Pytorch——计算机视觉工具包:torchvision
Pytorch——计算机视觉工具包:torchvision
torchvision独立于Pytorch,需通过pip install torchvision 安装。
torchvision 主要包含以下三部分:
- models : 提供深度学习中各种经典的网络结构以及训练好的模型,包括Alex Net, VGG系列、ResNet系列、Inception系列等;
- datasets:提供常用的数据集加载,设计上都是继承torch.utils.data.Dataset,主要包括MMIST、CIFAR10/100、ImageNet、COCO等;
- transforms: 提供常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
1.models
from torchvision import models
from torch import nn
#加载预训练好的模型,如果不存在会下载
resnet34=models.resnet34(pretrained=True, num_classes=1000)
resnet34.fc=nn.Linear(512,10)
2.datasets
from torchvision import datasets
from torchvision import transforms as T
transform=T.Compose([
T.Resize(224), #缩放图片(Image),保持长宽比不变,最短边为224像素
T.CenterCrop(224), #从图片中间裁剪出224*224的图片
T.ToTensor(), #将图片Image转换成Tensor,归一化至【0,1】
T.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5]) #标准化至【-1,1】,规定均值和方差
])
dataset=datasets.MNIST('data/',download=True, train=False, transform=transform)
len(dataset)3.transforms
import torch as t
from torchvision import transforms
to_pil=transforms.ToPILImage()
to_pil(t.randn(3,64,64))输出的是随机噪声:

4.make_grid、save_img
torchvision 还提供了两个常用的函数,一个是make_grid,它能将多张图片拼接在一个网格中;
另一个是save_img,它能将Tensor保存成图片。
from torchvision import datasets
from torchvision import transforms as T
transform=T.Compose([
T.Resize(224), #缩放图片(Image),保持长宽比不变,最短边为224像素
T.CenterCrop(224), #从图片中间裁剪出224*224的图片
T.ToTensor(), #将图片Image转换成Tensor,归一化至【0,1】
T.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5]) #标准化至【-1,1】,规定均值和方差
])
dataset=datasets.MNIST('data/',download=True, train=False, transform=transform)
print(len(dataset))
from torch.utils.data import DataLoader
dataloader=DataLoader(dataset,batch_size=16,shuffle=True)
from torchvision.utils import make_grid, save_image
dataiter=iter(dataloader)
img=make_grid(next(dataiter)[0],4) #拼成4*4的网格图片,且会转成3通道。
save_image(img,'a.png')
5. 可视化工具
在训练神经网络时,我们希望能够更直观地了解训练情况,包括损失曲线、输入图片、输出图片、卷积核的参数分布等信息。这些信息能帮助我们更好地监督网络的训练过程,并为参数优化提供方向和依据。
最简单的办法就是打印输出,但其职能打印数值信息,不够直观,同时无法查看分布、图片、声音等。
本节重点介绍深度学习中常用的可视化工具:Tensorboard和 visdom.
5.1. Tensorboard
需要安装TensorFlow 和Tensorboard_logger
pip3 install Tensorboard_loggerpython -m visdom.server
TensorBoard 1.8.0 at http://DESKTOP-U3R9MCE:6006
http://DESKTOP-U3R9MCE:6006
还有针对Pytorch开发的TensorboardX.
5.2. visdom
使用方法参考: https://ptorch.com/news/77.html
1)使用方法
总结为以下几步:
1)cmd命令行安装visdom pip3 install visdom
2) cmd命令行启动服务器 python -m visdom.server
3) 浏览器访问:http://localhost:8097
4) Python编辑器中建立要可视化的代码:
例如:
import visdom
import numpy as np
import torch as t
vis = visdom.Visdom()
import visdom
# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
x = t.arange(1, 30, 0.01)
y = t.sin(x)
vis.line(X=x, Y=y, win='sinx', opts={'title': 'y=sin(x)'})编译,得到以下结果:
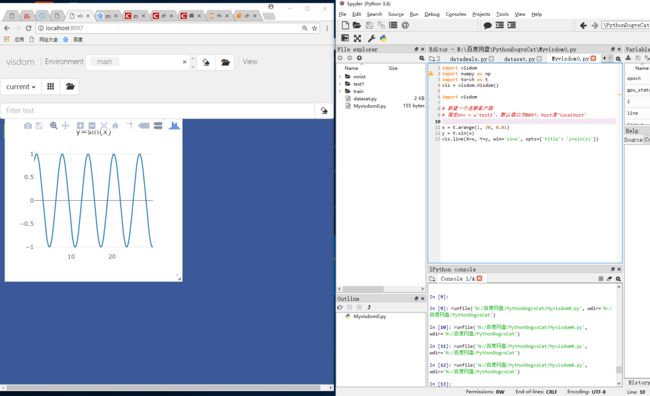
2)Visdom可视化接口
Visdom支持下列API。由Plotly提供可视化支持。
vis.scatter : 2D 或 3D 散点图
vis.line : 线图
vis.stem : 茎叶图
vis.heatmap : 热力图
vis.bar : 条形图
vis.histogram: 直方图
vis.boxplot : 箱型图
vis.surf : 表面图
vis.contour : 轮廓图
vis.quiver : 绘出二维矢量场
vis.image : 图片
vis.text : 文本
vis.mesh : 网格图
vis.save : 序列化状态这些API的确切输入类型有所不同,尽管大多数API 的输入包含,一个tensor X(保存数据)和一个可选的tensor Y(保存标签或者时间戳)。所有的绘图函数都接收一个可选参数win,用来将图画到一个特定的window上。每个绘图函数也会返回当前绘图的win。您也可以指定 汇出的图添加到哪个env上。
(这里的window的意思就是之前说的Pane)。
。。。
本小节链接:https://blog.csdn.net/u012436149/article/details/69389610
import visdom
import numpy as np
import torch as t
#vis = visdom.Visdom()
# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
vis = visdom.Visdom(env=u'test1')
x = t.arange(1, 30, 0.01)
y = t.sin(x)
vis.line(X=x, Y=y, win='sinx', opts={'title': 'y=sin(x)'})
# 可视化一个随机的黑白图片
vis.image(t.randn(64, 64).numpy())
# 随机可视化一张彩色图片
vis.image(t.randn(3, 64, 64).numpy(), win='random2')
# 可视化36张随机的彩色图片,每一行6张
vis.images(t.randn(36, 3, 64, 64).numpy(), nrow=6, win='random3', opts={'title':'random_imgs'})
vis.text('Hello, world!')
# append 追加数据
for ii in range(0, 10):
# y = x
x = t.Tensor([ii])
y = x
vis.line(X=x, Y=y, win='polynomial', update='append' if ii>0 else None)
# updateTrace 新增一条线
x = t.arange(0, 9, 0.1)
y = (x ** 2) / 9
vis.updateTrace(X=x, Y=y, win='polynomial', name='this is a new Trace')可视化结果:
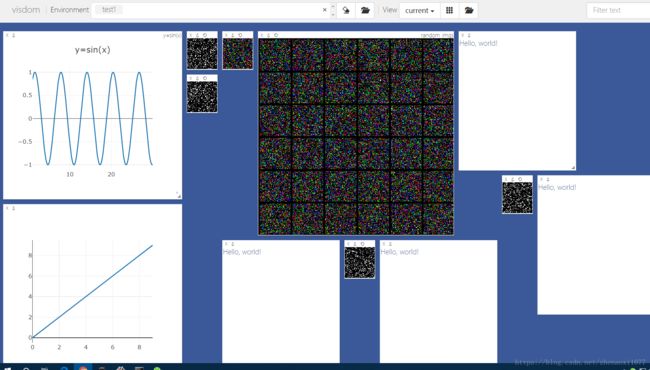
下面逐一分析这几行代码:
- vis = visdom.Visdom(env=u'test1'),用于构建一个客户端,客户端除指定env之外,还可以指定host、port等参数。
- vis作为一个客户端对象,可以使用常见的画图函数,包括:
- line:类似Matlab中的`plot`操作,用于记录某些标量的变化,如损失、准确率等
- image:可视化图片,可以是输入的图片,也可以是GAN生成的图片,还可以是卷积核的信息
- text:用于记录日志等文字信息,支持html格式
- histgram:可视化分布,主要是查看数据、参数的分布
- scatter:绘制散点图
- bar:绘制柱状图
- pie:绘制饼状图
- 更多操作可参考visdom的github主页这里主要介绍深度学习中常见的line、image和text操作。
Visdom同时支持PyTorch的tensor和Numpy的ndarray两种数据结构,但不支持Python的int、float等类型,因此每次传入时都需先将数据转成ndarray或tensor。上述操作的参数一般不同,但有两个参数是绝大多数操作都具备的:
- win:用于指定pane的名字,如果不指定,visdom将自动分配一个新的pane。如果两次操作指定的win名字一样,新的操作将覆盖当前pane的内容,因此建议每次操作都重新指定win。
- opts:选项,接收一个字典,常见的option包括
title、xlabel、ylabel、width等,主要用于设置pane的显示格式。
之前提到过,每次操作都会覆盖之前的数值,但往往我们在训练网络的过程中需不断更新数值,如损失值等,这时就需要指定参数update='append'来避免覆盖之前的数值。而除了使用update参数以外,还可以使用vis.updateTrace方法来更新图,但updateTrace不仅能在指定pane上新增一个和已有数据相互独立的Trace,还能像update='append'那样在同一条trace上追加数据。
image的画图功能可分为如下两类:
image接收一个二维或三维向量, H×WH×W 或 3×H×W3×H×W ,前者是黑白图像,后者是彩色图像。
images接收一个四维向量 N×C×H×WN×C×H×W , CC 可以是1或3,分别代表黑白和彩色图像。可实现类似torchvision中make_grid的功能,将多张图片拼接在一起。images也可以接收一个二维或三维的向量,此时它所实现的功能与image一致。# 可视化一个随机的黑白图片
vis.image(t.randn(64, 64).numpy())
# 随机可视化一张彩色图片
vis.image(t.randn(3, 64, 64).numpy(), win='random2')
# 可视化36张随机的彩色图片,每一行6张
vis.images(t.randn(36, 3, 64, 64).numpy(), nrow=6, win='random3', opts={'title':'random_imgs'})
对比ResNet: 超深层网络DiracNet的PyTorch实现:链接:
https://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/78536813