【数据库】——Mysql索引的底层剖析
前言
应该先写这个索引的,在写事务的博客,只能说上一篇博客写早了。
涉及到的知识点/你可以了解到的点,关键字
索引原理,底层存储;
B-Tree、B+Tree
聚集索引,非聚集索引,联合索引,覆盖索引
为什么会索引失效/索引失效的原理
正文
什么是索引?
索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构
为什么加索引
索引能极大的减少存储引擎需要扫描的数据量
索引可以把随机IO变成顺序IO
索引可以帮助我们进行分组、排序等操作时,避免使用临时表
索引上数据结构的对比
二叉树
二叉树别的不说,有个很致命的问题,如果存储的数据在极端的情况下,就直接变成链表了

平衡二叉树

这里说,二叉树一个相对平衡的平衡树,叶子节点的高度差等于一
平衡二叉树解决了上面二叉树中提到的问题。
但还是存在一些问题的:
1、平衡二叉树的高度依旧很高,他的每个节点只有两个分支。
2、没有很好的利用操作系统的io预读能力
内存与磁盘的数据交互的单位为页,1页的大小为4k或8k(和操作系统有关系)
即一次io的大小为4k,而平衡二叉树的每个节点只存储了一个数据,一些引用,远远不足以填充4k的空间
B-Tree 多路平衡查找树
兄弟,我真的不想在听到谁念成B减Tree了。
该念成什么,自己心里没点B Tree 么
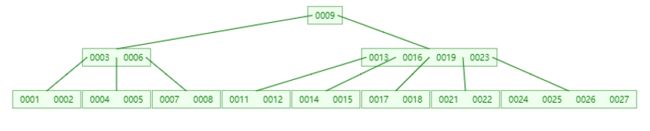
B-Tree就解决了上面的两个问题,然后自身存在这么一些属性:
1、B-Tree是一个绝对平衡的平衡树,叶子永远是在一层上的。
2、在mysql中,充分利用了io预读能力,每一次io取出的数据是16k
就是看图片里面每个方块,他的大小就是16k
如果索引的数据类型是int,int的大小为4k,如果算上些引用的话,那么每个节点的锁存储的数据就是16/4+2(引用)k 个数据,当然对于这个数据也不用特别的认真,大概一看的就行了。
同时,在存储相同多的数据时,这个树就矮了很多
3、在B-Tree中 节点的数据去区间属于 左开右开 () 区间,节点的最大数=最大路数-1
B+Tree 加强版的多路平衡查找树(mysql中索引的默认数据结构)

B+Tree 属于加强版的B-Tree,他拥有B-Tree中的所有优势
但与B-Tree稍有不同:
最大的节点个数=最大的路数
数据区间是一个左闭右开区间
最大的区别是,只有叶子节点存储数据,非叶子节点只存储关键字以及引用
并且节点直接顺序排列,具有相邻节点的引用
相比B-Tree的优势
1、是B-Tree的加强版,拥有B-Tree的所有优势
2、扫库能力更强
从图上的数据结构上来看,b+tree的叶子节点形成了一个链表,所以在范围查询的时候,会沿着链表扫描数据,不会在返回上一层节点。
3、磁盘读写能力更强
因为,,他比b-tree多一路
4、排序能力更强
理由和上面一样
5、查询效率更稳定
数据全都存在叶子节点上,所以随机访问时,io此时都是一样的,所以时间啥也都差不多。
数据结构网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
我上面的图是从这截出来的,然后有兴趣的同学可以看看,可以看出数据在各个数据结构中是如何插入删除查找的。
引擎中数据的存储
不知道大家对于引擎有多少了解,然后对于引擎的话,后面应该会有一个稍微减短的文章来介绍几个mysql的引擎。
这里的话,需要知道的是,在不同的引擎下 数据库中数据的具体存储 是不太一样的。
下面来介绍一下在innodb和myisam中数据存储的一个情况
Myisam
先看一个之前画的老图

在myisam中,一个数据表,会生成三个文件.frm(印象中在mysql5.8之后这个文件没有了) .myi .myd 文件
.frm 文件,存储的是一个数据表的表结构,这里不重点讲,并且是在所有的引擎中,都会生成的一个文件
.myi 文件,存储的是一个表中的索引。
.myd 文件,存储的是一个表中的数据。
在myd中就是数据,如图所示就好了。
在myi中会生成多个非聚集索引树,左侧是以id为索引的索引树,右侧是以name为索引的索引树,当然他们都是在一个文件中的,只是为了更好的表现画在了两侧,而一直检索到叶子节点的时候,其保存的数据也是对应的一个引用,就是指在磁盘上实际的一个物理地址。
Innodb

在innodb下会生成两个文件,frm咱么就不提了,所以就只有一个ibd文件是用来存储数据的。
在ibd 中存储的是数据以及索引,其中包含一个以id为索引的聚集索引树,以及多个非聚集锁索引。
其中以id为索引的聚集索引树,叶子节点包含了某一行的所有数据,不要问我什么是聚集索引,我会告诉你,这就是
然后建立的其他索引的索引树都是非聚集索引,叶子节点存储的是其对应的id。
如果以非聚集索引树查找数据时,会先通过非聚集索引树找到对应的主键,然后在去以主键为索引的聚集索引树找到对应的主键,最后找到所需数据。
这里我们引申两个概念,组合索引、覆盖索引。
组合索引,顾名思义,你可能理解成将多个索引加在一起了,那我现在为他正名,一般的索引,我们叫他单值索引,将多个字段放在一起作为一个索引时 我们叫他组合索引,而其实呢,单值索引也不就是组合索引 字段为1时的一个特殊情况罢。
覆盖索引,如果我们select的字段/数据,可以通过,索引树直接找到数据,不需要再次去聚集索引的叶子节点找数据,这时我们就叫他覆盖索引。
比如,上面的图,在加上些其他的phone,email等字段后,我们select id,name from table wehre name= '张三'
这时,id和name我们只需要在name的索引树上就能找到并返回了。
索引失效
相信索引失效,有不少同学都死记硬背过,背固然是一个方法,或者还有什么顺口溜。
都挺好的,愿意的话,你可以被,但是理解一下为什么比较好。
其实上面说了索引的存储,数据的存储,而失效的原因就已经在其中了。
我总结的一句话,就是,千万不要让系统懵逼了。
比如,使用 <> 会使索引失效,为什么呢,因为,系统我自上向下索引,你告诉我找谁,我能按着大街小巷胡同门牌号的给你找到,你告诉我不找谁,那你一定是在逗我。
其他情况同理。
这里在说一个问题,像之前怎们背的时候什么时候失效,什么时候不失效,还可以继续背着,这里补充一个离散性的问题
离散性的问题主要时说,当你建立索引的时候,如果某一列的离散性非常的不好,那么你使用它的时候,他可能并不起作用,这是系统的优化的一个点。其实揪其底,还是和上面以上,你这个索引的离散型这么差,老弄的我如此懵逼,不知道该往哪走,我还不如自己遍历整个表快呢,你快去在那凉快的树下面呆这去,最好找个榴莲树。
基本上索引失效的问题到这里也就结束了。
优化
也没能说光将原理,
现在说几点可以优化的部分,对于上面的内容,理解的可以消化一下优化的点,不理解的可以通过优化的点再回过头找一下共鸣
-索引列的数据长度能少则少
-索引一定不是越多越好,越全越好
-匹配列前缀可用到索引 like 99%,like %99%用不到索引
-where条件中not int 和<> 操作无法使用索引
-匹配范围值,order by ,group by 也可以用到索引
-多使用指定列查询,只返回自己想得到的数据列,少用select *(如果查询列可通过索引节点中的关键字直接返回,则该索引称覆盖索引。覆盖索引可减少数据库IO,将随机IO变为顺序IO,可提高查询性能);
-索引列上不能使用表达式和函数
-对于过长字符串需创建索引可通过创建前缀索引;(前缀的选择,要有好的离散性)
联合索引中如果不是按照索引最左列开始查找,无法使用索引
联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引
联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引;
结语
Hello Wrold