敖丙思维导图-Mysql数据库
数据库三范式
一:确保每列的原子性
二:非主键列不存在对主键的部分依赖 (要求每个表只描述一件事情)
三:满足第二范式,并且表中的列不存在对非主键列的传递依赖
分库分表
1、单表记录条数达到百万或千万级别时
2、解决表锁的问题
水平分表:表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询次数
垂直分表:把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中。
设定网站用户数量在千万级,但是活跃用户数量只有1%,如何通过优化数据库提高活跃用户访问速度?
可以使用MySQL的分区,把活跃用户分在一个区,不活跃用户分在另外一个区,本身活跃用户区数据量比较少,因此可以提高活跃用户访问速度。
还可以水平分表,把活跃用户分在一张表,不活跃用户分在另一张表,可以提高活跃用户访问速度。
事务隔离级别
Read uncommitted 、Read committed 、Repeatable read 、Serializable
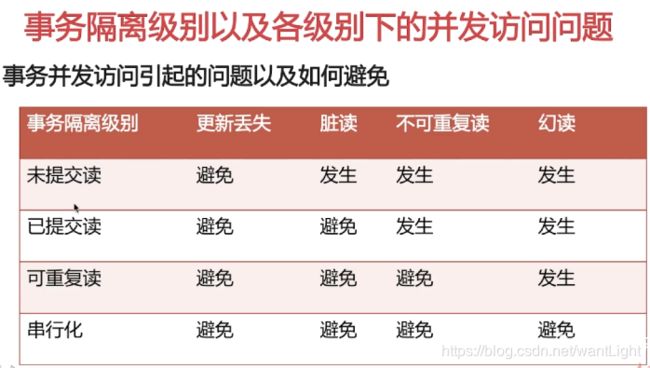
1.脏读:
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
2.不可重复读:
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
例如,一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改。原始读取不可重复。如果只有在作者全部完成编写后编辑人员才可以读取文档,则可以避免该问题。
3.幻读:
是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象
发生了幻觉一样。
例如,一个编辑人员更改作者提交的文档,但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料添加到该文档中。如果在编辑人员和生产部门完成对原始文档的处理之前,任何人都不能将新材料添加到文档中,则可以避免该问题。
索引
程序局部性:一个程序在访问了一条数据之后,在之后会有极大的可能再次访问这条数据和访问这条数据的相邻数据。在操作系统的概念中,当我们往磁盘中取数据,假设要取出的数据的大小是1KB,但是操作系统并会取出4KB(一个页表项)的数据。在MySQL的InnoDb引擎中,页的大小是16KB,是操作系统的4倍。
二叉树插入有序数列会变成链表,而平衡二叉查找树,左右子树高度差不得超过1,时间复杂度O(logn),会产生非常多IO次数。(红黑树也是为了保证树的平衡性,降低树的高度)
B树是一种多路搜索树,每个节点可以拥有多于2个孩子的节点。(不限制路数会退化成有序数组)它常用于文件系统的索引,因为一棵树无法一次性加载进入内存,涉及磁盘操作。可以每次加载B树的一个节点,一步步往下找。
B+树的数据都在叶子节点,同时叶子节点之间还加了指针形成链表。
为啥不用hash索引呢
- 取多条数据时,B+树由于所有数据都在叶子结点,不用跨层,同时由于有链表结构,只需要找到首尾,通过链表就能把所有数据取出来了。
- 数据库中的索引一般是在磁盘上,数据量大的情况可能无法一次装入内存,B+树的设计可以允许数据分批加载,同时树的高度较低,提高查找效率。
- InnoDB主索引 (聚集索引, 必须要有,且只有一个聚集索引),其中叶子中存放的就是数据行
- InnoDB普通索引 (非聚集索引),其中叶子节点存储主键值,通过辅助索引查找到主键之后,再通过查找的主键去查找主键索引。(回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。),考虑使用
覆盖索引代替
索引的重建过程
现某张表的数据量和其存储的实际数据数目不匹配,这种情况通常是因为删除了过多的数据。
alter table t engine=InnoDB 可以用于重建整张表的索引数据,将表里以前的一些索引空洞给一并压缩进行重新整合。
在mysql进行索引树重建的时候,会将原先表的所有数据都拷贝存入另外一张表,在拷贝的期间如果有新数据写入表的话,会建立一份redo log文件将新写入的数据存放进去,保证整个过程都是online的,因此这也被称为Online DDL,redo log在这整个过程中就起到了一个类似缓冲池的角色。
联合索引
create index idx_obj on user(age asc,height asc,weight asc)
- idx_obj这个索引会根据age,height,weight进行
排序(联合索引的排序有这么一个原则,从左往右依次比较大小,因此直接用height和weight不会走索引。) - idx_obj这个索引是一个
非聚簇索引,查询时需要回表。
当覆盖索引生效的时候能够避免“回表查询”操作,减少了io查询的次数。如果数据库引擎使用了myisam则不需要回表,直接根据对应的叶子地址去查询数据即可
最左前缀匹配原则,MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)。
=和in可以乱序,比如 a=1 and b=2 and c=3 建立(a,b,c)索引可以任意顺序,MySQL的查询优化器会帮你优化成索引可以识别的形式。
MyISAM和InnoDB都使用B+树来实现索引:
MyISAM的索引与数据分开存储
MyISAM的索引叶子存储指针,主键索引与普通索引无太大区别
InnoDB的聚集索引和数据行统一存储
InnoDB的聚集索引存储数据行本身,普通索引存储主键
InnoDB一定有且只有一个聚集索引
InnoDB建议使用趋势递增整数作为PK,而不宜使用较长的列作为PK
HASH索引
(1):BTree索引可能需要多次运用折半查找来找到对应的数据块
(2):HASH索引是通过HASH函数,计算出HASH值,在表中找出对应的数据
(3):大量不同数据等值精确查询,HASH索引效率通常比B+TREE高
(4):HASH索引不支持模糊查询、范围查询和联合索引中的最左匹配规则,而这些Btree索引都支持
MySQL死锁分析
show engine innodb status;(锁会加在聚集索引)explain
- 间隙锁互斥 (并发事务,间隙锁可能互斥): 事务A删除某个区间内的一条不存在记录,获取到
共享间隙锁,会阻止其他事务B在相应的区间插入数据,因为插入需要获取排他间隙锁。 - 共享排他锁死锁(并发插入相同记录,可能死锁) : 三个事务都试图往表中插入一条为7的记录,A先执行,插入成功,rollback,id=7排他锁释放。B和C要想插入成功,必须获得id=7的排他锁,但由于双方都已经获取到id=7的共享锁,它们都无法获取到彼此的排他锁,死锁就出现了。当然,InnoDB有死锁检测机制,B和C中的一个事务会插入成功,另一个事务会自动放弃
- 并发间隙锁的死锁(并发插入,可能出现间隙锁死锁(难排查)) : A执行delete后,会获得(3, 10)的共享间隙锁。
B执行delete后,也会获得(3, 10)的共享间隙锁。
A执行insert后,希望获得(3, 10)的排他间隙锁,于是会阻塞。
B执行insert后,也希望获得(3, 10)的排他间隙锁,于是死锁出现。
唯一索引中定义的类型与传入不一致,导致update时无法命中索引而对每一行都加锁(type:index:走索引的全表扫描;),导致并发时互相等待对方insert时的锁而出现死锁。
explain关键字
type字段(扫描方式):
- system:系统表,少量数据,往往不需要进行磁盘IO;(外层嵌套从
临时表查询/系统表) - const:常量连接;(命中
主键,且被连接的部分是一个常量) - eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描;(
对于前表的每一行(row),后表只有一行被扫描) - ref:非主键非唯一索引等值扫描(对于前表的每一行(row),后表可能有多于一行的数据被扫描);
- range:范围扫描(
索引上的范围查询); - index:索引树扫描(扫描索引上的全部数据);
- ALL:全表扫描(full table scan);
sql语句调优
- 列类型尽量定义成数值类型,且长度尽可能短
- 根据需要建立多列联合索引 / 覆盖索引
- 多表连接 / 排序 / 分组 的字段上建立索引
- 避免在索引列上使用mysql的内置函数 / 表达式操作
- 查询结果只有一条用limit 1
or可能会导致全表扫描,此时可以优化为union查询;
如果
允许空值,不等于(!=)的查询,不会将空值行(row)包含进来,此时的结果集往往是不符合预期的,此时往往要加上一个or条件,把空值(isnull)结果包含进来;
- 优化limit分页,返回上次最大查询记录(偏移量)。
- like语句前面尽量不要加%
- 避免在where子句中使用!=或<>操作符
- 联合索引一般遵循最左匹配原则。
- exist&in的合理利用。
B的数据量小于A,适合使用in,如果B的数据量大于A,即适合选择exist。 - 如果检索结果中不会有重复的记录,推荐union all 替换 union。
SQL语句执行得很慢
- 偶尔很慢
- 数据库在刷新脏页。(
redo log被写满了,数据同步到磁盘中) - 拿不到锁。
show processlist
- 一直很慢
- 没用到索引
- 数据库自己选错索引。(系统采样来预测索引的基数,导致系统没有走索引)

innodb内部的线程

MVCC (https://blog.csdn.net/Waves___/article/details/105295060)
多版本控制(Multiversion Concurrency Control): 指的是一种提高并发的技术。MVCC只在 Read Committed 和 Repeatable Read两个隔离级别下工作。其他两个隔离级别和MVCC不兼容,Read Uncommitted总是读取最新的记录行,而不是符合当前事务版本的记录行;Serializable 则会对所有读取的记录行都加锁。
默认事务隔离级别是RR(可重复读),防止幻读是通过 "行级锁+MVCC"一起实现的(for update)。
而 MVCC 的实现依赖:隐藏字段、Read View、Undo log
- 隐藏字段
- DB_TRX_ID(6字节):表示最近一次对本记录行作
修改(insert | update)的事务ID。 - DB_ROLL_PTR(7字节):回滚指针,
指向当前记录行的undo log信息 - DB_ROW_ID(6字节):随着新行插入而单调递增的行ID。
- Read View 结构(重点)
其实Read View(读视图),跟快照、snapshot是一个概念。
Read View主要是用来做可见性判断的, 里面保存了“对本事务不可见的其他活跃事务”。
- low_limit_id:目前出现过的最大的事务ID+1,即下一个将被分配的事务ID
- up_limit_id:活跃事务列表trx_ids中最小的事务ID,如果trx_ids为空,则up_limit_id 为 low_limit_id。
- trx_ids:Read View创建时其他未提交的活跃事务ID列表。
- creator_trx_id:当前创建事务的ID,是一个递增的编号。
- Undo log
Undo log中存储的是老版本数据,当一个事务需要读取记录行时,如果当前记录行不可见,可以顺着undo log链找到满足其可见性条件的记录行版本。
- insert undo log : 事务对insert新记录时产生的undo log, 只在
事务回滚时需要, 并且在事务提交后就可以立即丢弃。 - update undo log : 事务对记录进行delete和update操作时产生的undo log,不仅在
事务回滚时需要,快照读也需要,只有当数据库所使用的快照中不涉及该日志记录,对应的回滚日志才会被purge线程删除。
Purge线程:为了实现InnoDB的MVCC机制,更新或者删除操作都只是设置一下旧记录的deleted_bit,并不真正将旧记录删除。
为了节省磁盘空间,InnoDB有专门的purge线程来清理deleted_bit为true的记录。purge线程自己也维护了一个read view,如果某个记录的deleted_bit为true,并且DB_TRX_ID相对于purge线程的read view可见,那么这条记录一定是可以被安全清除的。
不同事务或者相同事务的对同一记录行的修改,会使该记录行的undo log成为一条链表,undo log的链首就是最新的旧记录,链尾就是最早的旧记录。
当前读和快照读
快照读(snapshot read):普通的 select 语句(不包括 select … lock in share mode, select … for update)
当前读(current read) :select … lock in share mode,select … for update,insert,update,delete 语句(这些语句获取的是数据库中的最新数据)
Read Committed / Repeatable Read的Read View(快照)产生
- Repeatable Read :
每次读取前生成一个 - Read Committed :
第一次生成一个
在RR级别下,快照读是通过MVVC(多版本控制)和undo log来实现的,当前读是通过加record lock(记录锁)和gap lock(间隙锁)来实现的。
单独靠MVCC并不能完全防止幻读,对“当前读语句”读取的记录行加记录锁(record lock)和间隙锁(gap lock),禁止其他事务在间隙间插入记录行,来防止幻读。也就是前文说的"行级锁+MVCC"。
可见性比较算法
在innodb中,创建一个新事务后,执行第一个select语句的时候,innodb会创建一个快照(read view),快照中会保存系统当前不应该被本事务看到的其他活跃事务id列表(即trx_ids)。当用户在这个事务中要读取某个记录行的时候,innodb会将该记录行的DB_TRX_ID与该Read View中的一些变量进行比较,判断是否满足可见性条件。
锁
表级锁与行级锁
InnoDB 存储引擎同时支持行级锁(row-level locking)和表级锁(table-level locking),默认情况下采用行级锁。
共享锁与排他锁
共享锁和共享锁可以兼容,排他锁和其它锁都不兼容。
- 共享锁(S):允许获得该锁的事务读取数据行(
读锁)。 - 排他锁(X):允许获得该锁的事务更新或删除数据行(
写锁),同时阻止其他事务取得该数据行上的共享锁和排他锁。
意向锁
InnoDB 除了支持行级锁,还支持由 MySQL 服务层实现的表级锁。当这两种锁同时存在时,可能导致冲突。意向锁属于表级锁,由 InnoDB 自动添加,不需要用户干预。
- 意向共享锁(IS):事务在给数据行加行级共享锁之前,必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务在给数据行加行级排他锁之前,必须先取得该表的 IX 锁。
InnoDB 行级锁实现
InnoDB 通过给索引上的索引记录加锁的方式实现行级锁。
记录锁Record Lock针对索引记录(index record)的锁定。
SELECT * FROM t WHERE id = 1 FOR UPDATE
间隙锁 (gap锁)
锁定的是索引记录之间的间隙、第一个索引之前的间隙或者最后一个索引之后的间隙。
SELECT * FROM t WHERE c1 BETWEEN 1 and 10 FOR UPDATE
Next-key 锁 (行锁+gap锁)
前面两种的组合,对记录及前面的间隙加锁。
如果索引有唯一属性,则 InnnoDB 会自动将 next-key 锁降级为记录锁。
SELECT * FROM t WHERE id <1 for update; 使用的就是间隙锁;
SELECT * FROM t WHERE id <=1 for update; 使用的就是 next-key 锁,因为表中存在 id = 1 的数据。
LOG
- 重做日志(
redo log) -前滚
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
在事务开始之后逐步写入重做日志文件,存储引擎先将重做日志写入innodb_log_buffer。
redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
- 回滚日志(
undo log)
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读。
事务开始之前,将当前是的版本生成undo log,undo 也会产生 redo 来保证undo log的可靠性。
可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
- 二进制日志(
binlog)
用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步;
用于数据库的基于时间点的还原;
事务提交的时候,一次性将事务中的sql语句(一个事物可能对应多个sql语句)按照一定的格式记录到binlog中。
MySQL通过两阶段提交过程来完成事务的一致性的,也即redo log和binlog的一致性的,两个日志都提交成功(刷入磁盘),事务才算真正的完成。
阶段1:InnoDB redo log 写盘,InnoDB 事务进入 prepare 状态。
阶段2:如果前面prepare成功,binlog 写盘,那么再继续将事务日志持久化到binlog,如果持久化成功,那么InnoDB 事务 则进入 commit 状态(实际是在redo log里面写上一个commit记录)。
唯一索引和普通索引的抉择
change buffer
在执行更新操作时,如果要更新的数据页在内存中就直接更新,否则的话,在不影响数据一致性的前提下,InnoDB 会将更新操作缓存在 change buffer 中,从而省去了从磁盘读取数据页的过程。在下次查询操作读取到恰好需要更新的数据页时,会将 change buffer 的更新语句执行,写入数据页。将操作应用到硬盘的过程叫 merge. 后台线程会定期 merge 或 数据库正常关闭时,也会进行 merge 操作。
因此对于写多读少的业务change buffer 发挥的作用也就越大。
主要的差异是在更新过程中,唯一索引由于需要唯一性检查,不能利用 change buffer。多了从磁盘到内容读取数据的过程,其中涉及随机 IO 的访问,相对来说效率就低了。
如果服务器异常掉电,会不会导致 change buffer 丢失?
并不会,因为 change buffer 中的数据已经被记录到 redo log 中,所以不会丢失。
由于 change buffer 一部分数据在磁盘,一部分在内存。对于在磁盘的数据已经 merge 所以不会丢失。
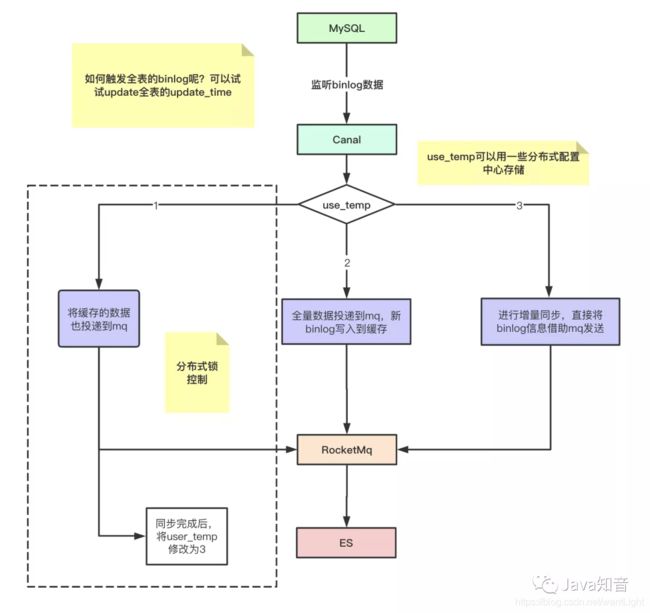
es和mysql之间是怎么做数据一致性的维护
canal会模拟成一台mysql的slave去接收mysql的master节点返回的binlog信息,然后将这些binlog数据解析成一个json字符串,再投递到mq当中。在rocketmq的接收端会做消息的监听,一旦有接收到消息就会写入到es中。
canal做日志订阅的时候可以借助一个“缓冲池”角色的帮助。这个缓冲池可以是一些分布式缓存,用于临时接收数据,当全量同步完成之后,进入一个加锁的状态,此时将缓存中的数据也一同刷入到db中,最后释放锁。由于将redis中的数据刷入到磁盘中是个非常迅速的瞬间,因此整个过程可以看作为几乎平滑无感知。
该如何全量将binlog都发送给到canal呢?
binlog的产生主要是依靠数据发生变动导致的,假设我们需要同步的表里面包含了update_time字段的话,这里只需要更新下全表的update_time字段为原先值+1 就可以产生出全表的binlog信息了。