MySQL总结(四)——UNDO LOG REDO LOG 详解
本节我们介绍下实现mysql可靠性的两个重要log undo redo log。还是先抛几个问题大家思考思考
一、问题
1.事务回滚怎么实现?
2.RC RR级别可见性是怎么实现的?
3.undo redo log 在哪里保存?空间多大?
4.redo log在容灾时起到什么作用?
二、undo log
2.1 先举栗
select * from t1 where id = 1234; 快照一
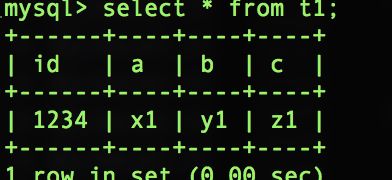
start transaction;
udpate t1 set a = "x2" where id = 1234;快照二
rollback; 快照三
2.2 B-tree数据结构分析
快照一

快照二
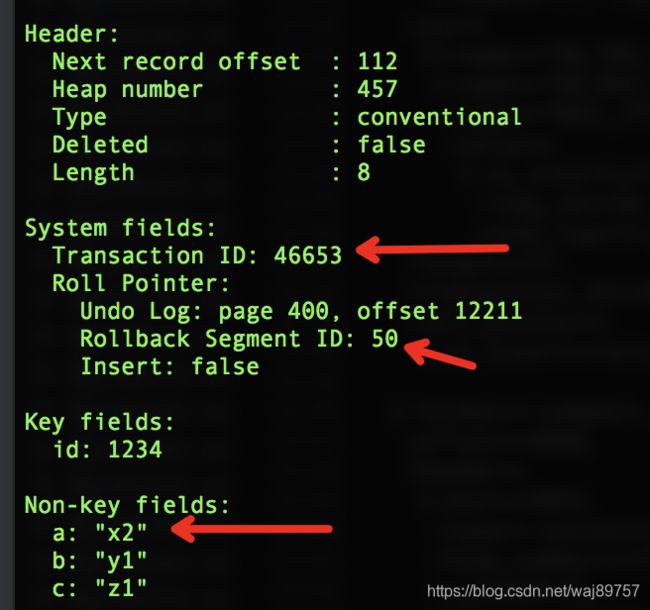
快照三
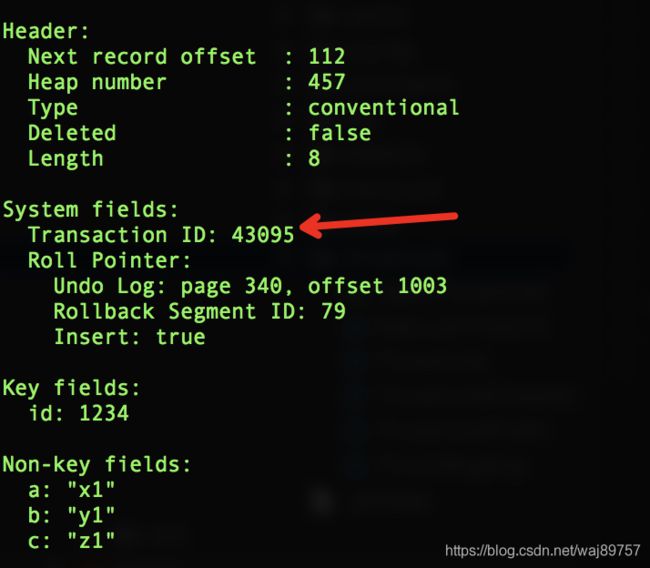
2.3 回滚原理
B-tree的叶节点数据结构会存一个Roll Pointer,就是专门用来回滚的。undo log字段表示回滚内容存在的数据段。当开启事务(如快照二) B-tree node会被覆盖,事务id是当前事务,undo log更新,record会保存(x1, x1,z1)这条数据。
rollback执行时,session的TID是43095,根据tid找到修改的记录读取RollPointer里undo log节点数据,覆盖掉B-tree Node 同时这个数据从undo log链表剔除。
2.4 可见性原理
undo log也是实现可见性的关键之一。快照二 该数据对其他事务查询依然不可见,怎么实现的呢? 通过MVCC+ReadView方式
ReadView:保存了活跃事务的TID集合,并且事务ID是自增的。RR级别下每开启一个事务都会更新当前活跃事务TID到集合里,RC级别下每开始一个SQL语句,都会更新当前活跃事务TID到集合里。
例如:
事务A(TID:46653)会加入到ReadView这个集合里 [46653]
事务B 在此时执行 select * from id = 1234 返回 (x1,x1,z1)
mysql查btree发现ROW_TID=46653
ROW_TID >=ReadView集合[46653] 说明这条记录的事务还没有提交 RR级别下不可见
查RollPointer 从undo log链表获取第一条记录,ROW_TID = 40395 <= [46653] 可见 则返回
小结:
BTree Row节点只会存最新的记录 旧的记录会存在undo log这个链表里。事务查数据先查btree节点 然后走链表。数据结构如下图
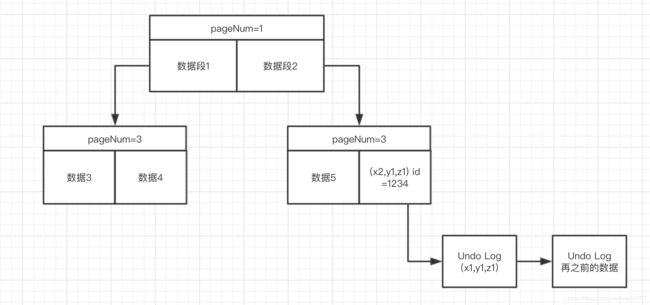
2.5 undo log 日志存储结构
undo log日志是无限大吗?不是的。默认存在ibdata1文件里(和数据行在一个文件),由于undo log时效性很短,大部分旧数据不会读,ibdata有不会自动回收,会导致文件膨胀很快,所以5.7后把undo log 分离并支持在线回收。
数据结构可以想象为Java中的HashMap 数组+链表。 一共128个段,每个段里多个slot,一个row数据放到一个slot里。

三、redo log
3.1 LSN
LSN: log sequence number 8个字节。这玩意是数据行的唯一标示 自增的,b-tree redo-log binlog都会记录,目的之一就是为了校准数据。
mysql> show engine innodb status
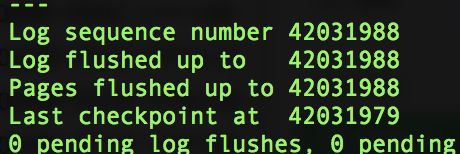
log sequence number就是当前的redo log(in buffer)中的lsn;
log flushed up to是刷到redo log file on disk中的lsn;
pages flushed up to是已经刷到磁盘数据页上的LSN;
从顺序上可以看出来 先写redo log lsn 再写数据页上。业内常用的可靠性手段——Write-ahead logging
3.2 事务提交流程
commit执行步骤
1.写binlog
2.写redo log
3.更新 readview undo log状态 释放各种锁
完成后 事务提交结束 数据才可见。
3.3 举栗分析
假设LSN = 100
msql> start transaction;
msql> udpate t1 set a = "x2" where id = 1234; //数据页b-tree node LSN =101
时间点1
msql> commit; 时间点2 //redo log LSN = 101 但此时尚未进行事务后续操作
时间点1 crash recover (MySQL重启后先扫描redo log 做恢复工作)
发现 redo log LSN=100 数据页LSN = 101 则需要回滚 101的事务,从RollPointer找到LSN <=100的数据覆盖。
时间点2 crash recover
发现 redo log LSN=101,把LSN=101的事务进行commit,更新readview undo log,数据可见。
小结:
redo log 在recover时候使用,根据log日志来修正数据页数据 保证一致性。
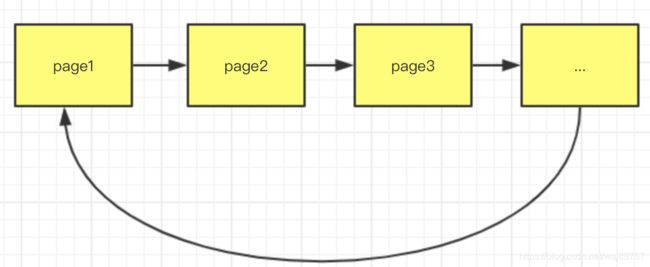
3.4 redo log存储结构 (详细结构: https://yq.aliyun.com/articles/213661)
存储数据格式和数据页一样,只会存最近的数据。环形链表结构,写满了直接覆盖。
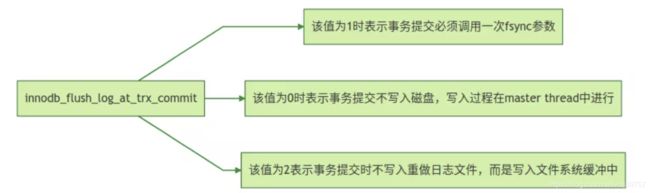
3.5 写文件还是写缓存
文件系统经典场景之一 缓存和磁盘策略。
不管是 b-tree数据页还是redo log 都有缓存和落盘的策略。不管才有那种形式,recover时都以redo log来校准,最坏策略在batch_insert下 BufferPool都会丢失,redo log很可能是比较早的数据点。
性能和可靠性 需要业务来取舍。
四、总结
1.事务回滚怎么实现?
依赖undo log 根据事务ID进行数据修正
2.RC RR级别可见性是怎么实现的?
依赖ReadView 根据事务ID 通过数据页和undo log来取数据
3.undo redo log 在哪里保存?空间多大?
存在类似ibdata文件里;undo log会定期回收,redo log是循环链表
4.redo log在容灾时起到什么作用?
依据WAL策略,根据log日志来修正数据页