Python应用|TOPSIS综合评价法与案例分析
Python应用:TOPSIS综合评价法与案例分析
- 一、TOPSIS综合评价法
-
- 1. 计算步骤
- 二、数据归一化处理
- 三、案例分析
一、TOPSIS综合评价法
TOPSIS方法:Technique for Order Preference by Similarity to an Ideal Solution,根据有限个评价对象与理想化目标的接近程度进行排序,适用于多项目标、对多个方案进行比较选择的分析方法。
1. 计算步骤
(1)构造初始矩阵A(n个评价指标,m个目标)

式中,aij表示第i个目标的第j项指标值(1≤i≤m, 1≤j≤n)。
#获取数据
data=pd.read_excel('研究生院评估数据.xlsx').values #程序和数据在一个根目录下
A=data[:,1:] #获取初始矩阵
A=np.array(A) #转为数组
m,n=A.shape[0],A.shape[1] # m,n为行,列数
(2)由于各个指标的量纲可能不同,需要对原始数据进行标准化处理。(归一化处理)

#归一化处理
A1=np.ones([m,n],float)
for i in range(n):
mu=np.power(np.sum(np.power(A[i],2)),0.5)
A1[i]=A[i]/mu
式中:

针对不同类型的要求还有其他的归一化处理方法,见二。
(3)构造加权标准化矩阵Z

式中,wj是第j个指标的权重。
权重确定方法:Delphi法,对数最小二乘法,层次分析法等。
W=[w1,w2,w3,w4]
W=np.array(W)
Z=np.ones([m,n],float)
for i in range(len(W)):
for j in range(len(W)):
if i==j:
W[i,j]=W0[j]
else:
W[i,j]=0
(4)根据加权矩阵判断正负理想解Z+ ,Z-
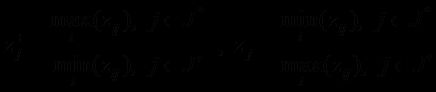
式中,J*是效益性指标集(指标值越大越好);J’是成本型指标集(指标值越小越好)。
Zmax=np.ones([1,n],float)
Zmin=np.ones([1,n],float)
for j in range(n):
Zmax[0,j]=max(Z[:,j])
Zmin[0,j]=min(Z[:,j])
(5)计算各个方案的到正理想点的距离Si+和负理想点的距离Si-

for i in range(m):
Smax=np.sqrt(np.sum(np.square(Z[i,:]-Zmax[0,:])))
Smin=np.sqrt(np.sum(np.square(Z[i,:]-Zmin[0,:])))
(6)计算各个方案的相对贴近度Ci
![]()
C=Smin/(Smin+Smax)
C=pd.DataFrame(C,index=['院校' + i for i in list('12345')])
按每个方案的相对贴近度的大小进行排序,值越大越好,找出最优解。
二、数据归一化处理
(1) 效益型指标:指标值越大越好

#归一化处理
A1=np.ones([A.shape[0],A.shape[1]],float)
for i in n:
if max(A[:,i])==min(A[:,i]):
A[:,i]=1
else:
for j in m:
A1[j,i]=(A[j,i]-min(A[:,i]))/(max(A[:,i])-min(A[:,i]))
(2) 成本型指标:指标值最小最好

#归一化处理
A1=np.ones([A.shape[0],A.shape[1]],float)
for i in n:
if max(A[:,i])==min(A[:,i]):
A[:,i]=1
else:
for j in m:
A1[j,i]=(max(A[:,i])-A[i,j])/(max(A[:,i])-min(A[:,i]))
(3) 中间型指标:指标最优值在某一点取得,值越靠近该点越好
![]()
式中,M为取到最优值的点。
#归一化处理
A1=np.ones([A.shape[0],A.shape[1]],float)
for i in n:
for j in m:
A1[j,i]=M/(M+abs(A[j,i])-M))
(4) 区间型指标:指标最优值落在一个区间范围呢。
设指标取值在区间[a,b]是最优的,最差下限为lb,最差上限为ub.

#归一化处理
A1=np.ones([A.shape[0],A.shape[1]],float)
for i in n:
for j in m:
if lb <= A[j,i]<= a:
A1[j,i]=(A[j,i]-lb)/(a-lb)
elif a <= A[j,i]<= b:
A1[j,i]=1
elif b <= A[j,i]<= ub:
A1[j,i]=(ub-A[j,i])/(ub-b)
else : #A[j,i]< lb or A[j,i]>ub
A1[j,i]=0
三、案例分析
问题:某一教育评估机构对5个研究生院进行评估。该机构选取了4个评价指标:人均专著、生师比、科研经费、逾期毕业率。采集数据如表所示。
| 研究生院 | 人均专著/(本/人) | 生师比 | 科研经费/(万/年) | 人均专著/% |
|---|---|---|---|---|
| 1 | 0.1 | 5 | 5000 | 4.7 |
| 2 | 0.2 | 6 | 6000 | 5.6 |
| 3 | 0.4 | 7 | 7000 | 6.7 |
| 4 | 0.9 | 10 | 10000 | 2.3 |
| 5 | 1.2 | 2 | 400 | 1.8 |
解释:人均专著和科研经费是效益性指标,预期毕业率是成本型指标,生师比是区间型指标,最优范围是[5,6],最差下限2,最差上限12. 4个指标权重采用专家打分的结果,分别为0.2,0.3,0.4和0.1。
import numpy as np
import pandas as pd
#TOPSIS方法函数
def Topsis(A1):
W0=[0.2,0.3,0.4,0.1] #权重矩阵
W=np.ones([A1.shape[1],A1.shape[1]],float)
for i in range(len(W)):
for j in range(len(W)):
if i==j:
W[i,j]=W0[j]
else:
W[i,j]=0
Z=np.ones([A1.shape[0],A1.shape[1]],float)
Z=np.dot(A1,W) #加权矩阵
#计算正、负理想解
Zmax=np.ones([1,A1.shape[1]],float)
Zmin=np.ones([1,A1.shape[1]],float)
for j in range(A1.shape[1]):
if j==3:
Zmax[0,j]=min(Z[:,j])
Zmin[0,j]=max(Z[:,j])
else:
Zmax[0,j]=max(Z[:,j])
Zmin[0,j]=min(Z[:,j])
#计算各个方案的相对贴近度C
C=[]
for i in range(A1.shape[0]):
Smax=np.sqrt(np.sum(np.square(Z[i,:]-Zmax[0,:])))
Smin=np.sqrt(np.sum(np.square(Z[i,:]-Zmin[0,:])))
C.append(Smin/(Smax+Smin))
C=pd.DataFrame(C,index=['院校' + i for i in list('12345')])
return C
#标准化处理
def standard(A):
#效益型指标
A1=np.ones([A.shape[0],A.shape[1]],float)
for i in range(A.shape[1]):
if i==0 or i==2:
if max(A[:,i])==min(A[:,i]):
A1[:,i]=1
else:
for j in range(A.shape[0]):
A1[j,i]=(A[j,i]-min(A[:,i]))/(max(A[:,i])-min(A[:,i]))
#成本型指标
elif i==3:
if max(A[:,i])==min(A[:,i]):
A1[:,i]=1
else:
for j in range(A.shape[0]):
A1[j,i]=(max(A[:,i])-A[j,i])/(max(A[:,i])-min(A[:,i]))
#区间型指标
else:
a,b,lb,ub=5,6,2,12
for j in range(A.shape[0]):
if lb <= A[j,i] < a:
A1[j,i]=(A[j,i]-lb)/(a-lb)
elif a <= A[j,i] < b:
A1[j,i]=1
elif b <= A[j,i] <= ub:
A1[j,i]=(ub-A[j,i])/(ub-b)
else: #A[i,:]< lb or A[i,:]>ub
A1[j,i]=0
return A1
#读取初始矩阵并计算
def data(file_path):
data=pd.read_excel(file_path).values
A=data[:,1:]
A=np.array(A)
#m,n=A.shape[0],A.shape[1] #m表示行数,n表示列数
return A
#权重
A=data('研究生院评估数据.xlsx')
A1=standard(A)
C=Topsis(A1)
print(C)
输出:
>>>院校1 0.553038
院校2 0.610575
院校3 0.662306
院校4 0.659379
院校5 0.281729
参考文献:
[1] 许建强, 李俊玲. 数学建模及其应用. 上海交通大学出版社.