一、初始化设置
1 jvm out of memory 解决方案:
在weka SimpleCLI窗口依次输入
java -Xmx 1024m
2 修改配置文件,使其支持中文:
配置文件是在Weka安装后的目录下,比如我的是在C:\Program Files\Weka-3-7\RunWeka.ini,打开这个文件,找到fileEncoding=Cp1252这一行,改成fileEncoding=utf-8即可。如下:
# The file encoding; use "utf-8" instead of "Cp1252" to display UTF-8 characters in the
# GUI, e.g., the Explorer
fileEncoding=utf-8如果是在C盘,可能会提示没有权限保存,这时可以把这个配置文件复制到桌面,修改完了再替换回去。
有些同学,改完配置文件,中文依然乱码,可能因为源文件不是utf8编码格式的,可以用notepad++把arff文件打开,然后选择格式->转为UTF-8编码格式,保存。
二、数据格式:
Weka使用的数据格式是它自己规定的,arff格式,大概就是这个样子:
@relation F__zle_study_ccf_code_Archive_text3
@attribute text string
@attribute @@class@@ {text006,text010,text013,text014,text015,text016,text020,text023,text024,text026,text100,text103,text104,text105,text106,text110,text113,text114,text115,text116,text120,text121,text122,text123,text124,text125,text126,text200,text203,text204,text205,text206,text210,text211,text212,text213,text214,text215,text216,text220,text222,text223,text224,text225,text226,text300,text302,text303,text304,text305,text306,text310,text311,text312,text313,text314,text315,text316,text320,text321,text322,text323,text324,text325,text326,text400,text403,text404,text405,text406,text410,text411,text412,text413,text414,text415,text416,text420,text421,text422,text423,text424,text425,text426,text500,text510,text511,text512,text513,text514,text515,text520,text521,text522,text523,text524,text525,text526,text600,text610,text612,text613,text614,text616,text620,text623,text624}
@data
'地图 中国 完整版 电影 秘密 官网 乔丹 2016 超载 超限 规定 最高 现在 中国 电影 超轻型',text006
'货运 远洋 秘密 版大图 世界地图 高清 顺德 版大图 高清 唐朝',text014
1 将文件转换成ARFF文件:
TextDirectoryLoader
java weka.core.converters.TextDirectoryLoader -dir text_example > text_example.arff
该方法只能通过命令行实现。如果是在windows下,要首先在环境变量里加入weka.jar的位置,再在cmd里敲入命令行。
该类的作用是把输入目录转化成ARFF文件,但是转化之后的ARFF文件里的属性是string型的,依然是大多数分类器不能处理的,需要做进一步处理。该类的作用相当于把每个文本表示一行的string格式。
输入的文件目录的格式应为图1所示:
图1 文件目录格式
一个生成图1格式的代码
import os re_base='F:\zle\study\ccf\code\Archive\dict_keywords.txt'#文件读取目录 wr_base="F:/zle/study/ccf/code/Archive/text3/text" #文件生成目录 with open(re_base,'r') as f: line=f.readlines() for x in range(107):#一共有107类 catalog=line.pop(0).split(':')[0] file_name=wr_base+str(catalog) if not os.path.exists(file_name): os.path.join(wr_base,str(catalog)) os.mkdir(file_name) else: pass with open(file_name+'/'+str(catalog)+'.txt','w') as f: f.write(line.pop(0).replace(',',' '))
2.StringToWordVector
由TextDirectoryLoader转化成的arff还不能直接用来分类,还需StringToWordVector类的进一步处理。这步在命令行和GUI上都能操作,但建议直接转到GUI上来操作更清楚、方便。
在打开的WEKA界面中选择打开已经上一步处理过的文件,然后选择StringToWordVector,该类位于weka.filters.unsupervised.attribute.StringToWordVector中,然后点击可以配置参数。这也是GUI的好处之一,可以配置更加详细的参数。
GUI步骤:
-
- 进入Weka的Explorer页面,Open file..选中这个e:/data.arff文件
-
在Filter中点击Choose
选择 weka->filters->unsupervised->attribute->StringToWordVector
点击Apply之后,Weka将自动统计词频,将词转成特征。在StringToWordVector中可以配置是否使用TFIDF特征,词频是否只使用
0,1统计(outputWordCounts=false)
参数介绍
这里简要介绍一下StringToWordVector可能需要自己做调整的参数:
-W 需要保留的单词个数,默认为1000。这不是最终的特征维数,但是维数跟此参数是正相关的
-stopwords
-tokenizer
其他参数只需默认值即可。在GUI当中,还有一些参数设置需要介绍:
lowerCaseTokens 是否区分大小写,默认为false不区分,这里一般要设置为ture,因为同一个词就会有大小写的区别
三.特征选择与训练
提取完ARFF文件之后,可以按上方的按钮保存文件。在Attribute一栏中也会显示所有的特征,此时也可以自己观察一下所提取的单词是否合理,然后再在去停词、符号等等方面做改进,当然若至于少部分的有问题,也可以手动剔除。
此步进行完之后,可以使用降维方法(例如PCA)对特征进行降维,当然这不是必须的。
接下来就可以按照一般ARFF文件进行训练了。
进入Classify面板,在Start按钮上面的下拉框中,选中(Nom)@@class@@ 这个表示分类的标签属性列
点Choose按钮选择trees中的J48,然后点击Start,Weka便开始进行训练。只要数据格式正确了,可以使用这里面的各个分类器进行训练,比如RandomForest,NaiveBayes,比较分类效果。
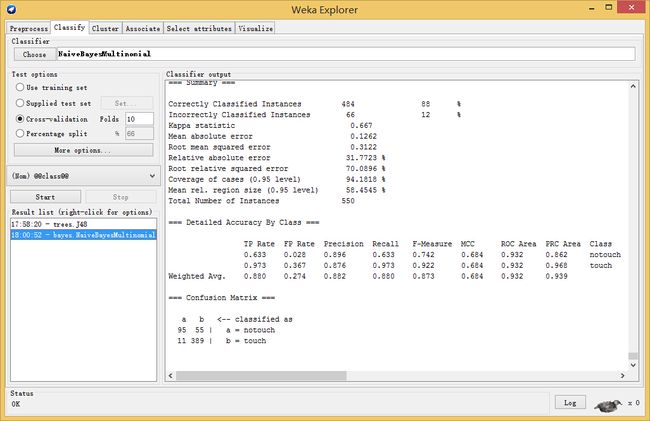
四 Weka输出结果的简单说明
=== Summary ===(总结)
Correctly Classified Instances(正确分类的实例) 45 90 %
Incorrectly Classified Instances (错误分类的实例) 5 10 %
Kappa statistic(Kappa统计量) 0.792
Mean absolute error(均值绝对误差) 0.1
Root mean squared error(均方根误差) 0.3162
Relative absolute error(相对绝对误差) 20.7954 %
Root relative squared error(相对均方根误差) 62.4666 %
Coverage of cases (0.95 level) 90 %
Mean rel. region size (0.95 level) 50 %
Total Number of Instances(实验的实例总数) 50
=== Detailed Accuracy By Class ===
TP Rate(真阳性率) FP Rate(假阳性率) Precision(查准率) Recall(查全率) F-Measure MCC(Matthews相关系数) ROC Area PRC Area Class(类别)
0.773 0 1 0.773 0.872 0.81 0.886 0.873 true
1 0.227 0.848 1 0.918 0.81 0.886 0.848 false
Weighted Avg. 0.9 0.127 0.915 0.9 0.898 0.81 0.886 0.859