aws emr简单使用
最近在做数据的分析处理,刚开始是自己试着搭了个三台服务器的hive小集群,发现还挺麻烦的,快要弄完了才知道aws有现成的emr服务可以用,直接就放弃了自己搞的想法。使用aws的emr可以很快就启动一个配置好的集群,而且可扩展性好,需要几台就开几台,再高的配置都可以开,32核120G内存的机器开上几台,用完可以直接关掉集群,需要再开,完全没有持有集群的高昂成本,爽爆了有木有。
流程大致就是把原始数据按目录分区存放到aws s3上面,这里需要了解hive数据分区(partition)的概念,然后开启集群创建外部表,把地址指向aws s3的路径接着加载数据到数据表里面,接着就可以进行SQL查询操作了,把生成的结果保存到s3上,处理完离线数据后关闭集群,后面需要简单操作就可以用aws 的Athena服务进行查询,这样的方式对于数据量不是特别大,离线数据处理频率不是很高的公司来说应该是成本最低的了。
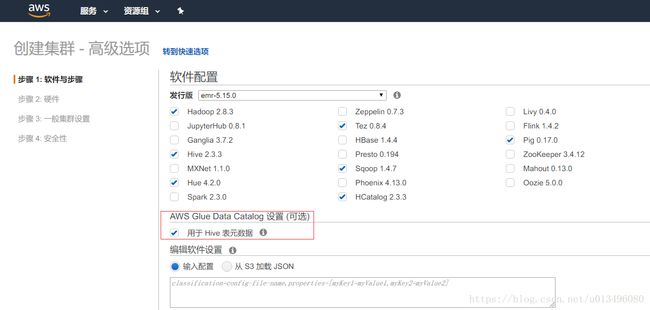
aws emr会把数据表的元数据保存起来,下次开启集群的时候会直接去读取元数据,创建的表不会丢失。下面截图是创建emr集群,注意勾选红框里面的那个选项,只有勾选了这个才会把数据保存起来供下次使用。
Hive表的数据可以由csv文件导入,可以从json文件里面解析,也可以自己写Java代码把数据库文件转化为parquet或者orc格式然后上传到s3上面,当然自己转为parquet这类压缩格式是最好的,可以省一些存储成本而且hive表可以直接读取,处理起来速度更快。集群的硬件配置方面可以从要处理的数据量与复杂程度做一个估算,我们一般一两T 的数据开个122核500G内存的竞价实例集群跑个几小时就跑能跑完,总体来说还是不贵的。hive表尽量创建外部表,那样集群不需要配置很大空间的磁盘,毕竟ebs存储贵的很,而且开小了还容易撑爆,把结果存在s3关掉集群数据不会丢失更重要的是利于数据的共享。有一个新手很容易出现的问题,好像有人会扫描emr的端口,然后占用集群去跑他们的东西,这导致了很多任务的失败,所以需要做好端口管理安全配置。
hive 使用详见
创建表的几种语法:
1.Create [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)]INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
2.create table xxxx LOCATION 's3://datacubes/tmp/hive_result' as
select xxxx #可以是hdfs的路径,也可以是外部存储的路径,可以加需要的语句,比如存储格式,分区等
3.create table xxx like xxx
数据导入的几种方式:
1.load data local inpath ‘xxx’ into table xxx [partition(column='xx')];#从本地导入数据“”/data/store“”
load data inpath ‘xxx’ into table [partition(column='xx')] ;#从hdfs或者s3导入数据“s3://xxx.xxx.xxx/xxx”或者hdfs://xxx/xx/xx
2.alter table xxx add if not exists partition(country='us',dt='20170121') location 's3://a5-bigdata/xxxx/country=us/dt=20170121'; #创建分区并载入数据
3.使用sqoop导入
sqoop import --connect jdbc:mysql://localhost:3306/xxx?charset=utf8 --username 'xxx' --password 'xxxx' --table 'xxxx'
查询的几种执行方式:
1.打开hive cli执行,这个容易因为连接断开而失败
2.写成sql在用命令行后台执行 nohup hive -f xxx.sql & 这种方式比较可靠,不过需要登录master才行
3.用程序连接执行代码,这个还没弄过
数据导出的几种方式:
1.sqoop export --connect jdbc:mysql://xxx:3306/biaoming?charset=utf8 --username 'root' --password 'xxxx' --table 'associate_us_2017' --hcatalog-table 'query_result_associate' -m 1
或者sqoop export --connect jdbc:mysql://xxx:11016/biaoming?charset=utf8 --username 'rootx' --password 'xxxx' --table 'associate_us_2017' --export-dir 's3://xxxx/tmp/hive_result' --input-fields-terminated-by '\001' 注意分隔符和字段类型,不然很容易导入失败(导入对象要先建好表,字段要对的上)详细使用见sqoop --help ,这种方式优点是省事, 缺点是导出相对而言很慢,受网络影响,而且集群要一直开着,很烧钱。。。
2.hive -e[-f] "select * from user_login" > /tmp/out.txt 这种是Linux输出重定向的方式(还是存在集群的硬盘上,不推荐)
3.insert overwrite [local] directory "s3://xxx/tmp/xxx" row format delimited fields terminated by',' select * from *** ;local可选,表示写到本地,这种速度最快(不推荐写本地,除非文件很小)
hive任务的监控
一般就用集群自带的资源管理器,或者hue,需要的话就登录master主机使用命令行查看,
yarn application –list 或者Hadoop jar list #查看运行中的任务列表
yarn application -kill application_xxx #杀进程
刚刚试用几次,只能写这么点东西了。