Hystrix断路器 -- SpringCloud
一)、分布式面临的问题
复杂分布式体系结构中的应用程序有数十个依赖,每个依赖关系在某个时候将不可避免地失败
服务雪崩效应
多个微服务之间调用地时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他微服务,这就是所谓地"扇出",如果在扇出地链路上,某个微服务地调用相应时间过长或者不可用,微服务A地调用就会占用越来越多的系统资源,进而引起系统崩溃,这就是所谓的“雪崩效应”
对于高流量的应用来说,单一的后端依赖可能会导致所有服务上的资源在几秒内饱和。比失败更糟糕,这些应用程序还可能导致服务之间延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示对故障和延迟进行隔离和管理。以便单个依赖失败,不能导致整个应用程序和系统崩溃
二)、是什么
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个服务失败,避免级联故障,以提供分布式系统的弹性。
“断路器”本身是一种开关装置,当某个服务发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个服务预期的,可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要的占用,从而避免了故障在分布式系统种的蔓延,乃至雪崩。
github网址:https://github.com/Netflix/Hystrix/wiki/How-To-Use
三)、能干嘛
1、服务降级
2、服务熔断
3、服务限流
4、接近实时的监控
。。。。。。。。
服务熔断和服务降级都是在SpringCloud整合Feign基础上进行操作的。
服务熔断和服务降级源码下载:https://download.csdn.net/download/erge353729094/12818080
四)、服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制
当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后恢复调用链路。在springcloud框架熔断机制通过Hystrix实现。Hystrix会监控微服务间的状况,当失败调用用到一定的阈值,缺省是5秒内20次调用失败就会启动熔断机制。熔断机制的注解是@HystrixCommand
服务熔断示例步骤
1、参考microservercloud-provider-dept-8001新建microservicecloud-provider-dept-hystix-8001。
2、pom.xml文件的配置,添加Hystrix的相关依赖
3、yml文件的配置修改,Eureka主机名的修改
4、修改Controller,在存在异常的方法上加上个熔断机制,@HystrixCommand
5、在主启动类上添加@EnableCircuitBreaker,开启断路器
6、测试
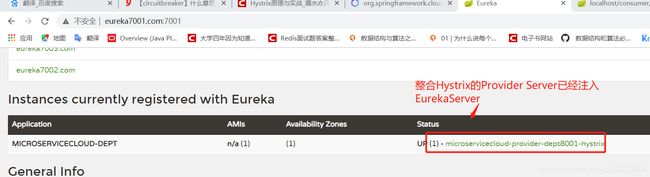
开启三个Eureka Server,在开启microservicecloud-provider-dept-hystix-8001,最后开启microservicecloud-consumer-dept-80。
访问:http://eureka7001.com:7001/。http://localhost/consumer/dept/get/127

五)、服务降级
整个资源快不够了,忍痛将某些资源先关掉,待度过难关后,再开启回来
服务降级处理是在客户端完成的,与服务端没有关系
步骤:
5.1、修改父工程microservicecloud-api,根据已有的DeptClientService,创建DeptClientServiceFallBackFactory实现FallbackFactory。该类需要添加注解@Component。否则启动会报错
@Component //该注解一定要添加
public class DeptClientServiceFallBackFactory implements FallbackFactory {
@Override
public DeptClientService create(Throwable throwable) {
return new DeptClientService(){
@Override
public Dept get(long id) {
return new Dept(id,"已做了相应的降级服务处理,暂停服务。晚点再试",
"no this databasee in mysql");
}
@Override
public boolean add(Dept dept) {
return false;
}
@Override
public List list() {
return null;
}
};
}
} 5.2、修改父工程microservicecloud-api。修改DeptClientService接口上的注解@FeignClient

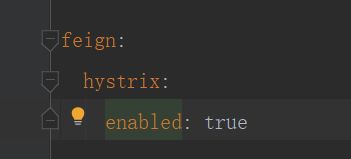
5.3、修改microservicecloud-consumer-dept-feign的yml
5.4、测试
启动3个Eureka Server,启动microservicecloud-provider-dept-8001。启动microservicecloud-consumer-dept-feign。
访问http://localhost/consumer/dept/get/2。故意关闭microservicecloud-provider-dept-8001。再访问http://localhost/consumer/dept/get/2


服务降级可参考网址:https://blog.csdn.net/ityouknow/article/details/81230412
小结:
服务熔断:一般是某个服务故障或者异常引起,类似于现实世界中的“保险丝”,当某个异常被触发,直接熔断整个服务,而不是一直等到此服务超时。
服务降级:一般是从整体负荷来考虑的,就是当某个服务熔断后,服务将不在被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强。
六)、服务监控hystrixDashboard
除了隔离依赖服务的调用外,Hystrix还提供了准实时的调用监控(Hystrix Dashboard),Hystrix会持续地记录所有通过Hystrix发起地请求执行信息,并以统计报表地形式展示给用户,包括每秒执行了多少请求,多少成功,多少失败等。Netflix通过hystrix-metrics-event-stream项目实现了对以上指标监控,SpringCloud也提供了Hystrix Dashboard地整合,对监控内容转化成可视化界面
参考网址:周阳老师教学视频
https://segmentfault.com/a/1190000005988895
https://my.oschina.net/7001/blog/1619842
https://zhuanlan.zhihu.com/p/114942145?from_voters_page=true