Mybatis框架学习(四)—查询缓存与spring的整合开发
1 项目整体目录

2 查询缓存
2.1 缓存的意义
将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
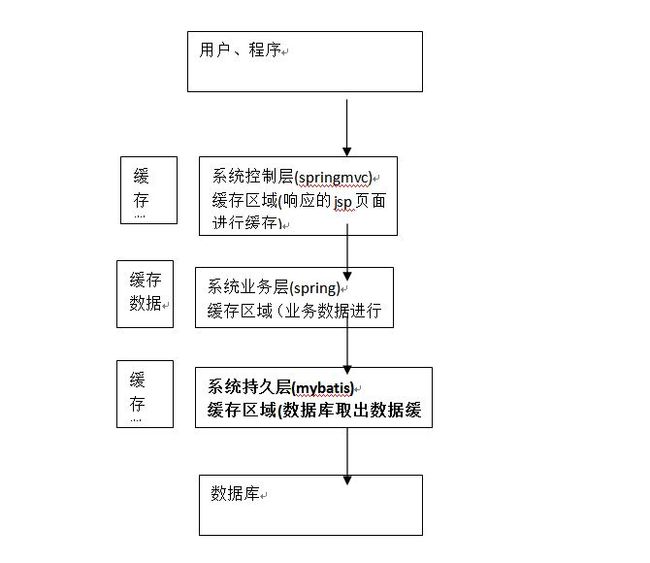
2.1 mybatis持久层缓存
mybatis提供一级缓存和二级缓存
mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据,二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的。
2.2 一级缓存
2.2.1 原理
第一次发出一个查询sql,sql查询结果写入sqlsession的一级缓存中,缓存使用的数据结构是一个map
key:hashcode+sql+sql输入参数+输出参数(sql的唯一标识)
value:用户信息
,同一个sqlsession再次发出相同的sql,就从缓存中获取数据不会而不走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
每次查询都先从缓存中查询,如果缓存中查询到则将缓存数据直接返回,如果缓存中查询不到就从数据库查询。
2.2.1 一级缓存配置
mybatis默认支持一级缓存不需要配置。
注意:mybatis和spring整合后进行mapper代理开发,不支持一级缓存,mybatis和spring整合,spring按照mapper的模板去生成mapper代理对象,模板中在最后统一关闭sqlsession。
2.2.2 一级缓存测试
新建一个CacheTest.java的缓存测试类
//一级缓存测试
@Test
public void testOneLevelCache() throws Exception{
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapperuserMapper = sqlSession.getMapper(UserMapper.class);
//第一次通过ID查询用户
Useruser = userMapper.findUserById(1);
System.out.println(user);
//中间修改用户这个时候要清空缓存,防止再从缓存中查询出脏数据
/*user.setUsername("测试一级session缓存");
userMapper.updateUser(user);
sqlSession.commit();*/
//第二次通过ID查询用户,可以观察该查询结果是从缓存获取还是查询数据库
Useru = userMapper.findUserById(1);
System.out.println(u);
sqlSession.close();
}
2.3 二级缓存
2.3.1 原理
二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓存数据结构,结构是map
每次查询先看是否开启二级缓存,如果开启从二级缓存的数据结构中取缓存数据,
如果从二级缓存没有取到,再从一级缓存中找,如果一级缓存也没有,从数据库查询。
2.3.2 mybatis二级缓存配置
在核心配置文件SqlMapConfig.xml中加入
<setting name="cacheEnabled" value="true"/>
|
|
描述 |
允许值 |
默认值 |
| cacheEnabled |
对在此配置文件下的所有cache 进行全局性开/关设置。 |
true false |
true |
要在你的Mapper映射文件中添加一行:
2.3.3 查询结果映射的pojo序列化
mybatis二级缓存需要将查询结果映射的pojo实现 java.io.serializable接口,如果不实现则抛出异常:
org.apache.ibatis.cache.CacheException:Error serializing object. Cause:java.io.NotSerializableException: cn.itcast.mybatis.po.User
二级缓存可以将内存的数据写到磁盘,存在对象的序列化和反序列化,所以要实现java.io.serializable接口。
如果结果映射的pojo中还包括了其他的pojo,都要实现java.io.serializable接口。
public class User implements Serializable {
private int id;
private String username;//用户姓名
private String sex;//性别
private Date birthday;//生日
private String address;// 地址
}
2.3.4 二级缓存禁用
对于变化频率较高的sql,需要禁用二级缓存:
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。
<select id = "findUserOrderDetail" resultMap="userOrderDetailResultMap" useCache="false">
2.3.5 刷新缓存
如果sqlsession操作commit操作,对二级缓存进行刷新(全局清空)。
设置statement的flushCache是否刷新缓存,默认值是true。
<select id="findUserOrderDetail" resultMap="userOrderDetailResultMap" flushCache="false">
2.3.6 测试代码
//二级缓存的测试
@Test
public void testTwoLevelCache() throws Exception {
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
SqlSession sqlSession3 = sqlSessionFactory.openSession();
UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class);
UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class);
UserMapper userMapper3 = sqlSession3.getMapper(UserMapper.class);
//第一次查询用户id为1的用户
User user = userMapper1.findUserById(1);
System.out.println(user);
sqlSession1.close();
//中间修改用户要清空缓存,目的防止查询出脏数据
/*user.setUsername("测试二级sqlSession缓存");
userMapper3.updateUser(user);
sqlSession3.commit();
sqlSession3.close();*/
//第二次查询用户id为1的用户
User user2 = userMapper2.findUserById(1);
System.out.println(user2);
sqlSession2.close();
}
2.3.7 mybatis的cache参数
mybatis的cache参数只适用于mybatis维护缓存。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
如下例子:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
二级缓存策略:
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:
1. LRU – 最近最少使用的:移除最长时间不被使用的对象。
2. FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3. SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
4. WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
2.4 mybatis和ehcache缓存框架整合
mybatis二级缓存通过ehcache维护缓存数据。
2.4.1 分布式缓存
将缓存数据数据进行分布式管理。
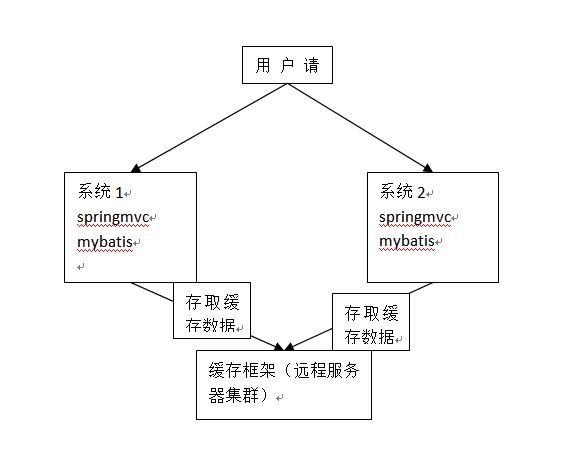
2.4.2 mybatis和ehcache思路
通过mybatis和ehcache框架进行整合,就可以把缓存数据的管理托管给ehcache。
在mybatis中提供一个cache接口,只要实现cache接口就可以把缓存数据灵活的管理起来。
这个接口在mybatis的jar包里(mybatis-3.2.7.jar—>org.apache.ibatis.cache)
mybatis中默认实现的jar包(mybatis-3.2.7.jar—>org.apache.ibatis.cache.impl)
2.4.3 下载和ehcache整合的jar包
Mybatis-ehcache-1.0.2.jar
ehcache对cache接口的实现类:
EhcacheCache.java
2.4.4 配置ehcache.xml
在config文件加下新建一个ehcache.xml文件加入如下配置:
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<diskStore path="E:\ehcache"/>
<defaultCache
maxElementsInMemory="1000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="false"
diskPersistent="true"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
defaultCache>
ehcache>
2.4.5 整合ehcache测试
在mapper.xml添加ehcache配置:
<cache type="org.mybatis.caches.ehcache.EhcacheCache">
<property name="timeToIdleSeconds" value="12000"/>
<property name="timeToLiveSeconds" value="3600"/>
<property name="maxEntriesLocalHeap" value="1000"/>
<property name="maxEntriesLocalDisk" value="10000000"/>
<property name="memoryStoreEvictionPolicy" value="LRU"/>
cache>
2.5 二级缓存的应用场景
对查询频率高,变化频率低的数据建议使用二级缓存。
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
2.6 mybatis局限性
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题需要在业务层根据需求对数据有针对性缓存。
3 mybatis和spring整合
3.1 mybaits和spring整合的思路
1、让spring管理SqlSessionFactory
2、让spring管理mapper对象或者是dao。
使用spring和mybatis整合开发mapper代理或原始dao接口。
自动开启事务,自动开启和关闭 sqlsession.
3、让spring管理数据源( 数据库连接池)
3.2 创建与spring整合工程

3.3 加入jar包
1、mybatis3.2.7本身的jar包
2、数据库驱动包
3、spring3.2.0
4、spring和mybatis整合包
从mybatis的官方下载spring和mybatis整合包
mybatis-spring-1.2.1.jar
3.4 log4j.properties
# Global loggingconfiguration\uff0c\u5efa\u8bae\u5f00\u53d1\u73af\u5883\u4e2d\u8981\u7528debug
log4j.rootLogger=DEBUG, stdout
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p[%t]-%m%n3.5 SqlMapconfig.xml
mybatis配置文件:别名、settings,数据源不在这里配置
3.6 applicationContext.xml
1、数据源(dbcp连接池)
2、SqlSessionFactory
3、mapper或dao
这个配置的前提条件是:映射接口类文件(.java)和映射XML文件(.xml)需要放在相同的包下(cn.itcast.mybatis.mapper)
如果myBatis映射XML文件和映射接口文件不放在同一个包下怎么办呢?
如果在不同的包下,那就需要手动配置XML文件的路径了,只需要修改SqlSessionFactoryBean配置即可:
classpath:表示在classes目录中查找;
*:通配符表示所有文件;
**:表示所有目录下;
3.7 整合开发原始dao接口
3.7.1 配置SqlSessionFactory
3.7.2 开发dao(这里直接继承了SqlSessionDaoSupport这个类,这个类会通过sqlSessionFactory初始化一个sqlsession来操作数据库)
public class UserDaoImpl extends SqlSessionDaoSupport implements UserDao{
@Override
public UserfindUserById (int id) throws Exception {
// 创建SqlSession
SqlSessionsqlSession = this.getSqlSession();
// 根据id查询用户信息
User user = sqlSession.selectOne("test.findUserById",id);
return user;
}
}3.7.3 配置dao
3.7.4 测试 dao
public class UserDaoImplTest {
private ApplicationContext applicationContext;
@Before
public voidsetUp() throws Exception {
//创建spring容器
applicationContext = new ClassPathXmlApplicationContext("spring/applicationContext.xml");
}
@Test
public void testFindUserById() throws Exception {
//从spring容器中获取UserDao这个bean
UserDao userDao = (UserDao) applicationContext.getBean("userDao");
User user = userDao.findUserById(1);
System.out.println(user);
}
}3.8 整合开发mapper代理方法
3.8.1 开发mapper.xml和mapper.java
3.8.2 使用MapperFactoryBean(基本上不使用了)
<bean id="userMapper" class="org.mybatis.spring.mapper.MapperFactoryBean">
<property name="mapperInterface"value="cn.itcast.mybatis.mapper.UserMapper"/>
<property name="sqlSessionFactory"ref="sqlSessionFactory"/>
bean>
使用此方法对于每个mapper都需要配置,比较繁琐。所以现在基本不使用这种配置,用下面的mapper扫描器
3.8.3 使用MapperScannerConfigurer
(通过源码可以发现这个扫描器做的事情非常多,首先会创建一个MapperFactoryBean,这个mapperFactoryBean继承了sqlSessionDaoSupport这个类,这个类会初始化一个sqlSession,这个sqlSession是线程安全的并由spring来管理)
使用扫描器自动扫描mapper,生成代理对象,比较方便。
3.8.4 测试mapper接口
public class UserMapperTest {
private ApplicationContext applicationContext;
@Before
public void setUp() throws Exception {
// 创建spring容器
applicationContext = new ClassPathXmlApplicationContext(
"spring/applicationContext.xml");
}
@Test
public void testFindUserById() throws Exception {
UserMapper userMapper = (UserMapper) applicationContext.getBean("userMapper");
Useruser = userMapper.findUserById(1);
System.out.println(user);
}
}