spring-cloud-Hoxton.SR6 (springBoot2.2.x-2.3.x)学习篇(七)微服务保护篇(一)Hystrix
spring-cloud-Hoxton.SR6 (springBoot2.2.x-2.3.x)学习篇(七)微服务保护篇(一)Hystrix
前言…
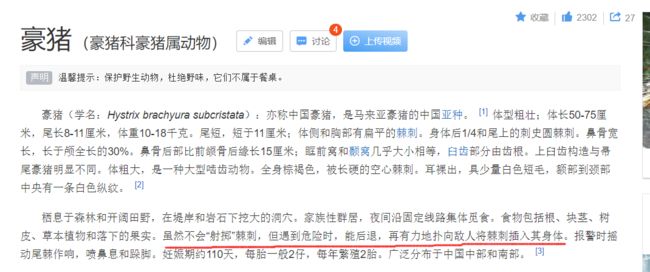
Hystrix 百度直接翻译:豪猪
就是它?萌萌哒的小动物?

对不起,上错图了,应该是它!

看它身上布满钢针的感觉是吧!有没有一点密恐?它身上的刺可是能轻易刺穿软皮肤组织的哟!
我们直接来走进科学!
我们的哺食猎人小花豹,在它面前是这样的!

今天的走进科学篇,到此打住!…
简言之:豪猪 ,其尖刺就是其防御,就是其自身保护手段!
我们今天呢,要学习的Hystrix 就是微服务的一种保护手段!而命名呢,就是以我们前边介绍的 豪猪 ,Hystrix!
写在开头!可能有初学小伙伴在百度了一下后,想发出疑问!
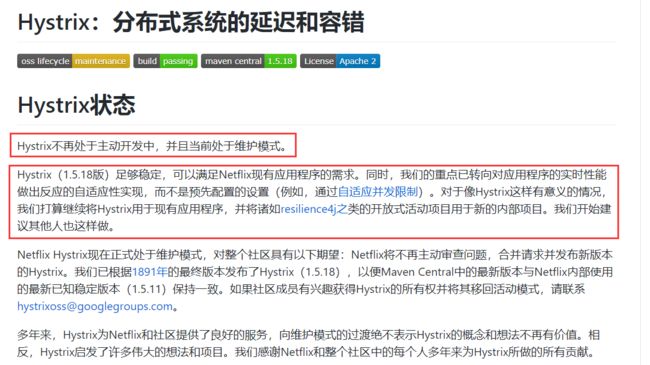
这都2020年9月了,还要学Hystrix?它停止维护了!不知道吗?

 **什么意思呢 **
**什么意思呢 **
- 停止维护了吗?
- 确实停止维护了
- 还能用吗?会有问题吗?
- 能用,问题可能会有,但是发展了这么多年,很多坑,前辈已经帮忙踩了,生产环境还是可以用的!
- 不能用的话?那前几年的老项目不是全部洗白?例如我们公司的 boot1.5.x +cloud Edgware.SR4
- Hystrix停止维护了,是否有可替代组件呢?
- 有的,例如官网推荐的Resilience4j、阿里的 Sentinel等等…
- 为什么要学习Hystrix
- 微服务服务容错保护老牌王者,市面上老cloud项目基本都在用!
- 学习其使用思路,方便其他类似组件快速上手!
在使用Hystrix前呢,我们需要先问自己一下,为什么要使用Hystrix?或者说不使用Hystrix或类似组件)有什么后果?
我们首先来了解一个微服务故障 --> 服务雪崩
一、什么是服务雪崩?
何为雪崩:小雪球,越滚越大越滚大,灾难性事故!
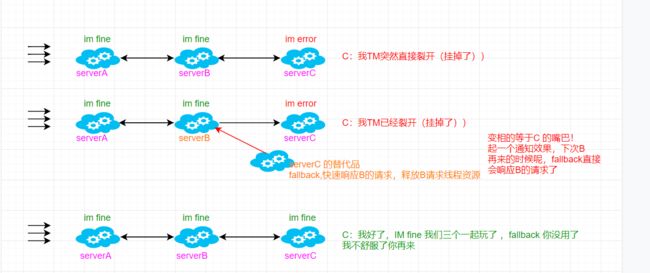
在微服务之间进行服务调用是由于某一个服务故障,导致级联服务故障(整个调用链路都不可用)的现象,称为雪崩效应。雪崩效应描述的是提供方不可用,导致消费方不可用并将不可用逐渐放大的过程。
比如,原本微服务有一条调用链路是这样的:
A---->B----->C

这个时候呢,A 服务请求流动性很大,经常不间隔性的高QPS,这个时候啊,A服务依赖于BC 即A 作为消费者服务要取拿提供者BC 给的数据,由于并发数很高,可能A服务顶住了!但是B、C 服务顶不住(可能是因为BC也正在被其他服务消费,或者BC 服务配置问题…)导致B或者C down 掉了,变为不可用!比如:现在是A、B 顶住了,C down 掉了!那么B对C 的请求将会被阻塞住,会慢慢耗尽B 服务的线程资源,渐渐导致B 不可用,A 又是在不断的请求B,慢慢的 A 对B 的请求也将会被阻塞,也会慢慢耗尽A 服务的线程资源,导致A 不可用,那么,若其他服务依赖于A提供数据,那么一连串的链路将会挂掉!
整个雪崩的过程可能是这样!

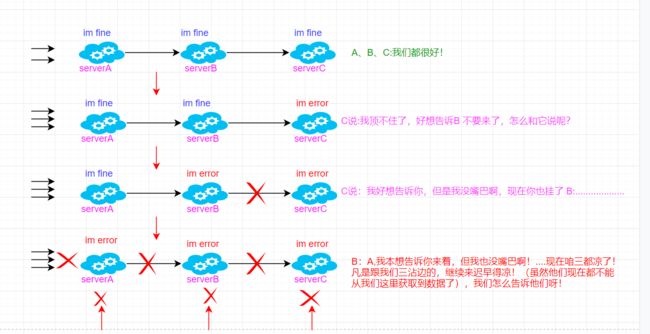
这即是服务雪崩,服务不可用越滚越大越滚越大,最后导致整个微服务所有服务均不可用!
这种情况既然有发生,那么肯定有解决措施呀!服务雪崩的解决措施就是服务熔断、服务降级!
二、什么是服务熔断?
“熔断器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控或者某个异常条件被触发,直接熔断整个服务,向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,就保证了服务调用方的线程不会被长时间占用,避免故障在分布式系统中蔓延,乃至雪崩。如果目标服务情况好转则恢复调用。服务熔断是解决服务雪崩的重要手段。
熔断图例:
三、什么是服务降级?
服务降级的话呢,我们其实在生活中已经用过了!或者说无形之中体验过了!
例如:双十一的时候,疯狂买东西没有任何问题,但是自己心血来潮的想要去差评某某店的时候(哈哈哈),发现,操作不了…恍惚之间还以为是手机卡了呢…但是自己购买东西又没有任何的问题!
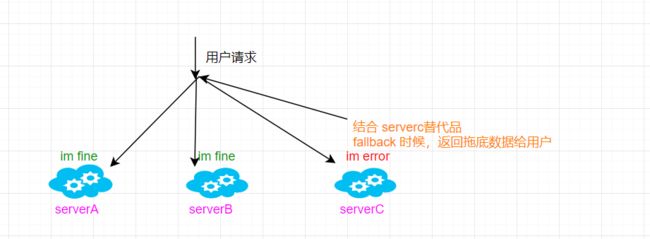
其实,这就是服务降级!双十一期间,TB 为了保证核心服务的可用性会关闭一些边缘Ob的业务(那么双十一当天,什么是核心服务呢?商品、支付、订单、库存服务吧…等等),在这个时候呢,店铺评价的功能似乎可以暂缓一下…即保证核心服务正常运行,关闭一些边缘业务(节约CPU、资源消耗、内存等)或返回一些符合用户响应但无意义的数据(拖底数据)例如:访问店铺评论------亲!评论区太火爆了趴,请稍后再试哟!
官话:
服务压力剧增的时候根据当前的业务情况及流量对一些服务和页面有策略的降级,以此环节服务器的压力,以保证核心任务的进行。同时保证部分甚至大部分任务客户能得到正确的相应。也就是当前的请求处理不了了或者出错了,给一个默认的返回。
简单来讲:为保证系统核心服务的正常运行,选择关闭系统一些中边缘服务(直接返回拖底数据),称之为服务降级!
反正是,一切为了孩子(核心业务)
图例:
粗略一讲!发现熔断与降级是差不多的,事实上也确实如此,但并不能说二者就是一个!
我们来梳理一下异同点!方便区分一下!
# 1.共同点
- 目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
# 2.异同点
- 触发原因不太一样,服务熔断一般是某个服务(多指当前调用下的服务提供者)故障引起,一般都是服务基于策略的自动触发,而服务降级一般是从整体负荷考虑(cpu、内存等)完全靠人手动升降级服务显然不可能;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(我们的降级当然会选择应用影响最小的服务入手,针对于想要保护服务来说,最为边缘OB业务的服务,例如双十一 ,应当把服务器性能以及精力放在买东西一些列的服务商,而非 评论啊,直播等等,,,)
# 3.总结
- 熔断必会触发降级,所以熔断也是降级一种,区别在于熔断是对调用链路的保护,而降级是对系统过载的一种保护处理
四、什么是HysTrix?
Hystrix简介

戳我:进入官方demo地址
戳我:进官方doc地址
在使用Hystrix组件之前呢,我们需要先了解一些概念,为什么要使用它,不使用它会出现什么问题(或者说,什么情况下产生了此组件?)
官方译文:在分布式环境中,许多服务依赖项不可避免地会失败。Hystrix是一个库,它通过添加延迟容忍和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止它们之间的级联故障以及提供后备选项来实现这一点,所有这些都可以提高系统的整体弹性。
官方原文:In a distributed environment, inevitably some of the many service dependencies will fail. Hystrix is a library that helps you control the interactions between these distributed services by adding latency tolerance and fault tolerance logic. Hystrix does this by isolating points of access between the services, stopping cascading failures across them, and providing fallback options, all of which improve your system’s overall resiliency.
简单明了就是:在分布式系统中,许多依赖不可避免的会调用失败,超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障(服务雪崩现象),提高分布式系统的弹性。
所以呢,豪猪图标作为了Hystrix的log
那么接下来呢,咱们就使用Hystrix 来进行微服务服务熔断和降级实操!
Hystrix使用
Hysyrix使用步骤,说简单的与cloud其他组件一样,大步骤,就四个
1.引入依赖
2.注解开启
3.项目配置
4.代码编写
-
熔断与降级
-
引入依赖
这个与OpenFeign一致,在客户端引入,即调用方引入!
<dependency> <groupId>org.springframework.cloudgroupId> <artifactId>spring-cloud-starter-netflix-hystrixartifactId> dependency>
-
注解开启
@SpringBootApplication @EnableDiscoveryClient @EnableFeignClients //开启hystrix断路器 @EnableCircuitBreaker public class SpringcloudOpenfeignHystrixOrderApplication { public static void main(String[] args) { SpringApplication.run(SpringcloudOpenfeignHystrixOrderApplication.class, args); } } -
说明:我们直接开始与OpenFeign整合吧
琐碎的代码我就不写了,实际工作开发,Hystrix 也是与OpenFeign 结合一起使用的!
-
Yml中 Hystrix 配置
分为两步,一步呢,是OpenFeign 开启Hystrix 支持,一步呢是Hystrix配置
feign: hystrix: #feign开启hystrix支持 enabled: true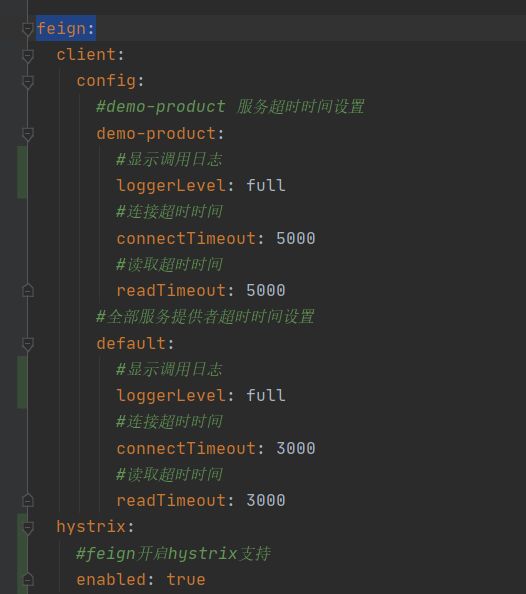
hystrix配置
hystrix: command: #default全局有效,service id指定应用有效 这个与Openfeign超时时间 日志设置等一致 default: execution: timeout: enabled: true isolation: thread: timeoutInMilliseconds: 6000 #断路器超时时间,默认1000ms
-
-
代码编写
修改原来Feign 调用配置代码,指明fallback 回调类

fallback属性说明
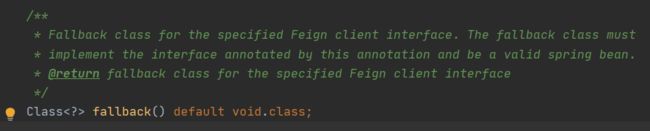
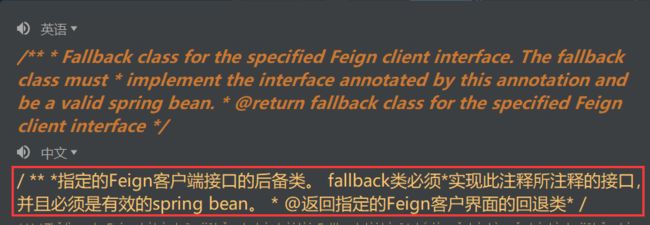
那么我们feign 客户端后备类是什么呢?实际就是若果调用服务失败后,返回给客户的备选信息(降级方法)
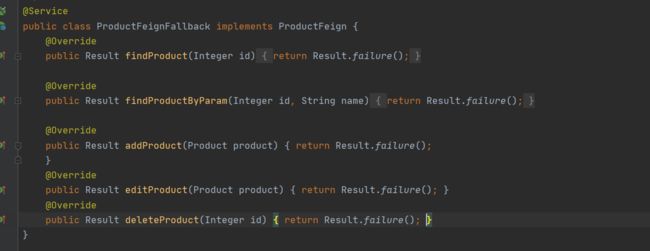
其需要交由Spring进行管理,且在Feign 客户端中指明 fallback 为该类 才能生效
例如,我这里如果调用

失败了,我就返回一个统一的无论成功还是失败均统一响应数据格式,但是返回的数据呢,又无数据敏感,仅做提示用途 (有点类似于全局异常作用)

@Service public class ProductFeignFallback implements ProductFeign { @Override public Result findProduct(Integer id) { return Result.failure("查询失败,product服务消失啦:商品Id为:"+id); } @Override public Result findProductByParam(Integer id, String name) { return Result.failure(); } @Override public Result addProduct(Product product) { return Result.failure(); } @Override public Result editProduct(Product product) { return Result.failure(); } @Override public Result deleteProduct(Integer id) { return Result.failure(); } }
需要注意的是呢,Hystrix 返回值必须与被调用者(服务提供者)返回值类型一致
-
测试
首先,我们来正常访问,此时product两个服务都很正常

我们再来关闭一台product服务
由于feign在上一篇设置了随机调用,所以此前正常请求会随机调用到product1、product2 服务中,但此时关闭了一台,仅仅只是一台服务器不可用,也仅仅无了feign随机调用服务端的效果而已,且feign 也不会在调到product2了,每次处理order请求的则只有Product1了,但product1为正常服务,所以呢,仍是无法检测到Hystrix功能正常性的!
于是,我们在关闭product1
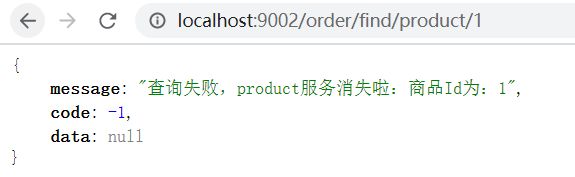
发现其快速的进入了熔断方法,不会因为product 服务不可用而一直在那里等待
如果调用某某服务只是一个最开始发起调用接口的其中一环,则可根据Hystrix 返回对象code 判断是否还要进行下一步操作,还是直接抛出异常,终止该请求了!
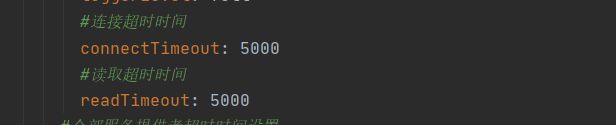
我们上方hystrix配置了超时时间,opeifeign 调用又配置了超时时间,两者是否有冲突呢?若有冲突,那么超时时间是以什么为准呢?
我们首先修改hystrix 超时时间为3000ms ,如果不设置则默认只有一秒

已知上文中openfeign超时时间设置为5秒
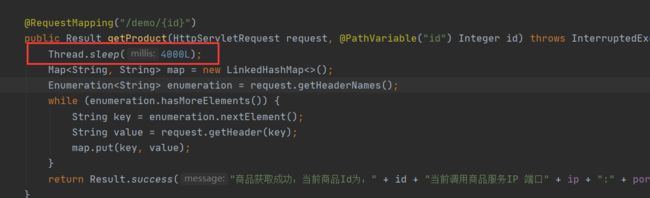
然后再修改product 接口 ,添加线程休眠时间,休眠四秒
ok,可以测试了
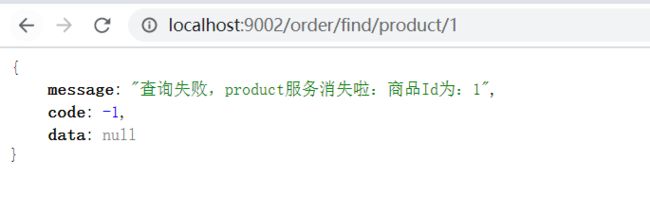
发现请求等待几秒后进入了熔断,但实际上,服务是调用成功了…因为呢,请求已经是进入了服务提供者端,但是服务提供者线程休眠了四秒,未及时返回数据(线程休眠时间为4秒,整个调用服务提供者,服务提供者返回数据时间大于了Hystrix超时时间)…
我们再修改hystrix 超时间为5秒!与OpenFeign 一致试一试!
发现一段时间后,仍是返回了正确响应

综上: hystrix 就像是一个保护开关,他设置了你三秒给我响应,但是你拖拖拉拉,四秒给我??不好意思,我直接半路拦截给你卡掉,我直接通知消费者,调用你失败了,你做的努力,白费了。。。。。
所以呢,当OpenFeign 调用服务超时时间设置后,与Hystrix 超时时间设置后,实际接口超时时间以Hystrix 为准!
即,Openfeign超时时间,Hystrix 超时时间一同设置,则调用该服务的超时时间以Hystrix 为准!!!
即,Openfeign超时时间,Hystrix 超时时间一同设置,则调用该服务的超时时间以Hystrix 为准!!!
即,Openfeign超时时间,Hystrix 超时时间一同设置,则调用该服务的超时时间以Hystrix 为准!!!
那么,在实际开发中,如果使用了Hystrix与Openfeign的话呢,Hystrix 超时时间一定是要大于等于Openfeign时间的,否则接口正常调用,但是数据返回的是Hystrix拖底数据,造成后续接口一些列错误操作!!!
那么 hystrix的使用篇就到这里结束了!!
项目源码:springcloud-openfeign-hystrix
下一篇学习:微服务保护者(二)微服务网关