mysql教程
首先我们先了解数据库可以干什么
SQL能做什么?
1. SQL可以创建和管理数据库、数据表、存储过程、视图等
2. SQL可以向数据库中插入新的记录,并可进行修改、删除
3. SQL可以查询数据库中的记录
4.SQL可以对数据库进愆事务控制和权限管理

按功能和用途,可以将SQL语言分为4类:DDL、DML、DQL、DCL
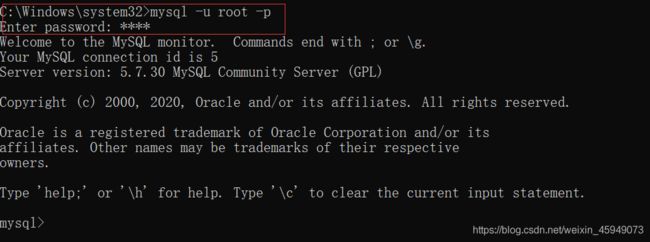
window+R后输入services.msc,找到mysql,点击启动。然后在命令提示符中输入mysql -u root -p后回车,输入密码即可启动mysql。如下图:
通过create database name;创建数据库,通过show databases;查看所有的数据库

既然可以创建数据库,那就可以删除数据库,可以通过drop database name删除相应的数据库

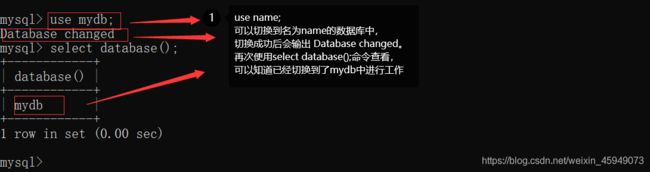
数据库创建完成后,如果想要使用刚刚所创建的名为mydb的数据库,可以使用命令use name;切换到相应的数据库中。之后使用select database();命令,可以查看当前的数据库是mydb
当我们并没有使用任意一个数据库时,输入命令select database();会发现当前正在使用的数据库为NULL,表示没有使用任意一个数据库。

在创建数据表时,准确的定义字段的数据类型是非常重要的。
MySQL支持多种数据类型,但大致可以分为3类:数值、日期/时间和字符串(字符)类型。
一、数值类型
| 类型 | 所占字节数 | 说明 |
|---|---|---|
| tinyint | 1 | 小整数值,如状态 |
| smallint | 2 | 大整数值 |
| mediumint | 3 | 大整数值 |
| int | 4 | 大整数值 |
| bigint | 8 | 极大整数值 |
| float | 4 | 单精度浮点数值 |
| double | 8 | 双精度浮点数值 |
| decimal | Max(D+,M+) | 含小数值,例如金额 |
二、日期和时间类型
| 类型 | 所占字节数 | 说明 |
|---|---|---|
| date | 3 | YYYY-MM-DC |
| time | 3 | HH:MM:SS |
| year | 1 | YYYY |
| datetime | 8 | YYYY-MM-DD HH:MM:SS |
| timestamp | 8 | YYYYMMDDHHMMSS |
三、字符串类型
| 类型 | 所占字节数 | 说明 |
|---|---|---|
| char | 0~255 | 定长字符串 |
| varchar | 0~65535 | 变长字符串 |
| text | 0~65535 | 长文本数据 |
对于已经存在的表,可以使用alter命令添加、修改、删除字段,也可以对表进彷删除操作。
#添加字段sex,类型为VARCHAR(1)
ALTER TABLE contacts ADD sex VARCHAR(1);
#修改字段sex的类型为tinyint
ALTER TABLE contacts MODIFY sex tinyint;
#删除字段sex
ALTER TABLE contacts DROP COLUMN sex;
#删除contacts表
DROP TABLE contacts;

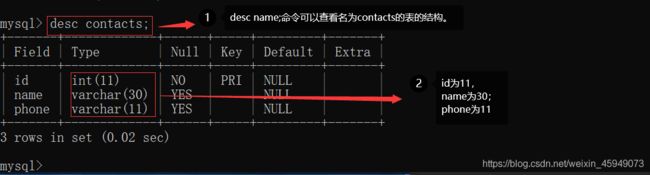
输入下面的代码创建一个名为contacts的表,它拥有id、name、phone,varchar(30)里面的30表示字节。id的key为主键
create table contacts(
id int primary key,
name varchar(30),
phone varchar(11)
);
上面代码输入后回车



*下方图片中的1句子中的值修改为字节。


切换到contacts表中,打开mydb(输入 use mydb;)。然后输入下面的代码后回车
id int not null auto_increment 表示int类型,不允许为空,id自动增长(如果没有auto_increment这一个关键词,那么id就需要我们手动给它赋值)
sex tinyint default 1, default 1表示设定默认值为1。
create table contacts(
id int not null auto_increment primary key,
name varchar(50),
sex tinyint default 1,
phone varchar(20)
);
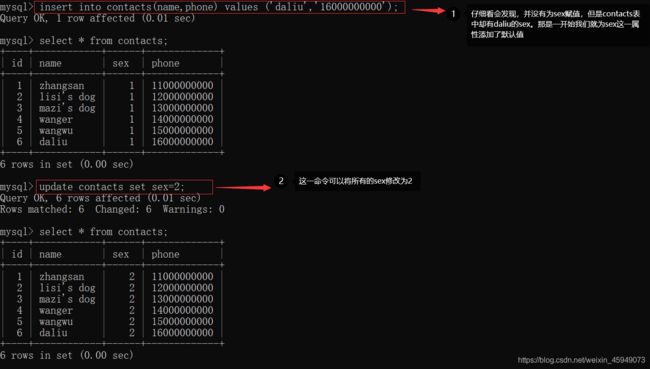
一次性插入一条数据
insert into contacts(name,sex,phone) values ('zhangsan', 1, '11000000000');
名字为lisi的狗,但需要给他进行转义,因为在单引号里面存在一个 ' 。或者用双引号包含 ' 。
insert into contacts(name,sex,phone) values ('lisi\'s dog', 1, '12000000000');
insert into contacts(name,sex,phone) values ("mazi's dog", 1, '13000000000');
也可以一次性插入多条数据
insert into contacts(name,sex,phone) values ("wanger", 1, '14000000000'),('wangwu',1,'15000000000');
或者不给sex赋值,让mysql给他赋予默认值。
insert into contacts(name,phone) values ('daliu','16000000000');
更新表中所有对应的数据。
下方语句将会把所有的sex修改为2。
update contacts set sex=2;
下面根据数据的id或者name等数据修改sex值。
update contacts set sex=1 where id=2;
update contacts set sex=3 where name='daliu';
删除数据
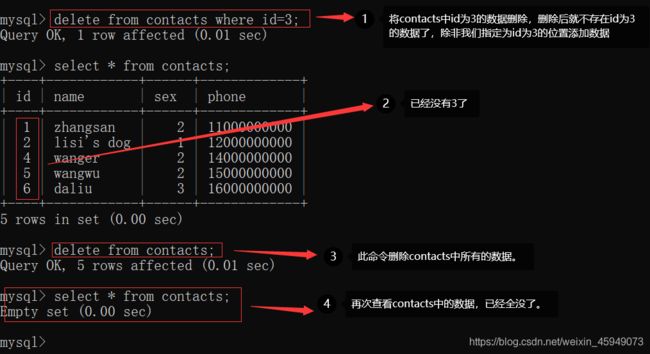
下面语句会将contacts表中的id为3的数据删除,也可以根据name等属性删除。
delete from contacts where id=3;
下面语句执行后会删除contacts中所有的数据。
delete from contacts;




用户自定义完整性
用户自定义完整性是针对某一具体关系数据座的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。
约束方法:规则、存储过程、触发器。
比如下面的代码:
create table ttt(
id int auto_increment primary key,
sex enum('男', '女'),
name varchar(20) not null
);
上述代码插入一行数据,sex不为男或者女,则插入失败!
域完整性
域完整性是针对某一具体关系数据库的约束条件,它保证表中某些列不能输入无效的值。 域完整性指列的值域的完整性,如数据类型、格式、值域范围、是否允许空值等。
就比如创建一个表,在其中有一句代码是:phone int(11) not null,它规定了phone是11位,你却要添加一个20位的数字,这肯定会报错的。
唯一性约束
在MySQL中,可以使用关键字UNIQUE 实现字段的唯一性约束,从而保证实体的完整性。unique意味着任何两条数据的同一个字段不能有相同值。 一个表中可以有多个unique约束。
建立一个名为person的表,输入下面的代码:
create table person(
id int not null auto_increment primary key comment '主键id',
name varchar(30) comment '姓名',
id_number varchar(18) unique comment '身份证号'
);
id_number varchar(18) unique comment ‘身份证号’ 此句有unique,所以不能存在具有相同身份证号的数据


下面两张图所输入的代码是
create table stu(
stu_no int not null primary key comment '学号',
stu_name varchar(30) comment '姓名'
);
create table sc(
id int not null auto_increment primary key comment '主键id',
stu_no int not null comment '学号',
course varchar(30) comment '课程',
grade int comment '成绩',
foreign key(stu_no) references stu(stu_no)
);
foreign key(stu_no) references stu(stu_no) 这一句是有外键约束。
什么是外键约束?
外键(FOREIGN KEY)约束定义了表之间的一致性关系,用于强制参照完整性。 外键约束定义了对同一个表或其他表的列的引用,这些列具有PRIMARY KEY或UNIQUE约束。
通俗点说:比如这个例子,foreign key(stu_no) references stu(stu_no),在插入数据时,必须先向主表插入,再向从表插入。删除数据时正好相反。就是说在stu这个表中不存在的学生,是无法在sc表中插入成绩的。




在SQL中,insert、update、delete和select后面都能带where子句,用于插入、修改、删除或查询指定条件的记录。
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <>或者!= | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| between and | 选取介于两个值之间的数据范围,在MySQL中,相当于>=并且<=。 |
在where子句中,使用and、or可以把两个或多个过滤条件结合起来。
| 运算符 | 描述 |
|---|---|
| and | 表示左右两边的条件同时成立 |
| or | 表示左右两边只要有一个条件成立 |
在mydb中建立名字为employee的表,代码如下:
create table employee(
id int not null auto_increment primary key,
name varchar(30) comment '姓名',
sex varchar(1) comment '性别',
salary int comment '薪资(元)'
);
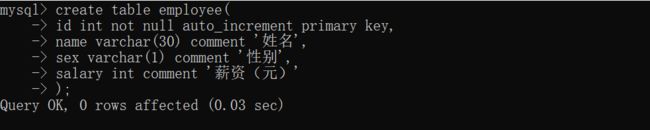

然后插入数据:如下代码所示:
insert into employee(name,sex,salary) values('一号工人','男',5500);
insert into employee(name,sex,salary) values('二号工人','女',4500);
insert into employee(name,sex,salary) values('三号工人','女',4200);
insert into employee(name,sex,salary) values('四号工人','男',7500);
insert into employee(name,sex,salary) values('五号工人','女',8500);
insert into employee(name,sex,salary) values('六号工人','男',6800);
insert into employee(name,sex,salary) values('七号工人','男',12000);
insert into employee(name,sex,salary) values('八号工人','男',3500);
insert into employee(name,sex,salary) values('九号工人','男',6000);
insert into employee(name,sex,salary) values('十号工人','男',8000);
insert into employee(name,sex,salary) values('十一号工人','女',10000);
insert into employee(name,sex,salary) values('十二号工人','女',4000);
可能会因为编码问题导致出现错误,解决方法如下(如果没出现问题就当我没写这一句话):
alter table employee default character set utf8;
alter table employee change name name varchar(30) character set utf8;
alter table employee change sex sex varchar(30) character set utf8;
insert into employee(name,sex,salary) values('一号工人','男',5500);
insert into employee(name,sex,salary) values('二号工人','女',4500);
insert into employee(name,sex,salary) values('三号工人','女',4200);
insert into employee(name,sex,salary) values('四号工人','男',7500);
insert into employee(name,sex,salary) values('五号工人','女',8500);
insert into employee(name,sex,salary) values('六号工人','男',6800);
insert into employee(name,sex,salary) values('七号工人','男',12000);
insert into employee(name,sex,salary) values('八号工人','男',3500);
insert into employee(name,sex,salary) values('九号工人','男',6000);
insert into employee(name,sex,salary) values('十号工人','男',8000);
insert into employee(name,sex,salary) values('十一号工人','女',10000);
insert into employee(name,sex,salary) values('十二号工人','女',4000);
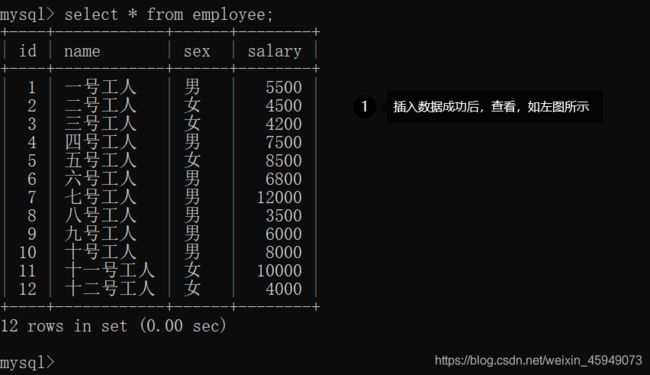
运算符 in like
运算符in允许我们在where子句中过滤某个字段的多个值
运算符like的使用
在where子句中,有时候我们需要查询包含xxx字符串的所有记录,这时就需要用到运算符like。
#where子句使用like语法
select column_name from table_name where column_name like‘%value%';
说明∶
1、like子句中的%类似于正则表达式中的*,匹配任意0个或多个字符
2、like子句中的_匹配任意单个字符
3、like子句中如果没有%和_,就相当于运算符=的效果
下面举一些例子就一目了然了。


MySQL内置函数
我们通常说的MySQL函数指的是MySQL数据库提供的内置函数,包括数学函数、字符串函数、日 期和时间函数、聚合函数、条件判断函数等,这些内置函数可以帮助用户更方便地处理表中的数 据,简化用户的操作。
| 函数 | 描述 |
|---|---|
| 数学函数 | 如ABS、SQRT、MOD、SIN.COS、TAN、COT等 |
| 字符串函数 | 如LENGTH、LOWER、UPPER、TRIM、SUBSTRING等 |
| 日期和时间函数 | 如NOW、 CURDATE、CURTIME、SYSDATE、DATE_FORMAT、YEAR、MONTH、 WEEK等 |
| 聚合函数 | COUNT、SUM、AVG、MIN、MAX |
| 条件判断函数 | IF、IFNULL、CASE WHEN等 |
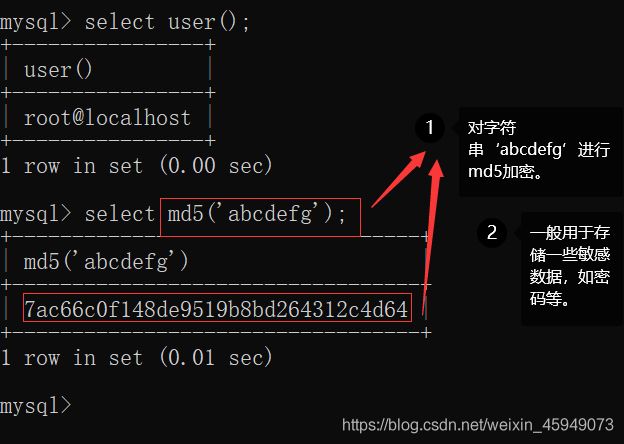
| 系统信息函数 | VERSION、DATABASE、USER等 |
| 加密函数 | MD5、SHA1、SHA2等 |
case when是流程控制语句,可以在SQL语句中使用case when来获取更加准确和直接的结果。SQL中的case when类似于编程语言中的if else或者switch。
case when的语法有2种
CASE [col_name] WHEN [value1] THEN [result1]...ELSE [default] END
CASE WHEN [expr] THEN [result1]...ELSE [default] END

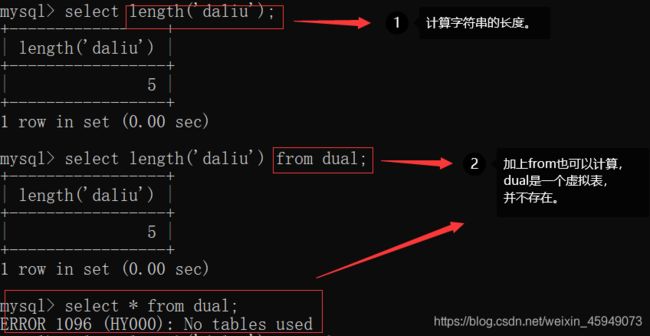
这样做仅仅比较顺眼。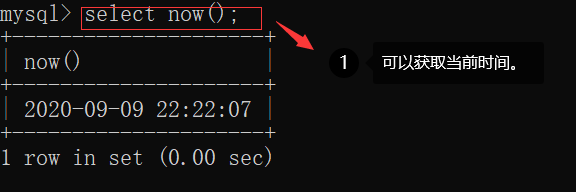
还可以在select count(*) from employee;这条命令后添加where。

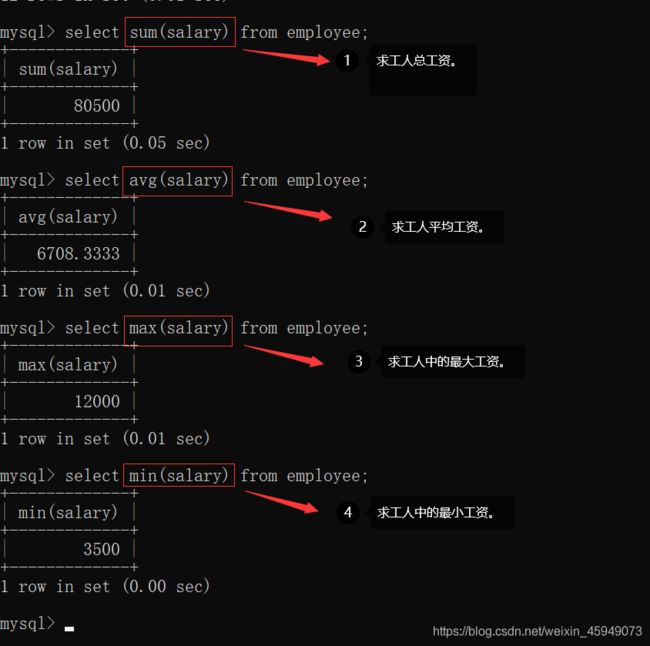
当工人中有人的salary为null时,在计算平均工资时,是不会考虑他的。

如果希望用F代替男,用M代替女。可以使用下面的代码。
select
id,
name,
case sex
when '男' then 'F'
when '女' then 'M'
else ''
end as sex,
salary
from employee;

查询结果排序与分页
order by的使用
在SQL中,使用order by对查询结果集进行排序,可以按照—列或多列进行排序。
#order by语法
selectcolumn_name1,column_name2
from table_name1, table_name2
order by column_name,column_name asc|desc]
说明∶
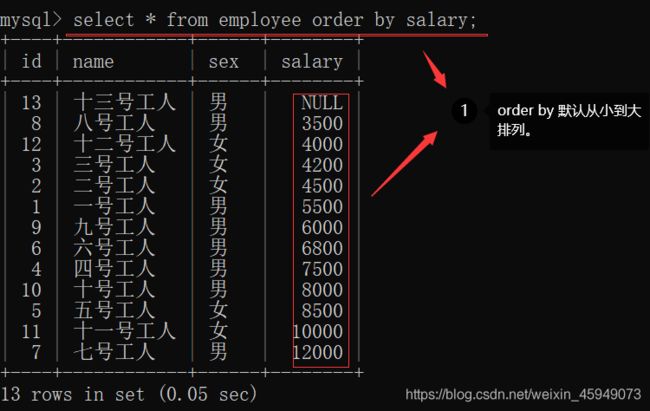
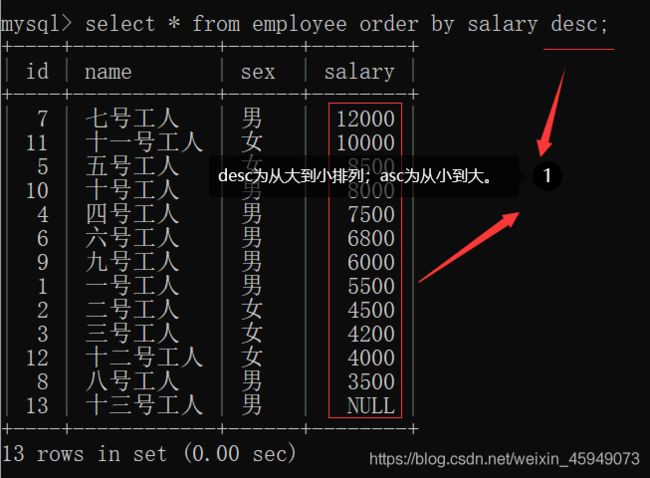
1.asc表示按升序排列,desc表示按降序排列。
2.默认情况下,对列按升序排列。
limit的使用
在select语句中使用limit子句来约束要返回的记录数,通常使用limit实现分页。
#limit语法
selectcolumn_name1, column_name2
from table_name1,table_name2
limit [offset,] row_count
说明:
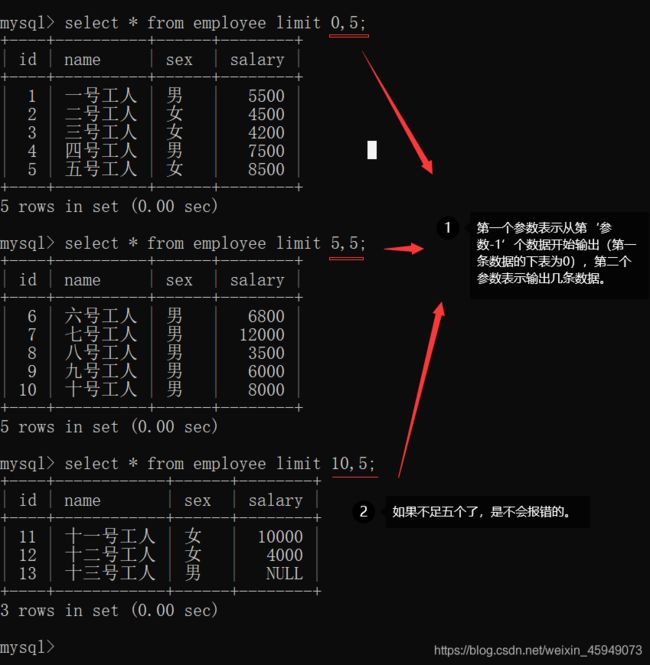
1. offset指定要返回的第一行的偏移量。第一行的偏移量是0,而不是1。
2. row_count指定要返回的最大行数。
一下操作将用到代码:
use mydb;
select * from employee;
select * from employee order by salary;
select * from employee order by salary asc;
select * from employee order by salary desc;
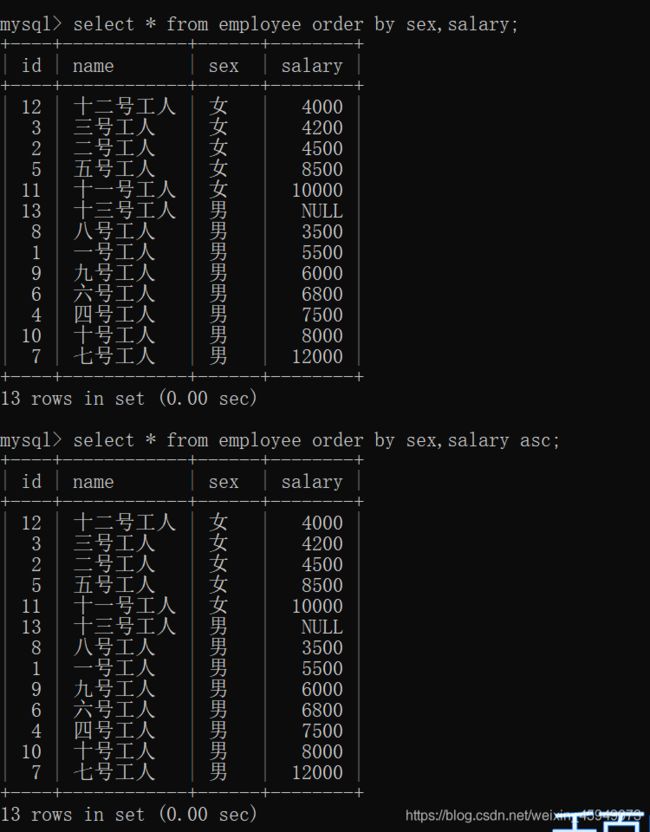
select * from employee order by sex,salary desc;
select * from employee order by sex,salary;
select * from employee order by sex,salary asc;
select * from employee limit 0;
select * from employee limit 5;
select * from employee limit 0,5;
select * from employee limit 5,5;
select * from employee limit 10,5;





group by的应用场景
我们已经掌握使用select语句结合where查询条件获取需要的数据,但在实际的应用中,还会遇到下面这类需求,又该如何解决?
某门店想掌握男、女性会员的人数及平均年龄
公司想知道每个部门有多少名员工
班主任想统计各科第—名的成绩
从字面上理解,group by表示根据某种规则对数据进行分组,它必须配合聚合函数进行使用,
对数据进行分组后可以进行count、sum、avg、max和min等运算。
#group by语法
select column_name,aggregate_function(column_name)
from table_name
group by column_name
说明∶
1. aggregate_function表示聚合函数。
2. group by可以对一列或多列进行分组。
having
在SQL中增加having子句原因是,where关键字无法与聚合函数一起使用。
having子句可以对分组后的各组数据进行筛选。
#having语法
select column_name,aggregate_function(column_name)
from table_name
where column_name operator value
group by column_name
having aggregate_function(column_name) operator value
下面举个例子:
先创建一个表
create table employee(
id int not null auto_increment primary key,
name varchar(30) comment '姓名',
sex varchar(1) comment '性别',
salary int comment '薪资(元)',
dept varchar(30) comment '部门'
);
下面插入数据
insert into employee(name,sex,salary,dept) values('一号工人','男',5500,'部门A');
insert into employee(name,sex,salary,dept) values('二号工人','女',4500,'部门C');
insert into employee(name,sex,salary,dept) values('三号工人','女',4200,'部门A');
insert into employee(name,sex,salary,dept) values('四号工人','男',7500,'部门C');
insert into employee(name,sex,salary,dept) values('五号工人','女',8500,'部门A');
insert into employee(name,sex,salary,dept) values('六号工人','男',6800,'部门A');
insert into employee(name,sex,salary,dept) values('七号工人','男',12000,'部门B');
insert into employee(name,sex,salary,dept) values('八号工人','男',3500,'部门B');
insert into employee(name,sex,salary,dept) values('九号工人','男',6000,'部门A');
insert into employee(name,sex,salary,dept) values('十号工人','男',8000,'部门B');
insert into employee(name,sex,salary,dept) values('十一号工人','女',10000,'部门C');
insert into employee(name,sex,salary,dept) values('十二号工人','女',4000,'部门B');
insert into employee(name,sex,salary,dept) values('十三号工人','女',8800,'部门A');
如果出现错误,就输入下面的代码
alter table employee default character set utf8;
alter table employee change name name varchar(30) character set utf8;
alter table employee change sex sex varchar(30) character set utf8;
alter table employee change dept dept varchar(30) character set utf8;
然后再次添加数据就行了。
下面是本次练习用到的代码:
select sex,count(*) from employee group by sex;
select dept,count(*) from employee group by dept;
select dept,sum(salary) from employee group by dept;
select dept,min(salary) from employee group by dept;
select dept,min(salary) from employee group by dept having count(*)<5;
select dept,count(*) from employee group by dept having count(*)<5;
select dept,count(*) from employee group by dept;
select dept,max(salary) from employee group by dept having max(salary)>=10000;
先把以前建立的employee表删了

创建新的employee表

插入数据

围绕group by和having进行操作



例子将会用到的代码命令:
select dept ,count(*),group_concat(name) from employee group by dept desc;
select dept ,count(*),group_concat(name order by name desc) from employee group by dept desc;
select dept ,count(*),group_concat(name order by name desc separator ';') from employee group by dept desc;