通过职位搜索"Python开发",看下搜索的结果:
https://www.zhipin.com/job_detail/?query=python开发&city=101020100&industry=&position=
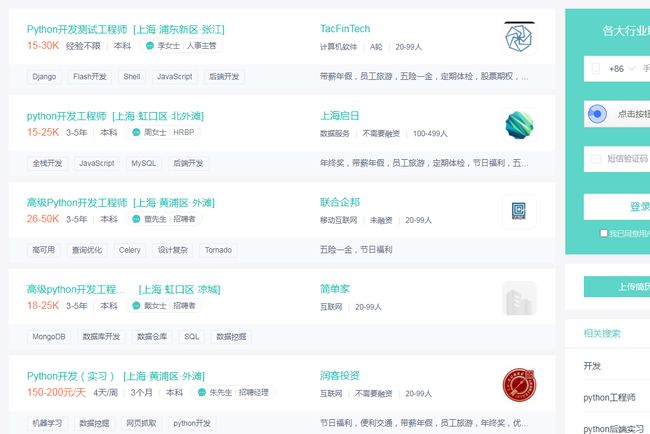
按F12,使用开发者工具查看下html的结构:
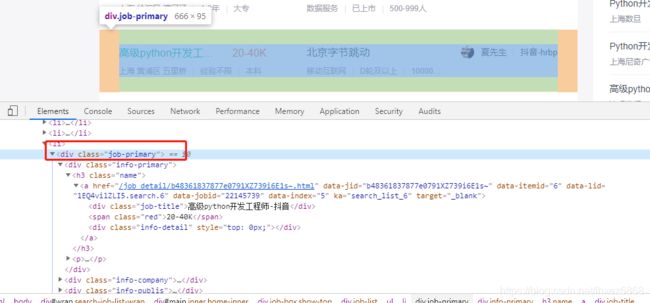
先获取所有的class="job-primary"的div列表,然后遍历列表对象,在子查询里面的各个需要的信息。
职位需求信息如下:

公司信息:

先创建数据库,保存爬取的信息
create table boss_job(
jid varchar(50) primary key,
name varchar(50) not null,
sal varchar(20),
addr varchar(50),
work_year varchar(20),
edu varchar(20),
company varchar(40),
company_type varchar(20),
company_staff varchar(20),
url varchar(200)
)engine=innodb default charset=utf-8
boss直聘需要带上cookies,不然无法正常返回,会访问到一个请稍后的页面。
爬取库使用BeautifulSoup4。
#-*- coding: UTF-8 -*-
import requests,pymysql
from bs4 import BeautifulSoup
def get_one_page_info(kw,page):
'''获取第page的数据,搜索关键字kw'''
url="https://www.zhipin.com/c101020100/?query="+kw+"&page="+str(page)+"&ka=page-"+str(page)
cookies={
"lastCity":"101020100",
"_uab_collina":"156594127160811552815566",
"sid":"sem_pz_bdpc_dasou_title",
"__c":"1566178735",
"__g":"sem_pz_bdpc_dasou_title",
"__l":"l=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title&r=https%3A%2F%2Fsp0.baidu.com%2F9q9JcDHa2gU2pMbgoY3K%2Fadrc.php%3Ft%3D06KL00c00fDIFkY0IWPB0KZEgsA_ON-I00000Kd7ZNC00000Irp6hc.THdBULP1doZA80K85yF9pywdpAqVuNqsusK15yRLPH6zuW-9nj04nhRLuhR0IHYYn1mzwW9AwHIawWmdrRN7P1-7fHN7wjK7nRNDfW6Lf6K95gTqFhdWpyfqn1czPjmsPjnYrausThqbpyfqnHm0uHdCIZwsT1CEQLILIz4lpA-spy38mvqVQ1q1pyfqTvNVgLKlgvFbTAPxuA71ULNxIA-YUAR0mLFW5Hfsrj6v%26tpl%3Dtpl_11534_19713_15764%26l%3D1511867677%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E5%252587%252586%2525E5%2525A4%2525B4%2525E9%252583%2525A8-%2525E6%2525A0%252587%2525E9%2525A2%252598-%2525E4%2525B8%2525BB%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253DBoss%2525E7%25259B%2525B4%2525E8%252581%252598%2525E2%252580%252594%2525E2%252580%252594%2525E6%252589%2525BE%2525E5%2525B7%2525A5%2525E4%2525BD%25259C%2525EF%2525BC%25258C%2525E6%252588%252591%2525E8%2525A6%252581%2525E8%2525B7%25259F%2525E8%252580%252581%2525E6%25259D%2525BF%2525E8%2525B0%252588%2525EF%2525BC%252581%2526xp%253Did(%252522m3224604348_canvas%252522)%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D8%26wd%3Dboss%25E7%259B%25B4%25E8%2581%2598%26issp%3D1%26f%3D8%26ie%3Dutf-8%26rqlang%3Dcn%26tn%3Dbaiduhome_pg%26sug%3Dboss%2525E7%25259B%2525B4%2525E8%252581%252598%2525E5%2525AE%252598%2525E7%2525BD%252591%26inputT%3D4829&g=%2Fwww.zhipin.com%2F%3Fsid%3Dsem_pz_bdpc_dasou_title",
"Hm_lvt_194df3105ad7148dcf2b98a91b5e727a":"1565941272,1566178735",
"__zp_stoken__":"c839%2FbUp4y%2FcG59Q1lQU84czePIXK3dDRi%2F3AGRWQ6KVQWUNKQa4lxpn2jAVyXKDRxk0g3H19loBTLIK4KtUfLuxbQ%3D%3D",
"__a":"74852898.1565941271.1565941271.1566178735.32.2.3.3",
"Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a":"1566178748",
}
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"referer":"https://www.zhipin.com/c101020100/?query=python%E5%BC%80%E5%8F%91&page=1&ka=page-1"
}
r= requests.get(url,headers=headers,cookies=cookies)
soup=BeautifulSoup(r.text,"lxml")
# 先获取每一行的列表数据
all_jobs=soup.select("div.job-primary")
infos=[]
for job in all_jobs:
jnama=job.find("div",attrs={"class":"job-title"}).text
jurl="https://www.zhipin.com"+job.find("div",attrs={"class":"info-primary"}).h3.a.attrs['href']
jid=job.find("div",attrs={"class":"info-primary"}).h3.a.attrs['data-jid']
sal=job.find("div",attrs={"class":"info-primary"}).h3.a.span.text
info_contents=job.find("div",attrs={"class":"info-primary"}).p.contents
addr=info_contents[0]
# 有的工作年薪是没有的,有的是有四个的需要更具contents子节点的个数去判断
# 上海 静安区 汶水路4天/周6个月大专
# contents里面包含着文本和em标签
# print(info_contents)
# ['上海 嘉定区 安亭', , '3-5年', , '大专']
if len(info_contents)==3:
work_year = "无数据"
edu = job.find("div", attrs={"class": "info-primary"}).p.contents[2]
elif len(info_contents)==5:
work_year=job.find("div",attrs={"class":"info-primary"}).p.contents[2]
edu=job.find("div",attrs={"class":"info-primary"}).p.contents[4]
elif len(info_contents)==7:
work_year = job.find("div", attrs={"class": "info-primary"}).p.contents[-3]
edu = job.find("div", attrs={"class": "info-primary"}).p.contents[-1]
company=job.find("div",attrs={"class":"company-text"}).h3.a.text
company_type=job.find("div",attrs={"class":"company-text"}).p.contents[0]
company_staff=job.find("div",attrs={"class":"company-text"}).p.contents[-1]
print(jid,jnama,jurl,sal,addr,work_year,edu,company,company_type,company_staff)
infos.append({
"jid":jid,
"name":jnama,
"sal":sal,
"addr":addr,
"work_year":work_year,
"edu":edu,
"company":company,
"company_type":company_type,
"company_staff":company_staff,
"url":jurl})
print("%s职位信息,第%d页抓取完成"%(kw,page))
return infos
def save_mysql(infos):
'''保存每一页的数据到数据库中'''
db = pymysql.connect("localhost","root","123456","ai11",charset="utf8")
cursor = db.cursor()
for job in infos:
sql = "insert into boss_job values('%(jid)s','%(name)s','%(sal)s','%(addr)s','%(work_year)s'\
,'%(edu)s','%(company)s','%(company_type)s','%(company_staff)s','%(url)s');"%(job)
try:
cursor.execute(sql)
except pymysql.Error as e:
print("数据库出错",e)
db.rollback()
else:
db.commit()
for i in range(1,11):
infos=get_one_page_info("python开发",i)
save_mysql(infos)
结尾:欢迎加入我们一起学习
最后,拿起你的小手机,点赞收藏,加扣群,里面有更多更好玩的资料源码分享。
正所谓,来者都是客,咳咳,不对,是你有一块钱,我有一块钱,我们合在一起就是两块钱,知识,是可以互相交流的^_^
