"test_python_bigboom","startUrl":
["http://shupai.downline.cn/local_test_db_009/001_center_data_shupai/000_test_python_webscraper_data_explesion.html"],
"selectors":[{"id":"root","type":"SelectorElement","parentSelectors":["_root"],
"selector":"a","multiple":true,"delay":0},{"id":"titlelink","type":"SelectorLink",
"parentSelectors":["root"],"selector":"_parent_","multiple":true,"delay":0},
{"id":"word_name","type":"SelectorText","parentSelectors":["titlelink"]
,"selector":"h1.keyword","multiple":false,"regex":"","delay":0},
{"id":"haici_n","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(1)","multiple":false,"regex":"","delay":0},
{"id":"haici_adj","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(2)","multiple":false,"regex":"","delay":0},
{"id":"haici_pron","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(3)","multiple":false,"regex":"","delay":0},
{"id":"Detailed interpretation","type":"SelectorText","parentSelectors":
["titlelink"],"selector":"div.detail","multiple":false,"regex":"","delay":0},
{"id":"Near antonym","type":"SelectorText","parentSelectors":["titlelink"],
"selector":"div.nfo","multiple":false,"regex":"","delay":0},
{"id":"Proximity word","type":"SelectorElementClick","parentSelectors":
["titlelink"],"selector":".rel h3.cur","multiple":false,"delay":0,
"clickElementSelector":".rel h3.cur","clickType":"clickOnce",
"discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"}]}变动为:
{"_id":"test_python_bigboom","startUrl":
["http://shupai.downline.cn/local_test_db_009/001_center_data_shupai/000_test_python_webscraper_data_explesion.html"],
"selectors":[{"id":"root","type":"SelectorElement","parentSelectors":
["_root"],"selector":"a","multiple":true,"delay":0},{"id":"titlelink","type":
"SelectorLink","parentSelectors":["root"],"selector":"_parent_",
"multiple":true,"delay":0},{"id":"word_name","type":"SelectorText",
"parentSelectors":["titlelink"],"selector":"h1.keyword",
"multiple":false,"regex":"","delay":0},
{"id":"haici_n","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(1)","multiple":false,"regex":"","delay":0},
{"id":"haici_adj","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(2)","multiple":false,"regex":"","delay":0},
{"id":"haici_pron","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(3)","multiple":false,"regex":"","delay":0},
{"id":"Detailed interpretation","type":"SelectorText","parentSelectors":
["titlelink"],"selector":"div.detail","multiple":false,"regex":"","delay":0},
{"id":"Near antonym","type":"SelectorText","parentSelectors":["titlelink"],
"selector":"div.nfo","multiple":false,"regex":"","delay":0},
{"id":"Proximity word","type":"SelectorElementClick","parentSelectors":
["titlelink"],"selector":"div.nwd","multiple":true,"delay":"2000",
"clickElementSelector":".rel h3.cur","clickType":"clickMore",
"discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"},{"id":"liju","type":"SelectorText","parentSelectors":
["titlelink"],"selector":"div.sort","multiple":false,"regex":"","delay":0},
{"id":"linjinyici","type":"SelectorText","parentSelectors":["Proximity word"],
"selector":"_parent_","multiple":false,"regex":"","delay":0}]}
{"_id":"test_python_bigboom","startUrl":
["http://shupai.downline.cn/local_test_db_009/001_center_data_shupai/000_test_python_webscraper_data_explesion.html"],
"selectors":[{"id":"root","type":"SelectorElement","parentSelectors":
["_root"],"selector":"a","multiple":true,"delay":0},
{"id":"titlelink","type":"SelectorLink","parentSelectors":
["root"],"selector":"_parent_","multiple":true,"delay":0},
{"id":"word_name","type":"SelectorText","parentSelectors":["titlelink"],
"selector":"h1.keyword","multiple":false,"regex":"","delay":0},{"id":"haici_n",
"type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(1)","multiple":false,"regex":"","delay":0},
{"id":"haici_adj","type":"SelectorText","parentSelectors":["titlelink"],
"selector":".basic li:nth-of-type(2)","multiple":false,"regex":"","delay":0},
{"id":"haici_pron","type":"SelectorText","parentSelectors":
["titlelink"],"selector":".basic li:nth-of-type(3)","multiple":false,"regex":"",
"delay":0},{"id":"Detailed interpretation","type":"SelectorText","parentSelectors":
["titlelink"],"selector":"div.detail","multiple":false,"regex":"","delay":0},
{"id":"Near antonym","type":"SelectorText","parentSelectors":["titlelink"],
"selector":"div.nfo","multiple":false,"regex":"","delay":0},
{"id":"Proximity word","type":"SelectorElementClick","parentSelectors":
["titlelink"],"selector":"div.nwd","multiple":true,"delay":"2000",
"clickElementSelector":".rel h3.cur","clickType":"clickMore",
"discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},
{"id":"liju","type":"SelectorText","parentSelectors":["titlelink"],
"selector":"div.sort","multiple":false,"regex":"","delay":0},
{"id":"linjinyici","type":"SelectorText","parentSelectors":
["Proximity word"],"selector":"_parent_","multiple":false,"regex":"","delay":0}]}以下是结构图:
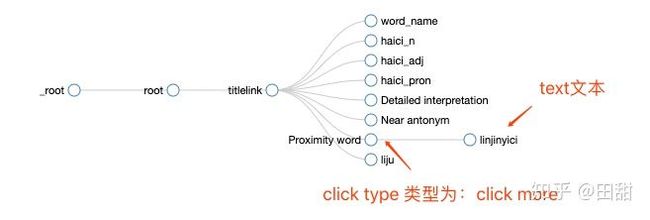
实际效果:到最后proximityword 为 elemtmore类型的click,所以不会在成果表单中显示,
proximity word 之后的 linjinyici为text类型,是真正展现在结果表单中的展示数据。
可以看下结果,以前是抓不到的。

上述仅仅为方法,真正应用实战中又出现了一部分问题,
所以进行了第二次修订:
树形图如下:

由于webscraper的树形图片区只有这么大(反正左右拉,上下拉都没有放大,将就一下,看不清直接导入json文件即可。)
以下为json文件:
{"_id":"python_haici","startUrl":
["http://shupai.downline.cn/001_center_data_shupai/000_test_python_webscraper_data_explesion.html"],
"selectors":[{"id":"base","type":"SelectorElement","parentSelectors":["_root"],
"selector":"a","multiple":true,"delay":0},{"id":"links","type":"SelectorLink",
"parentSelectors":["base"],"selector":"_parent_","multiple":true,"delay":0},
{"id":"word","type":"SelectorText","parentSelectors":["links"],
"selector":"h1.keyword","multiple":false,"regex":"","delay":0},
{"id":"Basic interpretation","type":"SelectorText","parentSelectors":["links"],
"selector":"div.word","multiple":false,"regex":"","delay":0},
{"id":"type_one","type":"SelectorText","parentSelectors":["links"],
"selector":".detail span:nth-of-type(1)","multiple":false,"regex":"","delay":0},
{"id":"Explain one","type":"SelectorText","parentSelectors":["links"],
"selector":".detail ol:nth-of-type(1)","multiple":false,"regex":"","delay":0},
{"id":"type_two","type":"SelectorText","parentSelectors":["links"],
"selector":".detail span:nth-of-type(2)","multiple":false,"regex":"","delay":0},
{"id":"Explain two","type":"SelectorText","parentSelectors":["links"],
"selector":".detail ol:nth-of-type(2)","multiple":false,"regex":"","delay":0},
{"id":"type_three","type":"SelectorText","parentSelectors":["links"],
"selector":".layout span:nth-of-type(3)","multiple":false,"regex":"","delay":0},
{"id":"Explain_three","type":"SelectorText","parentSelectors":
["links"],"selector":".detail ol:nth-of-type(3)","multiple":false,"regex":"",
"delay":0},{"id":"type_four","type":"SelectorText","parentSelectors":["links"],
"selector":"span:nth-of-type(4)","multiple":false,"regex":"","delay":0},
{"id":"Explain four","type":"SelectorText","parentSelectors":
["links"],"selector":"ol:nth-of-type(4)","multiple":false,"regex":"","delay":0},
{"id":"type_five","type":"SelectorText","parentSelectors":["links"],
"selector":"span:nth-of-type(5)","multiple":false,"regex":"","delay":0},
{"id":"Explain_five","type":"SelectorText","parentSelectors":
["links"],"selector":"ol:nth-of-type(5)","multiple":false,"regex":"","delay":0},
{"id":"type_six","type":"SelectorText","parentSelectors":
["links"],"selector":"span:nth-of-type(6)","multiple":false,"regex":"","delay":0},
{"id":"Explain_six","type":"SelectorText","parentSelectors":
["links"],"selector":"ol:nth-of-type(6)","multiple":false,"regex":"","delay":0},
{"id":"English plus English interpretation click",
"type":"SelectorElementClick","parentSelectors":["links"],
"selector":"div.en","multiple":false,"delay":"400",
"clickElementSelector":".def h3.cur","clickType":"clickMore",
"discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"},{"id":"English plus English interpretation++",
"type":"SelectorText","parentSelectors":
["English plus English interpretation click"],"selector":
"_parent_","multiple":false,"regex":"","delay":0},
{"id":"Double interpretation click","type":
"SelectorElementClick","parentSelectors":["links"],"selector":
"div.dual","multiple":false,"delay":"400","clickElementSelector":
".def h3.cur","clickType":"clickMore","discardInitialElements":"do-not-discard",
"clickElementUniquenessType":"uniqueText"},
{"id":"Double interpretation++","type":"SelectorText","parentSelectors":
["Double interpretation click"],"selector":"_parent_","multiple":false,"regex":"",
"delay":0},{"id":"Example","type":"SelectorText","parentSelectors":["links"],
"selector":"div.sort","multiple":false,"regex":"","delay":0},
{"id":"Common sentence pattern click",
"type":"SelectorElementClick","parentSelectors":["links"],"selector":
"div.patt","multiple":false,"delay":"400","clickElementSelector":
".sent h3.cur","clickType":"clickOnce","discardInitialElements":
"do-not-discard","clickElementUniquenessType":"uniqueText"},
{"id":"Common sentence pattern++","type":"SelectorText","parentSelectors":
["Common sentence pattern click"],"selector":
"_parent_","multiple":false,"regex":"","delay":0},
{"id":"Common Phrases click","type":
"SelectorElementClick","parentSelectors":["links"],
"selector":"div.phrase","multiple":false,"delay":"400","clickElementSelector":
".sent h3.cur","clickType":"clickOnce","discardInitialElements":"do-not-discard",
"clickElementUniquenessType":"uniqueText"},
{"id":"Common Phrases++","type":"SelectorText","parentSelectors":
["Common Phrases click"],"selector":"_parent_","multiple":false,"regex":"",
"delay":0},{"id":"Vocabulary matching click","type":
"SelectorElementClick","parentSelectors":["links"],"selector":"div.coll",
"multiple":false,"delay":0,"clickElementSelector":".sent h3.cur","clickType":
"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"},{"id":"Vocabulary matching++",
"type":"SelectorText","parentSelectors":["Vocabulary matching click"],
"selector":"_parent_","multiple":false,"regex":"","delay":0},
{"id":"Classic citation click","type":
"SelectorElementClick","parentSelectors":["links"],
"selector":"div.auth","multiple":false,"delay":"400","clickElementSelector":
".sent h3.cur","clickType":"clickOnce","discardInitialElements":"do-not-discard",
"clickElementUniquenessType":"uniqueText"},
{"id":"Classic citation++","type":"SelectorText","parentSelectors":
["Classic citation click"],"selector":"_parent_","multiple":false,"regex":
"","delay":0},{"id":"Word usage","type":"SelectorText","parentSelectors":
["links"],"selector":"div.ess","multiple":false,"regex":"","delay":0},
{"id":"Discrimination of word meaning click","type":
"SelectorElementClick","parentSelectors":
["links"],"selector":"div.discrim","multiple":false,"delay":"400",
"clickElementSelector":".learn h3.cur","clickType":
"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"},{"id":"Discrimination of word meaning++",
"type":"SelectorText","parentSelectors":["Discrimination of word meaning click"],
"selector":"_parent_","multiple":false,"regex":"","delay":0},
{"id":"Common mistakes click","type":"SelectorElementClick","parentSelectors":
["links"],"selector":"div.comn","multiple":false,"delay":"400",
"clickElementSelector":".learn h3.cur","clickType":"clickOnce",
"discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"},{"id":"Common mistakes++","type":"SelectorText","parentSelectors":
["Common mistakes click"],"selector":
"_parent_","multiple":false,"regex":"","delay":0},
{"id":"Etymological explanation click","type":
"SelectorElementClick","parentSelectors":["links"],"selector":"div.etm",
"multiple":false,"delay":"400","clickElementSelector":
".learn h3.cur","clickType":"clickOnce","discardInitialElements":
"do-not-discard","clickElementUniquenessType":"uniqueText"},
{"id":"Etymological explanation++","type":"SelectorText","parentSelectors":
["Etymological explanation click"],
"selector":"_parent_","multiple":false,"regex":"","delay":0},
{"id":"Near antonym","type":"SelectorText","parentSelectors":
["links"],"selector":"div.nfo","multiple":false,"regex":"","delay":0},
{"id":"Proximity word click","type":"SelectorElementClick","parentSelectors":
["links"],"selector":"div.nwd","multiple":false,
"delay":"400","clickElementSelector":".rel h3.cur","clickType":"clickOnce",
"discardInitialElements":"do-not-discard","clickElementUniquenessType":
"uniqueText"},{"id":"Proximity word++","type":"SelectorText","parentSelectors":
["Proximity word click"],"selector":"_parent_","multiple":false,"regex":
"","delay":0}]}
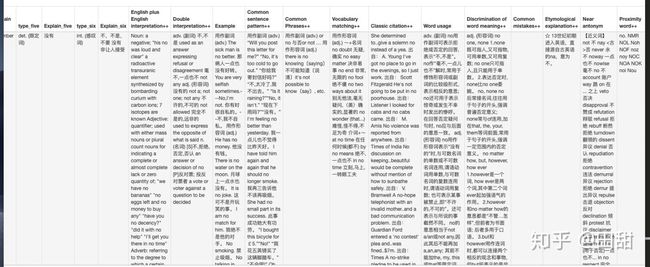
这边也没什么特点好说的,主要是一点,类型太多,动名词等类型有的单词有很多,而有的单词没有,有多种类型的单词解释,多类型的单词解释那一部分数据必不可缺,类型少的单词有的数据类型列是为空值的。
虽然说后期的列表排序和管理比较困难,但是必须这么去做,不然有一部分数据是抓取不到的。
实例:(no单词和one单词的用例标签栏有区别,或多或少)



这边用六个类型囊括详尽释义,对于详尽释义这一栏我重点抓取,
造成的是部分type类型为空,因为有的单词没有这么多类型,而有的单词达到六个类型之多。
但这一栏的分开写,分类型写,我认为是有必要的,因为便于以后学习。分清楚这些基本类型,动,名,代,数。。。词。

OK里面就有几个是空值,但是这个不可避免。
晒一下抓取之后的结果图:
好了,解释就到这里了,这个可能只有实际操作网页才能弄透彻,希望大家动手实操,一起学习,一起进步!
这个插件还有一些内容可以深挖,而且有很多隐藏性的问题,可能存在属性冲突之类的疑难问题,可能使用还不够熟悉,需要多加熟悉。
本文将持续更新,完善,对此文档有疑问或者对这方面有兴趣的同志可以留言联系我,与我一起学习,一起进步,come on!
2019年12月6日更新
大家好久不见哈。今天给大家实战一个项目。本次是抓取易读网[5]的小说。本人不具备版权,大家记得数据仅提供学习使用,私自挪用产生的一切后果,本人不承担任何连带责任。好了,不说了,展开正题。
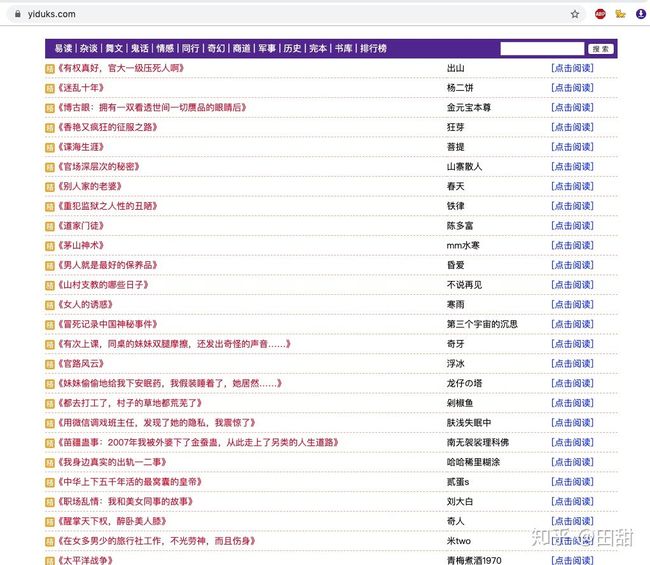
乍一看,结构分明,非常适合操作。 来来来,操作一把。
没有任何“杂质”(华丽布局,繁杂广告等)而且外表看似一个非常好抓的网站,谁料到它是分离型的结构。没有外框,这就意味着不能设置元素选择器。元素选择器需要设置一大片区域,Element...想了一下,直接把外部标题弄成束状集结点。具体结构如下图所示 。

json串如下:
{"_id":"yidu","startUrl":["https://yiduks.com/artlist_[1-5].html"],
"selectors":[{"id":"外部标题","type":"SelectorText","parentSelectors":["_root"],
"selector":".b_title a","multiple":true,"regex":"","delay":0},
{"id":"版权作者","type":"SelectorText","parentSelectors":["_root"],"selector":
".b_auth a","multiple":false,"regex":"","delay":0},
{"id":"小说类型","type":"SelectorText","parentSelectors":["_root"],
"selector":"div.b_artc","multiple":false,"regex":"","delay":0},
{"id":"是否连载","type":"SelectorText","parentSelectors":["_root"],
"selector":"div.b_staus","multiple":false,"regex":"","delay":0},
{"id":"点击阅读","type":"SelectorLink","parentSelectors":["_root"],
"selector":".b_read a","multiple":true,"delay":0},
{"id":"章节链接","type":"SelectorLink","parentSelectors":["点击阅读"],
"selector":"td[width] a","multiple":true,"delay":0},
{"id":"小说章节","type":"SelectorText","parentSelectors":
["章节链接"],"selector":"b","multiple":false,"regex":"","delay":0},
{"id":"小说作者","type":"SelectorText","parentSelectors":["章节链接"],"selector":
".MC a[title]","multiple":false,"regex":"","delay":0},
{"id":"小说正文","type":"SelectorText","parentSelectors":["章节链接"],
"selector":"div.ART","multiple":false,"regex":"","delay":0}]}后来发现了一个问题,就是,这个网站做了如下限制:(有的章节不能看,这个不是爬取数据被识别出来了,而是网站本身的问题)


解决方案:

ok,填入邀请码,不影响我们的接下来的操作,继续爬。
这个为结果,构成结构还需要调整一下。

2019年11月19日更新:
经过后续测试,发现是我之前错了,这个Element可以多个条目的情况下使用,当然,其他问题,我之前所担心的只能抓取单条数据的可能存在的问题,都不是问题。
所以,这次经历告诉我,实践是检验真理的唯一标准,不要以自己的猜想和臆测,或者根据之前的经验,而妄下定论。
这个修改起来是不能直接在那个地方修改的,只能在json字符串里面进行改动,只需要在前面的头部结构加一个束状元素把它们捆绑起来就OK。
修改json数据如下:
测试窗口:

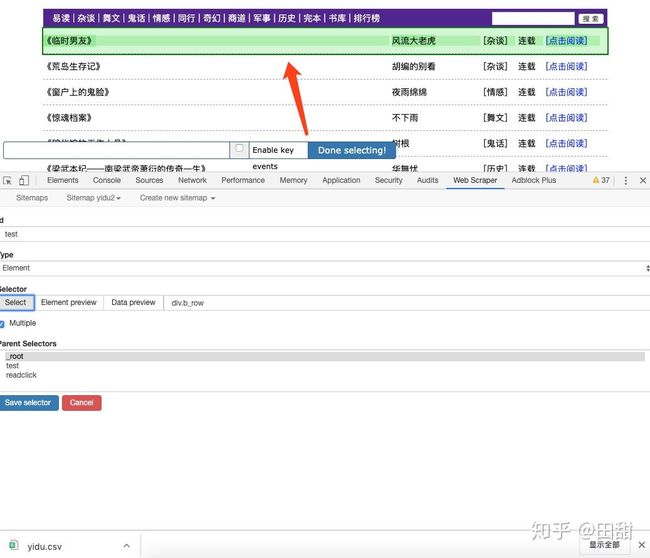
这里要详细解释一下之前出现的问题。
问题体现在设立元素选择器的时候,没有大框,不能一下选定所有需要爬取的数据,如果没有整合,如何能够抓取里面的内容。
因为束状选择器(这个算是无中生有的名字,这是我自己命名的,其实就是我之前文档中所说过的,一个橡皮筋的作用)里面包含了
所有的内容,下一级的内容都要从这个大盘子中获取。
这里是一条一条叠起来的element区域。详情见下图:

连续点击两条条目数据之后叠加,和子类数据条目获取一个概念。
我这里就不对抓取详细说明了,第一为了减少篇幅,我削减了很多之前已经在此栏目说明的抓取方法,如果对基本使用存在疑问可以往上面看一下之前的项目怎么抓取的。再次感谢大家追更的心。篇幅确实有点长。
以下我对本次抓取的结构放在下面。如果对本次抓取的结构还有疑问,请复制此json串慢慢研究。
测试json如下:
{"_id":"yidutwo","startUrl":
["https://yiduks.com/artlist_[1-2].html"],"selectors":
[{"id":"test","type":"SelectorElement","parentSelectors":["_root"],
"selector":"div.b_row","multiple":true,"delay":0},
{"id":"title","type":"SelectorText","parentSelectors":["test"],
"selector":".b_title a","multiple":false,"regex":"","delay":0},
{"id":"auther","type":"SelectorText","parentSelectors":["test"],
"selector":".b_auth a","multiple":false,"regex":"","delay":0},
{"id":"type","type":"SelectorText","parentSelectors":
["test"],"selector":"div.b_artc","multiple":false,"regex":"","delay":0},
{"id":"yesnonext","type":"SelectorText",
"parentSelectors":["test"],"selector":"div.b_staus",
"multiple":false,"regex":"","delay":0},
{"id":"readclick","type":"SelectorLink",
"parentSelectors":["test"],"selector":".b_read a",
"multiple":false,"delay":0}]}
根据这个json,改动正式结构的json结构如下:
{"_id":"yidu","startUrl":
["https://yiduks.com/artlist_[1-5].html"],
"selectors":[{"id":"yiduelement","type":"SelectorElement","parentSelectors":
["_root"],"selector":"div.b_row","multiple":true,"delay":0},
{"id":"外部标题","type":"SelectorText","parentSelectors":["test"],"selector":
".b_title a","multiple":false,"regex":"","delay":0},
{"id":"版权作者","type":"SelectorText","parentSelectors":["_root"],
"selector":".b_auth a","multiple":false,"regex":"","delay":0},
{"id":"小说类型","type":"SelectorText","parentSelectors":
["_root"],"selector":"div.b_artc","multiple":false,"regex":"","delay":0},
{"id":"是否连载","type":"SelectorText","parentSelectors":["_root"],
"selector":"div.b_staus","multiple":false,"regex":"","delay":0},
{"id":"点击阅读","type":"SelectorLink","parentSelectors":["_root"],
"selector":".b_read a","multiple":false,"delay":0},
{"id":"章节链接","type":"SelectorLink","parentSelectors":["点击阅读"],
"selector":"td[width] a","multiple":true,"delay":0},
{"id":"小说章节","type":"SelectorText","parentSelectors":
["章节链接"],"selector":"b","multiple":false,"regex":"","delay":0},
{"id":"小说作者","type":"SelectorText","parentSelectors":["章节链接"],
"selector":".MC a[title]","multiple":false,"regex":"","delay":0},
{"id":"小说正文","type":"SelectorText","parentSelectors":["章节链接"],
"selector":"div.ART","multiple":false,"regex":"","delay":0}]}
{"_id":"yidu","startUrl":
["https://yiduks.com/artlist_[1-5].html"],
"selectors":[{"id":"外部标题","type":"SelectorText","parentSelectors":["_root"],
"selector":".b_title a","multiple":false,"regex":"","delay":0},
{"id":"版权作者","type":"SelectorText","parentSelectors":["_root"],
"selector":".b_auth a","multiple":false,"regex":"","delay":0},
{"id":"小说类型","type":"SelectorText","parentSelectors":
["_root"],"selector":"div.b_artc","multiple":false,"regex":"","delay":0},
{"id":"是否连载","type":"SelectorText","parentSelectors":
["_root"],"selector":"div.b_staus","multiple":false,"regex":"","delay":0},
{"id":"点击阅读","type":"SelectorLink","parentSelectors":
["_root"],"selector":".b_read a","multiple":false,"delay":0},
{"id":"章节链接","type":"SelectorLink","parentSelectors":["点击阅读"],
"selector":"td[width] a","multiple":true,"delay":0},
{"id":"小说章节","type":"SelectorText","parentSelectors":["章节链接"],
"selector":"b","multiple":false,"regex":"","delay":0},
{"id":"小说作者","type":"SelectorText","parentSelectors":["章节链接"],
"selector":".MC a[title]","multiple":false,"regex":"","delay":0},
{"id":"小说正文","type":"SelectorText","parentSelectors":["章节链接"],
"selector":"div.ART","multiple":false,"regex":"","delay":0}]}
{"_id":"yidu","startUrl":
["https://yiduks.com/artlist_[1-5].html"],"selectors":
[{"id":"yidu","type":"SelectorElement","parentSelectors":["_root"],
"selector":"div.b_row","multiple":true,"delay":0}
{"id":"bubiaoti","type":"SelectorText","parentSelectors":["test"],
"selector":".b_title a","multiple":false,"regex":"","delay":0},
{"id":"banquanzuozhe","type":"SelectorText","parentSelectors":["_root"],
"selector":".b_auth a","multiple":false,"regex":"","delay":0},
{"id":"xiaoshuoleixing","type":"SelectorText","parentSelectors":
["_root"],"selector":"div.b_artc","multiple":false,"regex":"","delay":0},
{"id":"shifoulianzai","type":"SelectorText","parentSelectors":["_root"],
"selector":"div.b_staus","multiple":false,"regex":"","delay":0},
{"id":"yuedu","type":"SelectorLink","parentSelectors":["_root"],
"selector":".b_read a","multiple":false,"delay":0},
{"id":"ielianjie","type":"SelectorLink","parentSelectors":["dianjiyuedu"],
"selector":"td[width] a","multiple":true,"delay":0},
{"id":"zhangjie","type":"SelectorText","parentSelectors":["lianjie"],
"selector":"b","multiple":false,"regex":"","delay":0},
{"id":"zuozhe","type":"SelectorText","parentSelectors":["elianjie"],
"selector":".MC a[title]","multiple":false,"regex":"","delay":0},
{"id":"hengwen","type":"SelectorText","parentSelectors":["lianjie"],
"selector":"div.ART","multiple":false,"regex":"","delay":0}]}
欢迎关注 技术团队的知乎账号 我们凭团队实例运作以下专栏, 必须干货!
互联网创业专栏 (我们小伙伴的创业历程)
与您一起聊技术 (APP、微信公众号、小程序、H5 技术总结)
互联网产品研发管理 (我们公司对产品结构的管理思路)
我们是不一样的技术团队:

(我们认为:所有的企业行为,都解读为交易行为,无论是摩拜单车、外卖平台、自动售货机、招聘社区、家政服务,都用交易的语言来表达,我们专栏里面有很多实际案例和开发过程和交付流程)

(类似于元素周期表,我们把交易拆解成元素级别,根据业务定制组装,完全复原个性化需求,我们专栏里面有很学术也很实际的介绍)

(每个项目设置: 导师成长基金、参与人员的奖励,全员股权池,创业氛围浓郁,我们专栏公开分享了我们的一些经验)

(专治各种复杂的业务场景, 我们通过简洁的元素和分层组合,来完成复杂场景的业务定制,我们在这一块有非常多的案例,在互联网创业专栏里面有详细描述)
参考
- ^网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上 https://www.cnblogs.com/fengzheng/p/8440806.html
- ^crxdl插件网 https://crxdl.com
- ^webscraper官方文档 http://webscraper.top/543178
- ^海词网 https://m.dict.cn/
- ^易读网 http://www.yidukk.com/