Hessian庖丁解牛
1、Hessian入门
Hessian是一种binary-rpc。性能较高。主要使用在交互数据较小的场景中。hessian的数据交互基于http协议,通常hessian的server端设计须要使用到web server容器(比方servlet等)。使用也是很简单,只需要暴露方法给server,client就可以像调用本地方法一下调用暴露的远程方法。
示例demo如下:
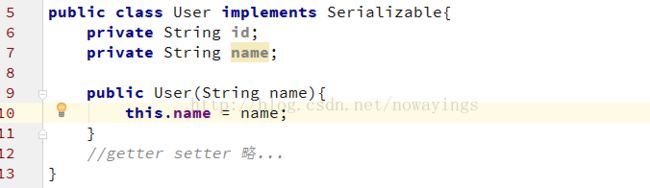
(1)提供一个服务接口来给客户端调用

User类
(2)IServer的具体实现类
(3)web.xml配置

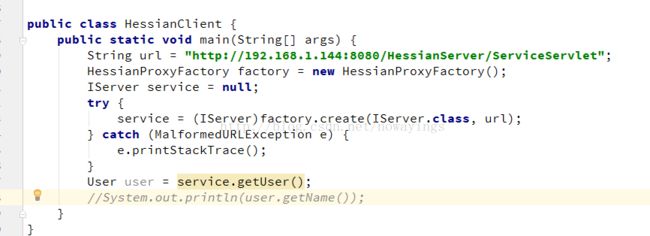
(4)客户端调用
2、Hesian基本原理
(1)客户端发起请求
Hessian的远程调用过程,客户端主要是通过 HessianProxyFactory 的 create 方法就是创建接口的代理类,该类实现了接口, JDK 的 proxy 类会自动用 InvocationHandler 的实现类—— HessianProxy 的 invoke 方法体来填充所生成代理类的方法体。
public Object create(Class api, URL url, ClassLoader loader){
if (api == null)
throw new NullPointerException("api must not be null for HessianProxyFactory.create()");
InvocationHandler handler = null;
handler = new HessianProxy(url, this, api);
return Proxy.newProxyInstance(loader,
new Class[] { api,HessianRemoteObject.class },
handler);
}
那么在客户端调用Hessian服务时候
public Object invoke(Object proxy, Method method, Object []args){
String methodName = method.getName(); // 取得方法名
Object value = args[0]; // 取得传入参数
conn = sendRequest(mangleName, args) ; // 通过该方法和服务器端取得连接
httpConn = (HttpURLConnection) conn;
code = httpConn.getResponseCode(); // 发出请求
// 等待服务器端返回相应…………
is = conn.getInputStream();
Object value = in.readObject(method.getReturnType()); // 取得返回值
}
(2)服务器端接收请求并处理请求
服务器端截获相应请求交给:HessianServiceExporter这个类,这个类的doc文档说明如下:
/**
* Servlet-API-based HTTP request handler that exports the specified service bean
* as Hessian service endpoint, accessible via a Hessian proxy.
**/
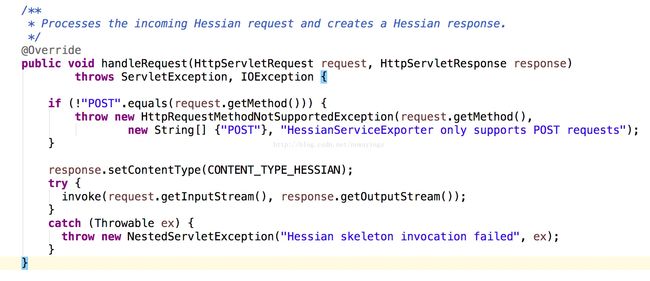
开始判断是否是POST请求。然后调用invoke方法:

其中doInvoke里面主要:将输入输出封转化为转化为 Hessian 特有的 Hessian2Input 和 Hessian2Output
然后跳转到:
public void invoke(Object service, AbstractHessianInput in, AbstractHessianOutput out) throws Exception{
ServiceContext context = ServiceContext.getContext();
// 读取方法名
String methodName = in.readMethod();
Method method = getMethod(methodName + "__" + argLength);
//读取方法参数
Class []args = method.getParameterTypes();
//执行相应方法并取得结果
try {
result = method.invoke(service, values);
} catch (Exception e) {
}
}
3、Hessian的序列化和反序列化
Hessian框架提供的序列化方式,在性能上优于java本身的序列化方式。他将对象序列化之后,生成的字节数组的数量要相对于Java自带的序列化方式要更简洁。
有人做过测试:一个UserData类,有一个字符串属性,一个日期属性,一个double属性,分别用java,hessian来序列化一百万次,结果让人吃,,不止是hessian序列化的速度要比java的快上一倍,而且hessian序列化后的字节数也要比java的少一倍。这要归功于它的序列化的实现机制。我们看一下它是如何来实现它的序列化的。
com.caucho.hessian.io这个包是hessian实现序列化与反序列化的核心包。它有如下几个核心类:AbstractSerializerFactory,AbstractHessianOutput,AbstractSerializer,AbstractHessianInput,AbstractDeserializer是hessian实现序列化和反序列化的核心结构代码
(1)AbstractSerializerFactory——一个抽象类,主要定义有序列化和反序列化抽象方法。

其中getSerializer和getDeserializer根据传入的参数类来决定使用哪种序列化和反序列化工具。
核心实现是:SerializerFactory继承AbstractSerializerFactory,而且在SerializerFactory有很多静态map用来存放类与序列化和反序列化工具类的映射,这样如果已经用过的序列化工具就可以直接拿出来用,不必再重新实例化工具类。 这就是hessian比java序列化性能高的原因。
2个静态大Map定义如下:
private static HashMap _staticSerializerMap;
private static HashMap _staticDeserializerMap;
然后它有一个addBasic函数用来给Map中存放需要序列化的类

然后把序列化后的对象在放入一个最终HashMap中。
private ConcurrentHashMap _cachedSerializerMap; //最终的HashMap
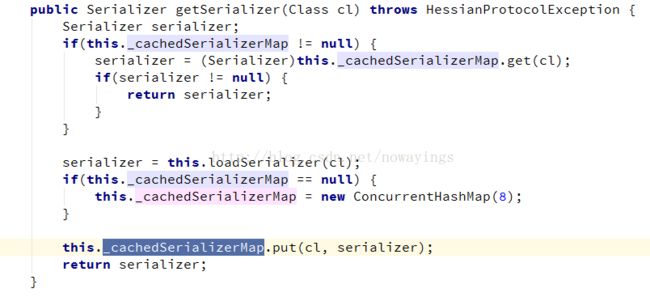
this.loadSerializer(cl)是序列化的具体实现。根据不同的需要被序列化的类来获得不同的序列化工具,数了一下,一共有17种序列化工具,hessian为不同的类型的java对象实现了不同的序列化工具,默认的序列化工具是JavaSerializer 。查看源码就很清楚了。
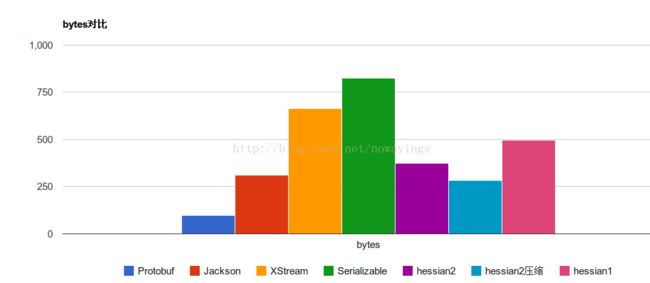
hessian序列化机制的性能比较:网上收集,没有实际测过
序列化数据对比:
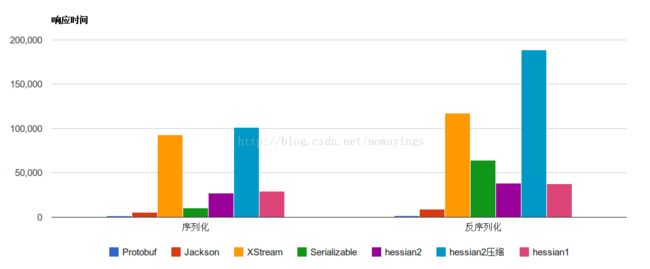
bytes字节数对比