NPTL分析之线程的创建
NPTL(NativePosix Thread Library)
NPTL包括pthread线程库以及配套的同步方法,我们这里暂时只讲pthread线程库的实现。
1. NPTL的起源
在NPTL之前,linux的线程库是LinuxThreads,该库部分实现了Posixthreads的规范。其主要特点是线程的调度在用户态完成,且由一个管理线程来调度。相应的,其缺点也来自于这种架构,导致管理线程带来了很大的任务切换的开销。另外一个问题是LinuxThreads对信号的处理不满足Posixthreads的规范。
NPTL解决了LinuxThreads的问题,因此,成为了Linux上默认的线程库。
2.NPTL的实现
提到NPTL与LinuxThreads的区别,很多人会说到1:1和M:N,即用户态线程与内核态进程的比例问题。NPTL的1:1在我看来是0.5:0.5,因为用户态看到的那个线程与内核态的进程本来就是同一个进程。下图是我对NPTL线程的理解:
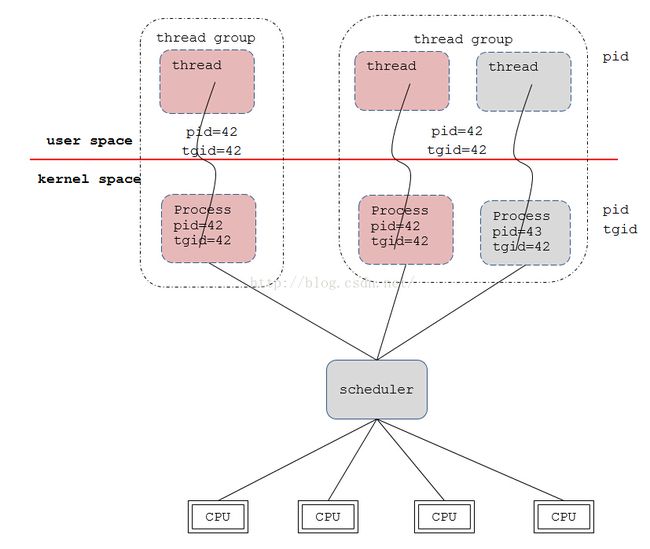
上图中,红色线以上是用户态,下面是内核态。左边虚线框内是单线程的,右边是多线程的(2个线程)。
在Linux的眼里,不会区别进程和线程,在它眼里只有task_struct。task_struct是用来描述进程(线程)的结构体,其中会记录一切关于进程的信息。内核做任务调度的时候,仅仅是选择一个task_struct而已。这个task_struct是属于进程还是线程的,内核并不关心。正因为如此,多线程下的无差别调度才能保证(所以,如果你想拖慢别人程序的速度,你可以创建大量的线程)。既然内核中线程和进程都是task_struct,那在用户态中线程的特性是如何实现的?下面将就几个例子来说明线程的特性是如何实现的。
2.1 为什么线程间可以很容易地访问全局变量,但是进程间却不行?
我们在写多线程代码时,线程间共享某些数据非常简单:弄一个全局变量即可。但是写多进程的程序时,则必须另外创建一个共享内存才能共享数据。为什么会有这样的差异?
简单地说,是因为线程的实现时线程间共享了虚拟地址空间。一般来说,每个进程都有独立的虚拟地址空间,其中包括独立的页表。那么,在一个线程组中,每个线程看到的虚拟地址对应的物理地址都是一样的。而在两个进程中,同样的虚拟地址可能就对应不同的物理地址。这就导致线程间的数据共享和进程间有很大的差别,继而导致线程间的同步方式和进程间有较大差异。
2.2 线程在内核中的数据模型
首先,看下面这个图:

不管是通过fork产生的进程还是通过pthread_create产生的线程,其在内核中都对应着一个task_struct。linux_structure图中有两个task_struct,其中右边的task_struct是通过pthread_create产生的,因此左边的task_struct是threadgroup的leader。task_struct有很多字段,其中mm就是用来描述虚拟地址空间的。我们可以看到两个task_struct的mm指向了同一个mm_struct对象,也就是前面提到的线程间共享同一个虚拟地址空间。
不仅仅是虚拟地址空间,线程间还共享信号相关的数据。比如,线程间共享相同的信号处理函数,相同的pending信号(线程也有独立的pending信号,这些信号是通过pthread_kill发送的,而不是通过kill发送的)。从图中可以看到,signal、sighand和pending字段都指向相同的对象。既然共享信号相关的数据,那么就可以解释一个问题:多线程程序中,信号是由哪个线程处理的?答案很简单:由最先从内核态返回用户态的线程处理的。信号处理会作为一个专门的技术问题在以后的技术分享中讲解。
用户态中,多线程会作为一个进程看待,在内核中,会被抽象为“线程组”。线程组中的task_struct有不同的pid字段,但是会有相同的tgid(threadgroup id)字段,这个tgid作为用户态进程的pid给上层使用。所以,在一个进程下的每个线程中获取到的pid是相同的,用户态的pid与内核态的pid不是同一个东西,想获取线程在内核态的pid可以通过系统调用(gettid)来获取。线程组中的task_struct会通过一个链表(thread_group)链接起来,后面创建的线程的task_struct中的group_leader字段会指向leader。通过共享mm_struct、fs、signal相关的数据,再通过thread_group相关的设置,线程的概念基本就实现了。
2.3 线程的创建流程,从用户态到内核
2.3.1 pthread_create
pthread_create是创建线程的入口,主要参数是一个函数指针,其指向的函数为线程创建成功后要执行的函数。由于线程组中的各个线程是可以并行运行在不同的CPU上的,所以各个线程必须得有自己独立的用户态栈和内核栈。Linux用户态栈的大小一般是8M,通过mmap在MemoryMapping Area中分配一块内存(不考虑用户态栈缓存)。在用户态也有一个数据结构用来描述线程(structpthread),该数据结构就放在用户态栈的最下面的位置,其中会存放线程创建成功后要执行的函数地址。
分配完structpthread和用户态栈之后(其实还有很多事情,不过都是些琐事),差不多就可以带着这些信息进入内核申请task_struct了。
2.3.2 syscall入口
像创建新的进程这种资源管理工作基本上都要通过内核完成,从用户态进入内核态有好几种方式,其中系统调用是主动陷入内核的一种方式。从用户态进入内核态与从内核态返回用户态,两种路径都是有标准的,由于涉及到模式的转换,所以与处理器架构有很大的关系。一般来说,从用户态进入内核态时,都会把进程在用户态时的状态保存在内核栈中,这样完成了内核态的任务之后返回时可以恢复用户态的状态。各种寄存器信息基本上就保存在内核栈的顶部的structpt_regs里面,x86_64架构下pt_regs的字段如下:

这个结构体在内核很多地方会见到,在trace系统中有重要的作用,后面会以专题的形式讲一下pt_regs的故事。
glibc在用户态对clone封装了一层,名为ARCH_CLONE。其中会把线程创建成功后要执行的函数地址以及参数压入用户态栈,然后再调用系统调用clone,这样系统调用clone返回后再从栈中取出线程函数以及对应的参数,继而开始执行线程函数。
2.3.3 clone
系统调用(syscall)clone用于创建当前进程的一个副本,fork就是调用的clone。我们这里是要创建线程,那么对clone的用法当然与fork有所区别了。区别主要在于clone的参数clone_flags的设置:
创建线程调用的clone:

创建进程调用的clone:

可以看到创建线程时使用的clone_flags中多了CLONE_VM、CLONE_FS、CLONE_FILES和CLONE_SIGNAL(CLONE_SIGHAND| CLONE_THREAD),这些是实现Posixthread规范的关键。这些参数体现在linux_structure图中就是其中的mm、fs、files、signal、sighand和pending字段指向相同的对象。正因为这些数据的共享,线程间的数据共享和同步比在进程间简单得多。
fork创建的进程是当前进程的儿子,pthread_create创建的进程则相当于当前进程的兄弟。CLONE_THREAD这个标记使得创建的进程加入当前的线程组。
clone的过程主要包括task_struct的分配以及相应的资源的拷贝,比较有条理,可以自行查看相关的代码,重点关注内核栈的建立以及内核栈与task_struct的关联关系的创建。
2.4 总结
线程在Linux内核中只是一个逻辑上的概念,并没有某个数据结构来区分进程或者线程,“线程”是一个轻量级进程,它与其它进程共享了虚拟地址空间,这一特性直接导致多线程和多进程的天壤之别。本文仅仅讲了NPTL中线程库部分(其中的线程创建部分),线程间的同步(futex)以后再讲。