基于Python实现的Elasticsearch批量操作客户端
by:授客 QQ:1033553122
1. 代码用途 1
2. 测试环境 1
3. 使用方法 1
3.1 配置ES服务器信息 1
3.2 配置ES操作数据 2
3.2.1 批量插入数据 2
3.2.2批量更新文档字段值|新增字段值 4
3.2.3 批量删除 7
3.2.4 批量去除冗余(重复)的数据 8
3.2.5 批量复制数据 9
3.3 运行程序 10
1.代码用途
Elasticsearch客户端,目的在于实现批量操作,如下:
<1> 批量插入数据
<2> 批量更新文档字段值
<3> 批量新增文档字段值
<4> 批量删除数据
<5> 批量复制数据
<6> 批量去除冗余数据
2.测试环境
Win7 64位
Python 3.3.2
Win elasticsearch-5.4.1
chardet-2.3.0
下载地址1:https://pypi.python.org/pypi/chardet/
下载地址2:http://pan.baidu.com/s/1nu7XzjN
3.使用方法
3.1 配置ES服务器信息
编辑配置文件conf/hostconfig
[DESTHOSTCONFIG]
host = 127.0.0.1
port = 9200
protocol = http
[SRCHOSTCONFIG]
host = 127.0.0.1
port = 9200
protocol = http
[README]
host = Elasticsearch所在服务器IP地址
port = Elasticsearch访问端口
protocol = 暂且固定为http
说明:
[DESTHOSTCONFIG]: 该节点下配置需要执行批量插入,批量更新文档,批量删除,批量复制时的ES主机信息
[SRCHOSTCONFIG]:该节点下配置需要复制ES数据的数据源主机信息,即从该节点下的ES主机复制到[DESTHOSTCONFIG]下的主机,两者可以是同一台主机
host = Elasticsearch所在服务器IP地址
port = Elasticsearch访问端口
protocol = 暂且固定为http
3.2 配置ES操作数据
3.2.1 批量插入数据
编辑配置文件conf/runconfig.txt
[RUNCONFIG]
runtimes = 1
说明:
runtimes = 执行批量插入时,每组数据会被重复执行的次数,总插入记录数=runtimes x 数据组数
编辑配置文件conf/esdataconfig_insertdata.txt
[INSERTDATA]
index= business_chance
type = customer_num1
{
"group_customer_code": "1",
"second_class": "服装||手机||水果",
"customer_num": 100||200||300,
"province": "广东省||福建省||云南省",
"branch": "品牌1||品牌2"
}
end
{
"group_customer_code": "2",
"second_class": "服装",
"customer_num": 400,
"province": "广东省",
"branch": "品牌3"
}
end
type = customer_num2
{
"group_customer_code": "1",
"second_class": "服装",
"customer_num": 600,
"province": "广东省",
"branch": "品牌",
"rank":1
}
end
index= business_index
type = customer_type
{
"group_customer_code": "1",
"second_class": "服装",
"customer_num": 600,
"province": "广东省",
"branch": "品牌2",
"rank":1
}
end
说明:
[INSERTDATA] ------------->固定值
index= 索引名称,不能为空
type = 类型名称,不可为空
{
"group_customer_code": "1",
"second_class": "服装||手机||水果",
"customer_num": 100||200||300,
"province": "广东省||福建省||云南省",
"branch": "品牌1||品牌2"
}
end
需要提交的一组数据,没组数据遵守json格式,后面一定要跟“end” 表示数据范围结束
"second_class": "服装||手机||水果",
1)如果有多个参数值,以 || 分隔,运行时程序随机选取一个
2)参数值如果是字符串类型,加以英文双引号",否则不加双引号
从上往下,
1)如果已填写index,需要切换文档类型,可直接另起一行,如下
type = customer_num2
表示接下来的数据组插入到该文档类型,直到遇到其它索引、文档类型
2)如果需要提交到其它新的索引,可直接另起一行,填写新的索引和类型,如下
index= business_index
type = customer_type
表示接下来的数据组插入到新索引名称下的新索引类型中
3.2.2批量更新文档字段值|新增字段值
编辑配置文件conf/esdataconfig_updatefield.txt
[UPDATEFIELD]
index=business_chance
type = customer_num1
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
},"size":150
}
end
{
"branch": "品牌99||品牌66",
"customer_num": 900||888
}
end
type = customer_num2
查询=
{
"query": {
"match_all": {}
},
"size": 100
}
end
{
"branch": "品牌999",
"customer_num": 990
}
end
index= business_index
type = customer_type
查询=
{
"query": {
"match_all": {}
},
"size": 100
}
end
{
"branch": "品牌666",
"customer_num": 666
}
end
说明:
[UPDATEFIELD] ------------>固定值
index= 需要更新记录所在索引名称,不可为空
type = 需要更新记录所在文档类型,不可为空
查询={……} 仅更新满足查询条件的结果,不可为空
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
},
"size":150
}
end
这里的逻辑是这样的:先“查询”,再对查询出来的每条记录进行更新
注意:
不使用size参数的话,ES默认仅仅会返回10条记录,程序仅会对返回的记录数进行更新,所以,如果需要更新的记录数大于10条,需要通过"size"参数,显示控制ES返回的记录数,比如“需要更新的记录数有150条,则size的值要设置大于等于150”(下同,不在赘述)
参数数据组
{
"branch": "品牌99||品牌66",
"customer_num": 900||888
}
end
同批量插入
1)如果有多个参数值,以 || 分隔,运行时程序随机选取一个
2)参数值如果是字符串类型,加以英文双引号",否则不加双引号
从上往下,
1)如果已填写index,需要切换文档类型,可直接另起一行,如下
type = customer_num2
表示接下来的数据组更新,只更新归属该文档类型的记录,直到遇到其它索引、文档类型
3)如果需要更新归属其它新索引的记录,可直接另起一行,填写新的索引和类型,如下
index= business_index
type = customer_type
表示接下来的数据组只更新新索引名称下的新索引类型中的记录,直到遇到其它索引、文档类型
同批量插入,查询,参数数据组,都必须跟 end,表示数据范围结束
另外,需要注意的是:“查询”,必须位于参数数组上方,索引类型下方
批量新增文档字段:如果填写的字段不存在,则会新增字段及对应值
3.2.3 批量删除
编辑配置文件conf/esdataconfig_deletedata.txt
[DELETEDATA]
index= business_chance
type = customer_num1
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
}
}
end
index= business_index
type = customer_type
{
"query": {
"match_phrase": {
"province": "广东省"
}
}
}
end
说明:
[DELETEDATA] --------固定值
index= 要删除记录所在索引
type = 要删除记录所在类型
查询={……} 仅更新满足查询条件的结果,不可为空
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
}
}
end
这里的逻辑是这样的:如先“查询”,再对查询出来的每条记录(ES实际返回的记录)进行删除
其它说明同上
3.2.4 批量去除冗余(重复)的数据
编辑配置文件conf/esdataconfig_deduplicatedata.txt
[DEDUPLICATEDATA]
index= business_index
type = customer_num2
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
},
"size":100
}
end
type = customer_type
查询=
{
"query": {
"match_all": {}
},
"size": 100
}
end
index= business_chance
type = customer_num1
查询=
{
"query": {
"match_all": {}
},
"size": 100
}
end
注意:
这里的查询不能为空,一定要填写
这里的实现逻辑是这样的:先查询,然后删除查询出来的全部记录,最后再把不重复的记录写回到ES中。
其它说明同上
3.2.5 批量复制数据
编辑配置文件conf/esdataconfig_copydata.txt
[COPYDATA]
index= business_chance
type = customer_num1
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
}
}
end
type = customer_num2
查询=
{
"query": {
"match_phrase": {
"province": "广东省"
}
}
}
end
格式基本同上述的批量更新文档的配置,多少有点不一样,需要注意如下:
1) 这里的index,type分别为数据源所在的索引和类型,即需要从该索引和类型中复制数据到目标索引和类型,不能为空
index= business_chance
type = customer_num1
2)条件= 配置需要“复制数据到”的目标索引,和目标类型,如下,以逗号分隔,一个条件仅仅支持一个目标index和type
条件 = index = business_index , type = customer_num2
end
条件和查询都不能为空。
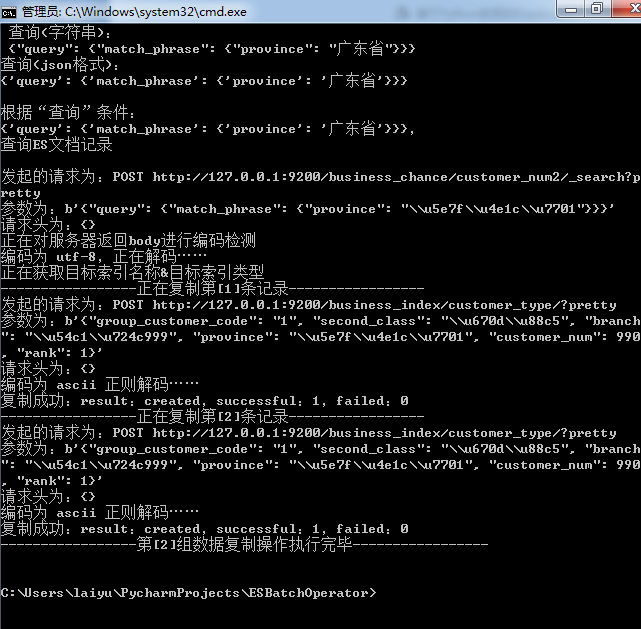
这里的实现逻辑是这样的:对数据源所在的index, type通过“查询”得到要复制的数据,然后根据“条件”设置的目标索引和类型名,复制到对应目标主机上的目标索引,目标类型中。
说明:重复复制,会生成重复数据
如果觉得麻烦,以上几个数据配置的内容,可以写在一个文件里,但是必须按格式填写
3.3 运行程序
cmd进入ESBatchOperator根目录(main.py所在目录)
python main.py
按提示,输入数字编号 1、2、3、4、5,回车运行

源码下载地址:基于Python实现的Elasticsearch批量操作客户端