数据挖掘开源软件:WEKA基础操作
数据挖掘开源软件:WEKA基础教程
本文档部分来自于网络,随着自己的深入学习,讲不断的修订和完善。
第一节 Weka简介:
Weka是由新西兰怀卡托大学开发的智能分析系统(Waikato Environment for Knowledge Analysis) 。在怀卡托大学
以外的地方,Weka通常按谐音念成Mecca,是一种现今仅存活于新西兰岛的,健壮的棕色鸟, 非常害羞,好奇心很强,但不会飞 。
Weka是用Java写成的,它可以运行于几乎所有的操作平台,包括Linux,Windows等操作系统。
Weka平台提供一个统一界面,汇集了当今最经典的机器学习算法及数据预处理工具。做为知识获取的完整系统,
包括了数据输入、预处理、知识获取、模式评估等环节,以及对数据及学习结果的可视化操作。并且可以通过对不同
的学习方法所得出的结果进行比较,找出解决当前问题的最佳算法。
Weka提供了许多用于数据可视化及预处理的工具(也称作过滤器),包括种类繁多的用于数据集转换的工具等。所有机器学习算法对输入数据都要求其采用ARFF格式。 Weka作为一个公开的知识过去的工作平台,集合了大量能承担数据(知识)挖掘任务的机器学习算法,包括分类,回归、聚类、关联规则等。
Weka与许多数据分析软件一样,Weka所处理的数据集是一个二维的表格.
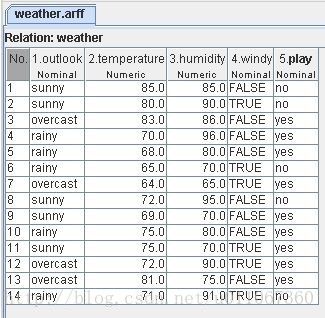
下面代码所示的二维表格存储在如下的ARFF文件中。这也就是Weka自带的“weather.arff”文件,在Weka安装目录的“data”子目录下可以找到。
@relation weather
@attribute outlook {sunny, overcast, rainy}
@attribute temperature numeric
@attribute humidity numeric
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,85,85,FALSE,no
sunny,80,90,TRUE,no
overcast,83,86,FALSE,yes
rainy,70,96,FALSE,yes
rainy,68,80,FALSE,yes
rainy,65,70,TRUE,no
overcast,64,65,TRUE,yes
sunny,72,95,FALSE,no
sunny,69,70,FALSE,yes
rainy,75,80,FALSE,yes
sunny,75,70,TRUE,yes
overcast,72,90,TRUE,yes
overcast,81,75,FALSE,yes
rainy,71,91,TRUE,no
Weka中的属性介绍:
数据集中的每一个属性都有它对应的“@attribute”语句,来定义它的属性名称和数据类型。
Weka支持的有四种,分别是
numeric-------------------------数值型
nominal-specification-----------分类(nominal)型
string----------------------------字符串型
date[]--------日期和时间型
数值属性:是整数或者实数,但Weka把它们都当作实数看待。
字符串属性:可以包含任意的文本。这种类型的属性在文本挖掘中非常有用。如:@ATTRIBUTE LC string
分类属性:由列出所有可能的类别名称并放在花括号中,如:
@attribute outlook {sunny, overcast, rainy} 。每个实例对应的“outlook”值必是这三者之一。
日期和时间属性:统一用“date”类型表示,它的格式是:@attribute date [] 其中是这个属性的名称,是一个字符
串,来规定该怎样解析和显示日期或时间的格式,
默认的字符串是ISO-8601所给的日期时间组合格式“yyyy-mm-dd hh:mm:ss”。
数据信息部分表达日期的字符串必须符合声明中规定的格式要求。
“Exploer”界面:
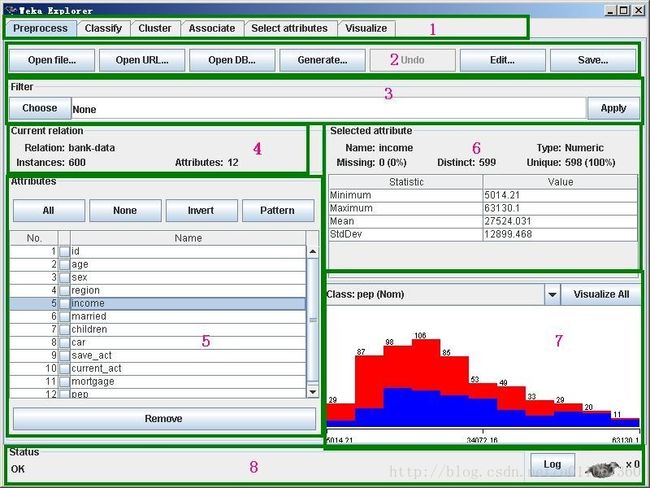
我们根据不同的功能把这个界面分成8个区域。
区域1的几个选项卡是用来切换不同的挖掘任务面板。这一节用到的只有“Preprocess”,其他面板的功能将在以后介绍。
区域2是一些常用按钮。包括打开数据,保存及编辑功能。我们在这里把"bank-data.csv"另存为"bank-data.arff"。
在区域3中“Choose”某个“Filter”,可以实现筛选数据或者对数据进行某种变换。数据预处理主要就利用它来实现。
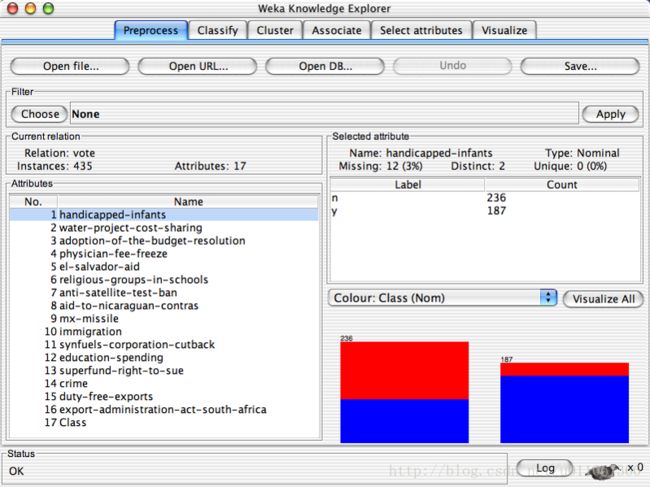
区域4展示了数据集的一些基本情况。
区域5中列出了数据集的所有属性。勾选一些属性并“Remove”就可以删除它们,删除后还可以利用区域2的“Undo”按钮找回。区域5上方的一排按钮是用来实现快速勾选的。
在区域5中选中某个属性,则区域6中有关于这个属性的摘要。注意对于数值属性和分类属性,摘要的方式是不一样的。图中显示的是对数值属性“income”的摘要。
区域7是区域5中选中属性的直方图。若数据集的最后一个属性(我们说过这是分类或回归任务的默认目标变量)是分类变量(这里的“pep”正好是),直方图中的每个长方形就会按照该变量的比例分成不同颜色的段。要想换个分段的依据,在区域7上方的下拉框中选个不同的分类属性就可以了。下拉框里选上“No Class”或者一个数值属性会变成黑白的直方图。
区域8是状态栏,可以查看Log以判断是否有错。右边的weka鸟在动的话说明WEKA正在执行挖掘任务。右键点击状态栏还可以执行JAVA内存的垃圾回收。
接下来在简单的看看窗口的其他几个标签菜单
Explorer: building “classifiers”:
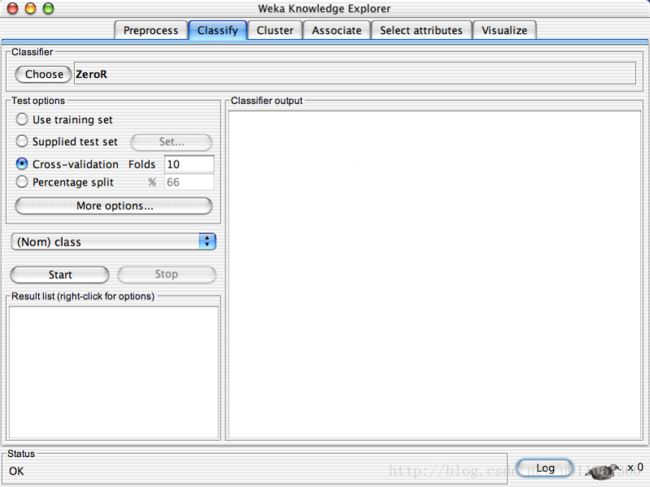



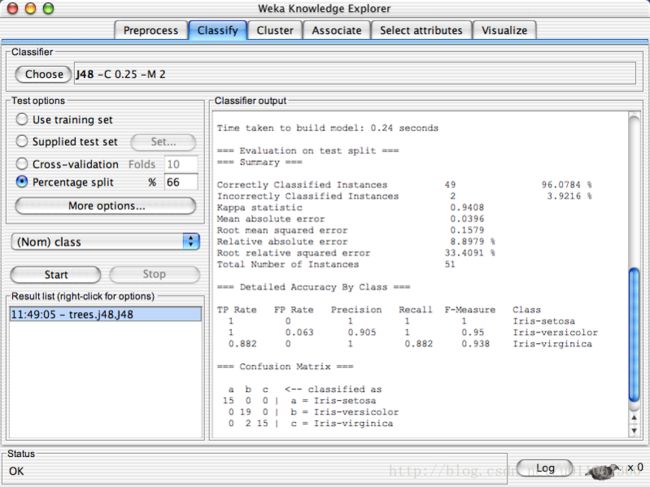
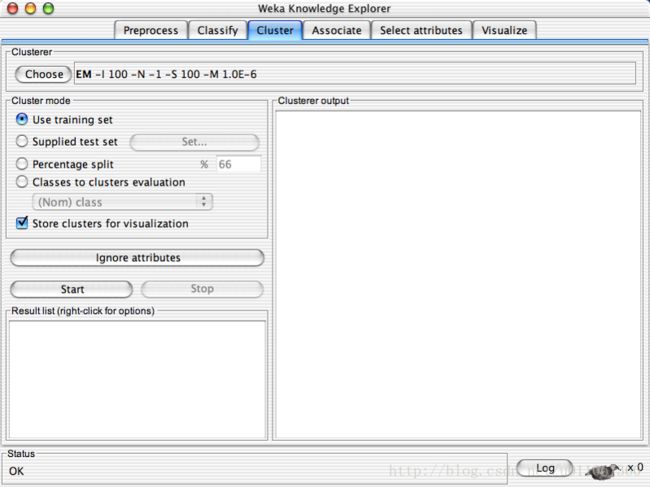
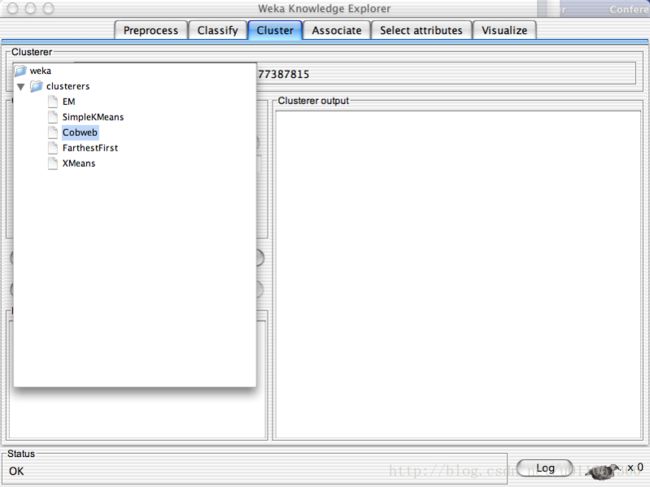
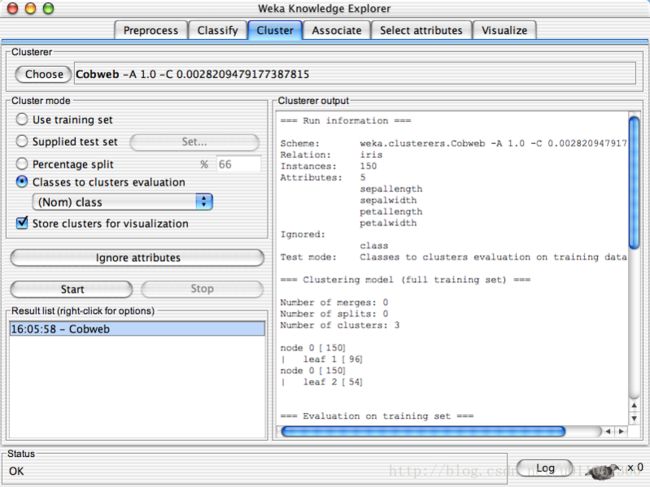
Explorer: clustering data:

Explorer: finding associations:


Explorer: attribute selection:
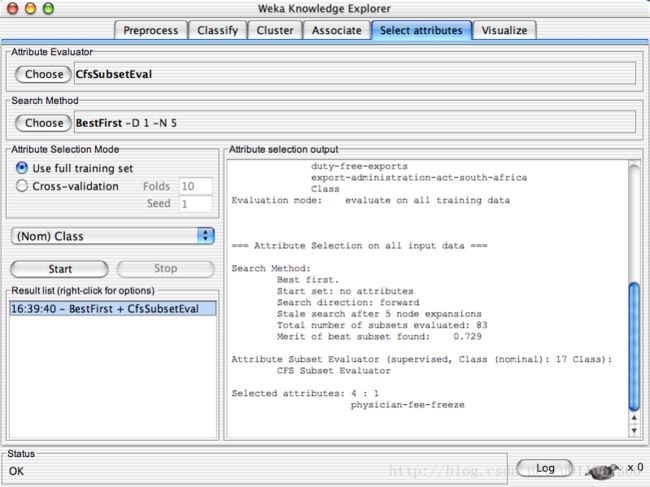





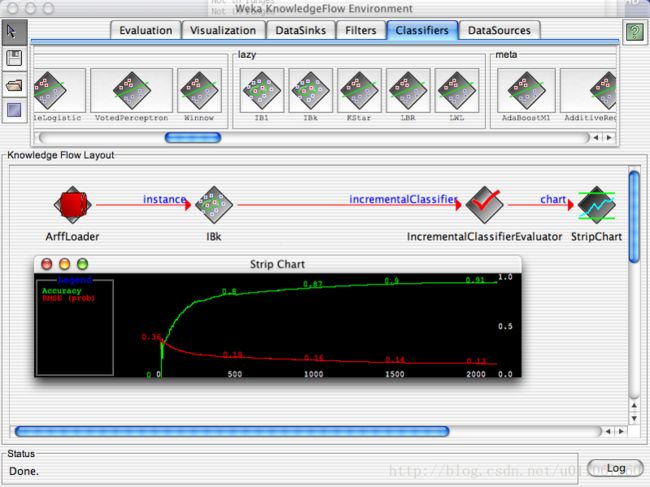
“data source” -> “filter” ->“classifier” -> “evaluator”
Layoutscan be saved and loaded again later