2020算法设计与分析 官方考前模拟卷 参考答案
算法设计与分析 样例试题
- 算法设计与分析总结笔记
注:
- 此试题仅供了解题型,和期末考试试题没有任何直接关系
FBI Warning:这套题难度较大,千万不要坏了心态,xj大佬说要是考试那么难他直播粪坑蝶泳
Power By 王宏志教授
- (5 分) 请叙述下述算法的功能并分析时间复杂度
算法 Compute
输入: 整数 n
输出: 整数
x=0
for i=1 to n do
for j=1 to i do
for k=1 to i+j do
x=x+1
return x
解:
Σ i = n + 1 2 n i \Sigma_{i=n+1}^{2n}i Σi=n+12ni
O ( n 3 ) O(n^3) O(n3)
- (5 分) 令 f, g 和 h 为定义在正整数上的正实数函数。假设f(n)=O(g(n)),
g(n)=O(h(n)),证明 f(n)=O(h(n)).
∵ f ( n ) = O ( g ( n ) ) \because f(n)=O(g(n)) ∵f(n)=O(g(n))
∃ n 0 , c 0 ∈ R , ∀ n ≥ n 0 , 0 ≤ f ( n ) ≤ c 0 g ( n ) \exists n_0, c_0\in R, \forall n\ge n_0, 0\le f(n)\le c_0g(n) ∃n0,c0∈R,∀n≥n0,0≤f(n)≤c0g(n)
同理 ∃ n 1 , c 1 ∈ R , ∀ n ≥ n 1 , 0 ≤ g ( n ) ≤ c 1 h ( n ) \exists n_1, c_1\in R, \forall n\ge n_1, 0\le g(n)\le c_1h(n) ∃n1,c1∈R,∀n≥n1,0≤g(n)≤c1h(n)
则 1 c 0 f ( n ) ≤ g ( n ) \frac{1}{c_0}f(n)\le g(n) c01f(n)≤g(n)且 g ( n ) ≤ c 1 h ( n ) g(n)\le c_1h(n) g(n)≤c1h(n)
故 1 c 0 f ( n ) ≤ c 1 h ( n ) \frac{1}{c_0}f(n)\le c_1h(n) c01f(n)≤c1h(n), 即 f ( n ) ≤ c 0 c 1 h ( n ) f(n)\le c_0c_1h(n) f(n)≤c0c1h(n)
∴ n ′ = m a x ( n 0 , n 1 ) , c = c 0 c 1 , ∀ n ≥ n ′ , 0 ≤ f ( n ) ≤ c h ( n ) \therefore n'=max(n_0, n_1), c=c_0c_1, \forall n\ge n', 0\le f(n)\le ch(n) ∴n′=max(n0,n1),c=c0c1,∀n≥n′,0≤f(n)≤ch(n)
即 f ( n ) = O ( h ( n ) ) f(n)=O(h(n)) f(n)=O(h(n))
- (5 分) 求解递归方程 T ( n ) = 2 T ( n / 2 ) + n 4 T(n)=2T(n/2)+n^4 T(n)=2T(n/2)+n4 其中 k>0 是一个常数。
解:
log b a = log 2 2 \log_{b}{a}=\log_2{2} logba=log22
f ( n ) = n 4 f(n)=n^4 f(n)=n4
Θ ( f ( n ) ) > Θ ( log b a ) \Theta (f(n))>\Theta (\log_ba) Θ(f(n))>Θ(logba)
T ( n ) = f ( n ) = n 4 T(n)=f(n)=n^4 T(n)=f(n)=n4
我不知道k拿来干嘛
- (15 分) 设计分治算法求解下述问题:
输入:对于一个有 n 个元素的数组 A 和一个有 k 个位置集合 S = p 1 , … , p k , 1 ≤ p 1 < p 2 < … < p k ≤ n S={p1, …, pk}, 1\le p1
设计时间复杂度为 O(nlogk)的分治算法求解此问题,要求写出伪代码并证明算法的时间复杂度。
不会。dbq乡亲父老,我真不会,我怎么想都是nlogn……
就讲讲nlogn的做法
解:
- 思路:存在 p j p_j pj,则找到 a p j a_{p_j} apj, [ p 1 , p j ] [p_1, p_j] [p1,pj]只要在 [ 1 , a p j ] [1, a_{p_j}] [1,apj]中找即可;于是可以想到二分,但是A数组无序,所以我们可以模仿“快速排序”,将比某一个数(本方法取中位数)小的所有数分到一边,大的分另一边,然后迭代进行;
- 解法:某一时刻搜索 [ l s , r s ] [ls, rs] [ls,rs]时需要保证搜索的A的 [ l a , r a ] [la, ra] [la,ra]区间内的所有数的大小位次,均在 [ p l s , p r s ] [p_{ls}, p_{rs}] [pls,prs]内
List<> func(A, la, ra, S, ls, rs):
Get: sMid, aMid
if S仅有一个: return {aMid}
if A仅有一个: return {A仅有的那一个}
用快速排序里的方法讲所有小于、大于aMid的数分到两侧(1个while套2个while)
Get: func(A, la, aMid, S, ls, sMid), func(A, aMid+1, ra, S, sMid+1, rs)
return 上述两部分并集
假设n与k同阶(这个假设我是从别人那学来的,先用,下面我会对此表示质疑)则复杂度:T(n)=2T(n/2)+O(m) --> O(nlogk)
上述复杂度分析引用自他人
- 异议:
这里的复杂度分析假设n与k同阶是很奇怪的。
直观做法:排序+匹配;排序复杂度nlogn,匹配是nk,二分优化变成nlogk。
因此直观做法的复杂度也是nlogk,即nlogn
那所谓“正确的分治做法”优势在哪?仅仅是题目要求嘛?
姑且作为对分治的学习辅助吧
- (15 分) 要为将即将到来的哈尔滨世界博览会设计和生产 n 个不同的展品,
每一个项目首先用 CAD 软件设计,然后送到外面加工厂加工,第 i 个展品的设计时间为 di,加工时间为 fi. 加工厂能力很强,可以同时加工 n 个展品,所以对于每件展品,只要设计结束就可以立刻开始加工。但是,只有一位设计师,所以需要确定产品设计的顺序,以最快时间完成所有 n 件展品的设计和加工。
比如,完成了第一件展品的设计,可以将其交给加工厂,然后立刻开始第二件展品的加工。当完成第二件展品的设计时,可以将其交给加工厂而不需要考虑是否第一件展品已经加工完成。
设计多项式贪心算法求解此问题,分析时间复杂度,并证明其正确性。
解:
- 显然,设计师的时间是一定的;并且,只要设计完成,一定能立刻加工;
- 所以,共用时间其实是 max Σ j = 1 i d j + f j , 1 ≤ i ≤ n \max{\Sigma_{j=1}^{i}d_j}+f_j, 1\le i\le n maxΣj=1idj+fj,1≤i≤n,目标使该值最小
- 对于任意两个展品,设 d a , d b , f a , f b d_a, d_b, f_a, f_b da,db,fa,fb,则当a比b先设计时,所用时间为 t 1 = max ( d a + f a , d a + d b + f b ) = d a + max ( f a , d b + f b ) t_1=\max (d_a+f_a, d_a+d_b+f_b)=d_a+\max (f_a, d_b+f_b) t1=max(da+fa,da+db+fb)=da+max(fa,db+fb);反之所用时间为 t 2 = d b + max ( f b , d a + f a ) t_2=d_b+\max (f_b, d_a+f_a) t2=db+max(fb,da+fa)
- 若 f a < f b f_a
fa<fb 时 t 1 = d a + d b + f b , t 2 = d b + max ( f b , d a + f a ) t_1=d_a+d_b+f_b, t_2=d_b+\max (f_b, d_a+f_a) t1=da+db+fb,t2=db+max(fb,da+fa)- 当 f b > d a + f a f_b>d_a+f_a fb>da+fa时, t 1 − t 2 = d a > 0 t_1-t_2=d_a>0 t1−t2=da>0,则 t 1 > t 2 t_1>t_2 t1>t2;
- 当 f b ≤ d a + f a f_b\le d_a+f_a fb≤da+fa时, t 2 = d b + d a + f a t_2=d_b+d_a+f_a t2=db+da+fa, t 1 − t 2 = f b − f a > 0 t_1-t_2=f_b-f_a>0 t1−t2=fb−fa>0,则 t 1 > t 2 t_1>t_2 t1>t2;
- 故应以 f i f_i fi为关键字进行递减排序能获得最小时间,即加工时间长的“早死早超生”
- 时间复杂度 O ( n log n ) O(n\log n) O(nlogn)
-
(15 分) 我们考虑将数轴上的 n 个点聚成 k 类的问题。输入: n 个从小到大的不同实数 x1, x2, …, xn表示 n 个不同点,一个参数 kn.
任务:将 n 个点划分成 k 个不相交的非空集合 S1, …., Sk 满足⋃ =1 ={x1,x2, …, xn}, Si 中所有点在 Si+1 中所有点左边, 1i目标:最小化∑ =1 (),其中 cost(Si)=(max(Si)-min(Si))2. max(Si)是 Si 中的最小元素, min(Si)是 Si中的最大元素。
例如,如果 Si={xj}, cost(Si)=0,如果 Si={xj, xj+1, …, xj+t}, xj,
例如,考虑将 4 个元素的集合{1,5,8,10}聚为两个类,有三种可能:- S1={1}, S2={5,8,10},总代价是 02+52=25
- S1={1,5}, S2={8,10},总代价是 42+22=20
- S1={1,5,8}, S2={10},总代价是 72+02=49
所以,算法的解是最优解 S1={1,5}, S2={8,10}。
解:
- 解法: f ( i , j ) f(i, j) f(i,j)为从第1到第i个元素分为j份的最小最大值
- 前提:因为若干元素被分为k-1份后,再分一份变成k份一定更优
- 状态转移方程:
f [ i , j ] = min ( max ( f [ t − 1 , j − 1 ] , w [ t , i ] ) ) f[i, j]=\min (\max (f[t-1, j-1], w[t, i])) f[i,j]=min(max(f[t−1,j−1],w[t,i]))
w [ t , i ] = ( a [ i ] − a [ t ] ) 2 w[t, i]=(a[i]-a[t])^2 w[t,i]=(a[i]−a[t])2
i ∈ [ 1 , n ] , j ∈ [ 2 , k ] i\in [1, n], j\in [2, k] i∈[1,n],j∈[2,k] - 伪代码
// 1. prepare f[i, 1]
// 2. calc
for (j = 2; j <= k; j++) {
for (i = 1; i <= n; i++) {
f[i, j] = MaxInt;
for (t = i + 1; t <= n; t++) {
w = (a[i] - a[t]) * (a[i] - a[t]);
f[i, j] = min(f[i, j], max(f[t-1][j-1], w));
}
}
}
// 3. ans: f[n, k]
- (8 分) 假设我们希望不仅能使一个计数器增值,也能使之复位至零(即,使其中所有的位都为 0)。请说明如何将一个计数器实现为一个位数组,使得对一个初始为零的计数器,任一个包含 n 个 INCREMENT 和 RESET 操作的序列的时间都为 O(n)。
解:
- 用n个1代表n;
- 每个INCREMENT操作为在最左边增加一个1,复杂度为O(1);
- 每个RESET操作为将所有1变为0,复杂度为O(m),m为1的个数,即在两个RESET之间的INCREMENT个数;
- 因此,n个操作中所有RESET操作的总复杂度为O(m’),m’=n个操作中INCREMENT的个数;
- 而n个操作中所有的INCREMENT操作的总复杂度也为O(m’);
- 故两种操作的总复杂度为 O ( 2 m ′ ) = O ( n ) , m ′ ≤ n O(2m')=O(n), m'\le n O(2m′)=O(n),m′≤n;
- (12 分) 随着越来越多的计算机配备了双核 CPU, TinySoft 公司的首席技术官塞塔格利布决定更新他们著名的产品——SWODNIW。
这个例程由 N 个模块组成,每个模块都应该在某个内核中运行。估计了在两个内核上执行所有例程的成本。我们把它们定义为 Ai 和 Bi。同时, M 对模块需要进行数据交换。如果它们在同一个内核上运行,则可以忽略此操作的成本。否则,就需要额外的费用。你应该明智地安排,把总费用降到最低。 请写出伪代码并分析算法复杂度。
这题对于成本的描述非常模糊,姑且认为是固定成本;M对模块姑且认为无重复(即不存在:[1, 2], [2, 3])
不然太难了,多项式时间内,我不会做……
解:
- 对于每对模块i和j,代价有4种情况:
- 都在内核A: t = A i + A j t=A_i+A_j t=Ai+Aj
- 都在内核B: t = B i + B j t=B_i+B_j t=Bi+Bj
- i在内核A,j在内核B: t = A i + B j + w i j t=A_i+B_j+w_{ij} t=Ai+Bj+wij
- i在内核B,j在内核A: t = B i + A j + w i j t=B_i+A_j+w_{ij} t=Bi+Aj+wij
- 比较4种代价,选择最小的代价
- 对于无需数据交换的模块,取 A i B i A_iB_i AiBi最小值即可
伪代码不用我写了吧
复杂度: O ( m + n ) O(m+n) O(m+n)
- (10 分)设计算法并分析时间复杂度:对于字符串 s,寻找这样的子串: 长度为 n, 且包含最多的碱基字符。返回其包含的碱基字符个数。注:碱基字符为(A、 G、 C、 T)
解:
- 可以类比为一个长度为n的窗口逐步划过整个字符串进行搜索,每一次平移变化只有少一个字符和多一个字符;
- 首先计算前n个字符的指定字符个数,然后一个一个平移,判断头尾是否为指定字符,适当把计数数字+1/-1,记录最大值和子串首字符指针。
伪代码不用我写了吧
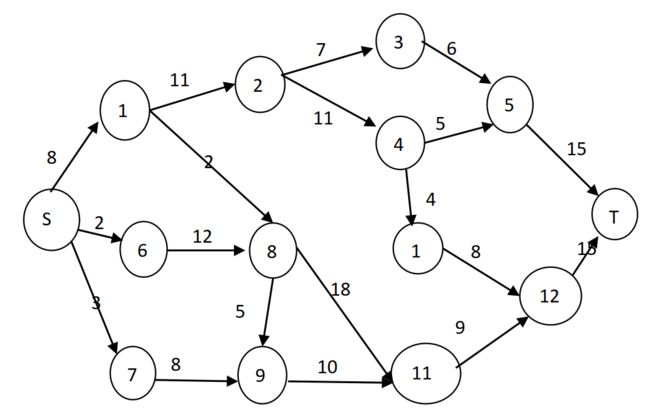
- (10 分)利用 A* 搜索计算下图中 S 到 T 的最短路径,要求写出计算过程S
老师笔误,中间的1是10
解:
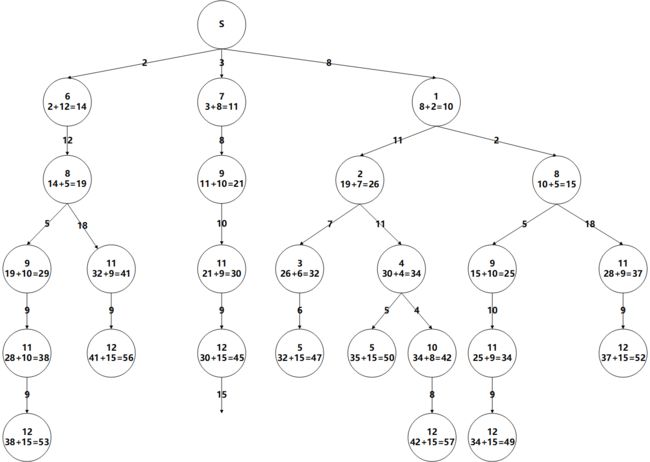
- 扩展S
- 扩展1
- 扩展7
- 扩展6

- 扩展右边的8
- 左边的8实际上不用扩展了,但是老师的教学里好像需要扩展……那就蛮扩展一下(此处存疑,需要求证)

- 扩展中间的9
- 扩展右边的9
- 扩展2
- 扩展左边的9
- 扩展中间的11
- 扩展3
- 扩展4

- 扩展右数第2个11
- 扩展右数第1个11
- 扩展左数第1个11
- 扩展左数第2个11
- 扩展左数第3个12,扩展到T,45为所有叶子节点最小,停止
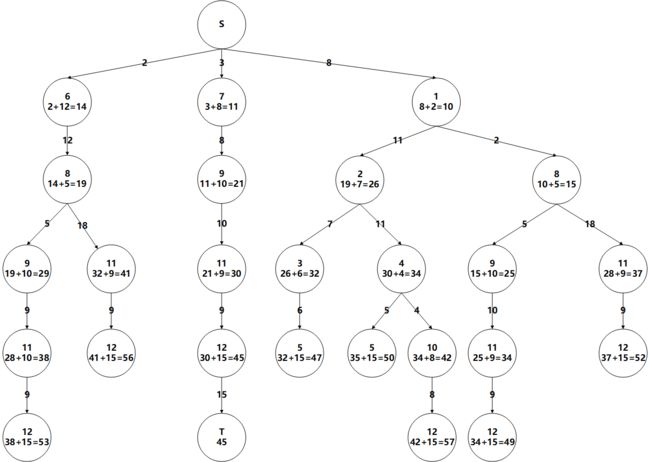
个人觉得相同点只需要扩展到达该点路径最短的即可,但是mooc上的方法不是如此,保留意见